






非滤波单目视觉SLAM系统
A survey on non-filter-based monocular VisualSLAM systems
Taylor Guo, 2016年9月12日 -2017年4月12日
摘要
视觉SLAM过去15年的研究产生了大量可以使用的系统,广泛应用于机器人和增强现实应用中。滤波(卡尔曼滤波,粒子滤波)视觉SLAM更通用,非滤波(运动估计结构)方案更有效率、日益成为构建视觉SLAM系统的事实方法。本文讲解各种非滤波视觉SLAM构建方法及其组成部分,每种系统的特殊的构建策略和模块实现。
关键词:视觉SLAM,单目,非滤波
一 简介
过去15年单目相机定位方法非常流行。相机在手机和平板电脑这样的手持设备上的增强现实应用非常普遍,相机传感器非常自然地成为用于定位用户位置、将虚拟场景投影到正确视角下的选择。由于成本低、体积小,相机在重量和功耗要求比较高的定位应用中也频繁使用,比如无人机。甚至尽管相机定位方案面临很多挑战,这种方法仍然比其他定位方案有非常明显的优势。
如果不谈依赖于标记或目标跟踪的定位方法,基于相机的定位有两种方法。一种是基于图像的定位,需要先处理场景生成3D结构、场景图像和对应的相机视角。定位问题就可以变为将图像序列与数据库的进行匹配,和选择具有最佳匹配的相机位置。第二种技术是,没有场景先验信息;地图构建和定位同时进行。我们可以增量式地估计相机位姿------也就是视觉里程计;或者为了减少里程计中的漂移,在整个运行过程中维护地图和相机位姿。这个就是通常所说的视觉SLAM。尽管上面所说的相机方法都很重要,但本文主要讲视觉SLAM。
其实,已经有大量的有关SLAM问题的综述了,但只有很少一部分专讲视觉SLAM的。2012年Fuentes的SLAM综述是对视觉SLAM的一般性综述,但没有探索各个视觉SLAM的方案细节。另外,在论文发表的时候,又有13个新系统发布了,这些系统对视觉SLAM有巨大贡献。2015年Yousif也发表了视觉SLAM的一般性综述,包含滤波、非滤波和RGB-D系统。但滤波视觉SLAM方案在2010年之前比较常用,之后大部分系统是基于非滤波方案架构的。这个综述描述了视觉SLAM的一般方法,但缺少对单目非滤波系统细节和问题的关注。基于上述动因,本文讲述了非滤波单目视觉SLAM系统的最新进展。对开源系统的描述超出了论文本来的内容,基于对这些方案代码的修改和应用后的理解。但是,对闭源系统并没有足够的信息,没法运行代码。
这个综述对用户或研究者来说是相机定位非常有价值的工具。每天都有新系统开发出来,这些信息对新手来说非常害怕,对使用哪个算法非常困惑。这个论文可以帮助研究者快速明白各种方法的缺点,可以专注在改善这些弱点上。
文章结构如下。第2部分介绍了视觉SLAM系统的历史发展,从Davison单目SLAM开始到最新的系统。第3部分介绍了视觉SLAM系统的构成基础,分析了各个开源系统的差别;初始化,数据观测和数据关联,位姿估计,地图生成,地图维护,失效恢复,和回环检测。第4部分总结了闭源非滤波视觉SLAM系统,第5部分对整个文章进行了总结。
二 概览
视觉SLAM方案可以基于滤波方案(卡尔曼滤波、粒子滤波),也可以基于非滤波方案(比如,将其视为优化问题)。图1a是滤波系统的不同部分的数据连接;相机位姿Tn和地图中所有路标的状态紧密结合,每帧图像都更新。非滤波系统相反,如图1.b所示,不同部分的数据连接,可以允许相机在Tn的位姿估计用整个地图的一个子集,不需要在处理每幅图像时都更新地图数据。由于这种差别,2010年Strasdat证明了非滤波方法优于滤波方法。毫无疑问自此之后,新的视觉SLAM系统都基于非滤波方法,如表一所示。本文集中分析非滤波方法,只是列出滤波方法。
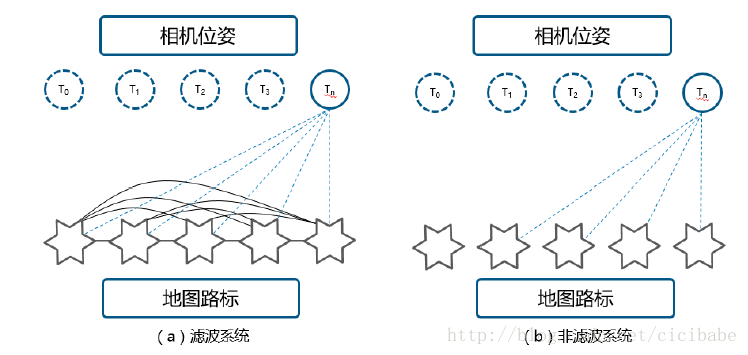
图1:视觉SLAM系统中的数据连接:滤波与非滤波方法

表一:视觉SLAM系统列表。非滤波方法用灰底标出。
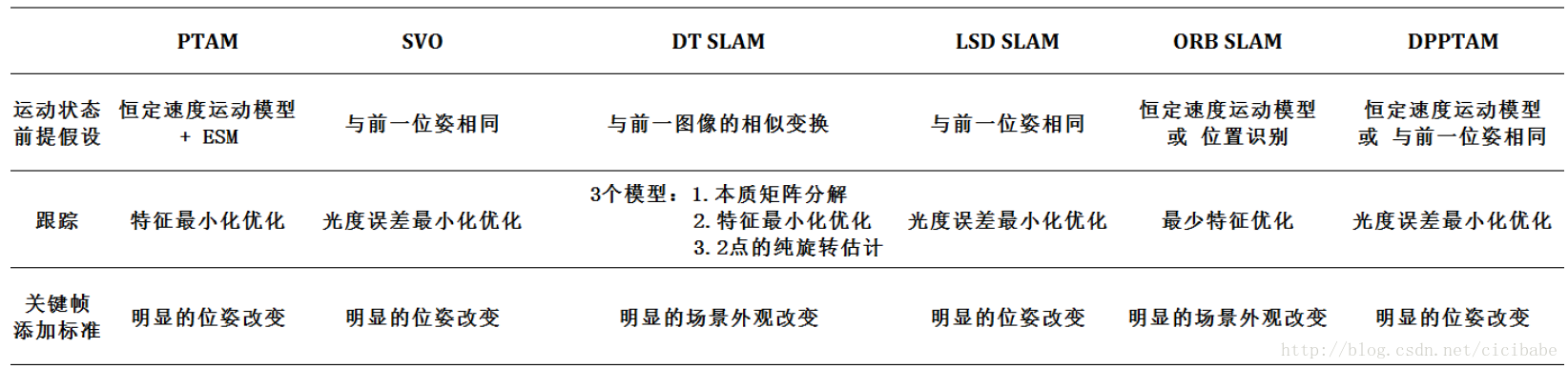
2007年PTAM发布,后来提出了各种修改和变种版本。PTAM是第一个算法,成功地将跟踪和地图构建分成两个并行计算的线程,同时运行,根据需要分享信息。这一分离使得PTAM中采用的运动恢复结构方法实时运行成为可能。这一方法在单目视觉SLAM社区是革命性的,跟踪和地图构建成为了所有视觉SLAM算法的标准。
2014年SVO发布,这个开源系统是一个混合系统采用了直接和间接方法解决视觉SLAM任务。与PTAM不同,SVO需要更高的帧率的相机。SVO的设计考虑到了高性能的平台运行和有计算能力限制的硬件,比如通用的微型飞行器的板载硬件。为了达到这样的目的,SVO提供了两种缺省的配置,一种为了运行速度进行了优化,另外一种是为了精度。
2014年还发布了LSDSLAM开源系统,采用了2013年Engel的视觉里程计方法。LSD SLAM采用了高效的概率直接法估计半稠密地图用于图像匹配对齐流程中解决SLAM任务。与其他用捆集调整方法的系统不同,LSD SLAM采用了Sim(3)的位姿图优化,如2011年Kummerle论文g2o所示,在系统中明确地表示了尺度信息,能够实时处理尺度漂移矫正和回环闭合检测。改进的LSD SLAM版本可以运行在移动平台,另外一个版本可以运行在立体相机上。LSD SLAM系统在初始化之后并行运行了3个线程:跟踪,深度地图估计和地图优化。
2014年底,DeferredTriangulation SLAM,简称DT SLAM发布,是一种间接方法。与其他算法类似,它将视觉SLAM分成3个并行的线程:跟踪、地图构建和捆集调整。DT SLAM的主要贡献是它能在一个统一的框架下从2D特征和3D特征中估计相机位姿,并且将两种特征整合进一个捆集调整中。这使得DT SLAM对纯旋转运动具有鲁棒性。系统的另外一个特点是它能处理多个未定义尺度的地图,一旦构建了足够多数量的3D匹配,就将它们融合在一起。在DT SLAM中并没有明确定义的初始化流程,因为它被嵌入到跟踪线程中;另外,当跟踪丢失的时候,它可以执行多次初始化。既然无论什么时候系统跟丢初始化都会自动完成,就算是在不同的尺度下,数据总是能收集到,相机跟踪也能正常工作。重新初始化局部子地图的能力能够减少对重定位流程的依赖。一旦各个子地图中的关键帧中有足够数量的匹配,子地图就会在统一尺度下被融合进一个单一地图中。
2015年,ORB SLAM发布,是一个间接视觉SLAM系统。它将视觉SLAM分成3个并行的线程,跟踪、地图构建和地图优化。ORB SLAM的主要贡献是采用了实时ORB特征,一个1999年Torr发布的一个初始化模型,一个对视角变换具有不变性的重定位,一个采用词袋模型检测回环的位置识别,covisibility和本征图优化。
2015年底,DPPTAM-Dense Piecewise Parallel tracking and Mapping发布,是一个半稠密直接方法,与LSD SLAM类似,用于解决视觉SLAM任务。DPPTAM的一个主要贡献是在采用LSD SLAM的基础上,添加了第3个并行线程用分割的室内平面场景超像素执行稠密重建。
三 视觉SLAM系统的设计
为了能够更好地理解视觉SLAM的最新开发情况,本章讨论视觉SLAM最近进展,分析最成功的开源非滤波方法视觉SLAM系统。具体讨论PTAM,SVO,DT SLAM, LSD SLAM,ORB SLAM, DPPTAM。通用的非滤波视觉SLAM系统主要有8部分组成,如图2所示,(1)数据输入类型,(2)数据关联,(3)初始化,(4)位姿估计,(5)地图生成,(6)地图维护,(7)失效恢复,(8)回环闭合。
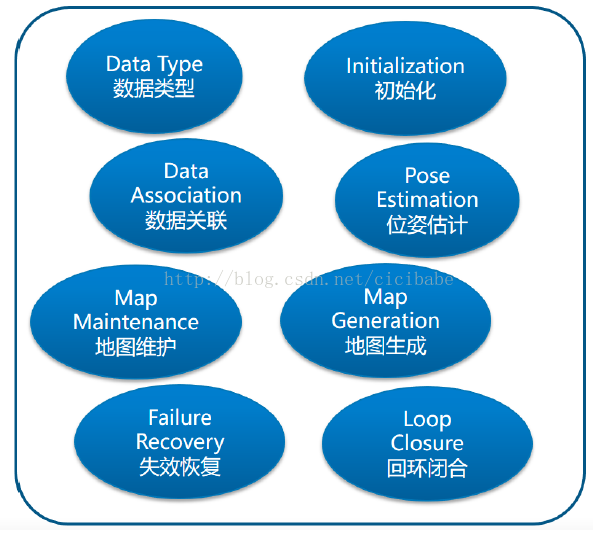
图2:非滤波方法的视觉SLAM系统的8个模块
我们会详细介绍每一部分,视觉SLAM如何执行这些模块。需要注意的是,这些系统的内参是已知的,已经离线标定好了。
视觉SLAM方法被分为直接法,间接法,混合法。直接方法---也是稠密或半稠密方法---指的是采用图像上每个像素的信息(亮度值)估计描述相机位姿的参数。另外,间接法用于减少处理每个像素的计算复杂度;可以只使用显著的图像部位(即特征)用于位姿估计的计算(如图3 所示)。
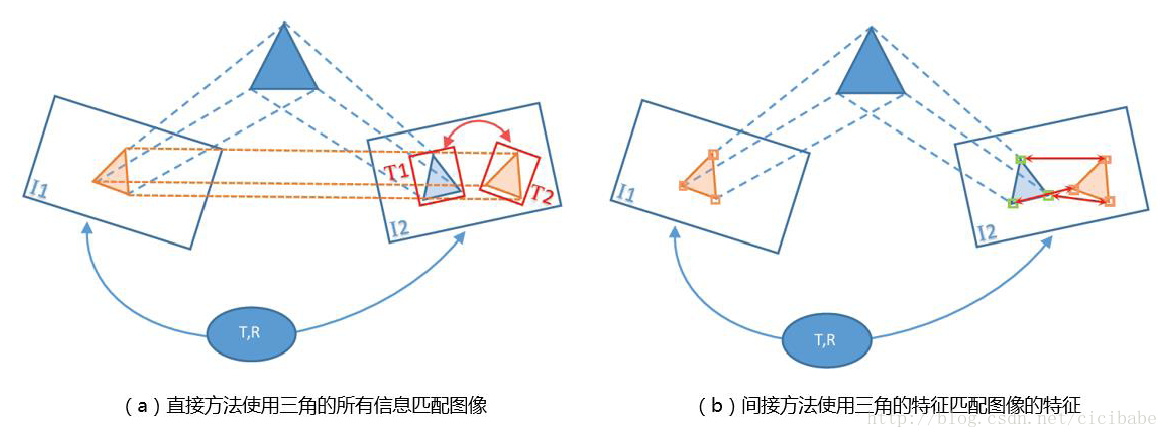
图3:视觉SLAM系统使用的数据类型
直接方法最基本的原理是亮度一致性约束,可以用一下公式描述:
J(x,y)=I(x+u(x,y)+v(x,y)), (1)
其中,x,y是像素坐标;u,v是同一场景的两幅图像I和J的像素(x,y)位置偏移函数。每个像素都有一个亮度值约束,但它增加了2个未知数(u和v),系统变为欠定方程组,有2n个未知数但只有n个等式(其中n是图像上的像素数量)。为了解决这个问题,1981年Lucas & Kanade提出光流法(相邻帧的运动信息,假设亮度保持不变,运动相对帧率缓慢,使用加权最小二乘法进行估计光流),采用前向相加图像对齐Forward Additive Image Alignment,使用一个单一的一般运动模型取代所有单一像素的位移u和v,这个模型参数的数量只取决于运动类型。FAIA通过改变变换参数迭代地求解一个模板和输入图像的像素亮度差值开方的最小化值。为了减小计算复杂度、节省时间,FAIA变化成其他形式,如 FCIA (Forward Compositional Image Alignment), ICIA (Inverse Compositional Image Alignment) 和IAIA (Inverse Additive Image Alignment)。
直接方法使用了图像上所有可用的信息,因此在纹理较差的部分比间接法更鲁棒。但当场景亮度变化时,当图像间的光度误差最小值取决于等式一的亮度一致性约束的内在要求时,直接法很可能会失效。第二个不利的因素是,每个像素的光度误差的计算非常密集;直接法的实时视觉SLAM的应用,之前认为一直不可行。由于最近出现了并行计算,直接法被整合到视觉SLAM中(比如DPPTAM, LSD-SLAM, SVO)。
非直接方法使用特征匹配。一方面希望特征比较显著,对视角和光照变化具有不变性,对模糊和噪声有弹性。另外一方面希望特征提取器的计算高效快速。但这些目标很难同时获得,需要在计算速度和特征质量上取得平衡。
计算机视觉领域开发了很多不同的特征提取器和特征描述子,它们对旋转、尺度不变,和计算速度的性能表现都不一样。选择合适的特征检测器依赖于平台的计算能力,视觉SLAM算法运行的环境,还有要求的图像帧率。特征检测器有 Hessian cornerdetector (Beaudet, 1978), Harris detector (Harris and Stephens, 1988),Shi-Tomasi corners (Shi and Tomasi, 1994), Laplacian of Gaussian detector(Lindeberg, 1998), MSER (Matas et al, 2002), Difference of Gaussian (Lowe,2004) 和加速分割检测器 (FAST, AGAST, OAST) (Mair et al, 2010).
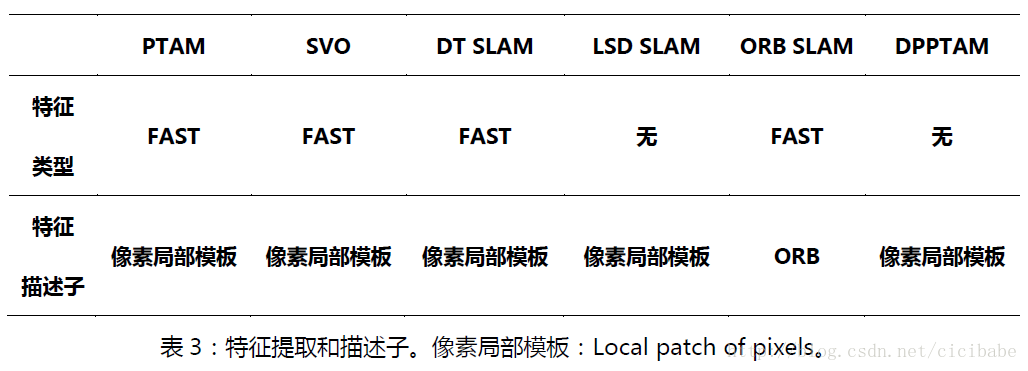
为了降低计算要求,大部分间接系统使用FAST作为特征提取器,与特征描述子一起执行数据关联。特征描述子包括但不限于BRIEF, BRISK, SURF,SIFT, HoG, FREAK, ORB 和低层局部像素区块。更多的有关特征提取器和特征描述子,可以参考论文综述。
3.1.3混合法基于直接法和间接法的差异,有的系统,比如SVO采用混合方法,用直接法构建特征匹配,用间接法优化相机位姿估计。
表2总结了部分视觉SLAM系统使用的数据类型。开源的间接方法,PTAM, SVO, DT SLAM使用FAST特征, ORB SLAM使用ORB特征。

数据关联就是在不同图像的观测之间建立匹配关系的过程,作为视觉SLAM其他模块的输入。这步是系统必须的,采用直接方法,在相机位姿里面还会讨论直接方法的数据关联。
构建特征匹配用间接方法,其数据关联分为有3类:2D-2D,3D-2D和3D-3D。
3.2.12D-2D没有地图,没有2幅图像的相机变换,也没有场景结构时,使用2D-2D的数据关联。为了减少计算时间,避免错误数据关联的可能性,第一幅图像的特征2D位置定义成一个搜索窗口在第2幅图像中进行搜索。每个特征有个描述子,与其他特征的相似度进行定量对比。描述子的距离函数随着所用描述子类型变化:对于像素描述子局部区块,通常使用模板(patch)匹配中差值平方和(SSD),或者为了增加对于光照变化的鲁棒性,使用零均值像素灰度差值平方和(ZMSSD)。对于高阶特征描述子,比如ORB,SIFT和SURF,可能会采用L1范数(向量中各个元素绝对值之和,就是绝对值相加,又称曼哈顿距离),L2范数(就是欧几里德距离)和汉明距离;但用这些方法做匹配计算量比较大,稍不注意可能会降低实时性能。这样,就采用特别的检索和执行方法在KD树或词袋向量中来处理特征匹配,比如2009年Muja的工作和2012年Galvez-Lopez的工作。
图4表示的是3D-2D数据关联问题,前一相机位姿估计和3D结构已知,需要估计2D特征和3D路标射影的对应关系,这个3D路标射影到一个新的图像中并且不知道这两个图像之间的确切运动关系。这种数据关联方法在视觉SLAM的位姿估计中非常常用。

为了估计和校正回环的累积漂移,就需要3D-3D的数据关联,2幅图像中观测到的3D路标的描述子可以与将要探测的路标之间进行匹配,用于产生两个图像间的相似变换。表3总结了各种开源视觉SLAM系统采用的特征类型和描述子。
PTAM。PTAM成功初始化之后,每个图像会生成一个4层金字塔(比如,第一层:640x480,第二层:320x240)。金字塔分层可以使特征对于尺度变换更鲁棒,从而降低位姿估计模块的收敛半径。每层都会提取FAST特征并且每个特征都会计算Shi-Tomasi分值;在执行非极大值抑制(Non-maximum suppression)算法之前就会删除低于一个设定的Shi-Tomasi阈值的特征。这样是为了确保提取的特征的高度显著性,并限制它们的数量,可以使计算复杂度可控制。
每层金字塔都有不同的Shi-Tomasi阈值和非极大值抑制;从而可以控制特征强度和数量,在都可以追踪到。然后,用已知的位姿估计将3D路标影射到新图像上去,使用与2D-2D同样的方法,在射影的路标位置附近的搜索窗口中构建特征匹配。3D路标特征匹配的描述子通常从已经先观测到3D路标的2D图像中提取;然而,当从相机视角观察到了显著变化,或者由于像素局部模板扭曲引起视角变化,有些系统建议更新描述子。
DTSLAM。与PTAM类似,DT SLAM采用相同机制构建2D-3D特征匹配。
SVO。SVO图像有5层金字塔:通过迭代执行直接图像对准方案从最高层金字塔到第3层金字塔进行数据关联。这一步的初步数据关联作为FAST特征匹配过程先验信息,与PTAM保持显著性的图像变形技术相似,使用零均值像素灰度差平方和(ZMSSD) 。
ORBSLAM。ORB SLAM在8层金字塔上都提取FAST角点。为了确保整幅图像的一致性分布,每层金字塔被分成小单元格,FAST特征检测器的参数在线调整以确保每个单元格至少提取5个角点。然后每个提取的特征计算一个256位ORB特征描述子。高层的ORB特征描述子用于建立特征间的匹配。ORB SLAM把描述子分散存储到词袋模型中,也就是视觉字典,字典树上相同节点下的特征约束可以加速图像和特征匹配。
单目视觉SLAM系统需要进行初始化,这一过程主要生成3D路标地图和初始相机位姿。为了达到这个目的,同一的场景至少要从同一基线的两个不同视角分开观测。图5是视觉SLAM系统的初始化,只知道2幅图像间的关联数据,初始相机位姿和场景结构都是未知的。对于这个问题不同的人有不同的方案。
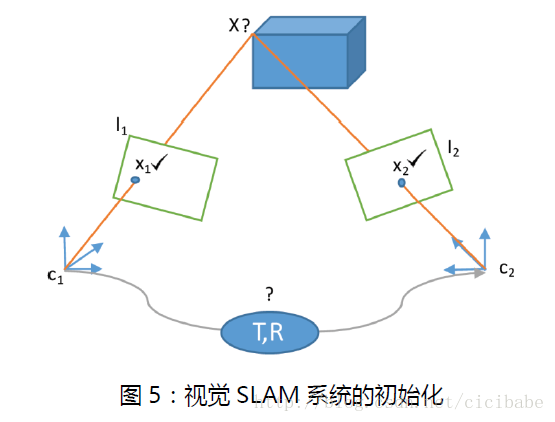
早期视觉SLAM系统,比如2007年Davison的单目视觉SLAM,系统初始化要求相机摆放在距平面场景已知距离的地方,场景由2维平面4个角组成,SLAM通过操作人员输入距离值实现初始化。
PTAM。图6显示了基于模型初始化的一般流程,比如PTAM,SVO,ORB SLAM都采用了。为了避免用户手动输入深度信息,PTAM最开始使用5点算法估计和分解基本矩阵用于一个非平面初始场景。后来PTAM初始化做了改变成使用单应矩阵,此时场景应该由2D平面组成。PTAM初始化要求用户两次输入获取地图中的前2个关键帧;它还需要用户在第一个和第二个关键帧之间,做与场景平行的、缓慢平滑相对明显的平移运动。
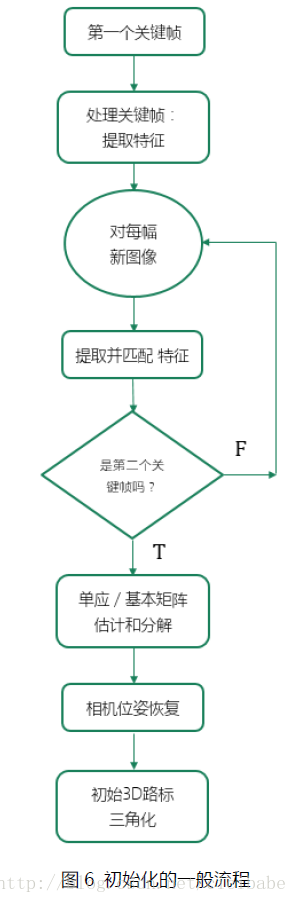
图6 初始化的一般流程
从第1个关键帧提取的FAST特征,在后来的每一帧图像中,用2D-2D数据关联方法追踪,直到用户标记插入第2个关键帧。 匹配过程采用ZMSSD,不需要保持显著性的图像特征的变形技术,构建角点匹配的过程对运动模糊和由于相机旋转造成明显的外观特征改变比较敏感,因此,要在初始化过程中对用户的运动状态要求严格。
为了使匹配错误最小化,特征需要搜索2遍;第一次从当前帧到上一帧,第二次从相反的方向搜索。如果两个方向的匹配不一致,特征就会被丢弃。既然PTAM初始化使用单应估计,那么初始化过程中的观察到的场景就应该是2维的。一旦第2个关键帧成功地放入地图中,一个随机抽样最大似然估计(MaximumLikelihood Estimation by Sample and Consensus, MLESAC)回环使用构建好的匹配生成一个单应,这个单应是2个关键帧间的,在分解成8个可能的方程之前使用内点进行优化。选择正确的相机位姿对,这样所有三角化过的3D点就不会生成不真实的配置(两幅图中的逆深度)。
生成的初始地图大小可以变化,比如前两个关键帧之间估计的平移变换就可以对应成0.1个单位,在这之前仅基于结构的捆集调整BA(只优化路标的3D位姿)就会先运行。选用3D路标的均作为世界坐标系,同时选择z轴的正方向作为相机位姿的正方向。
PTAM初始化程序非常脆弱,需要技巧去运行,尤其是对于没有经验的用户。还有,初始化场景不是2维平面,或用户运动状态不恰当的时候,系统退化,容易崩溃,这样的退化无法检测。
SVO。类似的,SVO使用单应进行初始化,但SVO不需要用户输入,算法使用系统启动时的第一个关键帧;提取FAST特征,用图像间的KLT算法跟踪特征(KLT(Kanade-Lucas-Tomasi)算法是计算机视觉的跟踪算法,通过基于平移模型进行灰度匹配来实现特征点的跟踪,并进行基于跟踪算法的特征点选择,提高特征点跟踪质量。通过特征点选择算法在起始图像中选择特征点,然后利用平移模型进行特征点跟踪,对于第N幅图像上跟踪到的特征点,通过仿射模型进行连续性判断,对跟踪错误的特征点进行剔除。KLT算法中在研究不同图像之间的匹配问题时,通过计算两个平移窗口的灰度残差,并寻找最小化残差SSD(sum of square difference)来实现匹配。在优化过程中,KLT算法使用泰勒展开直接计算平移矢量,而不需要通过遍历进行搜索;同时使用Newton-Raphson迭代算法来避免泰勒展开带来的误差。)。为了避免用户二次输入,SVO监控第一个关键帧和当前图像间的特征点基线中值,无论什么时候这个值达到一定的阈值,算法都认为已经获得了足够的视差,开始估计单应。然后,分解单应(矩阵);接着选择正确的相机位姿,路标对应的内点匹配会被三角化,用于估计初始场景的深度信息。在第二个图像作为第二个关键帧并放入地图管理线程之前,前2帧图像和它们关联路标的捆集调整就开始运行了。
与PTAM一样,SVO的初始化要求同样的运动模型,适用于剧烈运动和非平面场景;监控特征间的基线中值并不是一个用于自动化选择一对初始关键帧的好方法,在退化状态下容易失效,而且没有办法检测到。
DT SLAM。DT SLAM没有明显的初始化过程,用估计本质矩阵的方法,集成在跟踪模块中。
表4总结了不同视觉SLAM系统所采用的初始化方法,都是在系统启动时对场景所做的处理和配置。除了单目SLAM之外,本文提到的所有方法对于特定的场景都会受到退化的影响,也就是说在相机的低视差运动情况下,或者当场景结构的特征匹配方法,即基本矩阵的前提是针对一般非平面场景,或者单应矩阵对应的平面场景,这些前提假设不成立时会受到影响。

表4:初始化
LSD SLAM。为了处理初始化问题,LSD SLAM从第1个视角随机初始化场景的深度,通过随后的图像进行优化。LSD SLAM初始化方法不需要使用两视图几何。不像其他SLAM系统跟踪两视图特征,LSD SLAM只用单个图像进行初始化;兴趣像素点(高亮度梯度的图像位置)初始化时将深度随机分布和方差大的放入系统。第一个初始化的关键帧和后面的图像对齐后,就直接开始跟踪。初始特征的深度测量用滤波方法优化,图像不断输入优化直到收敛。这种方法不会因为两视图几何的原因退化;但估计深度在算法收敛之前需要处理大量图像,需要一个中间跟踪过程,生成的地图也不可靠。
DPPTAM。DPPTAM借用了LSD SLAM的初始化过程,因此,也会受到随机深度初始化的影响,在它得到一个稳定的配置之前,必须要往系统中加入几个关键帧。
为了解决上述局限,Mur-Artal建议并行计算基本矩阵和单应(用RANSAC算法),根据对称转移误差(多视图几何)惩罚不同的模型,最终是为了选择合适的模型。完成之后,就会进行适当的分解,在捆集调整优化地图之前,场景结构和相机位姿都会重构。如果选择的模型跟踪质量差,进来的图像的特征对应少,初始化就会迅速被系统放弃,再用不同的图像进行重启动。值得注意的是,上述初始化方法,除单目SLAM以外,图像坐标和对应的3D坐标的关系只能根据未知尺度λ决定。
因为数据关联计算量巨大,大部分SLAM系统都有一个先决条件,即对于每个新图像的位姿,用于数据关联工作都有具体要求和限制。这个先决条件通常都是位姿估计的第一个任务。图7描述了位姿估计问题;两幅图像之间的一个地图和数据关联已知,先给定第一个位姿,去估计第二幅图像的位姿。PTAM,DT SLAM,ORB SLAM,DPPTAM都假设相机做平滑运动采用恒定速度运动模型,用跟踪到的两幅图像的位姿变化估计当前图像的先验知识(用于数据关联的图像位姿的要求和限制)。但是,在相机运动方向上有猛烈移动时,这样的模型就容易失效。LSD SLAM和SVO都假设在随后的图像(这种情况下都是用高帧率相机),相机位姿没有明显改变,因此,他们给当前图像位姿和前一个跟踪到的图像分配相同的要求和限制的先验信息(先决条件)。
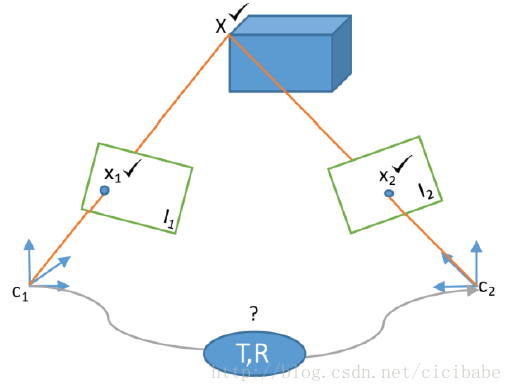
图7 视觉SLAM系统的位姿估计。
图8是位姿估计的一般流程。前一幅图像的位姿可以有几种方法用于指导数据关联流程。它可以从当前图像的地图中获取一组视觉特征,从而减少盲目投影整个地图的计算开销。另外,它还可以估计特征在当前图像中的位置,这样特征匹配只在很小的区域内进行搜索,而不是搜索整个图像。最后,它还是用于优化相机位姿的最小化流程的起始点。

图8 位姿估计的一般流程
直接和间接方式都是通过最小化图像间的测量误差估计相机位姿;直接方法测量光度误差,间接方法通过最小化从图像上一位姿的地图中获得的路标的重投影误差估计相机位姿。重投影误差用前一位姿下投影到图像上的3D路标和它发现的图像上的2D位置的像素距离构建函数。

图9 位姿估计的一般过程。
Cm是用运动模型估计的新图像位姿,C2是真实的相机位姿。
图9演示了相机位姿是如何估计的。运动模型用于生成Cm处的新图像位姿,和一系列潜在的从地图投影到新图像上的视觉3D路标。以投影的路标为中心的搜索窗口Sw用于数据关联。然后,系统使用刚体变换参数最小化重投影误差d。为了获得对离群点(错误匹配的特征)的鲁棒性,目标函数最小化会处理掉重投影误差比较大的特征。
PTAM。PTAM用SE(3)变换表示相机位姿,最少可以用6个参数表示。从完全SE(3)上的变换到它的最小表示Sξ(3),还有反向过程,可以通过李代数上的对数和指数映射解决。最小表示Sξ(3)变换非常重要,它将参数从12个减到6个,在优化过程中可以明显提速。
PTAM中,位姿估计流程是先用恒定速度运动模型估计一个图像位姿的先验信息。然后优化先验信息,用一个小的模糊图像代表这个图像,采用ESM算法(ESM 是Efficient Second-order Minimization 的缩写,源自 Benhimane 和 Malis 在 2004年 在IROS 上发表的工作。该算法采用重构误差平方作为衡量 R 和T 相似性的指标,然后对于姿态空间进行了在李群(Lie Group)上的重新构建使得搜索的步长更为理性,在寻优上面使用的二阶近似的快速算法。这个算法的结构清晰,各模块都容易独立扩展,所以在其基础上衍生出了不少改进算法,通常是针对实用场景中不同的调整(比如处理强光照或者运动模糊))。先验信息(图像)的速度定义为当前图像的位姿估计与前一相机位姿的改变快慢。如果速率快,PTAM会预计到一个快速运动发生,那么运动状态就是模糊的;会导致程序失效,PTAM会限制跟踪线程使其只作用于最高层金字塔上(对运动模糊的弹性最大),这只是一个粗略的跟踪过程;粗略跟踪阶段后会接着采用一个精细跟踪阶段。但是,当相机静止时,这个粗糙的步骤可能会导致相机抖动---因此,它会被关闭。
最小表示的初始相机先验信息(模糊图像)可以用最小化重投影误差的Tukey双向加权目标函数来优化,向下权重观测值误差大。如果精细跟踪线程完成后,就从金字塔最低层选取特征,重复运行上述流程。
为了判断追踪的质量,PTAM中的位姿估计线程监控图像中成功匹配的特征数量占所有要匹配特征数量的比率。如果跟踪质量有问题,追踪线程还是会照常运行但是没有关键帧会被系统接收。如果连续3个图像都认为跟踪器性能不好,跟踪就被认为是丢失了,失效恢复就启动了。
表5 总结了不同视觉SLAM的位姿估计方法。
SVO。SVO用金字塔算法中基于稀疏模型的图像对齐方法估计初始相机位姿。它先假定t时刻相机位姿与t-1时刻相机位姿相同,是为了最小化当前图像中已知深度的2D图像位置的光度误差,即同一位置的t-1(与t)时刻的,根据两幅图像的不同相机位姿变换不同。最小化需要使用逆向合成图像对齐方法中高斯-牛顿迭代30次。然而这对SVO引入了很多限制,因为ICIA要求图像间的位移很小(1个像素)。这就要求SVO使用高帧率相机(典型的是大于70fps),对于这样的限制位移就不会超出范围。还有,ICIA基于亮度一致性约束,表现出更容易因光照条件而变化的特性。
SVO并没有对每个图像采用明显的特征匹配;但在图像对齐步骤顺带获得。一但图像对齐,当前帧上估计的路标,就投影到图像上去。从当前图像的初始投影位置中提取的投影路标2D位置可以用最小化区块间的光度误差优化,弯曲路径上的路标从可以观察到2D位置的最邻近关键帧中生成。为了减小计算复杂度,只维护最强的特征,图像分成网格,每个网格只有一个投影的路标(最强的)。然而,这个最小化违反了整个帧的对极约束,后续是在跟踪模块中需要使用的。接着处理运动捆集调整,然后是结构捆集调整,它是基于前一步骤中优化过的相机位姿来优化路标的3D位置。
最后,联合(位姿和结构)局部捆集调整优化之前的相机位姿估计。在位姿估计模块中,会持续监控跟踪的质量;如果图像中的可观测值数量低于某个阈值,或者如果连续图像间的特征数量下降过快,跟踪质量就不好,失效恢复就会启动。
DT SLAM。DT SLAM基于3种跟踪模式维护相机位姿:全位姿估计,本质矩阵估计和纯旋转估计。如果有足够数量的3D匹配,就可以估计完全位姿;否则,如果有足够多的2D匹配,平移也小,就会估计一个本质矩阵;最后,如果出现纯旋转状况,就会用2点估计匹配的绝对方向。位姿估计模块进行迭代处理3D-2D重投影和2D-2D匹配的最小化误差向量。如果跟踪丢失,系统就初始化一个新地图,继续收集数据跟踪一个不同的地图;然而,地图构建线程会继续查找新地图的关键帧和老地图之间的匹配,一旦匹配好后,两个地图就融合在一起,因此系统可以在不同的尺度上处理多个子图。
LSD SLAM。LSD SLAM里的跟踪线程负责用前一帧位姿作为先验信息根据当前活动关键帧估计当前位姿。要求的位姿用SE(3)变换表示,通过迭代再加权高斯-牛顿优化最小化归一方差光度残差得到结果,如Engel论文所述,是在地图中的当前帧和活动关键帧之间处理。如果最新的关键帧正在地图中处理,这个关键帧被认为是激活的。为了最少化离群点,具有比较大残差的观测值在迭代过程中会被分配越来越少的权重。
ORB SLAM。ORB SLAM中的位姿估计通过一个恒定速度的运动模型为先验知识,然后用优化方法来作位姿优化。运动模型很容易受到剧烈运动的损伤,ORB SLAM会跟着匹配的特征点来检测这样的失效状况;如果低于某一个阈值,地图点云会被投影到当前帧,就会在投影位置附近展开更大范围的特征搜索。如果跟踪失败,ORB SLAM就会激活失效恢复方法通过全局重定位构建一个初始相机(帧)位姿。
为了使ORB SLAM能够在大场景中运行,全局地图的一个子集,即局部地图,用所有路标对应的所有和当前关键帧有相同的边缘的关键帧的一组集合和位姿图中这组关键帧的所有邻居来定义。选择好的路标再进行过滤以确保只有更可能匹配的特征保留在当前帧中。还有,如果从相机中心到路标的距离大于有效特征的尺度范围,路标就会被丢弃。接着继续搜索剩下的这组路标与当前帧匹配,最后才是相机位姿优化。
DPPTAM。与LSD SLAM类似,DPPTAM用ICIA算法通过关联的SE(3)变换优化两幅图像间高梯度像素位置的光度误差。最小化从使用一个恒定速度运动模型开始,除非光度误差增加。如果真的发生了这种情况,运动模型就会被放弃,转而使用上一次跟踪帧的位姿。与PTAM是在正切空间Sξ(3)优化类似,用最小化参数法处理6个参数的刚体变换。
地图生成模块将世界表示成稠密(直接)或稀疏(间接)的点云。图10是地图生成模块的一般流程。系统将2D兴趣点三角化成3D路标,并持续跟踪3D坐标,然后定位相机,这就是量度地图。但是,相机在大场景运行时,量度地图的大小就会无限增大,最终导致系统失效。

图10 地图生成的一般流程
拓扑地图可以减少这一弊端,它尽量将地图中的量度信息最小化,减少几何信息(尺度,距离和方向)而采用连接信息。视觉SLAM中,拓扑地图是一个无向图,节点通常表示关键帧,关键帧通过边连接,节点之间存在相同的数据关联。
拓扑地图与大场景的尺度比较吻合,为了估计相机位姿,也需要量度信息;从拓扑地图到量度地图的变化并不是一件容易的事情,因此,最近的视觉SLAM系统都采用混合地图,局部量度地图和全局拓扑地图。混合地图的实际设计可以使系统: (1) 在高层次上理解世界,拓扑信息用于回环闭合和失效恢复更有效率;(2)将地图范围限制到相机周围的局部区域可以增加量度位姿估计的效率。混合地图使得局部优化量度地图的同时可以维护全局拓扑地图的大规模优化。
在量度地图中,地图制作过程会处理新路标将其添加到地图中,还检测和处理离群点。场景的3D结构可以从已知的2幅图像的变换和对应的数据关联中获得。由于数据关联和图像的位姿估计的噪声,关联特征的投影射线在3D空间中可能不会相交。图11显示了优化的三角化方法,估计对应特征的路标位姿,可以最小化两帧的重投影误差e1和e2优化。为了对离群点更有弹性,获得更好的精度,有些系统采用了相似的特征优化,这些特征关联的图像超过2个视图。
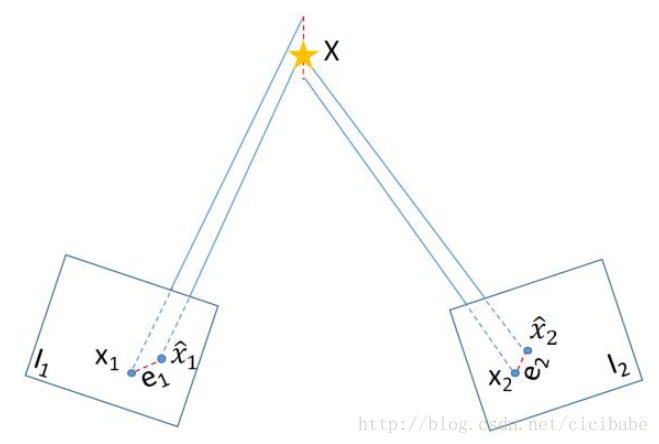
图11 优化路标三角化

图12 基于滤波方法的路标估计
图12所示,基于滤波的路标估计技术恢复路标位置,使用的是用路标位置估计的均匀分布(D1)填入粒子滤波中的方法,作为路标可以在多个视图中观测到,并持续更新。这一过程会一直持续直到滤波从均匀分布到小方差(D3)的高斯分布收敛。在这种类型的路标估计中,离群点很容易被识别为路标,这些离群点的分布基本保持为均匀分布。在路标用于位姿跟踪之前,基于滤波的方法会产生时间延迟,与优化方法中一旦路标从两视图三角化后就使用的三角化方法的状况不同。
这些方法的主要局限是它们需要图像中可观测特征间的基线,当相机是纯旋转状态时,比较容易失效。为了控制这样的失效模式,DT SLAM 在将它们三角化成3D路标之前就引入2D地图路标。
表6总结了不同视觉SLAM的地图生成方法,主要有两种方法:优化方法的三角化(PTAM和ORB SLAM)和基于滤波的路标估计(SVO,LSD SLAM和DPPTAM)。

表6 地图生成
PTAM。在PTAM中,当加入一个新关键帧时,所有的捆集调整操作都挂起,新的关键帧从粗糙跟踪阶段继承了位姿。跟踪器估计的一组潜在可视化路标,就被重投影到新的关键帧上,构建特征匹配。正确匹配的路标再次标记为已知;这样就完成了对路标质量的跟踪,就可以在地图优化步骤中删除崩溃的数据。
创建并三角化新加入的关键帧和地图中和它最近邻的关键帧(位置上最邻近)之间的特征匹配可以生产新的路标。地图中已经存在的路标被投影到两个关键帧上,沿着它们的对应极线在其他关键帧中没有包含投影路标的区域中从当前关键帧搜索特征匹配。投影路标的平均深度用于约束从线到面的对极搜索;这就限制了搜索的计算成本,避免再将路标添加到附近已经存在路标的区域。然而,这也将新建的路标限制到对极区域中,因此场景深度的巨大变化也可能导致可能的路标被忽略。
SVO。SVO中地图生成线程与跟踪线程并行运行,负责创建和更新地图。SVO用一个逆深度参数化模型参数化3D路标。插入新关键帧时,拥有最高Shi-Tomasi分值的特征被选用初始化深度滤波器。这些特征被标记为种子,从相机中心到原有关键帧中的种子2D位置繁殖出直线上进行初始化。剩下的需要解决的参数就是路标的深度,初始值是场景深度的平均值,是从原来关键帧中观测的。
没有新关键帧处理的时候,地图管理线程监控并用新获得图像帧的后续观测值中更新地图种子。沿着对极搜索线搜索种子,受限于当前帧中种子的不确定性和平均深度分布。当滤波器收敛时,不确定性就会降低,对极搜索的范围也会降低。如果种子不能快速匹配,如果它们发散,或者如果初始化后过了很长时间,它们都会被认为是坏种子,都会从地图中删除。
当种子的分布从最初假定的均匀分布变成高斯分布时,滤波器就会收敛。种子就会被加入到地图中,高斯分布的均值就是深度值。但是,这个过程限制SVO的操作环境为深度分布相对平均的场所。SVO中路标初始化依赖于很多观测值因为特征需要被三角化,即使地图包含了离群点,也很少,因此不需要离群点检测。然而,在特征被初始化成路标添加到地图之前,会出现一些延迟。
DT SLAM。当有足够视图变化的时候,DT SLAM就会加入关键帧;关键帧加入的标准有三个:(1)图像帧,包含了足够数量的从地图中没有包含特征的区域中创建新的2D特征,或者(2)能够被三角化成3D路标的最少2D特征数量,或者(3)从明显不同的角度观测到的一个给定已有3D路标数量。地图同时包含了2D特征和3D路标,2D特征到3D路标的三角化使用的是两视图三角化,这个过程会被推迟直到观测的关键帧之间有足够的视差,这也就是这个算法的名字来源。
LSD SLAM。LSDSLAM的地图生成模块功能可以被分成两种主要类别,根据当前帧是否是关键帧,如果是的,关键帧保留的深度地图就会创建出来;如果不是的,深度地图就在常规图像上进行优化。为了保证跟踪质量,LSD SLAM要求频繁将关键帧添加到地图中去,也是要求高帧率的相机。
如果一个图像被标记为关键帧,从前一关键帧估计的深度地图就会投影过来,作为它的初始深度地图。以近邻观测的最小方差只作为方差、用环境值的平均值取代每个投影深度值,做空间归一化处理。
在LSD SLAM中,监控每个像素点是否是离群点的投影深度前提条件的概率来检测离群点。为了使离群点检测步骤可行,LSD SLAM记录在跟踪线程中所有成功匹配的像素,相应地增加或减少成为离群点的概率。
在一种直接的、尺度漂移敏感的图像配置流程中估计和优化新加入的关键帧的Sim(3),这个图像配置流程和跟踪线程中是一样的,但在地图中的其他关键帧,超过7自由度Sim(3)变换。
由于Sim(3)上直接图像配置的非凸性,就需要一个精确初始化的最小化过程;为了这个目的,ESM高效二阶最小化方法和一个由粗到细很低分辨率的金字塔算法可以增加任务的收敛半径。
如果地图生成模块认为当前图像不能作为关键帧,就在一个合适的参考帧中对每一个像素构建立体匹配优化深度地图。可以观察到像素的最老的关键帧决定了采用哪个参考帧,搜索范围和观测角度不会超过一定的阈值。对每个像素的1D对极线搜索用SSD方法。
为了最小化计算代价,减小地图中离群点的影响,不是所有的立体匹配都用于更新深度地图;相反,选择像素的一个子集,不一致搜索的精度就很大。精度由三个标准决定:光度不一致误差,几何不一致误差,像素与逆深度的比值。更多的细节可以参考Engel的论文。最后,深度图归一化和离群点处理,与关键帧处理步骤中的一样。
ORB SLAM。ORB SLAM的局部地图构建线程负责关键帧插入,地图点云三角化,地图点云裁减,关键帧裁减和局部捆集调整。关键帧插入负责更新covisibility和合适边的本质图,计算地图中词袋模型表示的新加入的关键帧。Co-visibility图是一个位姿图,系统中所有的关键帧用结点表示,与本质图不同,每个结点可以有两个或更少的边,每个结点只保留最强的两个边。地图点云创建模组三角化ORB特征生成了大量的路标,这些特征出现在co-visibility图中相连的关键帧中的两个或更多视图。测试三角化后的路标用于正深度值,重投影误差,所有关键帧的尺度一致性,为了将它们送入地图。
DPPTAM SLAM。DPPTAM SLAM中的路标三角化是用逆深度参数法处理几个重叠的场景观测值;地图制作是为了最小化最近添加的关键帧的高梯度像素区域和像素对应区域的光度误差,可以通过将特征从关键帧投影到当前帧中找到。当图像有比较大的平移时,为了找到高梯度像素,最小化过程要重复10次;平移的阈值就会在一次次迭代中增加以确保图像间足够的基线。最后的结果就是每个高梯度像素的深度值。为了减少最终的深度估计,会执行三个连续测试,包括梯度方向测试,时间一致性,空间一致性。
地图维护通过捆集调整或位姿图优化来优化地图。图13显示了视觉SLAM地图维护的一般流程。地图扩展的过程中,新的3D路标基于相机位姿估计进行三角化。经过一段时间的运行,由于相机累积误差增加,相机位姿错误,系统出现漂移。图14描述了地图维护的效果,场景地图通过去除离群点和误差最小化得到优化,产生一个更精确的场景表示。

图13. 地图维护的一般流程
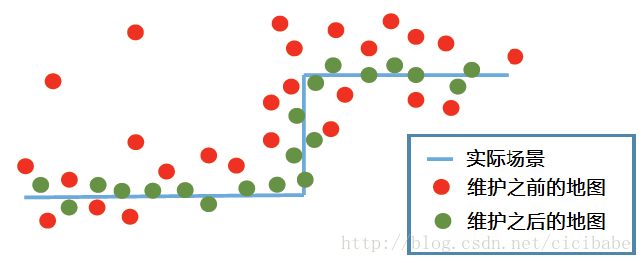
图14. 地图维护的效果
从运动恢复结构中继承的捆集调整,由非线性优化过程形成,用于优化一个视觉重建,联立产生一个最优结构和关联的相机位姿估计。如果对所有图像和位姿都执行捆集调整,计算量巨大、无法控制。PTAM使用了关键帧使得BA的应用有突破性的进展,只选择标记为关键帧的图像用作地图构建,并送入捆集调整过程中,与运动恢复结构方法中使用所有图像不同。不同的算法用不同的标准标记关键帧,捆集调整的策略也不同,有的使用局部(局部数量的关键帧)捆集调整和全局(整个地图)捆集调整,有的认为局部捆集调整已经可以足够维护一个高质量的地图。为了减小捆集调整的计算开销,Strasdat提出用欧式地图用于局部捆集调整和拓扑地图用于位姿图优化可以明显地将累积漂移分散到整个地图中的组合方式表示视觉SLAM地图。
位姿图优化相比全局捆集调整返回较差的结果。原因是位姿图优化只用于关键帧位姿优化,相应地调整路标的3D结构;全局捆集调整都优化关键帧位姿和3D结构。全局捆集调整以计算时间为代价,位姿图速度更快。然而,位姿图优化要求高效的回环闭合检测,在误差分布到整个地图中后可能不会生成一个最优结果,从而导致局部区域的不准确,但这些区域之前并没有错误。
地图维护也负责检测和删除地图中的由于噪声和错误特征匹配的离群点。由于大多数视觉SLAM算法的前提是环境是静态的,有的算法,比如RD SLAM采用地图维护方法处理变化缓慢的场景(光照和结构的变化)。
PTAM。PTAM中的地图制作线程和跟踪线程并行运行,不需要一帧一帧地操作;它只处理关键帧。当地图制作线程不处理新关键帧时,它执行各种地图优化和维护,比如局部地图收敛的局部捆集调整和地图全局收敛的全局捆集调整。PTAM中计算代价跟随地图变化,当关键帧数量增大时就无法处理;因为这个原因PTAM的设计是针对小型空间的。最后,优化线程通过第一次搜索优化数据,在所有关键帧中更新路标观测值,删除很多次都无法进行成功特征匹配的路标。
SVO。为了运行时效率原因,SVO的地图管理只维护了地图中固定数量的关键帧,当加入新关键帧时,删除较远的那个。这样操作的话,算法就可以在运行很长时间后仍可以保持实时性能。
DT SLAM。除了地图生成模块以外,DT SLAM采用了第3个线程在后台通过一个稀疏全局捆集调整持续优化整个地图。
LSD SLAM。LSD SLAM在后台运行了第3个并行线程优化地图,它采用的位子图优化的g2O框架。与前面所说的方法相比精度会差一些。
ORB SLAM。为了维护一个高质量的地图,并从关键帧中频繁添加特征,ORB SLAM采用了比较严格的路标裁减以确保地图中很少离群点。路标必须正确地匹配即将看到的图像的25%。当不止一个关键帧被用于构建地图后,路标必须至少在三个关键帧中可见。否则就删除路标。为了能长期运行,在地图中出现大量关键帧的情况下保持单边高效(计算复杂度,离群点,冗余),运行一个严格的关键帧裁减流程。关键帧中有90%的路标被其他3个关键帧观测到,就被认为是冗余的,需要删除。局部地图构建线程也运行一个局部捆集调整,其在co-visibility图中所有连接到最新关键帧的那些关键帧和其他所有可以在当前关键帧中观测到任何路标的关键帧中运行。
DPPTAM。DPPTAM没有像之前的系统那样使用优化,但它使用稠密地图构建线程生成了一个实时稠密地图,这个线程使用了人工室内场景的平面特征。关键帧先被分割到一组2D超像素中,地图中所有的3D路标投影到关键帧上,根据它们投影到关键帧中合适超像素的距离分配给不同的超像素。在3个测试条件决定是否将超像素平面添加到地图中之前,属于超像素轮廓的3D点云将3D平面和每个超像素匹配。测试包括(1)归一化内生测试,(2)退化情况的检测,(3)时间一致性。最终,用3D平面关联的超像素的深度先验信息估计每个像素的深度重构一个完全稠密地图。
表7总结了不同视觉SLAM系统采用的地图维护方法。

不管是错误的用户运动(相机位姿的剧烈改变和运动模糊),或者相机观测无特征的区域,还是无法匹配足够的特征,或者其他原因,视觉SLAM系统最终会失效。任何视觉SLAM可以用的一个关键模块是能够从这样的失效中恢复。
PTAM。检测失效时,PTAM的跟踪器会启动一个恢复程序,每个新进来的图像帧的最小模糊图像SBI会和所有关键帧的SBI数据库进行对比。如果新进来图像帧和它最近邻看到的关键帧之间的亮度差低于某一个阈值,当前帧的位姿被认为和那个对应的关键的相同。ESM跟踪就会启动(与跟踪线程相似)用于估计关键帧和当前图像帧之间的旋转变化。如果融合好了,地图中路标的PVS投影到估计的位姿上,跟踪器会尝试匹配路标和图像帧上的特征。如果有足够特征被正确匹配好了,跟踪器就继续运行,否则就需要一个新的图像帧,跟踪器还会跟丢。对于成功的重定位,这个方法要求丢失的相机位姿靠近已知的关键帧位姿,否则当两者之间有偏移时就会失效。
SVO。跟踪质量不好的时候,SVO就启动失效恢复。失效恢复的第一个步骤是做新进来的图像帧和已知上一次正确跟踪的图像帧之间的图像对准。如果在图像对准步骤中,有超过30个特征正确匹配了,重定位器就自动融合,继续常规跟踪;否则,它就尝试用新进来的图像重新定位。这样的重定位器对场景的光照改变敏感,为了成功的重定位,丢失图像帧的位置应该和检索的关键帧足够近。
LSD SLAM。LSD SLAM的恢复流程首先从地图中选择一个随机的关键帧,它在位姿图中有超过两个近邻关键帧连着它。然后,它尝试和当前丢失的图像帧对准。如果离群点与内点的比值太大,关键帧就随机再更换一个;否则,所有位姿图中连接的关键帧都会被检测一遍。如果大比值的内点比离群点比率的邻居数量大于大比值的离群点比内点比率,或者如果有超过有大比值的内点比离群点比率的5个邻居,有大比值的相邻关键帧就被设置为活动关键帧,常规的跟踪就会继续运行。
ORB SLAM。跟踪失效触发恢复后,ORB SLAM激活全局位置识别模块。重定位器将当前图像帧转换成词袋向量,在关键帧数据库中检索可能用于重定位的关键帧。ORB SLAM中的位置识别模块,同时用于回环检测和失效恢复,主要依靠词袋向量,词袋向量是指同一场景下的图像有大量相同的视觉字典。与其他从关键帧数据库中检索返回最优解的词袋向量不同,ORB SLAM中的位置识别返回所有可能的解,它们都有可能存在最好匹配的75%。ORB特征的优势,还有词袋向量的位置识别模块,使得系统可以实时,频繁操作,在重定位和回环检测中对视角变换有较高的容差。所有解都用PnP算法的RANSAC实现来检测,PnP算法得到了一组3D到2D匹配的相机位姿。已经找到的相机位姿有最多内点用于构建候选关键帧上更多的特征匹配,在这之前要使用构建好的匹配优化相机位姿。
表8总结了不同视觉SLAM系统的失效恢复机制。

视觉SLAM是一个优化问题,在相机位姿估计中容易漂移。如图15所示,经过了一段时间的运行后,当回到运行起点时,返回的位姿可能和最初的相机位姿观测值不一样。这样的相机位姿漂移使得在地图尺度漂移中最终导致系统出现错误观测,并失效。为了解决这个问题,有的算法在线检测回环闭合,优化回环跟踪,矫正漂移,和相机位姿误差,在回环过程中所有地图相关的过程都进行处理。回环闭合线程在插入新关键帧时尝试构建一个闭环,为了纠正和最小化任何系统运行累积的漂移。
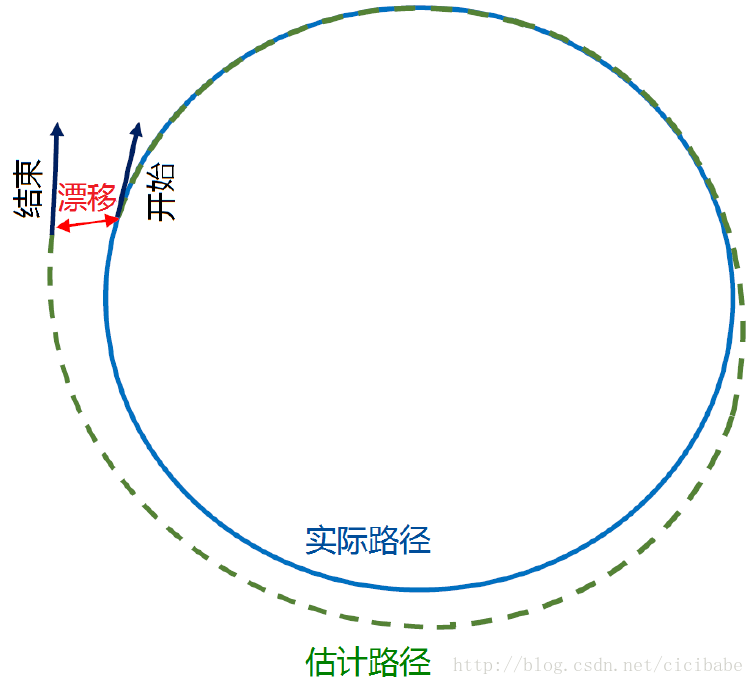
图15. 视觉SLAM位姿估计返回起始点的漂移
LSD SLAM。无论LSD SLAM什么时候处理关键帧,回环闭合都在它最近的10个关键帧中搜索,也搜索基于FABMAP模型的外观方法构建回环终点。一旦回环边缘检测到,一个位姿图优化就会最小化在回环边缘将误差分布到整个回环关键帧位姿上构建的相似度误差。
ORB SLAM。ORB SLAM中的回环检测使用全局位置识别模块,从数据库中返回所有可能和回环另外一端匹配的关键帧。为了确保有明显的距离变化,它们根据co-visibility图中阈值计算当前关键帧和所有关键帧的相似度变换。如果相似度值低于阈值,就删除回环的候选关键帧。如果有足够的内点支撑优化相似变换,检索到的关键帧就被认为是回环的另外一端,就会产生回环融合。
回环融合首先合并关键帧中重复的地图点云,在covisibility图中插入一个新的边,用相似变换校准当前关键帧的Sim(3)位姿来闭合回环。所有检索到的关键帧的路标和它们的近邻投影的矫正关键帧,在covisibility图中和当前关键帧关联的所有关键帧进行搜索。最初的内点集合和找到的匹配用于更新covisibility和本质图,在回环两端构建很多边。最后,本质图上的位姿图优化与LSDSLAM相似,沿着回环结点分布回环闭合误差,最小化回环误差。
表9总结了不同视觉SLAM的回环闭合机制。

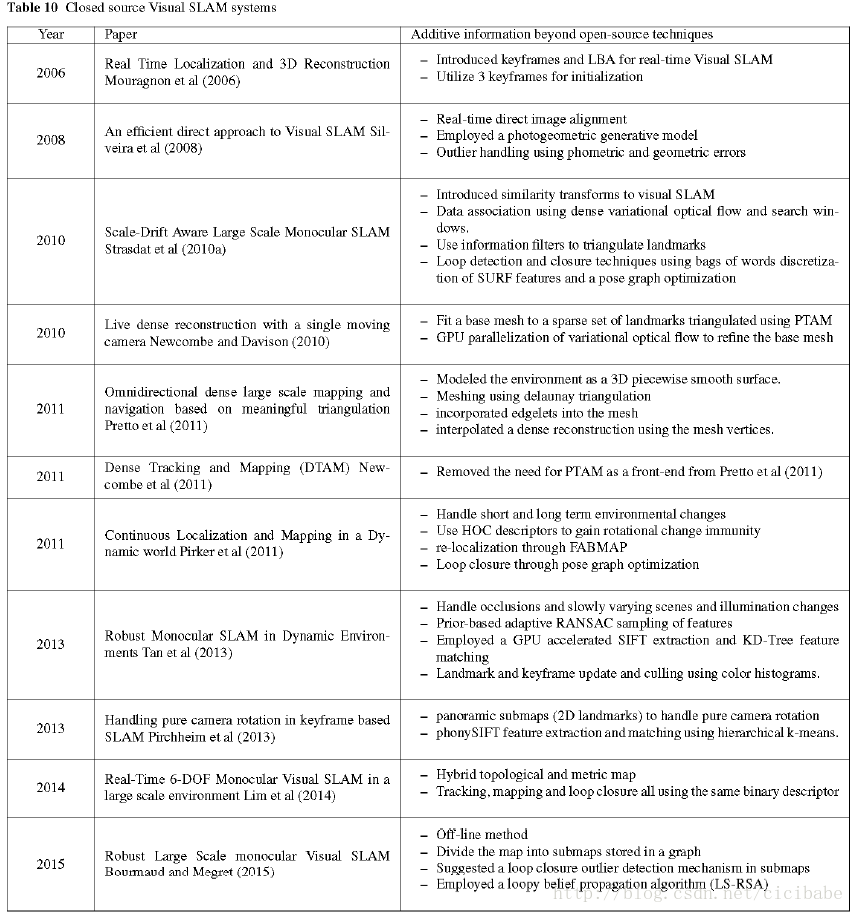
四 非开源系统
前面讨论的是开源视觉SLAM系统;也有大量的闭源系统。本章将迅速浏览这些系统,包含了很多有意思的思路。表10按时间顺序列出了这些系统。为了避免重复,我们不讨论每个系统的详细细节;更多地关注除第3章介绍的信息之外的附加价值。2006年,Mouragnon在视觉SLAM中第一次引入了关键帧的思想,在地图中一组关键帧子集采用了实时局部捆集调整。为了确保足够的基线,系统自动插入3个关键帧进行初始化。但是系统并没有用这3个视图进行初始化,而是用第1个和第3个关键帧的5点算法进行初始化,容易受到平面场景的影响。
2008年,Silveira提出了实时直接方案,假定高亮度梯度像素包围的区域大片局部区块为平面,最小化新进图像的区块的光度误差进行图像配准,在单个优化步骤中,整合了Cheirality,几何和光度约束。为了对光照变化和离群点获得弹性,系统采用光度生成模型,监控最小化过程中的误差用来标记离群点。
2010年,Strasdat介绍了视觉SLAM的相似度变换,一旦系统检测到回环闭合后就可以估计和校正尺度偏移估计。特征跟踪用一个稠密多元光流法和投影的路标周围的一个窗口搜索执行一个自定往下和自下往上的混合方法。更新信息滤波三角化路标,用SURF特征词袋向量执行回环检测。回环最终用关键帧的相似变换进行位姿图优化。
还是2010年,Newcombe和Davison,提出了一种混合视觉SLAM系统,用基于特征的SLAM(PTAM)适用于环境的稠密表面估计,用直接法进行优化。表面模型计算和多边形化很好地适用于基于特征的前端三角化的路标。一个并行处理流程选择有重叠的表面可视区域的一批图像用于GPU加速的多元光流法估计稠密优化。
2011年,Newcombe发布了DTAM更新了这个工作,删除了PTAM前端,用稠密重建完全解决视觉SLAM流程,用整个图像配准过程中找到的相机位姿估计进行在线稠密重建。
与2011年Newcombe工作类似,Pretto对环境建模形成一个平滑表面,用前端提供的稀疏特征作为基础用于三角剖分以适配用于插入环境的稠密重建用的网格。
2011年Pirker发布了CD SLAM主要是处理环境的短期和长期变化问题,处理室内室外混合问题。为了限制地图大小,获得对剧烈旋转变化的鲁棒性,CD SLAM建议使用改良的HOC描述子,用GPU加速描述子更新,用概率权重处理离群点。还有,它建议用尺度偏移矫正处理大规模回环闭合,在回环闭合后使用光度更新特征描述子。关键帧在位姿图中没有顺序,没有权重。用最小二乘法初始化进行重定位,地图中最优匹配的候选关键帧的位姿用FABMAP查找;回环闭合用位姿图优化。
2013年Tan发布了RD SLAM,为了处理遮挡,缓慢变化的,活动的场景。RD SLAM采用了大量并行GPU加速的SIFT,将它们存储在KD树中,可以在树中检索最近邻加速特征匹配。为了处理动态物体(移动的)和缓慢变化的场景,RD SLAM提出了一种基于先验信息的适应性RANSAC算法采样特征,基于前一图像中特征离群点与特征的比值,在当前图像中和路标和关键帧裁剪机制一起估计相机位姿中得到的特征,在有稀疏暂时遮挡路标时,用颜色直方图检测更新变化的图像位置。
2013年,Pirchheim构建了局部全景地图处理相机的纯旋转问题,无论系统什么时候进入一个纯旋转的新场景。系统提取phonySIFT描述子,通过层次k-means聚类加速匹配。在位姿估计过程中没有观测到足够的3D路标,系统进入纯旋转估计模式,构建一个全景地图,直到相机观测到部分常规地图。
2014年,Lim处理跟踪,地图构建和回环检测,都适用了相同的二值特征,使用的是混合地图。无论什么时候检测到回环,地图都被转换成量度地图,在变换成拓扑地图之前,进行局部捆集调整。
2015年,Bourmaud发布了一个离线视觉SLAM系统(需要2.5小时处理一个10000个图像数据集)。系统采用分而治之的策略,将地图分成子图。在子图和最邻近10个邻居之间估计相似变换。每个子图和一个全局参考帧的全局相似变换,用位姿图优化计算,参考帧存储在子地图图中。上面的过程在回环检测中容易受到离群点的影响,需要一个高效的离群点处理机制。为了这个目的,阻止离群点,内点一直计算连续的相似度。在最短的回环中加入相似度执行离群点剔除模块,模块监控闭合误差以确认是否接受回环。为了处理大量子图,一个回环置信繁殖算法将主图切成子图,再进行非线性优化。
五 结论
本文列出了视觉SLAM系统的一般结构;包括数据类型,初始化,数据关联,位姿估计,地图生成,地图维护,失效恢复和回环闭合。讨论了最新开源系统的一些细节。最后总结了闭源系统的一些附加的信息。
尽管这个领域的研究一直在进行,我们认为每个模块都有改进空间。对光照变化,动态场景和环境遮挡鲁棒的数据关联,无需假设初始化场景、无需处理大量图像的初始化方法,不会受到剧烈运动、模糊、噪声、大幅深度变化或移动物体的精确相机位姿估计; 能够在很少纹理区域中生成有效稠密场景表示的地图构建模块,能够增强地图对动态、变化的大小规模环境弹性的地图维护方法;一个能从相机视角大幅变化中恢复系统的失效恢复流程,这些都是大多数系统所缺少的,仍然有很大挑战的主题。
我们做了大量实验,满足每个开源系统的要求,比如初始化,相机帧率,深度同态。在完成这些实验的时候,我们比较了所有开源视觉SLAM系统很好的识别出每个系统模块的优缺点。长期目标是应用这些优点制作一个强有力的非滤波方法的视觉SLAM系统。
非滤波方法的单目视觉SLAM系统
A survey on non-filter-based monocular VisualSLAM systems
Taylor Guo, 2016年9月12日 -2017年4月12日@EJU Shanghai
参考文献
AlahiA, Ortiz R, Vandergheynst P (2012) Freak: Fast retinakeypoint. In: Computer Vision and Pattern Recognition(CVPR), 2012IEEE Conference on, pp 510–517, DOI 10.1109/CVPR.2012.6247715
BakerS, Matthews I (2004) Lucas-Kanade 20 Years On:A Unifying Framework. International Journal of Computer Vision56(3):221–255
BayH, Ess A, Tuytelaars T, Van Gool L (2008) Speeded-up robustfeatures (surf). Comput Vis Image Underst 110(3):346–359, DOI10.1016/j.cviu.2007. 09.014, URL http://dx.doi.org/10.1016/j.cviu. 2007.09.014
BeaudetPR (1978) Rotationally invariant image operators. In: International Conferenceon Pattern Recognition
BenhimaneS, Malis E (2007) Homography-based 2DVisual Tracking and Servoing. International Journalof Robotics Research 26(7):661–676
BentleyJL (1975) Multidimensional Binary Search Trees Used for Associative Searching.Communications ACM 18(9):509–517
BourmaudG, Megret R (2015) Robust large scale monocular visual slam. In: ComputerVision and Pattern Recognition (CVPR), 2015 IEEE Conference on, pp 1638–1647,DOI 10.1109/CVPR.2015.7298772
CalonderM, Lepetit V, Ozuysal M, Trzcinski T, Strecha C, Fua P (2012) Brief: Computing a localbinary descriptor very fast. IEEE Transactions on Pattern Analysisand Machine Intelligence 34(7):1281–1298, DOI 10.1109/TPAMI.2011.222
CastleRO, Klein G, Murray DW (2008) Video-rate Localizationin Multiple Maps for Wearable Augmented Reality. In: Proc 12thIEEE Int Symp onWearable Computers, pp 15–22
CelikK, Somani AK (2013) Monocular vision slam for indoor aerial vehicles. Journalof Electrical and Computer Engineering 2013:15, URLhttp://dx.doi.org/10.1155/2013/374165%]374165
CiveraJ, Davison AJ, Montiel JM (2007) Dimensionless monocular slam. In: Proceedingsof the 3rd Iberian Conference on Pattern Recognition and Image Analysis, PartII, Springer-Verlag, Berlin, Heidelberg, IbPRIA ’07, pp 412–419, DOI10.1007/978-3-540-72849-8 52, URL http://dx.doi.org/10.1007/978-3-540-72849-8_52
CiveraJ, Davison A, Montiel J (2008) Inverse Depth Parametrization for MonocularSLAM. IEEE Transactions on Robotics 24(5):932–945
ClementeL, Davison A, Reid I, Neira J, Tard´os J (2007) Mapping Large Loops with aSingle Hand-Held Camera. Atlanta, GA, USA, URLhttp://www.roboticsproceedings.org/rss03/p38.html
ConchaA, Civera J (2015) Dpptam: Dense piecewiseplanar tracking and mapping from a monocular sequence. In:Intelligent Robots and Systems (IROS), 2015 IEEE/RSJ International Conferenceon, pp 5686–5693, DOI 10.1109/IROS.2015.7354184
DalalN, Triggs B (2005) Histograms of orientedgradients for human detection. In: Computer Vision andPattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on, vol1, pp 886–893 vol. 1, DOI 10.1109/CVPR.2005.177
DavisonA (2003) Real-time simultaneous localisation and mapping with a single camera.In: Ninth IEEE International Conference on Computer Vision, pp 1403–1410 vol.2
DavisonA, Cid YG, Kita N (2004) Real-time 3D SLAM with wide-angle vision. In: Proc.IFAC Symposium on Intelligent Autonomous Vehicles, Lisbon
DavisonAJ, Reid ID, Molton ND, Stasse O (2007) MonoSLAM: real-timesingle camera SLAM. Pattern Analysis and Machine Intelligence(PAMI), IEEE Transactions on 29(6):1052–67
EadeE, Drummond T (2006) Scalable monocular slam. In: Computer Vision and Pattern Recognition,2006 IEEE Computer Society Conference on, vol 1, pp 469–476, DOI10.1109/CVPR.2006.263
EadeE, Drummond T (2007) Monocular slam as a graph of coalesced observations. In:Computer Vision, 2007. ICCV 2007. IEEE 11th International Conference on, pp 1–8,DOI 10.1109/ICCV.2007.4409098
EngelJ, Sturm J, Cremers D (2013) Semi-dense Visual Odometry for a Monocular Camera.In: Computer Vision (ICCV), IEEE International Conference on, IEEE, pp1449–1456
EngelJ, Sch¨ops T, Cremers D (2014) LSD-SLAM: Large-Scale Direct Monocular SLAM. In:Fleet D, Pajdla T, Schiele B, Tuytelaars T (eds) Computer Vision – ECCV 2014 SE- 54, Lecture Notes in Computer Science, vol 8690, Springer InternationalPublishing, pp 834–849
EngelJ, Stuckler J, Cremers D (2015) Large-scale direct slamwith stereo cameras. In: Intelligent Robots and Systems (IROS),2015 IEEE/RSJ International Conference on, pp 1935–1942, DOI10.1109/IROS.2015.7353631
FaugerasO, Lustman F (1988) Motion and structure from motion in apiecewise planar environment. International Journalof Pattern Recognition and Artificial Intelligence 02(03):485–508
Fern´andez-MoralE, Ar´evalo V, Gonz´alez-Jim´enez J (2015) Hybrid Metric-topological Mapping for Large Scale Monocular SLAM .Springer International Publishing, pp 217–232
ForsterC, Pizzoli M, Scaramuzza D (2014) SVO : Fast Semi-Direct Monocular VisualOdometry. In: Robotics and Automation (ICRA), IEEE InternationalConference on
Fuentes-PachecoJ, Ruiz-Ascencio J, Rend´on-Mancha JM (2012) Visual simultaneouslocalization and mapping:a survey. Artificial IntelligenceReview 43(1):55–81,DOI 10.1007/s10462-012-9365-8, URLhttp://dx.doi.org/10.1007/s10462-012-9365-8
Galvez-L´opezD, Tardos JD (2012) Bags of Binary Words forFast Place Recognition in Image Sequences. Robotics, IEEETransactions on 28(5):1188–1197, DOI 10.1109/TRO.2012.2197158
GloverA, Maddern W, Warren M, Reid S, Milford M, Wyeth G (2012) OpenFABMAP: An opensource toolbox for appearance-based loop closure detection. In: 2012 IEEEInternational Conference on Robotics and Automation (ICRA), IEEE, pp 4730–4735
GrasaO, Bernal E, Casado S, Gil I, Montiel J (2014) Visual slam for handheldmonocular endoscope. Medical Imaging, IEEE Transactions on 33(1):135–146, DOI 10.1109/TMI.2013.2282997
HallBC (2015) Lie Groups, Lie Algebras, and Representations, vol 222, number 102edn. Springer- Verlag
HarrisC, Stephens M (1988) A combined corner and edge detector. In: In Proc.of Fourth Alvey Vision Conference, pp 147–151
HartleyR, Zisserman A (2003) Multiple View Geometry in Computer Vision. CambridgeUniversity Press
HartmannJ, Klussendorff JH, Maehle E (2013) A comparison of featuredescriptors for visual SLAM. In: Mobile Robots (ECMR), 2013 EuropeanConference on, pp 56–61, DOI 10.1109/ECMR.2013.6698820
HerreraD, Kannala J, Pulli K, Heikkila J (2014) DT-SLAM: DeferredTriangulation for Robust SLAM. In: 3D Vision, 2ndInternational Conference on, IEEE, vol 1, pp 609–616
HietanenA, Lankinen J, K¨am¨ar¨ainen JK, Buch AG, Kr¨ugerN (2016) A comparison of featuredetectors and descriptors for object class matching.Neurocomputing
HochdorferS, Schlegel C (2009) Towards a robust visual slam approach: Addressing thechallenge of life-long operation. In: Advanced Robotics, 2009. ICAR 2009.International Conference on, pp 1–6
HolmesSA, Klein G, Murray DW (2008) A square root unscented kalman filter for visualmonoslam. IEEE Transactions on Pattern Analysis and Machine Intelligence 31(7):1251–1263,DOI http://doi.ieeecomputersociety.org/10.1109/TPAMI.2008.189
HornBKP (1987) Closed-form solution of absolute orientation using unit quaternions.Journal of the Optical Society of America A 4(4):629–642
JeongW, Lee KM (2005) Cv-slam: a new ceiling vision basedslam technique. In:Intelligent Robots and Systems, 2005. (IROS 2005). 2005 IEEE/RSJ International Conferenceon, pp 3195–3200, DOI 10.1109/IROS.2005.1545443
J´erˆomeMartin JLC (1995) Experimental Comparisonof Correlation Techniques. In: IAS-4, International Conference onIntelligent Autonomous Systems
KleinG, Murray D (2007) Parallel Tracking andMapping for Small AR Workspaces. 6th IEEE and ACMInternational Symposium on Mixed and Augmented Reality pp 1–10
KleinG, Murray D (2008) Improving the Agility ofKeyframe-Based SLAM. In: Proc. 10th European Conference on ComputerVision (ECCV), Marseille, pp 802–815
KneipL, Siegwart R, Pollefeys M (2012) Finding the ExactRotation between Two Images Independently of the Translation, SpringerBerlin Heidelberg, Berlin, Heidelberg, chap Finding th, pp 696–709. DOI 10.1007/978-3-642-33783-3fng50, URL http://dx.doi.org/10.1007/978-3-642-33783-3{_}50
KonoligeK (2010) Sparse sparse bundle adjustment. In: Proceedings of the BritishMachine Vision Conference, BMVA Press, pp 102.1–102.11, doi:10.5244/C.24.102
KummerleR, Grisetti G, Strasdat H, Konolige K, Burgard W (2011) G2o: A generalframework for graph optimization. In: Robotics and Automation (ICRA), IEEEInternational Conference on, IEEE, pp 3607–3613
KwonJ, Lee KM (2010) Monocular slam with locally planar landmarks via geometricrao-blackwellized particle filtering on lie groups. In: Computer Vision andPattern Recognition (CVPR), 2010 IEEE Conference on, pp 1522–1529, DOI10.1109/CVPR.2010.5539789
LeeSH (2014) Real-time camera tracking using a particle filter combined withunscented kalman filters. Journal of Electronic Imaging 23(1):013,029, DOI10.1117/1. JEI.23.1.013029, URLhttp://dx.doi.org/10.1117/ 1.JEI.23.1.013029
LemaireT, Lacroix S (2007) Monocular-vision based slam using line segments. In:Robotics and Automation, 2007 IEEE International Conference on, pp 2791–2796,DOI 10.1109/ROBOT.2007.363894
LepetitV, Moreno-Noguer F, Fua P (2009) EPnP: An Accurate O(n) Solution to the PnPProblem. International Journal of Computer Vision 81(2):155–166
LeuteneggerS, Chli M, Siegwart RY (2011) Brisk: Binary robustinvariant scalable keypoints. In: Computer Vision(ICCV), 2011 IEEE International Conference on, pp 2548–2555, DOI10.1109/ICCV.2011.6126542
LimH, Lim J, Kim HJ (2014) Real-time 6-DOF monocular visual SLAM in a large-scaleenvironment. In: Robotics and Automation (ICRA), IEEE International Conference on,pp 1532–1539
LimJ, Frahm JM, Pollefeys M (2011) Online environment mapping. In: Computer Visionand Pattern Recognition (CVPR), 2011 IEEE Conference on, pp 3489–3496,DOI10.1109/CVPR.2011.5995511
LindebergT (1998) Feature detection withautomatic scale selection. Int J Comput Vision 30(2):79–116, DOI10. 1023/A:1008045108935, URL http://dx.doi.org/10.1023/A:1008045108935
LoweD (1999) Object recognition from localscaleinvariant features. In: International Conference on ComputerVision (ICCV), the seventh IEEE, IEEE, vol 2, pp 1150–1157 vol.2
LoweDG (2004) Distinctive image features from scaleinvariant keypoints. Int J Comput Vision 60(2):91–110, DOI10.1023/B:VISI.0000029664.99615.94, URL http://dx.doi.org/10.1023/B:VISI.0000029664.99615.94
LucasBD, Kanade T (1981) An Iterative ImageRegistration Technique with an Application to Stereo Vision. In:International Joint Conference on Artificial Intelligence -Volume 2, MorganKaufmann Publishers Inc., San Francisco, CA, USA, IJCAI’81, pp 674–679
MahonI, Williams SB, Pizarro O, Johnson-Roberson M (2008) Efficient view-based slamusing visual loop closures. IEEE Transactions on Robotics 24(5):1002–1014, DOI10.1109/TRO.2008.2004888
MairE, Hager GD, Burschka D, Suppa M, Hirzinger G (2010) Adaptive and GenericCorner Detection Based on the Accelerated Segment Test. In:Proceedings of the European Conference on Computer Vision (ECCV’10), DOI10.1007/978-3-642-15552-9fn g14
MatasJ, Chum O, Urban M, Pajdla T (2002) Robust wide baselinestereo from maximally stable extremal regions. In: Proc.BMVC, pp 36.1–36.10, doi:10.5244/C.16.36
MeltzerJ, Gupta R, Yang MH, Soatto S (2004) Simultaneous localization and mappingusing multiple view feature descriptors. In: Intelligent Robots and Systems, 2004.(IROS 2004). Proceedings. 2004 IEEE/RSJ International Conference on, vol 2, pp1550–1555 vol.2, DOI 10.1109/IROS.2004.1389616
MiglioreD, Rigamonti R, Marzorati D, Matteucci M, Sorrenti DG (2009) Use a singlecamera for simultaneous localization and mapping with mobile object tracking indynamic
environments
MorannaRa, Martin RD, Yohai VJ (2006) Robust Statistics. Wiley
MoreelsP, Perona P (2007) Evaluation of featuresdetectors and descriptors based on 3d objects. Int J ComputVision 73(3):263–284, DOI 10.1007/s11263-006-9967-1, URLhttp://dx.doi.org/10.1007/s11263-006-9967-1
MouragnonE, Lhuillier M, Dhome M, Dekeyser F, Sayd P (2006) Real time localization and3d reconstruction. In: Computer Vision and Pattern Recognition, 2006 IEEE ComputerSociety Conference on, vol 1, pp 363–370, DOI 10.1109/CVPR.2006.236
MujaM, Lowe DG (2009) Fast approximate nearest neighbors withautomatic algorithm configuration. In: In VISAPPInternational Conference on Computer Vision Theory and Applications, pp 331–340
Mur-ArtalR, Tard´os JD (2014) Fast relocalisation and loop closing in keyframe-basedslam. In: Robotics and Automation (ICRA), 2014 IEEE International Conference on,pp 846–853, DOI 10.1109/ICRA.2014.6906953
Mur-ArtalR, Montiel JMM, Tardos JD (2015) ORB-SLAM: A Versatile and Accurate MonocularSLAM System. IEEE Transactions on Robotics PP(99):1–17
NewcombeRA, Davison AJ (2010) Live dense reconstruction with a single moving camera.In: Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on,IEEE, pp 1498–1505
NewcombeRA, Lovegrove SJ, Davison AJ (2011) Dtam: Dense tracking and mapping inreal-time. In: Proceedings of the 2011 International Conference on Computer Vision,IEEE Computer Society, Washington, DC, USA, ICCV ’11, pp 2320–2327, DOI10.1109/ICCV.2011.6126513, URL http://dx.doi.org/10.1109/ICCV.2011.6126513
Nist´erD (2004) An efficient solution tothe five-point relative pose problem. Pattern Analysis andMachine Intelligence (PAMI), IEEE Transactions on 26(6):756–77
PiniesP, Tardos J (2008) Large-scale slam building conditionally independent localmaps: Application to monocular vision. Robotics, IEEE Transactions on24(5):1094–1106, DOI 10.1109/TRO.2008.2004636
PirchheimC, Reitmayr G (2011) Homography-based planar mapping and tracking for mobilephones. In: Mixed and Augmented Reality (ISMAR), 2011 10th IEEE International Symposiumon, pp 27–36, DOI 10.1109/ISMAR. 2011.6092367
PirchheimC, Schmalstieg D, Reitmayr G (2013) Handling pure camera rotation inkeyframe-based slam. In: Mixed and Augmented Reality (ISMAR), 2013 IEEEInternational Symposium on, pp 229–238, DOI 10.1109/ ISMAR.2013.6671783
PirkerK (2010) Histogram of oriented cameras - a new descriptor for visual slam indynamic environments. In:Proceedings of the British Machine Vision Conference, BMVAPress, pp 76.1–76.12, doi:10.5244/C.24.76
PirkerK, R¨uther M, Bischof H (2011) CD SLAM – Continuous localization and mapping ina dynamic world. In: IEEE International Conference on Intelligent RobotsSystems (IROS), IEEE, pp 3990–3997
PrettoA, Menegatti E, Pagello E (2011) Omnidirectional dense large-scale mapping andnavigation based on meaningful triangulation. In: Robotics and Automation (ICRA),2011 IEEE International Conference on, pp 3289–3296, DOI10.1109/ICRA.2011.5980206
PupilliM, Calway A (2005) Real-time camera tracking using a particle filter. In: InProc. British Machine Vision Conference, pp 519–528
Rey-OteroI, Delbracio M, Morel J (2014) Comparing feature detectors: A bias in therepeatability criteria, and how to correct it. CoRRabs/1409.2465, URL http://arxiv.org/abs/1409.2465
RostenE, Drummond T (2006) Machine Learning forHighspeed Corner Detection. In: 9th European Conference on ComputerVision - Volume Part I, Proceedings of the, Springer-Verlag, Berlin,Heidelberg, ECCV’06, pp 430–443
RubleeE, Rabaud V, Konolige K, Bradski G (2011) ORB: An efficientalternative to SIFT or SURF. In: International Conference on ComputerVision (ICCV), pp 2564–2571
ScaramuzzaD, Fraundorfer F (2011) Visual odometry[tutorial].IEEE Robotics Automation Magazine 18(4):80–92,DOI10.1109/MRA.2011.943233
ShiJ, Tomasi C (1994) Good features to track. In: ComputerVision and Pattern Recognition, 1994. Proceedings CVPR ’94., 1994 IEEE ComputerSociety Conference on, pp 593–600
SilveiraG, Malis E, Rives P (2008) An efficient direct approach to visual slam.Robotics, IEEE Transactions on 24(5):969–979, DOI 10.1109/TRO.2008.2004829
SmithP, Reid I, Davison A (2006) Real-time monocular slam with straight lines. pp17–26, URL http://hdl.handle.net/10044/1/5648
StrasdatH, Montiel J, Davison A (2010a) Scale drift-aware large scale monocular slam.The MIT Press, URL http://www.roboticsproceedings.org/rss06/
StrasdatH, Montiel JMM, Davison AJ (2010b) Real-time monocular SLAM: Why filter? In:Robotics and Automation (ICRA), IEEE International Conference on, pp 2657–2664
StrasdatH, Davison AJ, Montiel JMM, Konolige K (2011) Double Window Optimisation forConstant Time Visual SLAM. In: International Conference on Computer Vision, Proceedingsof the, IEEE Computer Society,Washington, DC, USA, ICCV ’11, pp 2352–2359
TanW, Liu H, Dong Z, Zhang G, Bao H (2013) Robust monocular SLAM in dynamicenvironments. 2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR)pp 209–218
TomasiC, Kanade T (1991) Detection and Tracking ofPoint Features. Tech. rep., International Journal of Computer Vision
TorrP, Fitzgibbon A, Zisserman A (1999) The Problem of Degeneracy in Structure andMotion Recovery from Uncalibrated Image Sequences. International Journal of ComputerVision 32(1):27–44
TorrPHS, Zisserman A (2000) MLESAC. Computer Vision and Image Understanding78(1):138–156
WagnerD, Reitmayr G, Mulloni A, Drummond T, Schmalstieg D (2010) Real-time detectionand tracking for augmented reality on mobile phones. Visualization and ComputerGraphics, IEEE Transactions on 16(3):355–368,DOI 10.1109/TVCG.2009.99
WeissS, Achtelik MW, Lynen S, Achtelik MC, Kneip L, Chli M, Siegwart R (2013)Monocular vision for long-term micro aerial vehicle state estimation: Acompendium. Journal of Field Robotics 30(5):803–831, DOI 10.1002/rob.21466, URLhttp://dx.doi.org/10.1002/rob.21466
WilliamsB, Reid I (2010) On combining visual slam and visual odometry. In: Proc.International Conference on Robotics and Automation
YousifK, Bab-Hadiashar A, Hoseinnezhad R (2015) An overview to visual odometry andvisual slam: Applications to mobile robotics. Intelligent Industrial Systems 1(4):289–311
ZhouH, Zou D, Pei L, Ying R, Liu P, Yu W (2015) Structslam: Visual slam withbuilding structure lines. Vehicular Technology, IEEE Transactions on64(4):1364–1375, DOI 10.1109/TVT.2015.2388780

















 5095
5095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









