







随着人工智能技术的飞速发展,许多用户希望在本地部署大型语言模型(LLM)以提升性能并保护数据隐私。 本文将指导您在3分钟内,通过Ollama、DeepSeek和ChatBox,完成从模型下载到可视化交互的全流程,实现完全离线的AI助手部署。
一、工具准备:Ollama与ChatBox
-
安装Ollama
Ollama是一款专为本地化设计的开源工具,支持一键部署多种大模型。 请访问Ollama官网(https://ollama.com/download)下载适用于您操作系统的安装包。 安装完成后,在命令行输入
ollama --version验证安装成功(应显示版本号)。
-
下载ChatBox
ChatBox是一款轻量级AI交互客户端,支持本地模型连接。 您可以从ChatBox官网(https://chatboxai.app/zh)或GitHub仓库下载安装包,支持全平台。
二、模型部署:一键拉取DeepSeek
-
选择模型版本
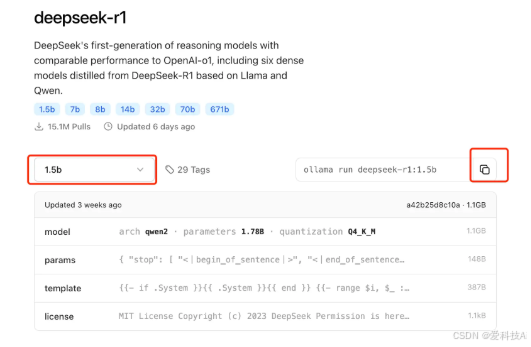
DeepSeek提供不同参数量级的模型,如1.5B(低配设备)、7B(均衡性能)、32B(高性能需求)、70B或671B(科研)。 根据您的硬件配置,选择适合的模型版本。 例如,若您的设备性能有限,可选择1.5B版本。
-
拉取模型
打开终端,执行以下命令(以1.5B为例):
ollama pull deepseek-r1:1.5b下载完成后,输入
ollama list查看已安装模型。
三、可视化交互:ChatBox连接配置
-
启动Ollama服务
运行Ollama后,默认在本地端口11434启动API服务。 若未自动启动,可在命令行输入
ollama serve手动开启。 -
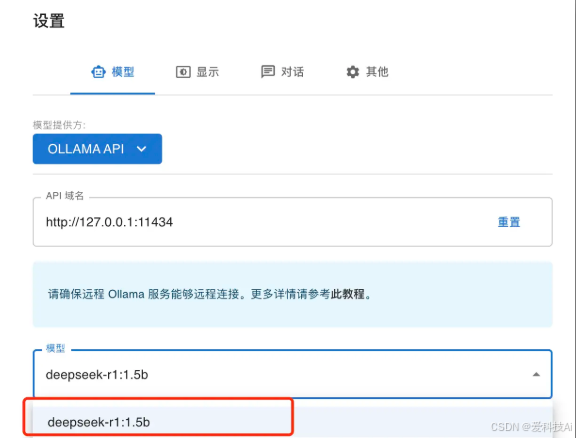
配置ChatBox
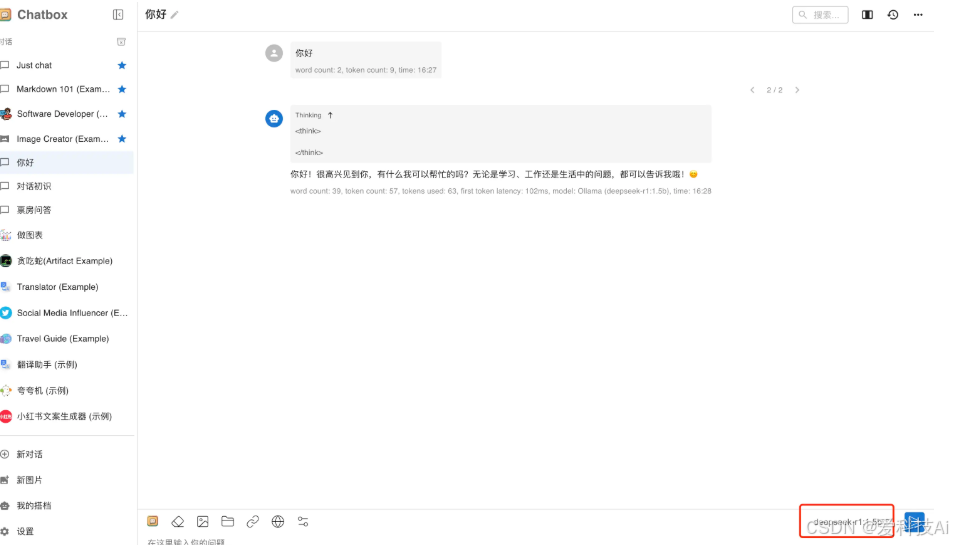
打开ChatBox,进入“设置” → “模型提供方”,选择“Ollama API”。 在API地址栏填写
http://127.0.0.1:11434,在模型列表中选择已下载的DeepSeek版本(如deepseek-r1:1.5b)。 点击“保存”后返回主界面,即可开始对话。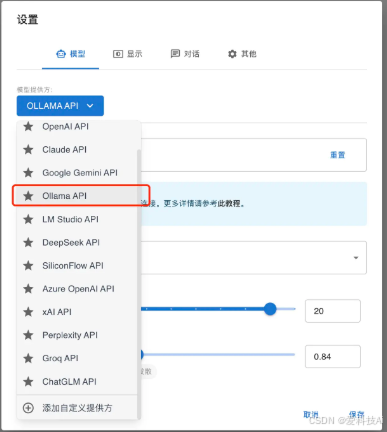
四、常见问题与解决方案
在使用Ollama、DeepSeek和ChatBox进行本地AI部署时,用户可能会遇到以下常见问题。以下是针对这些问题的详细解决方案:
1. 模型下载速度慢或连接错误
-
问题描述:在使用Ollama下载DeepSeek模型时,下载速度缓慢,甚至出现连接错误。
-
解决方案:
- 使用下载工具:建议使用迅雷等下载工具进行模型文件的下载,以提高下载速度。
- 更改下载源:如果Ollama默认的下载源速度较慢,可以尝试更改下载源或使用代理服务器。
- 检查网络连接:确保您的网络连接稳定,避免在下载过程中断开。
2. 模型无法在ChatBox中显示或连接失败
-
问题描述:在ChatBox中无法找到已下载的模型,或连接Ollama服务时出现错误。
-
解决方案:
- 确认Ollama服务运行:确保Ollama服务已启动,并在默认端口(11434)上运行。可以在命令行中输入
ollama list查看已安装的模型。 - 配置环境变量:在系统环境变量中添加
OLLAMA_MODELS,指向模型存储路径。 - 防火墙设置:检查防火墙设置,确保未拦截Ollama的端口。
- 确认Ollama服务运行:确保Ollama服务已启动,并在默认端口(11434)上运行。可以在命令行中输入
3. 显存不足导致模型加载失败
-
问题描述:在加载较大模型时,出现显存不足的错误提示。
-
解决方案:
- 选择适合的模型:根据您的硬件配置,选择适合的模型版本。例如,1.5B模型对硬件要求较低。
- 关闭其他占用显存的程序:在运行模型前,关闭其他占用显存的应用程序,以释放更多资源。
- 增加虚拟内存:在系统设置中增加虚拟内存,以缓解显存不足的问题。
4. ChatBox界面卡顿或响应迟缓
-
问题描述:在使用ChatBox时,界面卡顿或响应迟缓,影响使用体验。
-
解决方案:
- 更新ChatBox版本:确保您使用的是最新版本的ChatBox,旧版本可能存在性能问题。
- 调整模型参数:在ChatBox设置中,调整模型的响应速度和质量参数,以平衡性能和效果。
- 优化系统性能:关闭不必要的后台程序,释放系统资源,以提升ChatBox的运行效率。
5. 模型加载时间过长
-
问题描述:加载模型时,等待时间过长,影响使用体验。
-
解决方案:
- 预加载模型:在使用前,提前加载模型,以减少使用时的等待。
- 检查硬盘性能:确保模型存储在读写速度较快的硬盘上,避免因硬盘性能不足导致加载缓慢。
- 使用SSD:如果可能,将模型存储在SSD上,以提高加载速度。
6. GPU占用率为0%
-
问题描述:在使用GPU加速时,GPU占用率显示为0%,未能有效利用GPU资源。
-
解决方案:
- 安装CUDA:确保已安装与显卡兼容的CUDA版本,并配置正确。
- 更新显卡驱动:安装最新的显卡驱动,以确保与Ollama的兼容性。
- 检查Ollama配置:在Ollama的配置文件中,确保启用了GPU加速选项。
7. 模型推理结果不准确或不符合预期
-
问题描述:模型的推理结果不准确,或与预期不符。
-
解决方案:
- 调整模型参数:在ChatBox或Ollama中,调整模型的温度、最大生成长度等参数,以优化输出结果。
- 使用不同版本的模型:尝试使用不同参数量的模型,以找到最适合您需求的版本。
- 提供更清晰的输入:确保输入的提示语清晰明确,以引导模型生成更准确的结果。
结语
通过Ollama、DeepSeek和ChatBox的组合,您无需依赖云端服务即可实现高效、私密的AI交互。 无论是代码生成、文案创作,还是学术研究,这一方案均能提供稳定支持。 未来,随着模型轻量化技术的进步,本地化部署将成为AI普惠应用的重要方向。 立即动手体验,开启您的智能助手之旅吧!
参考资源:
- Ollama官网:ollama.com
- ChatBox下载:chatboxai.app/zh

















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









