








1. 评估方法
1、回归:RMSE(平方根误差)、MAE(平均绝对误差)、MSE(平均平方误差)、Coefficient of determination (决定系数R2)、 MAPE(平均绝对百分误差)、MSLE(均方根对数误差)等。
2、分类:混淆矩阵、精确率、召回率、准确率、F1值、ROC-AUC 、PRC、G-MEAN等。
3、聚类:兰德指数、互信息、轮廓系数等。
1.1 训练集与测试集
目标:对于模型/学习器的泛化误差(用来衡量一个学习机器推广未知数据的能力,即根据从样本数据中学习到的规则能够应用到新数据的能力。)进行评估;
专家样本:训练集+测试集
训练集:训练误差
测试集:测试误差
独立同分布&互斥 :用测试误差近似表示泛化误差
1.2 测试误差与泛化误差
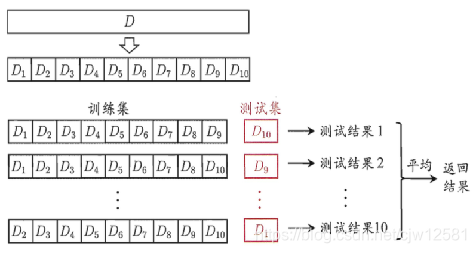
1.留出法
训练集+测试集:互斥互补
训练集训练模型,测试集测试模型
合理划分、保持比例(二八开)
单次留出与多次留出
多次留出法:如对专家样本随机进行100次训练集/测试集划分,评估结果取平均;
2.交叉验证法
K折交叉验证:将专家样本等份划分为K个数据集,轮流用K-1个用于训练,1个用于测试;
主要参数含义:
estimator:估计方法对象模型(分类器)
X:数据特征(Features):data属性值
y:数据标签(Labels):属性
soring:调用方法(包括accuracy和mean_squared_error等等)
cv:几折交叉验证
n_jobs:同时工作的cpu个数(-1代表全部)
from sklearn.model_selection import cross_val_score # 导入K折交叉验证函数
from sklearn.datasets import load_iris # 导入鸢尾花数据集
from sklearn.svm import SVC # 导入SVC支持向量机模型
iris = load_iris()
model = SVC(kernel='linear', C=1) # 构建支持向量机模型
a = cross_val_score(model, iris.data, iris.target, cv=5) # 5折交叉验证
print('K折交叉验证:', a)
# K折交叉验证: [0.96666667 1. 0.96666667 0.96666667 1. ]
留出法与交叉验证法的训练集数据少于样本数据;
3.自助法
给定m个样本的数据集D,从D中有放回随机取m次数据,形成训练集D’,用D中不包含D’的样本作为测试集。
D中某个样本不被抽到的概率:
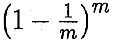
测试集数据量约为:
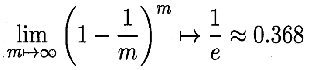
缺点:改变了初始数据集的分布
1.3 模型性能评估
评价方法与评价标准:
| 方法 | 标准 |
|---|---|
| 回归任务 | 均方误差 |
| 错误率与精度 | 错误率:分类错误样本数占总样本数比例;精度:1-错误率,分类正确样本数占总样本数比例 |
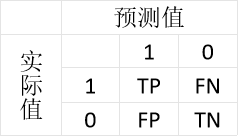
| 查准率与查全率 | 查准率/准确率(precision): P = TP/(TP+FP)查全率/召回率/灵敏度(recall):R = TP/(TP+FN);“1”代表正例,“0”代表反例 |
| F1系数 | 查准率与查全率的综合 |
| 均方误差公式: | |
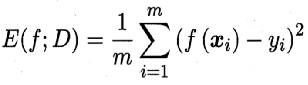 | |
| 错误率公式: | |
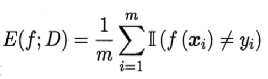 | |
| 精度公式: | |
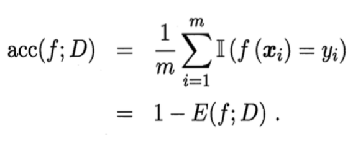 | |
| 查准率与查全率: | |
  | |
| F1系数: | |
| 综合查准率与查全率( β β β=1): | |
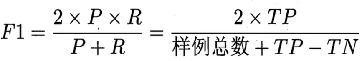 | |
| 一般的形式: | |
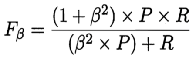 | |
| 其中, β β β为正数,度量了查全率对查准率的相对重要性: | |
| β β β=1:标准的F1系数; | |
| β β β>1:查全率有更大影响; | |
| β β β<1:查准率有更大影响; |
多次训练/测试时的F1系数:
先分后总:先分别计算各混淆矩阵的查准率和查全率,再以均值汇总;

先总后分:先将各混淆矩阵的对应元素(TP、FP、TN、FN)进行汇总平均,再求P、R、F1值

在机器学习领域,混淆矩阵(confusion matrix),又称为可能性表格或是错误矩阵。它是一种特定的矩阵用来呈现算法性能的效果,通常是监督学习(非监督学习,通常用匹配矩阵:matching matrix),就是对机器学习算法的运行结果进行评价,效果如何,精确度怎么样而已。
# -*- coding: utf-8 -*-
# 混淆矩阵可视化具体可参考数据挖掘与分析实例
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix # 导入混淆矩阵函数
cm = confusion_matrix(y, yp) # 混淆矩阵
import matplotlib.pyplot as plt # 导入作图库
plt.matshow(cm, cmap=plt.cm.Greens) # 画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。
plt.colorbar() # 颜色标签
for x in range(len(cm)): # 数据标签
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label') # 坐标轴标签
plt.xlabel('Predicted label') # 坐标轴标签
return plt
sklearn中的classification_report函数用于显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息。
主要参数:
y_true:1维数组,或标签指示器数组/稀疏矩阵,目标值。
y_pred:1维数组,或标签指示器数组/稀疏矩阵,分类器返回的估计值。
labels:array,shape = [n_labels],报表中包含的标签索引的可选列表。
target_names:字符串列表,与标签匹配的可选显示名称(相同顺序)。
sample_weight:类似于shape = [n_samples]的数组,可选项,样本权重。
digits:int,输出浮点值的位数.
from sklearn.metrics import precision_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
y_true = [1, 0, 1, 1, 0] # 样本实际值
y_pred = [1, 0, 1, 0, 0] # 模型预测值
a = precision_score(y_true, y_pred, average=None)
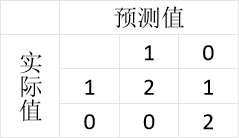
b = confusion_matrix(y_true, y_pred)
c = classification_report(y_true, y_pred)
print('查全率与查准率:', '\n', a)
print('混淆矩阵:', '\n', b)
print('主要分类指标的文本报告:', '\n', c) # 精确度,召回率,F1值
# 查准率与查全率:
# [0.66666667 1. ]
# 混淆矩阵:
# [[2 0]
# [1 2]]
# 主要分类指标的文本报告:
# precision recall f1-score support
#
# 针对0的预测情况:真实值中有2个0,预测值中有3个0,其中2个预测正确,1个预测错误。
# 0 0.67 1.00 0.80 2
# 1 1.00 0.67 0.80 3
#
# accuracy 0.80 5
# macro avg 0.83 0.83 0.80 5
# weighted avg 0.87 0.80 0.80 5
1.4 比较检验与偏差方差
测试误差能代表泛化误差吗?
根据大数定律,经验误差会收敛于泛化误差,两者(在一定容忍下)相近是由hoeffding不等式作为理论保证的,两者相差过大说明模型的欠拟合或者过拟合,偏差大:拟合不足/欠拟合;方差大:过拟合,而学习的一致收敛性说的正是这一特性:当训练集足够大,两者的结果就会足够相近。
泛化错误率的构成:偏差+方差+噪声
偏差:模型输出与真实值的偏离程度,刻画了算法的拟合能力;
方差:同样大小的训练集的变动导致的学习性能的变化,即数据扰动造成的影响;
噪声:当前学习器所能达到的泛化误差的下限;
END
















 1513
1513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











