







论文链接:Object as Query: Lifting any 2D Object Detector to 3D Detection
代码链接:https://github.com/tusen-ai/MV2D
作者:Zitian Wang,Zehao Huang,Jiahui Fu,Naiyan Wang,Si Liu
发表单位:北京航天航空大学人工智能学院、图森未来
会议/期刊:ICCV2023
一、研究背景
早期的单目 3D 对象检测方法通常按照 2D 对象检测流程构建框架。对象的 3D 位置和属性是从单视图图像直接预测的。尽管这些方法取得了巨大进步,但它们无法利用周围摄像机的几何配置和多视图图像对应关系,而这对于现实世界中物体的 3D 位置至关重要。此外,为了使这些方法适应多视图设置,需要依赖于复杂的跨相机后处理,这进一步导致效率和功效下降。为了解决这些问题,最近的研究人员提出基于多视图图像直接定位3D世界空间中的对象,为基于视觉的3D对象检测提供了新的范例。
根据融合特征的表示,当前的多视图3D目标检测方法主要可以分为两类:密集3D方法和稀疏查询方法。
(1)密集3D方法:将多视图特征渲染到 3D 空间中,例如鸟瞰 (BEV) 特征空间或体素特征空间。由于计算成本与 3D 空间的范围成正比,因此它们不可避免地无法扩展到大规模场景。
(2)稀疏查询方法:采用可学习的对象查询来聚合多视图图像的特征,并根据查询特征预测对象边界框。尽管固定数量的对象查询避免了 3D 空间的计算成本爆炸,但依赖于经验先验的查询数量和位置可能会在动态场景中导致误检或漏检。

作者指出了研究的动机:具有固定对象查询的 3D 检测器(固定查询意味着查询对于不同的输入是不变的)会错误定位或者忽略对象 (b),但 2D 检测器 (c) 可以成功检测到这些对象。如果基于 2D 检测器生成对象查询,3D 检测器可以生成更精确的位置 (d)。
因此,作者提出一种新颖的方法,即多视角2D物体引导的3D物体检测器(MV2D),旨在将任何2D物体检测器提升到多视角3D物体检测。通过利用2D物体检测方法的进步,这些方法可以生成高质量的2D边界框来定位图像空间中的物体,MV2D能够将这些检测转换为后续3D检测任务的参考,使用这些检测作为动态查询有效地定位3D空间中的物体,克服了以前方法的限制。
得益于强大的2D检测性能,2D检测结果生成的动态查询可以覆盖图像中出现的大多数物体,与固定查询相比,具有更高的精度和召回率,特别是对于小而远的物体。如图 1 所示,基于固定查询的 3D 检测器可能会错过的对象可以在 2D 对象检测器的帮助下在 MV2D 中重新调用。理论上,由于 3D 对象查询源于 2D 检测结果,因此该方法可以受益于所有现成的出色 2D 检测器改进。
论文贡献:
(1)提出了一个 MV2D 框架,可以将任何2D 对象检测器提升到多视图 3D 对象检测;
(2)实验证明,基于 2D 检测的多视图图像中某些相关区域的动态对象查询和聚合可以提高 3D 检测性能;
(3)在标准nuScenes 数据集上评估MV2D,它实现了最先进的性能。
二、相关工作
作者这里讨论一下2D检测、3D检测,重点在3D检测。
过去一部分个工作是基于单视图图像预测3D边界框,通过额外的深度预测模块来补充2D检测器的深度信息,但是在处理多视图图像的时候,这些方法需要从每个2D视图检测对象,并将它们投影到统一的3D空间,而且还要繁琐的NMS后处理来处理结果;
还有一部分的工作是从多视图角度出发,将2D图像提升到3D空间,再进行检测,例如通过建立3D体素化空间或使用BEV(鸟瞰图)表示。另一部分工作采用可学习的物体查询来从多视图图像中聚合特征,并基于查询特征预测物体,这一方法避免了随着3D空间范围增大导致的计算成本指数级增加的问题。
三、整体框架
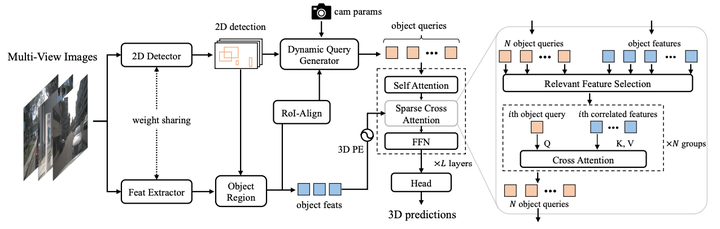
MV2D 的整体框架
给定输入的多视图图像,分别使用图像特征提取器提取图像特征、2D检测器获取每个视图的2D检测结果;动态查询生成器将图像特征、2D检测框和相机参数作为输入来初始化1组目标查询;其中,RoI-Align应用于目标区域以获得查询生成器的固定长度目标特征。落在对象区域中的所有特征都用 3D PE(3D 位置嵌入)进行装饰,然后将对象查询和对象特征输入到解码器以更新查询特征。与Vallina Transformer(就是最原始的ViT,香草味被认为是冰淇淋的原始口味,计算机界以此指代原版)解码器相比,MV2D 中的解码器采用稀疏交叉注意力,其中每个对象查询仅与其相关特征交互。最后,将预测头应用于更新的对象查询以生成 3D 检测结果。
总结如下:
-
多视角图像输入:MV2D框架以多个视角的图像为输入,这些图像捕捉了场景中物体的不同侧面和角度。
-
2D物体检测:首先,框架利用一个预训练的2D物体检测器对每个视角的图像进行处理,生成2D边界框。这些2D检测结果提供了物体存在的强证据以及它们在图像空间中的大致位置。
-
动态对象查询生成:基于每个2D边界框,框架生成一个动态的对象查询。这些查询是根据目标物体特征、2D检测结果和相机配置动态生成的,用于后续的3D定位。
-
相关特征选择:为了减少背景噪声和不相关信息的干扰,MV2D选取与每个目标查询相关的图像特征。这是通过比较不同视角中的2D检测框来完成的,旨在仅集中于含有目标物体的图像区域。
-
稀疏交叉注意力模块:利用相关的图像特征,每个对象查询通过一个带有稀疏交叉注意力机制的Transformer解码器进行更新。这个模块允许每个查询专注于特定对象的特征,从而提高定位准确性。
-
3D边界框预测:最后,基于更新后的对象查询,框架预测3D边界框,包括物体的3D位置、尺寸和方向。
四、核心方法
4.1 Dynamic Object Query Generation
借助有效的 2D 对象检测器,可以很好地证明对象的存在,并将对象位置限制在某些图像区域内,从而为在 3D 空间中定位对象提供有价值的先验。
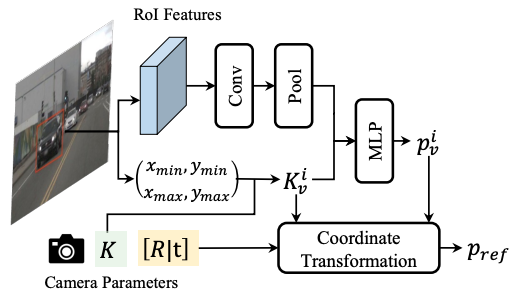
动态对象查询生成器
为了从 2D 检测生成对象查询,作者提出了一个动态查询生成器。
对于给定的所有图像2D目标检测结果 和图像特征图
,首先通过RoI-Align提取对象RoI特征 O,其中
表示与2D目标边界框
对应的RoI特征:
这里的 代表从第v张图像中提取到的RoI特征,
表示第v张图像中检测到的2D目标边界框数量,
表示RoI-Align操作后,每个RoI特征的高度和宽度,这是一个固定的尺寸,使得无论原始边界框的大小如何,提取出来的特征都是相同的维度,比如
;C就是特征图的通道数了。RoI特征图
, 每个特征图对应于图像中的一个物体。这些特征图后续将被用来生成动态对象查询,为3D物体检测提供必要的视觉信息。
虽然其具有足够的目标外观信息来推断图像空间中的对象中心位置。然而,直接从 RoI 特征进一步估计对象深度是很困难的。因为,当原始图像空间中的对象区域缩放为固定大小的 RoI 时,原始图像中包含的几何信息会丢失。考虑到这一点,作者对每个RoI应用等效的相机内参变换,这样做的目的是让不同RoI的重新缩放操作等同于具有不同相机参数的透视投影。因此,可以通过这些等效的相机内参将RoI坐标系统中的点变换到3D世界空间中。这个过程考虑到了相机的内在几何性质和相机观测到的3D世界之间的映射关系。
其中, (齐次坐标)表示RoI坐标系的2.5D点,也就是包括了图像平面的位置(x, y),深度信息z,还有一个额外的维度(通常是设为1)以便更好的进行矩阵变化;
表示3D世界空间中的点,
是RoI等效相机内参矩阵,用于将3D世界中的点投影到2D平面,在这里,每个RoI都有一个等效的内参矩阵,这个矩阵考虑了RoI相对于原图的缩放和位移,以模拟该RoI视角下的相机投影过程;[R|t]是相机的外参,由旋转矩阵R和平移向量t组成,描述了相机在3D世界空间中的位置和朝向,用于将3D世界中的点转换到相机坐标系中。
通过上面的公式,就将RoI坐标系统中的点转换成3D世界空间中的点。也就是利用相机的几何信息将图像上的点“还原”到其在真实世界中的位置,从而为后续的3D物体检测提供了一个基于实际观察的3D位置估计。
此外,RoI大小是 ,第v个视图中的第i个2D目标边界框是
,原始的相机内参矩阵是:
那么第i个RoI的等效相机内参矩阵就是:
其中, 和
是根据RoI的尺寸和边界框的尺寸计算出的缩放比例。
由于等效相机内参矩阵包含相机和物体的几何属性,因此作者采用一个小型网络(卷积+池化+MLP,包含特征串联和齐次变化)根据RoI特征 和等效相机内参对物体位置
进行隐式编码内参 :
其中,(;)表示特征串联、 表示齐次变换。
这种方法允许模型不直接从RoI特征计算物体的深度信息,而是通过学习摄像头的几何属性和物体的视觉特征之间的映射关系来间接推断3D位置。这样做的好处是可以更灵活地处理不同场景下的物体定位问题,同时也使得网络能够利用深度学习的能力来理解复杂的几何和视觉模式。
隐式编码的对象位置 可以看作是RoI坐标系中3D目标的位置,然后使用内外参转换为3D世界空间。因此,转换后3D位置用作在3D世界空间中定位目标的参考点
。
通过上面的操作,MV2D基于2D检测和相机参数生成一组动态参考点 ,然后这些参考点通过位置编码层来初始化一组目标查询
,具体来说,每个目标查询q是通过下面的方式得到的:
第一个部分就是将位置编码利用权重矩阵转换为query,而第2-3个部分是指位置编码PE分为两部分,一部分使用正弦函数(sin)生成,另一部分使用余弦函数(cos)生成。这样设计是为了使得任何两个不同的位置都能拥有唯一的位置编码,同时保持位置编码的周期性特征。
是3D参考点的位置,通常表示为齐次坐标形式。第二个部分用于生成一半的位置编码,i是索引,指从0到C/2(C是说位置编码的维度),意味着对于位置编码的每一维,使用正弦函数按照不同频率生成编码,cos同理,提供了相位的补充,使得整体编码包含了更丰富的信息。10000这一项用于按不同的频率缩放参考点的位置,这样做可以使得模型能够学习到不同尺度上的位置关系,提高模型对位置信息的感知能力。
总结就是下面3个过程:
(1)等效相机内参变换:每个RoI由于来源于原始图像的不同区域,其尺寸和位置与原图相比都有所变化。为了准确地将这些RoI映射回3D空间,需要对它们应用一种等效的相机内参变换。这个变换考虑了RoI的缩放和位移,确保了变换后的RoI仍然能准确反映其在3D世界中的视角和位置。
(2)透视投影的模拟:通过应用这些等效的相机内参,RoI中的每个点都被视为是通过透视投影从3D世界投射到2D图像平面上的。因此,反过来,也可以利用这些等效的相机内参,将2D图像中的点“逆投影”回3D空间,以估计其在3D世界中的可能位置。
(3)从RoI到3D世界的映射:这种方法允许将RoI中的点基于相机的视角和位置,逆向映射回3D世界空间,从而为之后的3D物体检测提供一个基于实际观察的粗略位置估计。
4.2 Relevant Object Feature Selection
每个对象仅在多视图图像内的子区域中被捕获。通过关注目标对象的相关区域,可以消除可能阻碍对象定位性能的干扰因素和噪声。
因此,作者提出为每个对象查询的更新选择相关特征。由于 2D 对象检测器可以预测不错的 2D 对象提议,因此检测到的对象边界框意味着哪个区域包含有关对象的最独特的信息。因此,作者考虑对象相关特征的两部分:(1)生成对象查询的 2D 边界框 ; (2) 其他视图中与
对应的边界框。
在本文中,作者开发了一种有效的方法来关联给定查询的其他视图中的边界框。
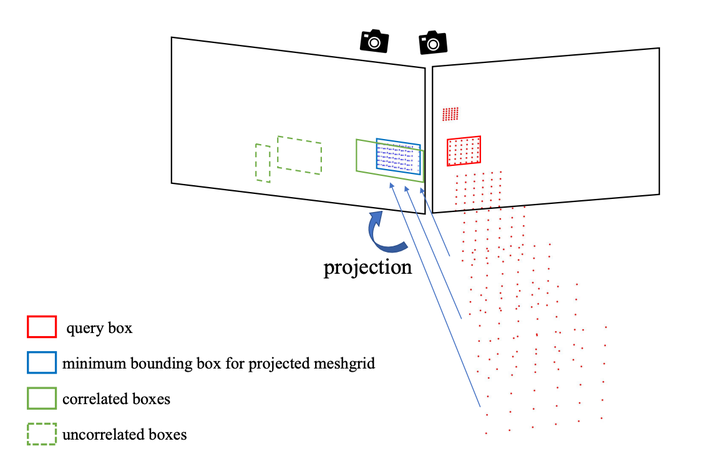
相关区域选择说明。每个查询框从 3D 网格生成一个离散的相机截锥体。然后将相机平截头体投影到另一个视图的像素坐标以计算最小边界框。然后根据与最小边界框的重叠来选择相关框。
如上图所示,为每个RoI创建一个3D网格 。将
表示为网格中的每个点。其中 (x, y) 是RoI中的坐标,
是一组预定义的深度值。RoI
的网格转换为第w视图的坐标系:
其中 是转换后在第w视图中的网格点,
是从第v视图到第w视图的坐标变换矩阵。然后,转换后的网格
的最小边界框
可以作为指导来找到
的相关前景区域。在本文中,考虑了两种规则,“top1 IoU”和“all overlapped”,来从其他视图中为
选择的相关前景区域
。
Top1 IoU:选择与 具有最高交集(IoU)(如果大于 0)的框作为
的相关区域:
全部重叠:所有检测到的与 重叠的框都被选为相关框:
然后,所有落入 和
区域的图像特征都被视为相关特征,并被用来更新对象查询
。
由于每个对象在不同的视角中可能呈现出不同的外观和尺寸,直接在全局特征上应用注意力机制可能会引入噪声,降低检测的准确性。因此,MV2D采用了相关对象特征选择策略,即只选取与当前查询对象最相关的那部分特征进行注意力计算。可以总结如下:
(1)创建3D网格:首先,对于每个RoI,创建一个3D网格,这个网格覆盖了RoI对应的3D空间区域。网格中的每个点都有一个预定义的深度值,这些点代表了可能的对象位置。
(2)网格投影:接着,将这个3D网格从一个视角(比如RoI所在的原始视角)投影到其他视角的图像平面上。这一步骤通过相机的内参和外参矩阵来完成,目的是确定RoI在其他视角中可能占据的图像区域。
(3)计算最小边界框:通过投影得到的点集,计算出包围这些点的最小边界框。这个边界框表示了在另一个视角中,RoI可能占据的最小图像区域。
(4)选择相关区域:根据最小边界框和其他视角中实际检测到的2D边界框,采用两种规则(“top1 IoU”和“all overlapped”)来选择相关的前景区域。如果一个检测到的边界框与最小边界框的重叠度(即IoU)最高,或者它们有任何重叠,那么这个检测到的边界框被认为是与当前查询相关的区域。
4.3 Decoder with Sparse Cross Attention
生成的对象查询通过类似 DETR 的编码器、解码器与其相关特征进行交互。和 DETR、PETR不同的是,MV2D 只使用相关特征来构造自己的键,而不是使用整个多视图特征图来构造所有查询共享的键和值。以及每个对象查询的值。这种设计不仅提供了一组紧凑的键和值,而且还可以防止对象查询受到背景噪音和干扰因素的干扰。最后,将由 MLP 组成的分类头和回归头应用于更新后的对象查询,以预测最终的 3D 对象检测结果。
在 3D 对象检测中,预测的对象中心 由
和查询预测的偏移量
组成,即
。
4.4 损失函数
在实现中,2D 检测器和 3D 检测器在 MV2D 中联合训练,骨干权重在两个检测器之间共享。 2D 物体检测损失 直接取自 2D 检测器。对于 3D 物体检测损失,按照之前的工作使用匈牙利算法进行标签分配。焦点损失和L1损失分别用于分类和框回归。 3D物体检测损失可以总结为:
整体损失就是:
,其中是平衡2D和3D检测损失的权重项,实验中设置为0.1。
4.5 Multi-Frame Input
通过将所有输入图像(无论是否来自相同时间戳)视为具有不同相机外参矩阵的相机视图,MV2D 可以处理多帧输入,而无需修改pipeline。对象查询不仅与同一时间戳的相关对象特征交互,还与其他时间戳的相关对象特征交互。因此,具有时序的优势。
五、实验结果
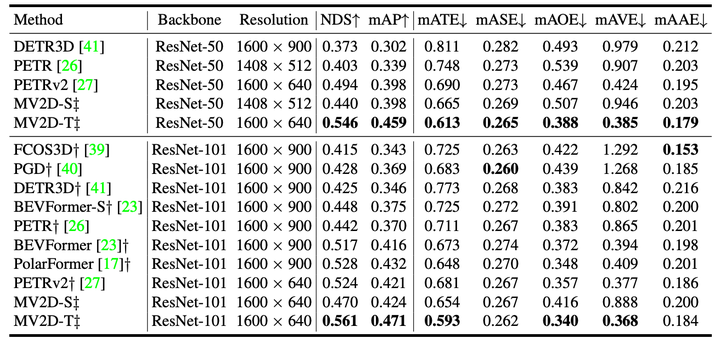
nuScenes val 集上的 3D 对象检测结果;† :模型从FCOS3D初始化。 ‡ :模型在 nuImages 上进行预训练。
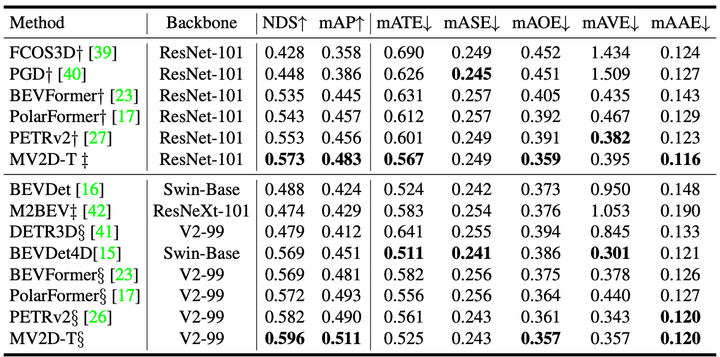
nuScenes测试集上的3D检测结果。 † :模型从FCOS3D初始化。 ‡ :模型在 nuImages 上进行预训练。 § :模型从DD3D初始化。
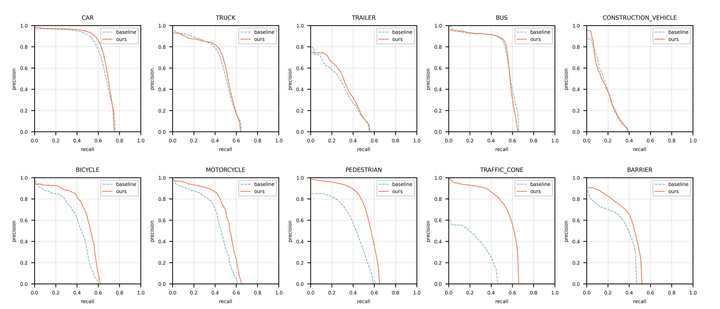
2D 目标检测设置下不同类别的精确召回曲线。该模型仍然生成 3D 对象预测,而每个图像中的 2D 边界框是通过使用相机参数投影 3D 边界框来生成的。精度和召回率是用 nuScenes val 集中的 2D IoU 阈值 0.5 计算的。蓝色虚线表示基线方法(固定对象查询)。红色实线代表提出的方法(生成的对象查询)
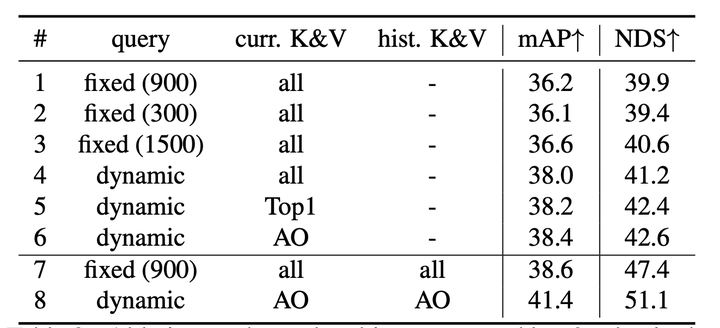
交叉注意层中对象查询和键值的消融研究。生成的查询数是平均计算的。curr表示当前帧,hist表示历史帧,Top1表示top1 IoU,AO表示全部重叠。
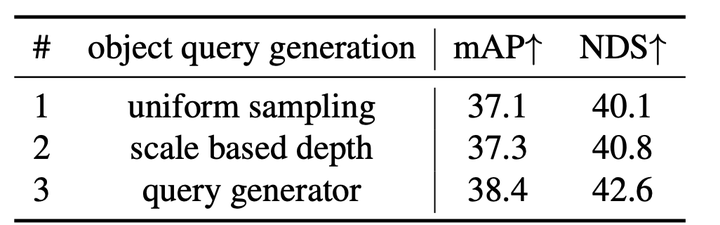
对象查询生成选择的消融研究。将查询生成器与两种替代方案进行比较:“均匀采样”和“基于比例的深度”。
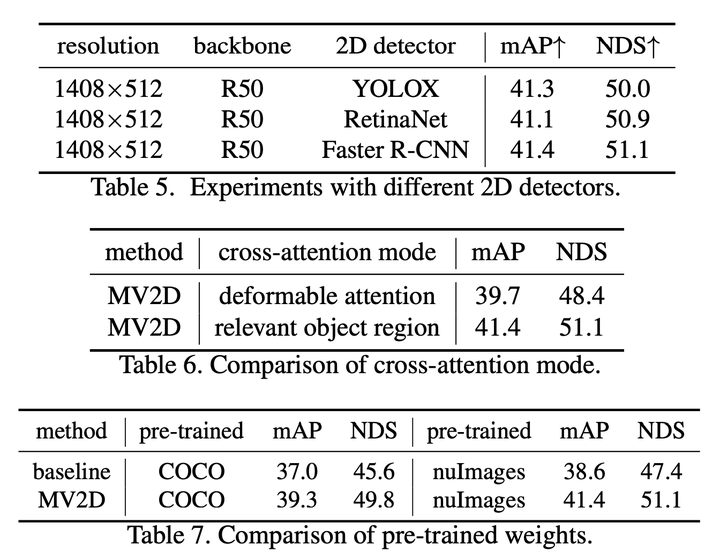
使用不同 2D 探测器的实验。交叉注意力模式比较。预训练权重的比较。
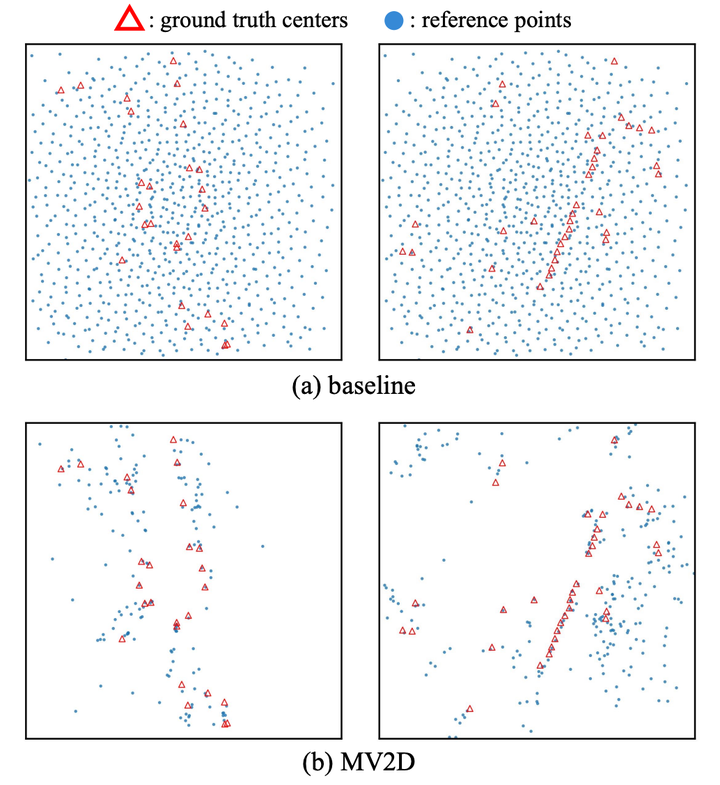
不同类型的对象查询的图示。顶行 (a) 代表基线方法(固定对象查询),底行 (b) 代表提出的方法(生成对象查询)。可视化了地面实况中心位置和 BEV 空间中的参考点。样本取自 nuScenes val 集。
六、结论
在本文中,提出了用于多视图 3D 对象检测的多视图 2D 对象引导 3D 对象检测器 (MV2D)。在框架中,利用 2D 对象作为稀疏查询,并采用稀疏交叉注意模块来约束信息聚合。在实验中,使用提出的 MV2D 框架在 nuScenes 数据集上展示了较好的结果。 MV2D 可以将任何 2D 检测器提升为 3D 检测,作者相信利用 2D 对象作为指导的见解可以进一步启发多视图 3D 对象检测方法的设计。
局限性:由于 MV2D 从 2D 检测生成对象查询,因此如果 2D 检测器未能在所有摄像机视图中检测到某个对象,则可能会丢失该对象。















 171
171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









