






关注公众号,发现CV技术之美
推荐三篇今天(2023.1.9)新出目标检测方向论文,其均为3D目标检测,其中两篇论文来自图森未来,方法上一篇多视图+两篇点云方向。
▌Object as Query: Equipping Any 2D Object Detector with 3D Detection Ability

作者单位:北航;图森未来
论文链接:
https://arxiv.org/abs/2301.02364
改造 “任意2D目标检测+多视图”,实现3D目标检测。
摘要:在过去的几年里,多视角图像的三维物体检测已经引起了人们的关注。现有的方法主要是从多视角图像中建立3D表示,并采用密集的检测头进行物体检测,或者采用分布在3D空间的物体查询来定位物体。
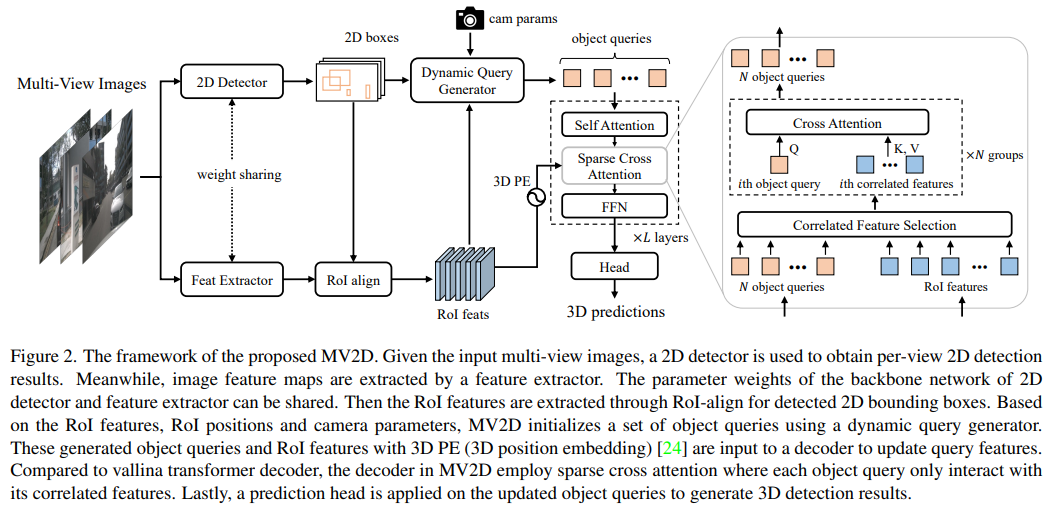
在本文中,我们设计了多视图2D物体引导的3D物体检测器(MV2D),它可以使用任何2D物体检测器来促进多视图3D物体检测。由于二维检测可以为物体的存在提供有价值的先验,MV2D利用二维检测器来生成以丰富的图像语义为条件的物体查询。这些动态生成的查询使MV2D能够在不增加计算成本的情况下检测更大的三维空间中的物体,并显示出强大的三维物体定位能力。对于生成的查询,我们设计了一个稀疏的交叉注意模块,迫使他们关注特定物体的特征,从而降低了计算成本并抑制了噪音的干扰。对nuScenes数据集的评估结果表明,动态物体查询和稀疏特征聚合并不损害三维检测能力。
MV2D在现有方法中也表现出最先进的性能。我们希望MV2D可以作为未来研究的新基线。
▌Super Sparse 3D Object Detection

作者单位:中科院;图森未来
代码链接:
https://github.com/tusen-ai/SST
论文链接:
https://arxiv.org/abs/2301.02562
超稀疏特征,实现远距离3D目标检测。
随着 LiDAR 感知范围的扩大,基于 LiDAR 的三维目标检测对自动驾驶的远距离感知的贡献越来越大。主流的三维目标检测器通常建立密集的特征图,其成本是感知范围的二次方,这使得它们很难扩展到长距离的设置。
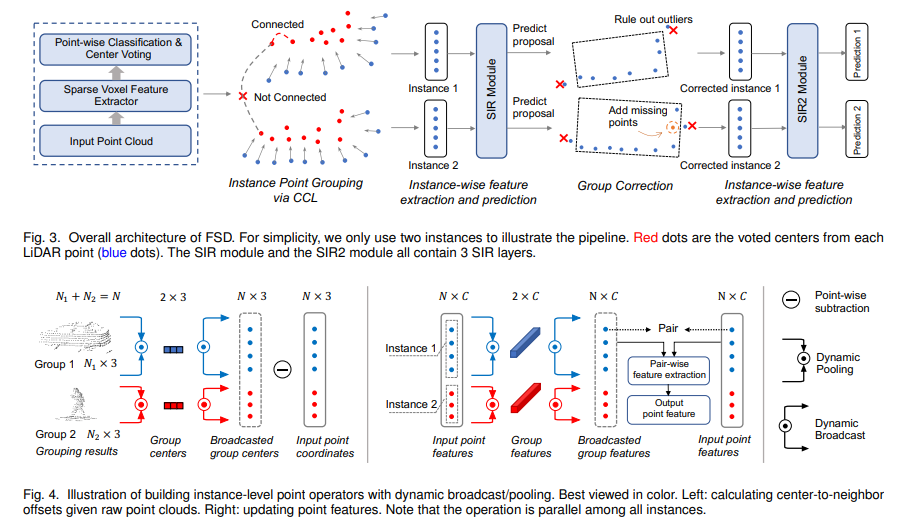
为了实现高效的远距离检测,该文首先提出一个完全稀疏的目标检测器,FSD。FSD 建立在一般的稀疏体素编码器和一个新的稀疏实例识别(SIR)模块上。SIR 将点分组为实例并应用高效的实例特征提取。实例分组避开了中心特征缺失的问题,这阻碍了全稀疏结构的设计。为了进一步享受全稀疏特征的好处,利用时间信息来消除数据冗余,并提出一个名为 FSD++ 的超稀疏检测器。FSD++ 首先生成残余点,表示连续帧之间的点变化。残余点与之前的几个前景点一起构成了超稀疏输入数据,大大减少了数据冗余和计算开销。
通过在大规模的Waymo开放数据集上对所提出方法进行了全面分析,实现了最先进的性能。为了展示该方法在长距离检测方面的优越性,作者还在Argoverse 2数据集上进行了实验,该数据集的感知范围(200米)比Waymo Open Dataset(75米)大很多。
▌Model-Agnostic Hierarchical Attention for 3D Object Detection

作者单位:马里兰大学&Salesforce Research&得克萨斯大学奥斯汀分校
代码链接:
https://github.com/salesforce/Hierarchical_Point_Attention
论文链接:
https://arxiv.org/abs/2301.02650
Transformers + "多尺度"/"尺寸自适应局部"注意力机制,实现更好的小目标的3D目标检测。
Transformers 作为多功能的网络架构,近期在3D 点云目标检测方面取得了巨大的成功。然而,普通 transformer 缺乏层次性,使得它难以学习不同尺度的特征,并限制了它提取局部特征的能力。这种限制使得它们在不同大小的目标上的性能不平衡,在较小的目标上性能较差。
本次工作中,作者提出两种新的注意力机制,作为基于 transformer 的三维检测器的模块化分层设计。为了实现不同尺度的特征学习,提出了简单多尺度注意力机制,从一个单一尺度的输入特征中建立多尺度的标记。对于局部特征的聚集,提出了尺寸自适应局部注意力机制,对每个边界盒的提议都有自适应的注意范围。所提出的两个注意力模块都是与模型无关的网络层,可以插入到现有的点云 transformer 中进行端到端训练。
作者在两个广泛使用的室内三维点云目标检测基准上评估了此方法。通过将所提出的模块插入到最先进的基于 transformer 的三维检测器中,在两个基准上都改进了以前的最佳结果,其中对小目标的改进幅度最大。


END
欢迎加入「目标检测」交流群👇备注:OD
















 3188
3188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









