






这篇文章主要是参考MJP的“Attack of The Depth Buffer”,测试不同格式下depth buffer的精度。
测试的depth buffer包含两类: 一是非线性的depth buffer,存储着perspective z(也就是最常用的,透视投影后归一化的z/w的buffer),二是线性的depth buffer,存储着view space z(这里的线性指的是在view space 中是否线性)。测试的格式包括16位浮点数,32位浮点数,16位定点数,还有最常用的24位定点数(DXGI_FORMAT_D24_UNORM_S8_UINT) 。
测试的方法是在pixel shader里采样depth buffer,然后构建出view space position,把这个值和vertex shader里插值过来的position做对比,把两者的差别输出到RT的red分量,这样越红的部分误差就越大。测试的near-clip plane为1,far-clip plane为300,场景模型用的是DXSDK里的Columns。
测试程序画面的左半边显示精度误差,右半边显示把精度误值乘以100的结果。
运行结果:
- Linear Z,16位浮点格式

从结果可以看出16位浮点的误差还是蛮大的,越靠近far-clip plane,误差越大
- Linear Z,32位浮点格式
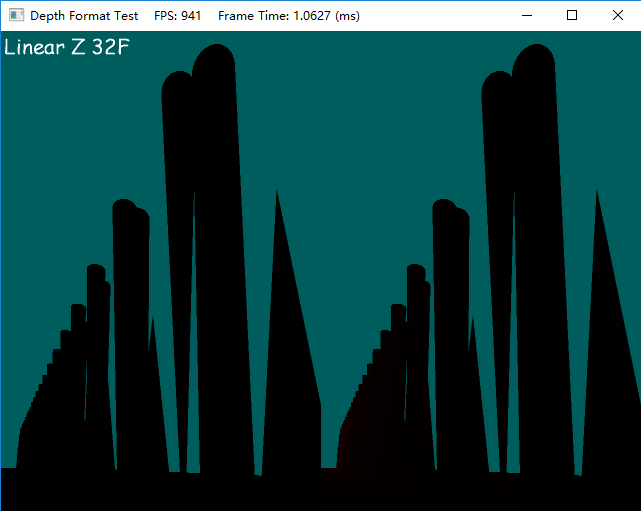
很明显,32位的精度很高,只有在非常接近far-clip plane时才有些许误差,理论上来讲32位定点数精度会更好。当然高精度的代价是高带宽
- Linear Z,16位定点格式
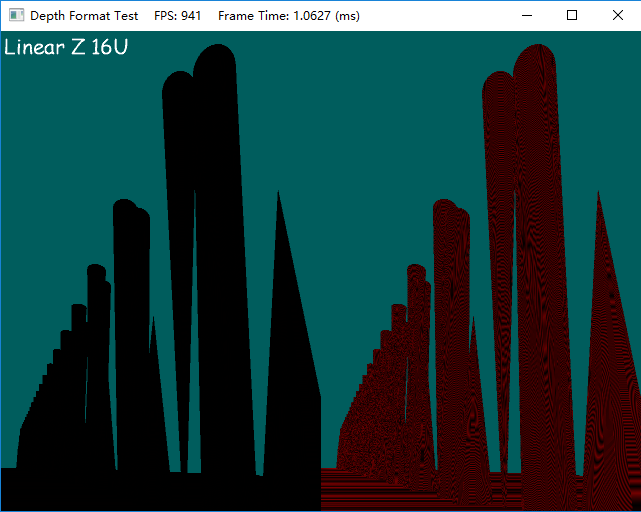
16位定点格式的精度比浮点要好,误差分布也很均匀。如果某些情况必须使用16位的buffer时,16位定点数是不错的选择。
- Perspective Z,16位浮点格式
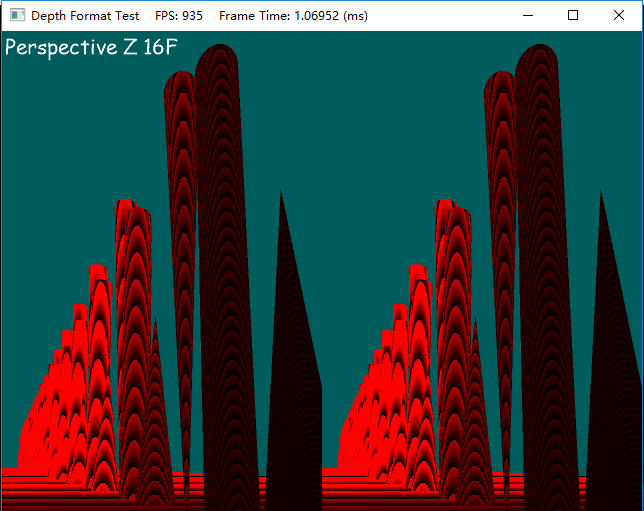
这是所有测试结果中误差最严重的一种,这和MJP的结果是一样的,原因在于浮点数的分布和透视投影的特性。所以无论何时,都不要使用16位浮点数的非线性depth buffer。
- Perspective Z,32位浮点格式
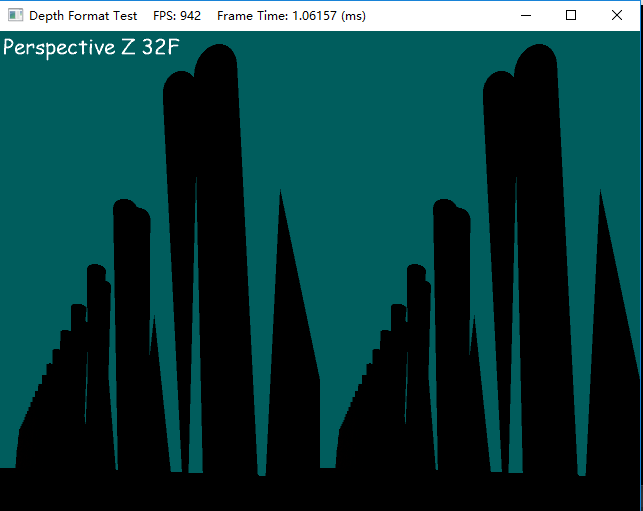
和之前的32位线性buffer一样,精度很高
- Perspective Z,16位定点格式

这个测试结果表明:对于非线性的depth buffer,16位定点数格式远好于16位浮点数,并且在靠近near-clip plane的地方,比16位的线性buffer精度更好,缺点就是在靠近far-clip plane时精度就下降很多,这是透视投影的特性导致的
- Perspective Z,24位定点格式

这是最常用的格式,从结果来看和32位的差不多。主要是这个测试结果的far-clip值并不大,误差值不容易察觉,实际的误差值在0.005%左右,如果far-clip非常大的话,误差就会变大。
- 分析总结
为什么16位浮点数非线性buffer的误差这么之大?原因有两个:1.透视投影的特性 2.浮点数的精度分布
根据透视投影矩阵,可以推导出view space z对应z buffer的函数图像如下
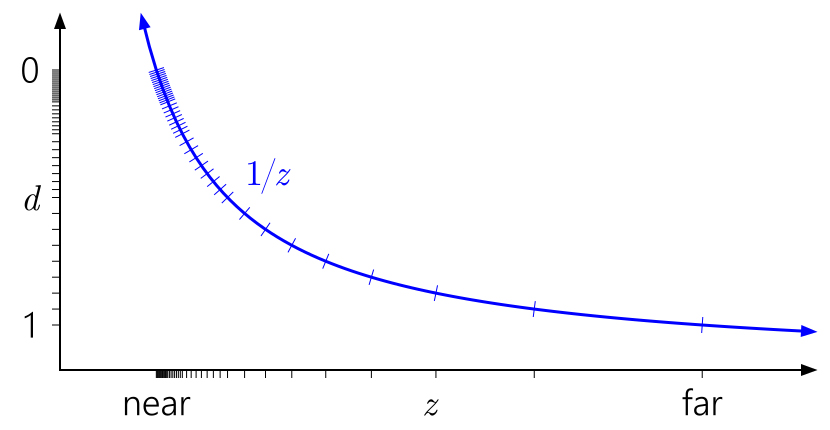
可以看出在靠近near的地方,曲线非常陡峭,斜率很大,在靠近far时,曲线很平稳,斜率很小。所以透视投影对于近处的物体有很好的精度,但随着越来越靠近far时,精度就会不断下降。
far和near的比值决定了曲线的陡峭程度,如果far/near越大,那么曲线就越陡,z buffer的精度越差。比如16位浮点格式,当far/near为600时,误差约为1%,当far/near为8000时,误差高达10%。
对于浮点类型,其值在[0,1] 区间并不是均匀分布的,实际上是在靠近0时,精度最好,远离0时,精度下降。如下图:

而浮点类型的这种分布,和透视投影的特性刚好是相矛盾的——在靠近near(0)时,斜率很大,view space z只要变换一点点,z buffer就能有很大变换,所以并不需要很高的精度,而在远离near时,斜率很小,就需要更多的精度。16位浮点本身精度就不如32位,再加上浮点的分布和透视投影特性,更加加剧了误差,所以16位float的非线性buffer的精度才会如此之差。
这也说明了为什么定点数的精度要好于浮点数——因为定点数是均匀分布的,不会有浮点数那样的问题。
当使用非线性的浮点buffer时,实际上浮点数的很多精度都被浪费了。所以有一种做法就是把near plane和far plane对换,这样近处的物体映射到1附近,远处的物体映射到0附近,这就刚好符合了浮点数的精度分布,这在精度不够时是一种很有效的优化手段。但在用的时候需要把depth test的条件从less改为greater,z buffer中的值变成了越大越靠近。
- Position Buffer的精度
MJP的博客里还测试了把position直接存储到texture的精度,他测试的格式是DXGI_FORMAT_R16G16B16A16_FLOAT 效果如下(左下角和右下角分别为误差和误差乘以100):

可以看出误差并不小,结果和用16位浮点depth buffer构建position是差不多的,所以把position存到texture是糟糕的选择,不仅精度不够,而且占用带宽。
- 线性和非线性的buffer
前面所说的线性和非线性buffer,指的是在view space中,perspective z的buffer不是线性的,view space z的buffer是线性的。但是在屏幕空间,情况相反,perspective z的buffer是线性的,而view space z的buffer不是线性的。Why ? 因为在屏幕空间,1/z才是线性的,而perspective z本身就是1/z的形式,所以是线性的,view space z不是1/z的形式,所以不是线性的。
屏幕空间中是线性的有什么好处?很多屏幕空间的渲染就能收益,线性就意味着位于同一图元表面的pixel的delta z是相同的(ddx(z), ddy(z)),那么边缘检测之类的就变得很容易。而且屏幕空间的线性意味着插值简单,无需做透视校正,那么对硬件是很友好的。
关于线性和非线性,Humus的“A couple of notes about Z”中有详细的论述。
- 总结
1. 尽量减小far/near的值。
2. 16位浮点数的非线性depth buffer精度最差,避免使用。
3. 浮点格式精度不够时,考虑交换near plane和far plane来提高精度
4. 在屏幕空间中,perspective z buffer是线性的,view space z buffer不是。
参考资料:
https://mynameismjp.wordpress.com/2010/03/22/attack-of-the-depth-buffer/
https://developer.nvidia.com/content/depth-precision-visualized
https://www.sjbaker.org/steve/omniv/love_your_z_buffer.html
http://www.humus.name/index.php?page=Comments&ID=255
http://dev.theomader.com/linear-depth/















 1133
1133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









