






BitNet 是微软专为 CPU 本地推理和极致压缩(低比特)大模型设计的推理框架。它支持对 1-bit/1.58-bit 量化模型进行高效、低能耗的推理,兼容 BitNet、Llama3-8B-1.58、Falcon3 等模型,适用于在本地或边缘设备上运行大模型推理任务,无需 GPU。
| 18730 | |
| 1372 |
主要特点
-
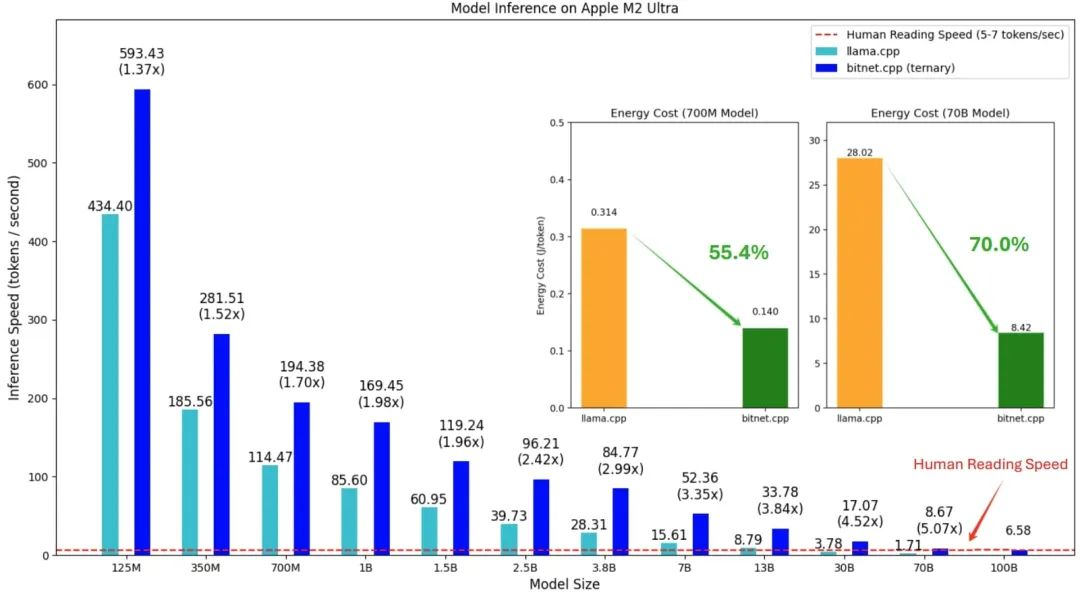
极致轻量化:0.4GB内存+原生1.58位设计,边缘设备(如手机、IoT)部署无忧。
-
能耗革命:比全精度模型节能90%,推动绿色AI发展。
-
训练创新:原生量化避免后训练(PTQ)性能损失,综合表现优于INT4量化模型。
-
开源生态:提供CPU/GPU双版本推理框架,开发者可快速上手。
当前局限
-
任务覆盖不足:知识密集型任务(如TriviaQA)表现稍弱,需优化数据分布。
-
硬件适配:依赖专用推理框架(如bitnet.cpp),通用库支持有限。
-
模型规模:20亿参数虽属轻量级,但复杂任务仍需更大模型支撑。
微软团队已规划多项升级:扩展至7B/13B参数、支持长上下文(4096 token)、集成多语言/多模态能力,并探索专用硬件加速。BitNet的诞生不仅为端侧AI开辟新路径,更挑战了“高性能必高耗能”的传统认知,或将成为AI普惠化的重要里程碑。
GitHub:GitHub - microsoft/BitNet: Official inference framework for 1-bit LLMs

















 215
215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









