







一、前言
1、 线性判别式分析(Linear Discriminant Analysis, LDA),也叫做Fisher线性判别(Fisher Linear Discriminant, FLD),是模式识别的经典线性学习算法,也是一种监督学习的降维技术。
2、 基本思想:将高维的模式样本投影到最佳鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的子空间有最大的类间距离和最小的类内距离,即模式在该空间中有最佳的可分离性。
3、 在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。
4、 LDA原理:将样本点投影到低维形成类簇,即可达到分类效果,也实现了特征降维的效果

二、LDA数学原理
1、 给定数据集 , , 表示类示例集合
 ,
,  ,
,  表示类示例集合
表示类示例集合2、 类样本均值 ,总体样本均值
3、 类样本投影后的均值 ,总体样本投影后的均值
 ,总体样本投影后的均值
,总体样本投影后的均值 
4、 投影后类内分散程度
a) 投影后的类样本

b) 原始空间类内分散程度
5、 类间分散程度 (二分类)或 (多分类)
 (二分类)或
(二分类)或  (多分类)
(多分类)6、 建立损失函数 , 或
 或
或 
7、 LDA的最大化目标: 与 的“广义瑞利商”
 与
与  的“广义瑞利商”
的“广义瑞利商” a)
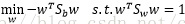
b) 根据拉格朗日乘子法得
c) 求导取0,求极值得

8、 简化运算
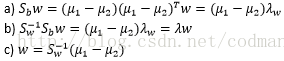
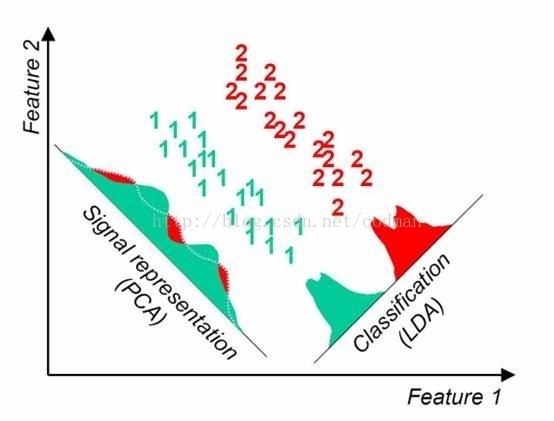
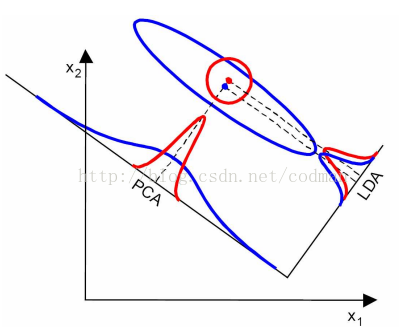
三、LDA与PCA对比
1、 相同点
a) 两者均可以对数据进行降维
b) 两者在降维时均使用了矩阵特征分解的思想
c) 两者都假设数据符合高斯分布
2、 不同点
a) LDA有监督,PCA无监督
b) LDA最多降维到类别数K-1的维数,而PCA无限制
c) LDA除了降维,还可用来分类
d) LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向
四、LDA特点
1、 优点
a) 降维过程中可以使用类别的先验只是经验
b) LDA在样本分类信息依赖均值而不是方差的时候,比PCA算法较优
2、 缺点
a) 不适合对非高斯分布样本进行降维(PCA同)
b) 维度限制较为严重,降维的维度大于类别数K-1时,不能使用LDA
c) LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好
d) LDA可能过度拟合数据
参考博客:http://link.zhihu.com/?target=http%3A//www.cnblogs.com/pinard/p/6244265.html















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









