







一、为什么用CNN做影像处理
比如我们来处理一张小猫的照片,如果我们用普通的全连接的神经网络来对这张照片进行分类的话就会像下图一样。有一种理论是认为每一层都会对这张照片进行分类,比如第一层对这张照片的颜色进行分类,第二层会基于第一层对纹理进行分类,第三层基于第二层可以识别特定的影像,直到最后。但是这样的话会产生一个问题,如果提供的小猫的照片是
100
∗
100
100*100
100∗100像素的话,那么深入就是
100
∗
100
∗
3
100*100*3
100∗100∗3的列向量了,如果每一层都是全连接的话没两层之间的weight就有
(
100
∗
100
∗
3
)
2
(100*100*3)^2
(100∗100∗3)2个,这样的话进行计算的时候就很费劲儿了。
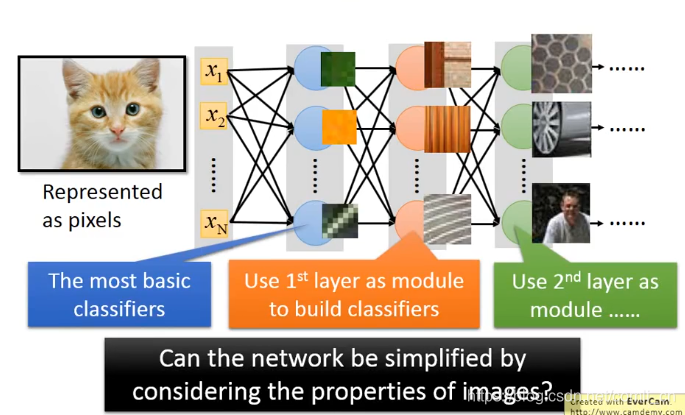
CNN的想法是通过某种方法去掉一些不必要的weight来对模型进行简化。
为什么可以去掉一些参数呢?
Property1:
神经网络中的每一个神经元的作用是识别一张大图中的某个小图案(pattern),为了识别这个小图案我们并不需要看整张大图。
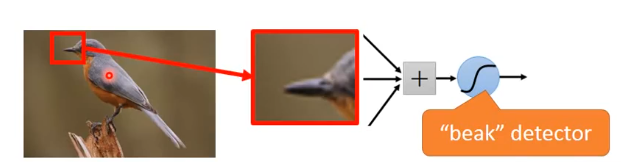
Property2:
同样的图案可能出现在两张图的不同位置,而我们要在两张图中识别这个图案需要的是一组同样的参数。
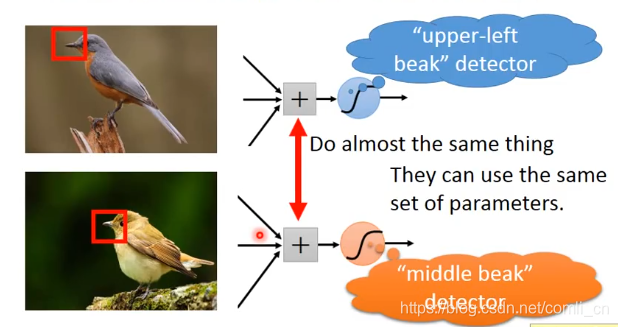
Property3:
对一张图像进行二次抽样(Subsampling),比如说隔一行抽掉一行的像素,隔一列抽掉一列的像素,把剩下的像素拼在一起我们依然可以分辨这张图片,但这样就可以减少参数了。
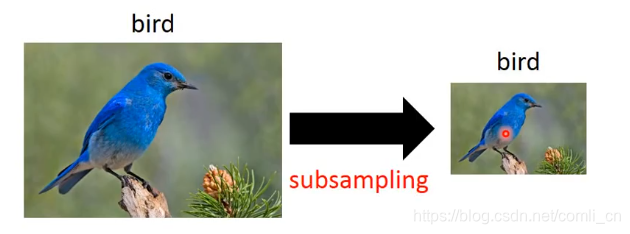
二、怎么用CNN做影像处理
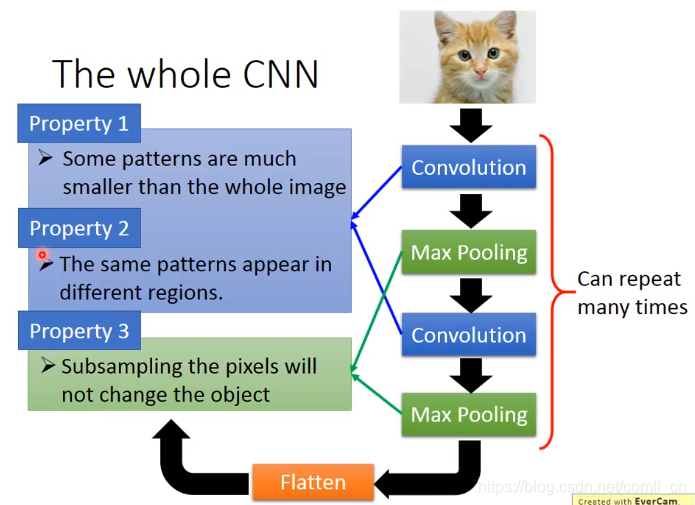
上图就是整个CNN运行的过程,通过卷积(Convolution)解决了Property1和property2,通过池化操作(Max Pooling)解决了property3,最后通过Flatten就完成了。
1.CNN-Convolution
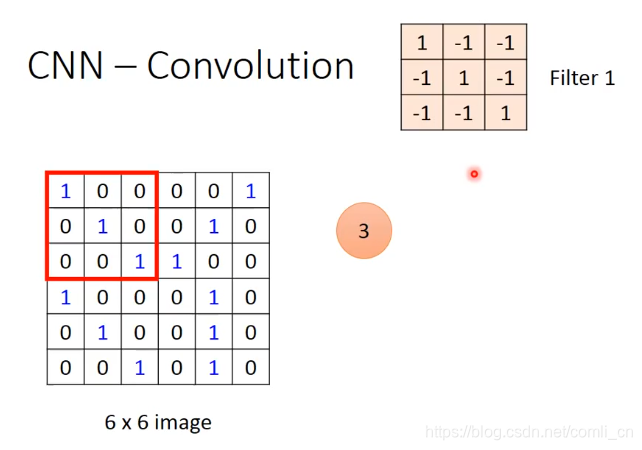
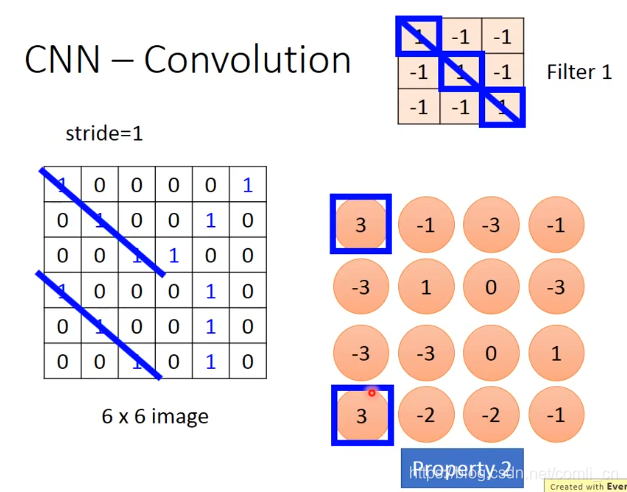
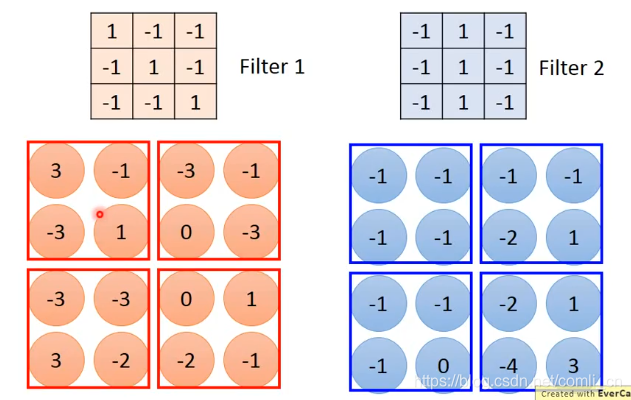
比如我们有一个6*6的image,还有一系列的Filter,每一个Filter是一个矩阵,如下图:

每一个Filter都是被学得的网络参数,每个Filter都只在image上detect一个小的pattern。
然后如下图一样,对Filter1和红框里面的矩阵做内积,算出来是3
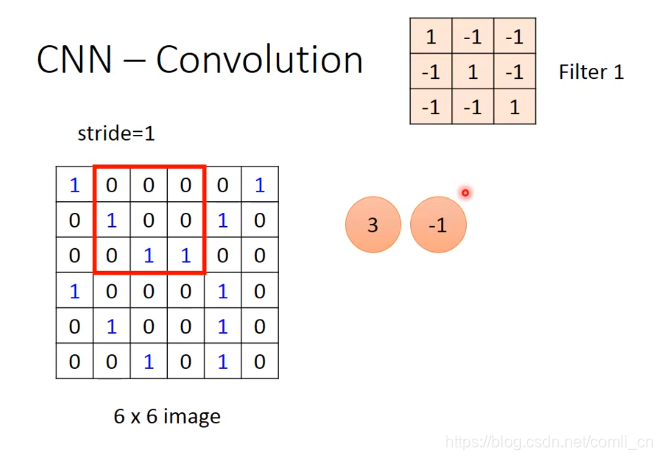
接下里移动红框,移动的步长可以自己定,我们先假设步长为1,与Filter1做内积之后算得 -1:
直到移动到右下角为止,做内积之后算出来是 -1:
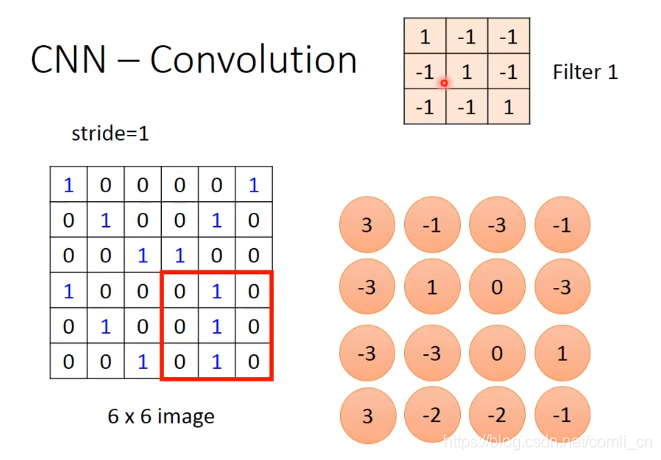
我们可以看到画蓝色斜杠的两个位置与Filter是相同的,而这两个位置与Filter做内积的值也是最大的。就此我们以后就可以通过比较内积值从image中找出与Filter相同的pattern。
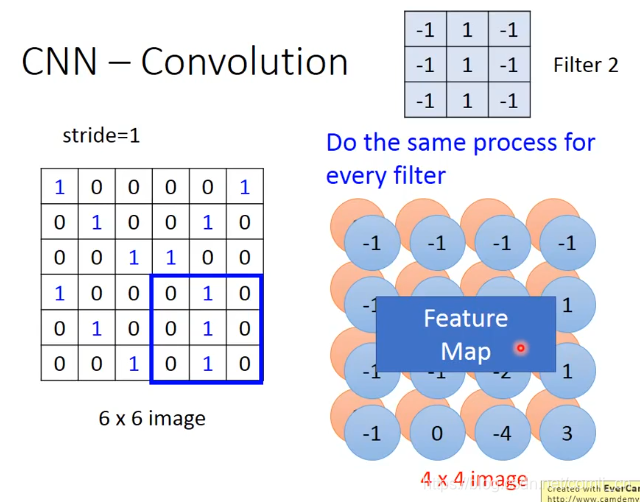
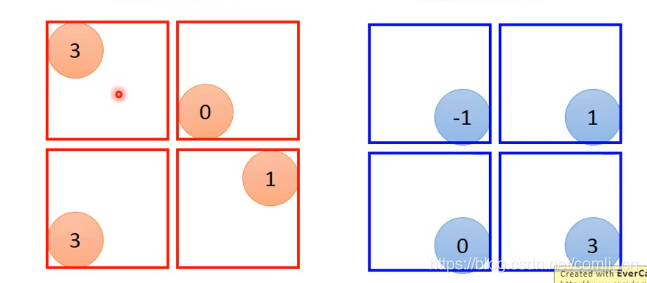
上面讲了一个Filter是怎么跟image做运算的,但我们有好多的Filter就要让每个Filter和和image做运算,最后把这些Filter和image运算出来的结果放在一个矩阵里,称这个矩阵为Feature Map
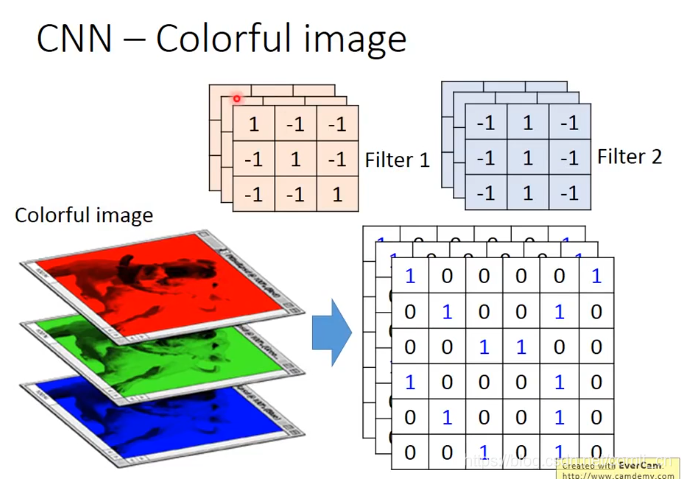
如果是一张彩色的image那么它的image和Filter都是三层的:
2.CNN-Convolution与Fully connected的联系
上面讲的Convolution似乎与我们常用的Fully connected的神经网络没什么联系,但事实不是这样的,我们把Filter当作参数矩阵,再将红色框里的展成一列:
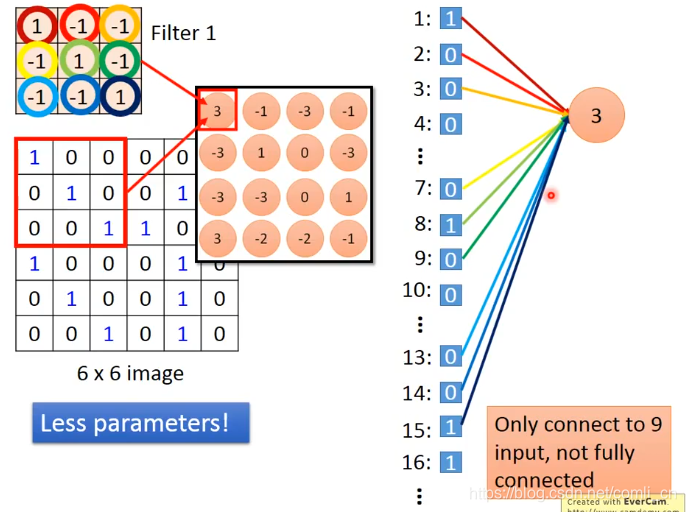
因为我们不需要连接每一个input所以我们用了比较少的参数。
接下来移动红框:
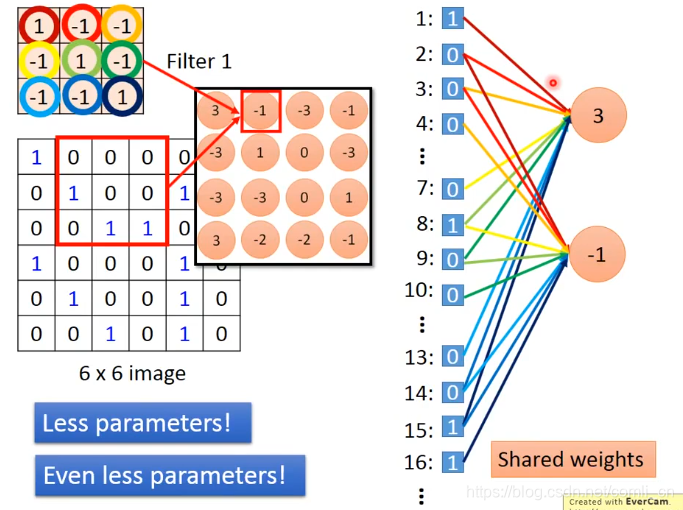
虽然移动了位置,但参数没变,这就叫shared weights,这会导致我们用了更少的weight。
3.CNN——Max Pooling(池化操作)
Max Pooling就是将内积值进行划分,比如下面把其划分为4个一组。
接下来保留每个小框里面的最大值(也可以计算出每个小框里的平均值保留)
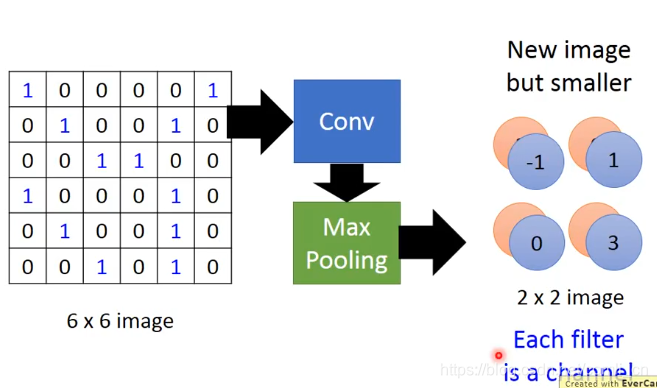
我们可以重复上面的步骤好几次:
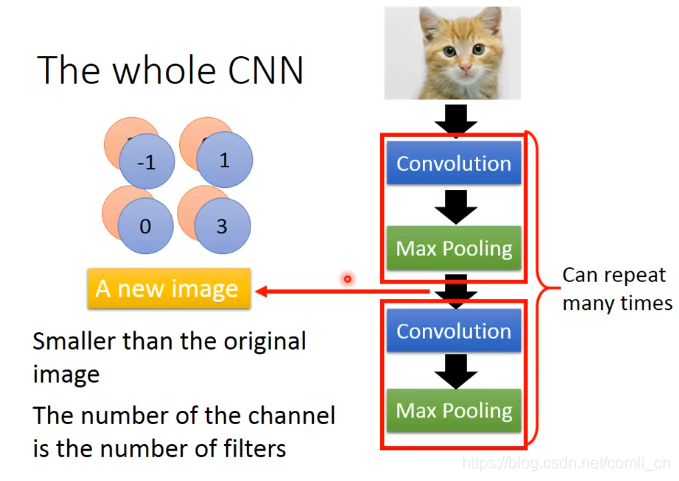
接下来到了Flatten和Fully Connected的部分:
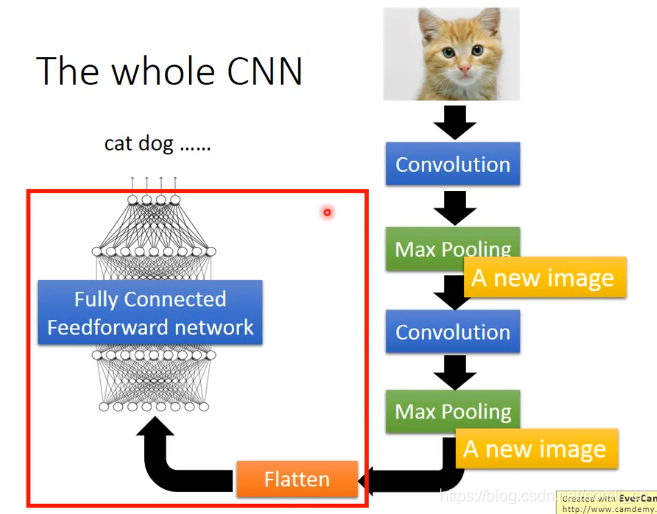
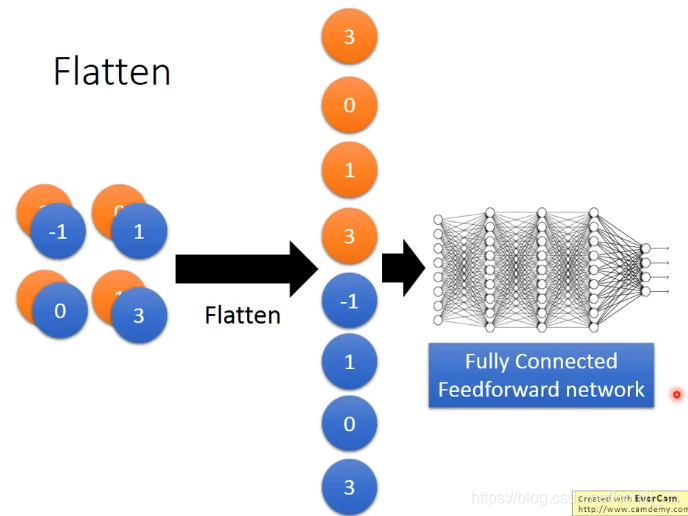
三、CNN在学习什么

也就是说,在CNN中weight值时固定的(Filter是固定的),我们通过移动红框在image上寻找一组
x
x
x使得激活函数
a
k
a^k
ak最大。
对不同的Filter在image上进行detect后找到的使激活函数
a
k
a^k
ak最大的
x
x
x如下,我们可以这样理解,比如第一个Filter就是为了在iamge里面找到有点像凹点的纹理,第二个Filter是为了找到凸点纹理······

经过flatten之后,把结果放进Fully Connect当作输入,那么这个Fully Connect的隐藏层的神经元会看到下面的图像,这是因为flatten之后它所关注的就不仅仅是纹理了,它将各种文理进行综合后会看到一些图案:

到最后的输出层会学到下面的图片,我们会发现机器学到的0到8和人类看到的0到8并不一样:
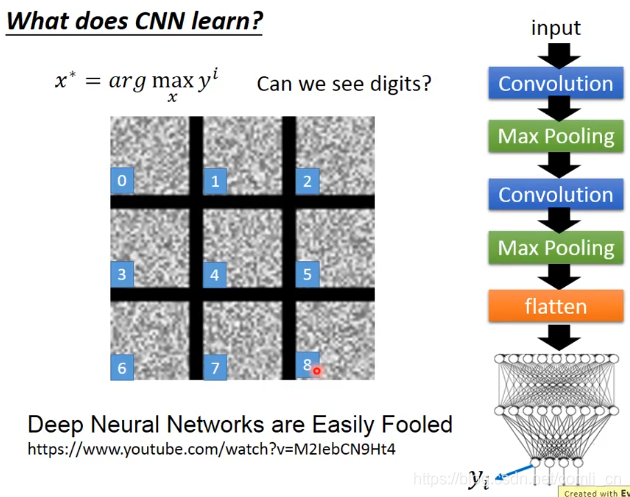
对上面的结果进行处理:
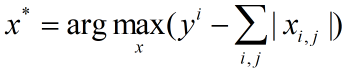
可得效果好一些的图片:
















 217
217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











