






目录
前言
本人在2023年末~2024.11月,耗时接近一年在视觉图神经网络上。
本篇文章我将结合我在探索过程中的思考来阐述ViG
另外,非常感谢韩凯大佬的工作让我在研究牲阶段能够有个方向能毕业🌹
代码链接放在 后记部分 ,建议把文章看完再去看代码
1. Introduction
计算机视觉任务中,卷积神经网络(Convolutional Neural Networks, CNNs) 因其具有的平移不变性和局部性,曾经是标准的网络架构。近来,具有注意力机制的Transformer被用于视觉任务中, 并且取得了与卷积神经网络相当的效果,如Vision Transformer (ViT)[1]
不同的网络结构以不同的方式处理图像,如图1.1所示。CNNs在图像上应用滑动窗口,将图像视为一个网格结构,并引入了平移不变性和局部性。而ViT则将图像视为序列结构。
🌰:ViT将图像转化为序列后,自注意力机制其实就把图像视为一个全连接图
计算机视觉的一个基本任务是识别图像中的物体,图像通常会被划分成若干个小区域(patches),每个区域代表物体的一个部分。由于物体通常不是规则的正方形,通过网格或序列的方式来表征图像显得不够灵活。
如网格结构是将图像划分为patches后,虽然具有局部性和平移不变性,但是区域之间缺少信息交互,使得这样的表征方法难以捕捉到区域间的复杂关系;序列结构则是将图像划分后的patches转化为序列,破坏了图像区域间原本的位置关联性。而一个物体通常可以视为有多个组成部分。比如,青蛙可以视为由头部、躯干和四肢组成, 这些部分通过关节的连接,自然地形成了图结构,这样的图结构也更符合人的认知。通过分析这个图,我们可以识别出青蛙。
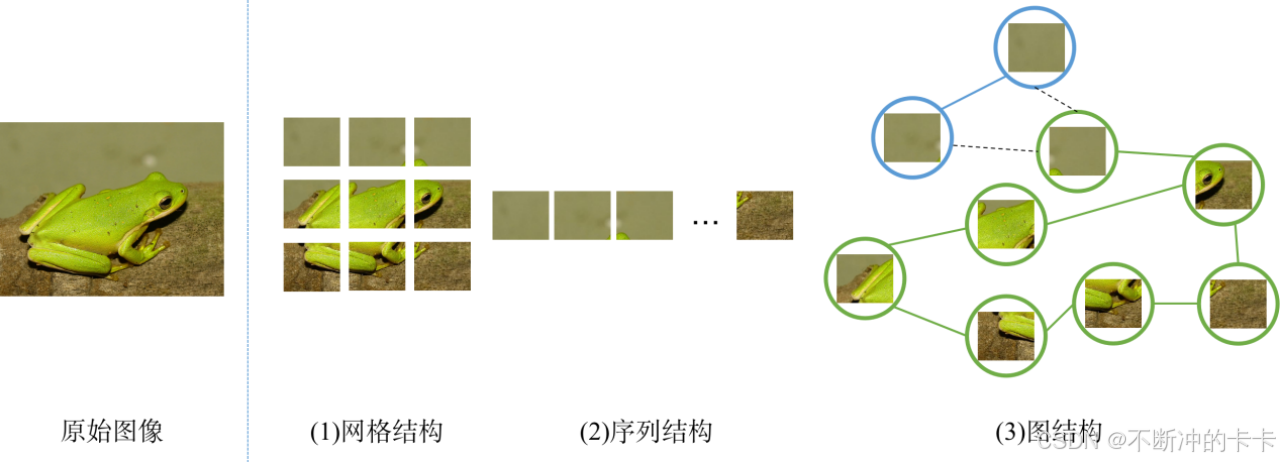
国内外研究现状:CNNs的历史、图网络在特定计算机视觉的应用,目前计算机视觉领域中缺乏更通用的图网络架构,提出ViG
2. Methodology
2.1 图像序列化
假设输入图像大小224×224,用一个浅层CNN下采样图像,得到196(14×14)个patch,每个patch大小为16×16。
然后插入像ViT 一样加上位置编码,关于ViG里面的位置编码,见仁见智,详见Github-ViG-位置编码
🌰
ViG作者只提供分类代码,图像默认是224×224,位置编码写死的:
self.pos_embed = nn.Parameter(torch.zeros(1, channels, 14, 14))
要适应其他shape的图像,需要像ViT一样对位置编码进行插值,这部分的代码我在前言中
如果你想玩目标检测,这个是逃不掉的!
如果你想玩目标检测,这个是逃不掉的!!
2.2 构图
2.2.1 KNN构图示意
把patches 视为图结点,ViG使用的是K近邻进行构图,如下面示意图2.1所示。假设K=4,那就把离每个结点最近的4个邻居作为邻接结点,连边,构成图结构。

2.2.2 狠狠深入KNN构图
介绍
🌰:这个KNN构图,实际在代码层面上的操作使用的是Dilated KNN[2] . 私以为这是把CNN的东西迁移到GCNs (模仿空洞卷积),这里额外引入一个dilation的参数。 不是特别懂空洞、分组卷积可以看一下这篇文章pytorch中的nn.Conv2d,可以顺便给这个朋友点个赞🌹,我还挺喜欢他的内容的
算法具体过程:即找K×dilation 近邻中的K 个近邻(等步长法或随机,随机的用于训练调参),取1就是常规的KNN了,如图2.2所示。
文章中说这样能提高感受野,因为它是基于特征相似度进行特征聚合的,跨步是提高特征聚合的多样性,能让不同特征的差异更大,能够抗过平滑一点。
🌰:关于特征多样性:图卷积神经网络随着深度加深,特征矩阵的秩会崩塌(=过平滑over-smoothing[3]=特征相似度过高=特征多样性(diversity)受限,详细的证明可见[4]),,进而导致模型性能变差。 [4]还提及 feed-forward network (FFN)还有skip-connection 是缓解上述现象的关键。 所以ViG后面用了FFN+skip-connection
图2.2 Dilated KNN示意图 🌰:
①你会发现,刚进入一个领域时,看文献就是递归往回看的
②复杂的公式,巴拉讲不清的,特别是给新手或非行内人士看的话,用图来表示会更直观清晰

K&Dilation的配置
以12层的ViG-Ti 为例
下面代码中的k=9 self.num_knn=[int(x.item()) for x in torch.linspace(k, 2*k, self.n_blocks)] self.max_dilation = 196 // max(self.num_knn) self.dilations = [min(i // 4 + 1, self.max_dilation) for i in range(self.n_blocks)] num_knn [9, 9, 10, 11, 12, 13, 13, 14, 15, 16, 17, 18] dilation [1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3]
2.3 特征聚合和更新
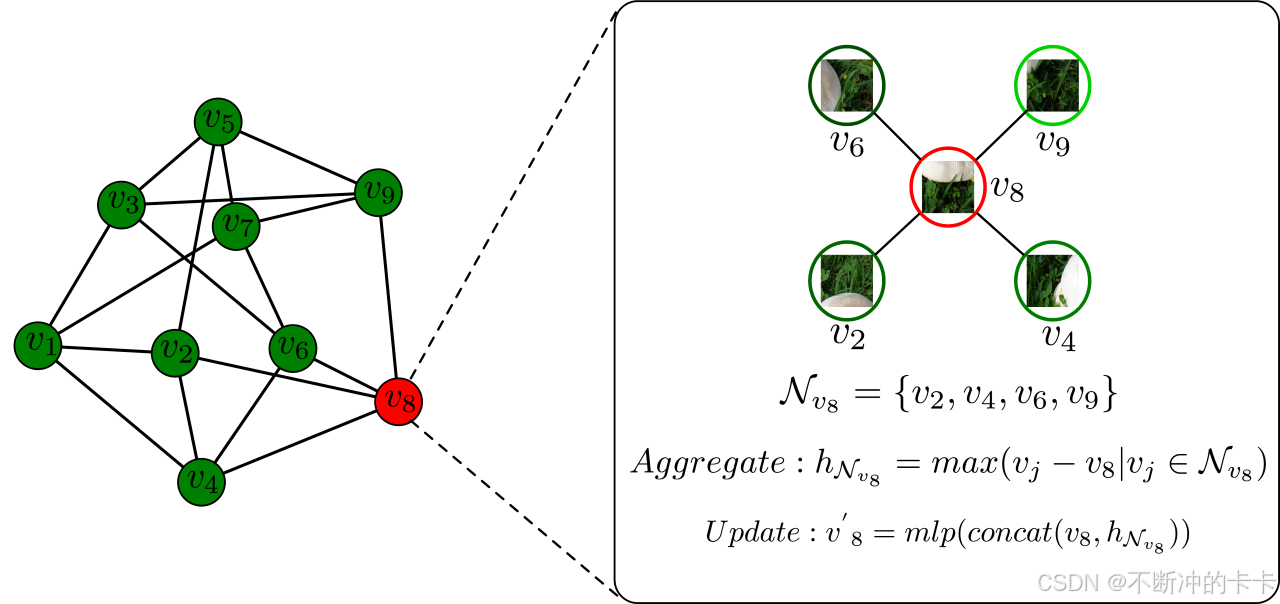
这里使用的Max-Relative GraphConv [2],来将结点与其邻接结点的信息进行聚合,如下图2.3 所示。
以结点V8为例,近邻结点为V2,V4,V6,V9。
聚合操作(Aggregate):将每一个近邻结点的信息与结点V8 的信息相减,比如得到四个向量A,B,C,D;然后在每一个维度(比如特征维度256,那就是从0到255),从A,B,C,D对应的维度,选取最大值作为聚合后的特征。
更新操作(update): 将聚合后的信息跟结点信息进行concat ,接着再进行映射。
3. Results
① Image Classification:在ImageNet上的结果能复现
② Object Detection:在COCO上结果,我复现不了,因为在标准的COCO跑法上,我用4张A6000都跑不起来PViG-Ti.详细见这个问题,然后就没有然后了。
4. Limitation
4.1 计算复杂度
局限性:用KNN构图的计算复杂度跟图像分辨率呈平方相关
用KNN构图,在计算图结点特征的距离矩阵的时候,
计算复杂度跟ViT的自注意力机制相同也是N²,其中N=(H×W)/P²,H,W为图像的高和宽,P为Patch的大小
目前也有一些工作在降低ViG的计算复杂度:
比如MobileViG[5],①采用深层CNN结合浅层GNN的方式替换掉ViG的深层GNN ②用一种固定图结构的构图方法,进一步降低计算复杂度。
4.2 没有充分利用卷积局部性
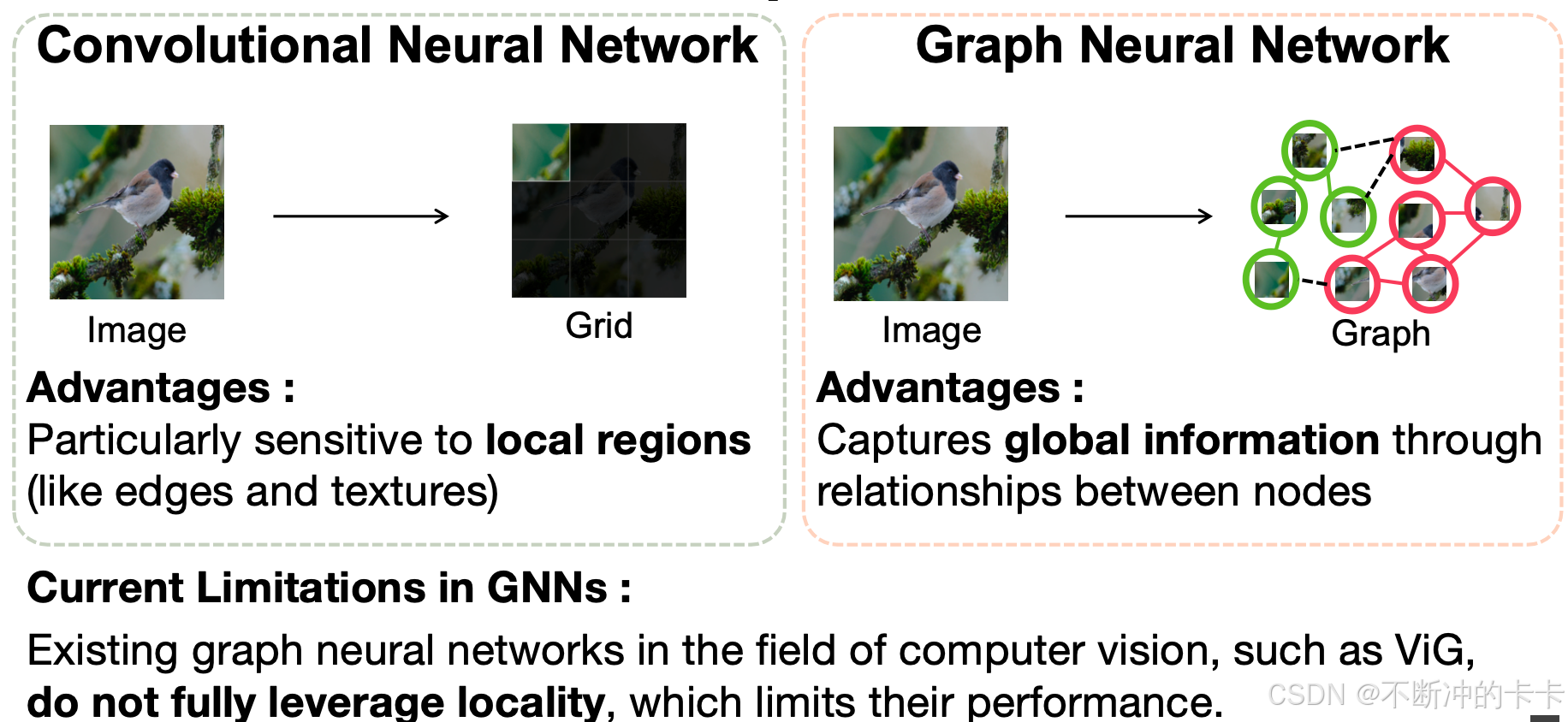
ViG 没有充分利用卷积的局部性,所以我缝了个BottleNeck 在ViG Block 后面,整个模型我叫它GraphConvNet,在ImageNet上提点了。
消融实验:把具有局部性的卷积替换成参数量相当的MLP,这一改动导致模型在ImageNet的性能下降,充分证明了在GNNs 中引入卷积局部性的优势。
这个idea形成的论文Hierarchical Convolution and Graph Net for Utilizing Structural Information of Image已被DSIT2024 (EI核心) [6] 接收。
5. Visualization
上面提到的GraphConvNet 源码及可视化代码的链接,我在代码里也实现了ViG图结点和它近邻结点的可视化
下面是我可视化的方法:我先用GradCAM [7] 算法可视化模型决策过程中的ROI(Regions Of Interest),然后可视化分数最高的patch(图结点)及其近邻结点(只可视化9个近邻,第一个近邻是它自己)。如图2.5所示,可以看见随着网络层数的加深,模型关注的重点从环境转移物体本身。
如果可视化代码看不懂,可以听听我的讲解,其实很简单。讲解链接

6. 后记
ViG后续的工作
①VIHGNN[8](ICCV2023 ,有代码,但是跑不了,有点怀疑这篇工作)
②MobileViG[5] CVPR2023 提高ViG的计算效率,创新点:①从ViG的深度GNN架构->深层CNN-浅层GNN架构②不使用KNN构图而使用固定的图结构,提高计算效率(但是这种方式图结构固定,没办法GNN捕获图中的语义信息)
③GreedyViG[9] CVPR2024 在②基础上 ,稍微改了下结构,用CNN混合GNN当模块。因为②的图结构固定,用特征图的信息估计了一个掩码,来mask掉语义不相关的patch.(想吐槽一下,做实验不在相同的超参下跑实验,比个锤子,这篇batch size 2048, ②的1024,谁知道是超参好还是模型好,)
④WiGNet[10] WACV2024 使用CNN-GNN的架构,GNN中基于kNN构图,然后把Swin-T 的思想融进来,降低kNN构图的计算复杂度
⑤GraphConvNet[6] DSIT2024 ViG只有全局近邻建模,缺乏局部细粒度特征提取能力,在ViG的block后缝了BottleNeck提点,BottleNeck换成相近参数量MLP->性能高于ViG但是低于有局部区域建模的GraphConvNet
代码链接
⭐️1. ViG的Github仓库
⭐️2. GraphConvNet可视化代码,以及pyramid 模型所需要的位置编码插值
碎碎念
- 读研阶段出的成果,除了跟自身能力挂钩外,也跟导师、组的名气、研究方向的关系有着非常大的关系。研究生又是短短几年,有时候做不出成果挺正常的。你想想如果你跑个imagenet ,试一次跑1星期,改几次模型几个月就过去了,还不知道效果好不好。。
- 改模型模块一定要一个一个地改,去做消融,不要一下子改一大块,不然你都不知道是什么模块在work.
问过韩凯大佬如何有针对性地改进模型,即试了一个新模块怎么分析work不work的原因,然后有针对性地修改,这是他的回复
参考文献
[1] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[2] Li G, Muller M, Thabet A, et al. Deepgcns: Can gcns go as deep as cnns?[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 9267-9276
[3] Li Q, Han Z, Wu X M. Deeper insights into graph convolutional networks for semi-supervised learning[C]//Proceedings of the AAAI conference on artificial intelligence. 2018, 32(1).
[4] Dong Y, Cordonnier J B, Loukas A. Attention is not all you need: Pure attention loses rank doubly exponentially with depth[C]//International Conference on Machine Learning. PMLR, 2021: 2793-2803.
[5] Munir M, Avery W, Marculescu R. Mobilevig: Graph-based sparse attention for mobile vision applications[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 2211-2219.
[6]Li Z, Dai D, Yi T. Hierarchical Convolution and Graph Net for Utilizing Structural Information of Image[C]//2024 7th International Conference on Data Science and Information Technology (DSIT). IEEE, 2024: 1-7.
[7] Selvaraju R R, Cogswell M, Das A, et al. Grad-cam: Visual explanations from deep networks via gradient-based localization[C]//Proceedings of the IEEE international conference on computer vision. 2017: 618-626.
[8] Han Y, Wang P, Kundu S, et al. Vision hgnn: An image is more than a graph of nodes[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 19878-19888.
[9] Munir M, Avery W, Rahman M M, et al. GreedyViG: Dynamic Axial Graph Construction for Efficient Vision GNNs[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024: 6118-6127.
[10] Spadaro G, Grangetto M, Fiandrotti A, et al. WiGNet: Windowed Vision Graph Neural Network[J]. arXiv preprint arXiv:2410.00807, 2024.

















 847
847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









