







一、需求背景
在处理或分析大规模GIS数据时,使用并行计算技术是一种有效的解决方案。结合ArcPy的丰富地理处理工具与开源库,如Geopandas和Shapely,可以灵活地满足复杂需求并实现高效开发。该技术路线充分发挥了ArcPy的功能,同时利用Geopandas和Shapely的优势,能够高效地处理和分析大规模空间数据。然而,在实际开发中,可能会遇到以下挑战:
1.如何在ArcPy中实现多进程处理;
2.如何在同一脚本中同时使用ArcPy和开源库;
3.如何在Pro的Python工具箱中实现多进程处理(★★★★★)。
针对这些问题,需要探索具体的解决方案,以确保在高效性与功能性之间取得平衡。
在对以上内容进行展开介绍前,先快速补充一下相关知识。
二、多进程和并发处理
2.1 纯 Python 中的多进程和并发处理
多进程是一种编程模型,它允许一个程序同时执行多个独立的任务或计算过程。在多进程模型中,一个程序可以创建多个进程,每个进程都有自己的内存空间和资源,这些进程可以并行地执行不同的任务。这种模型特别适用于利用多核处理器或多台计算机的能力来加速程序的执行速度。
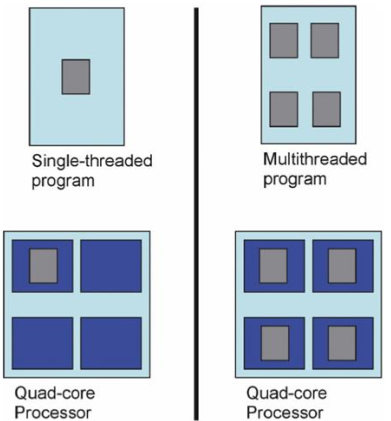
2.1.1 什么是多进程?
多进程是指在一个程序中创建多个独立的进程来并行执行任务的能力。每个进程都是一个独立的执行单元,具有自己的私有内存空间、堆栈和数据段。这意味着每个进程都可以独立地执行自己的代码,并且不会影响其他进程的状态。
多进程的优势:
-
资源隔离:每个进程都有自己的内存空间,这使得进程之间的资源隔离更加容易实现,从而降低了数据竞争的风险。
-
稳定性:如果一个进程崩溃或出现问题,其他进程通常不受影响,这提高了整个程序的稳定性和可靠性。
-
并行计算:在多核处理器上,多进程可以充分利用多个核心,从而提高程序的执行效率和响应速度。
-
易于管理和扩展:由于进程之间相对独立,可以更容易地管理每个进程,并且可以根据需要轻松地添加更多的进程来扩展程序。
多进程的挑战:
-
通信成本:进程间通信通常比线程间通信更昂贵,因为它们需要通过操作系统提供的机制来进行通信,例如管道、套接字或共享内存。
-
上下文切换:虽然多进程可以利用多核处理器,但在不同进程之间切换也会消耗一定的时间和资源。
-
资源管理:每个进程都需要分配和管理自己的资源,这可能会导致额外的资源消耗和管理复杂度。
多进程与多线程的区别:
-
多线程:在一个进程中创建多个线程,共享相同的内存空间。线程之间的通信更快,但资源隔离较差,可能导致数据竞争。
-
多进程:创建多个独立的进程,每个进程都有自己的内存空间。进程间的通信较慢,但资源隔离更好,更稳定。
实际应用:
在实际应用中,多进程经常被用于处理那些可以并行化的工作负载,例如大规模的数据处理、模拟计算、网络服务等。例如,在科学计算中,多进程可以用来并行处理大型数据集,显著加快处理速度。
2.1.2 什么不是多进程?
不属于多进程的情况:
串行程序
-
在一个进程中一次执行一条指令。
-
指令从开始执行到结束。
-
程序崩溃会导致整个程序终止。
-
需要重新开始执行。
-
失败则关闭程序。
并发程序
-
在一个进程中同时执行多条指令。
-
指令可能“休眠”以让其他指令运行。
-
任何时候只有一条指令在执行。
分散式程序
-
网络上的多台计算机。
-
进程/指令在网络中运行。
-
由一个中央“枢纽”控制。
分布式程序
-
网络上的多台计算机。
-
进程/指令在网络中运行。
-
每台计算机独立运行。
2.2 Python 多进程理念
替换循环为并行迭代:
-
概念:在串行程序中,循环通常用于重复执行某项任务。在多进程环境下,可以通过将循环中的任务分配给不同的进程来实现并行处理。
-
实践:使用
multiprocessing.Pool中的map或imap方法可以很容易地将循环操作转换为并行迭代。
替换集合为迭代器/生成器:
-
概念:在多进程场景下,使用迭代器和生成器可以节省内存并提高效率,因为它们按需产生数据而不是一次性加载所有数据到内存中。
-
实践:可以使用生成器表达式或者定义一个生成器函数来创建迭代器。
结合多进程和并发:
-
概念:除了多进程之外,还可以利用多线程或异步 I/O(如 asyncio)来进一步提高程序的并发能力。
-
实践:可以使用
concurrent.futures模块来轻松地结合多进程和多线程。
并行函数与并发指令:
-
概念:将原本顺序执行的函数并行化,同时确保指令能够并发执行。
-
实践:使用
multiprocessing.Process或multiprocessing.Pool来启动并行任务。
容错性:
-
概念:即使某个子进程发生错误也不会导致整个应用程序崩溃。
-
实践:利用
multiprocessing模块提供的异常处理机制,比如使用Process的join()方法来捕获异常。
受限于输入或“映射”函数:
-
概念:控制并行任务的执行速度,通常由输入数据流或处理数据的函数决定。
-
实践:使用
multiprocessing.Queue或multiprocessing.Pipe来控制数据流和任务调度。
验证数据,并发送到可用的 CPU 上进行处理:
-
概念:确保传入的数据有效,并将其分发给空闲的处理器。
-
实践:可以在主进程中进行数据验证,并使用
multiprocessing.Pool的apply_async方法来异步地提交任务。
两种形式的输出:
-
离散返回:每个并行任务完成后立即返回结果,适用于不需要合并结果的情况。
-
聚合“减少”:将多个任务的结果合并成单一结果,通常用于需要汇总分析的情况。
-
实践:对于离散返回,可以直接使用
imap或imap_unordered;对于聚合减少,可以使用reduce函数或类似方法来合并结果。
2.3 Python 模块
2.3.1 threading
-
核心开发者:通常只有在非常熟悉 Python 内部机制的核心开发者才会考虑使用
threading模块。 -
全局解释器锁 (Global Interpreter Lock, GIL):在 CPython 解释器中,GIL 是一种同步机制,它确保了同一时刻只有一个线程可以执行 Python 字节码。这意味着即使在多核处理器上,由单个
python.exe控制的两个线程也不能同时运行 Python 代码。 -
实践:
threading模块适合用于 I/O 密集型任务,如网络请求、文件读写等,而不适合 CPU 密集型任务,因为在 CPU 密集型任务中 GIL 会成为瓶颈。
-
除非有非常明确的原因才使用
2.3.2 multiprocessing
-
不受 GIL 问题的影响:
multiprocessing模块通过创建多个 Python 进程来绕过 GIL 的限制,这意味着每个进程都有自己的 Python 解释器和内存空间,因此不受 GIL 的影响。 -
操作系统负责
python.exe的线程调度:每个进程中的线程调度由操作系统负责,这意味着在多核处理器上,不同的进程可以并行执行。 -
实践:
multiprocessing模块非常适合 CPU 密集型任务,因为它可以让多个 CPU 核心同时工作。它也适用于那些需要在多个进程中并行处理数据的任务。
-
创建多个
python.exe实例
2.3.3 subprocess
-
串行或并行:
subprocess模块可以用来启动外部程序(非 Python 程序),这些程序可以在串行或并行模式下运行。 -
回调允许子进程并行运行:通过使用
subprocess.Popen或concurrent.futures中的ProcessPoolExecutor,可以实现子进程的并行执行。例如,可以通过回调函数来处理子进程的输出,或者使用concurrent.futures来并行启动多个子进程。 -
实践:
subprocess模块非常适合需要调用外部程序或脚本的情况,比如执行系统命令、调用编译器、运行其他语言编写的程序等。通过这种方式,可以在 Python 程序中集成多种外部工具和服务。
-
用于启动非
python.exe进程
2.3.4 Twisted
-
开源 Python 包:Twisted 是一个开源的 Python 库,它能够帮助你管理来自
threading模块的线程,简化并发编程。 -
设计用于处理 I/O 并发:Twisted 被设计用于处理 I/O 密集型任务,特别是网络通信。它提供了一个高性能的事件循环,使你可以编写非阻塞的网络服务器和客户端。
-
Twisted 替你管理
threading中的线程
2.3.5 asyncio
-
设计用于处理 I/O 并发:与 Twisted 类似,
asyncio也是专为 I/O 密集型任务设计的,但它是基于协程的,使你能够编写简洁且高效的异步代码。 -
全新!完全接受于 Python 3.6.0:虽然
asyncio最初是在 Python 3.4 版本中引入的,但在 Python 3.6.0 版本中得到了进一步的发展和完善,并被广泛接受和使用。从那时起,asyncio成为了编写异步代码的标准方式。
-
纯 Python 包:
asyncio是一个内置于 Python 标准库中的包,用于编写单线程并发代码。
2.4 Python并行示例
示例1:multiprocessing
这段代码演示了如何使用 multiprocessing 模块来并行处理任务,并使用 tqdm 来显示每个任务的进度。
import multiprocessing 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1789
1789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











