






1 异常检测方法适用范围
什么时候我们需要异常点检测算法呢?常用的有三种情况。
- 1.做数据预处理的时候需要对异常的数据做过滤,防止对归一化等处理的结果。
- 2.对没有标记输出的特征数据做筛选,找出异常的数据。
- 3.对有标记输出的特征数据做二分类时,由于某些类别的训练样本非常少,类别严重不平衡,此时也可以考虑用非监督的异常点检测算法来做。
在以上场景中,异常的数据量都是很少的一部分,因此诸如:SVM,逻辑回归等分类算法,都不适用,因为监督学习算法适用于有大量的正向样本,也有大量的负向样本,有足够的样本让算法去学习其特征,且未来新出现的样本与训练样本分布一致。
2 基于统计学的方法来处理异常数据
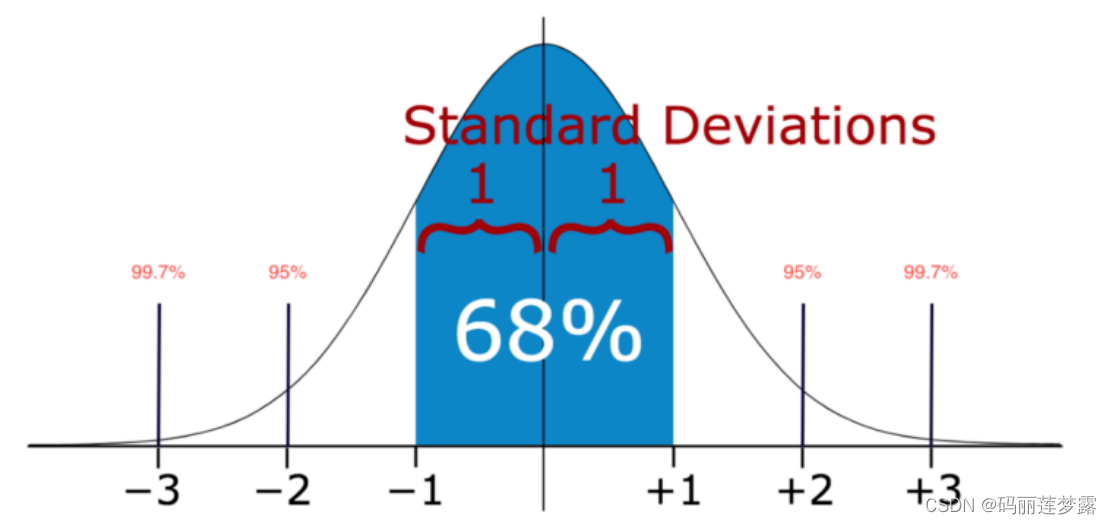
(1) 标准差:
(2) 箱型图:
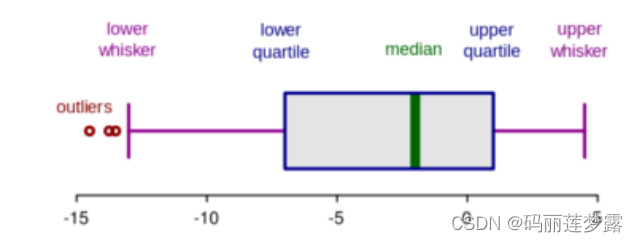
这两种方式源自统计学概念,适用于一维数据集。
3 基于聚类的方法来做异常点检测
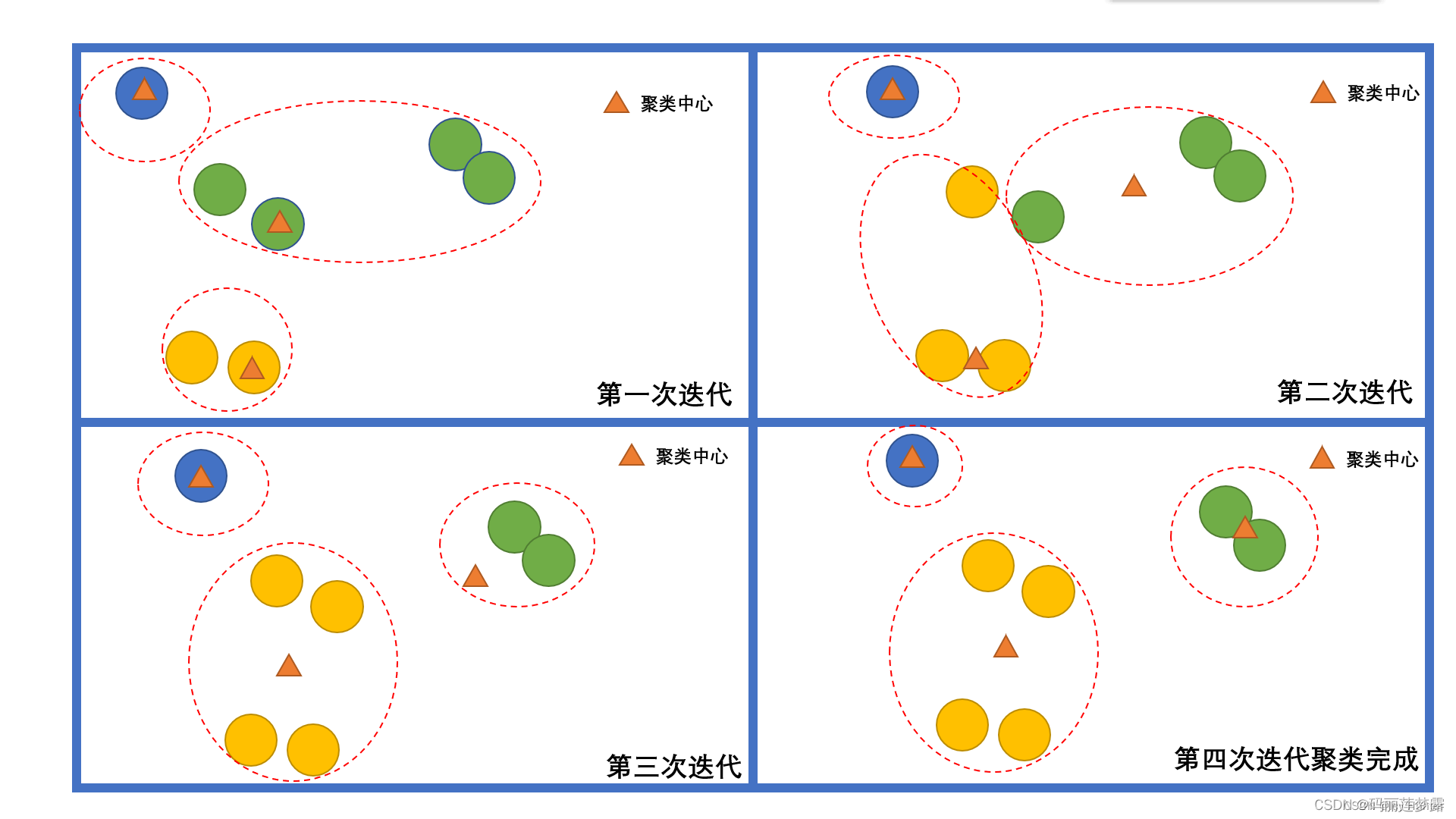
如:k-means、层次聚类、DBSCAN集群等方法,这类方法试图找到数据的正常区域,然后将所定义区域外的任何值视为异常值,通常如果我们聚类后发现某些聚类簇的数据样本量比其他簇少很多,而且这个簇里数据的特征均值分布之类的值和其他簇也差异很大,这些簇里的样本点大部分时候都是异常点。例如:下图为k-means的一个聚类过程,其中蓝色点可认为是异常点。
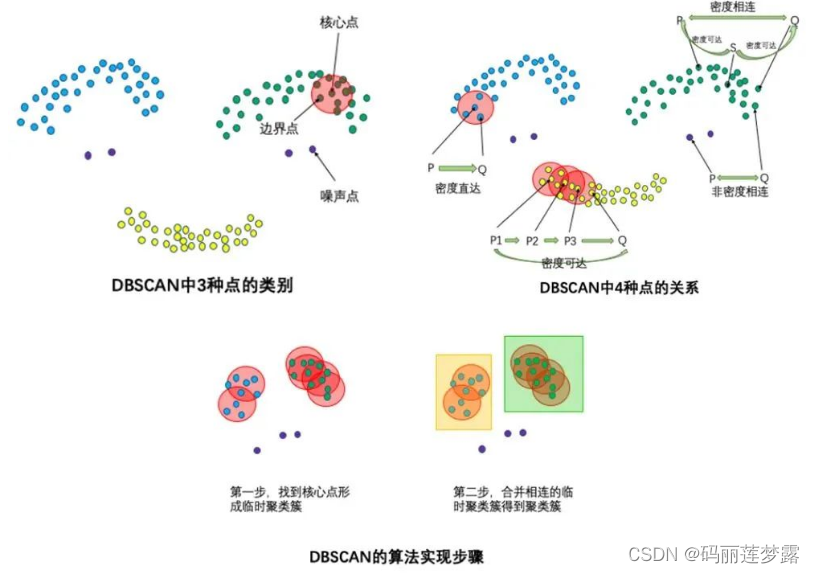
如:DBSCAN算法(Density-Based Spatial Clustering of Applications with Noise)的输入和输出如下,对于无法形成聚类簇的孤立点,即为异常点(噪声点)。
- 输入:数据集,邻域半径Eps,邻域中数据对象数目阈值MinPts;
- 输出:密度联通簇
「下面是一些常见的聚类算法及其基本原理」:
「K-means聚类算法」:K均值聚类是最常用的聚类算法之一。其基本原理是通过计算数据样本与聚类中心之间的距离来确定样本的归属,并将样本分配到最近的聚类中心所代表的簇。然后,根据已分配的样本重新计算聚类中心的位置,迭代更新样本的归属和聚类中心的位置,直到达到停止条件。
「层次聚类算法」:层次聚类是一种自下而上或自上而下的聚类方法。其基本原理是通过计算样本之间的相似性或距离,将相似度高的样本逐步合并为越来越大的簇或者将所有样本初始为一个簇,然后逐步分割为越来越小的簇。这种逐步合并或分割的过程称为聚类树、树状图或者树状结构。
「密度聚类算法」(如DBSCAN):密度聚类是一种基于样本密度的聚类方法。其基本原理是通过确定样本周围邻域内的密度来判断样本是否属于一个簇。密度聚类可以自动发现任意形状和大小的簇,并且对噪声和离群值具有较好的鲁棒性。
4 第三类是基于专门的异常点检测算法来做
这类方法是明确的孤立异常值,而不是通过给每个点分配一个分数来构造正常的点和区域。它充分利用了这样一个事实:异常值只占数据的小部分,并且它们有与正常值大不相同的属性。该算法适用于高维数据集,并且被证实是一种非常有效的检测异常值的方法。
以iForest 算法(Isolation Forest,孤立森林)为例:由于异常数据较小且特征值和正常数据差别很大。因此,构建 iTree的时候,异常数据离根更近,而正常数据离根更远。当然,一颗ITree的结果往往不可信,iForest算法通过多次抽样,构建多颗二叉树。最后整合所有树的结果,并取平均深度作为最终的输出深度,由此计算数据点的异常分支。
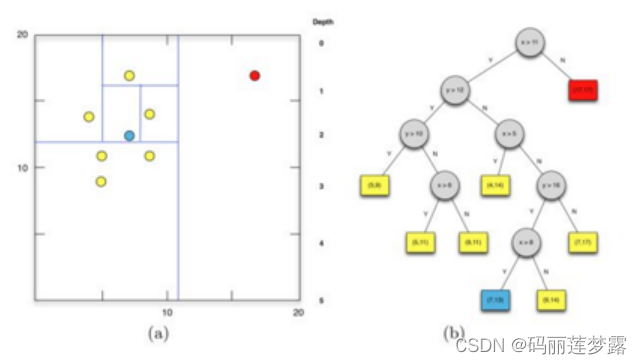
由于在业务场景里,通常是实时流数据。在面对流式数据时,孤立森林会有以下几点问题:
- 数据是随着时间的流逝而产生的,孤立森林会遗漏时间这个维度;
- 孤立森林的每棵树在建立候选样本集合时,采用的是针对整体样本的无放回抽样,而在流式数据中,我们需要每次对最新的数据进行采样,构建出数据集;
- 孤立森林在面对流式数据时,每次来一个点都要重新去构建树,整体耗时以及复杂度较高;
因此后续又在 iForest 算法基础上提出了RRCF(Robust Random Cut Forest,稳健随机采伐森林).
参考:
1 异常检测算法-RRCF(Robust Random Cut Forest) | 秃头少年的boke (zuoxiang95.github.io)
2 独家 | 每个数据科学家应该知道的五种检测异常值的方法(附Python代码)-腾讯云开发者社区-腾讯云 (tencent.com)
3 官方rrcf代码:https://github.com/kLabUM/rrcf
















 3395
3395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











