






卡尔曼滤波,简单来说就是滤波,根据用户反馈的测试值来做预测并做可靠性计算。那么他是怎么做的呢?就目前我的理解而言,他是属于加权平均数的一种用法,就是先通过真实数据和测试数据来计算真实数据和预测数据的权重比,这样说可能比较绕,举一个简单的例子:在一个温度测量系统中,使用ADC将温度传感器输出的电压信号转换为数字信号。由于热噪声和其他因素的影响,ADC的输出可能包含一些误差。卡尔曼滤波器可以通过以下步骤来估计ADC的输出:
初始化:我们需要初始化卡尔曼滤波器的状态估计值和误差协方差矩阵。在这个例子中,可以将初始温度估计值设为ADC输出的数字信号,将误差协方差矩阵设为一个较大的值。
预测:在预测步骤中,我们使用系统的动态模型和卡尔曼滤波器的状态估计值来预测ADC的输出。在这个例子中,我们可以使用以下公式进行预测:
T_pred = T_est
P_pred = P_est + Q
其中T_pred是预测的温度估计值,P_pred是预测的误差协方差矩阵,Q是热噪声的协方差矩阵。
更新:在更新步骤中,我们使用ADC的输出和卡尔曼滤波器的预测温度估计值来更新系统的温度估计值。在这个例子中,我们可以使用以下公式进行更新:
y_pred = T_pred
S = P_pred + R
K = P_pred / S
T_est = T_pred + K * (y - y_pred)
P_est = (I - K) * P_pred
其中y是ADC的输出,R是ADC的分辨率和量化误差的协方差矩阵,K是卡尔曼增益,T_est是更新的温度估计值,P_est是更新的误差协方差矩阵。重复步骤2和步骤3,直到我们处理完所有的ADC输出。
通过以上步骤,我们可以使用卡尔曼滤波器来估计ADC的输出值,并减小噪声对信号的影响。在实际应用中,需要根据具体的情况调整卡尔曼滤波器的参数,例如初始温度估计值、误差协方差矩阵、热噪声的协方差矩阵、ADC的输出、分辨率和量化误差的协方差矩阵等。
经过使用,发现在数据不是线性变化的算法里边并不适用,也就是说在原始数据不是线性曲线的话在使用上会自己的粗见,因为是第一次使用,还不是很了解,所以使用下来有这个发现,但是对他小噪声的优化处理特别好,可以过滤大部分噪声,下面是从我二师父哪里搞来的一个小例子:
/***********************************************************************************************************
* @描述 : 卡尔曼滤波初始化
*@kalman_lcw:卡尔曼滤波器结构体
*@init_x:待测量的初始值
*@init_p:后验状态估计值误差的方差的初始值
***********************************************************************************************************/
void kalman_init(kalman_struct *kalman_lcw, float init_x, float init_p)
{
kalman_lcw->x = init_x;//待测量的初始值,如有中值一般设成中值(如陀螺仪)
kalman_lcw->p = init_p;//后验状态估计值误差的方差的初始值
kalman_lcw->A = 1;
kalman_lcw->H = 1;
kalman_lcw->q = 1500*5e-2;//10e-6;//2e2;predict noise convariance 预测(过程)噪声方差 实验发现修改这个值会影响收敛速率
kalman_lcw->r = 10e1;//10e-5;//测量(观测)噪声方差。以陀螺仪为例,测试方法是:
}
/***********************************************************************************************************
* @描述 : 卡尔曼滤波器
*@kalman_lcw:卡尔曼结构体
*@measure;测量值
***********************************************************************************************************/
float kalman_filter(kalman_struct *kalman_lcw, float measure)
{
/* Predict */
kalman_lcw->x = kalman_lcw->A * kalman_lcw->x;
kalman_lcw->p = kalman_lcw->A * kalman_lcw->A * kalman_lcw->p + kalman_lcw->q; /* p(n|n-1)=A^2*p(n-1|n-1)+q */
/* Measurement */
kalman_lcw->gain = kalman_lcw->p * kalman_lcw->H / (kalman_lcw->p * kalman_lcw->H * kalman_lcw->H + kalman_lcw->r);
kalman_lcw->x = kalman_lcw->x + kalman_lcw->gain * (measure - kalman_lcw->H * kalman_lcw->x);
kalman_lcw->p = (1 - kalman_lcw->gain * kalman_lcw->H) * kalman_lcw->p;
return kalman_lcw->x;
}下面是主函数,将卡尔玛初始值设置为0,后验状态估计值误差的方差的初始值设置为2,也就是该数据和真实值的一个误差的方差,通常情况下设置为最大方差值,或者0,数据是我从一个传感器上面导出的数据,在算法正常的情况下,这两个数据的和是相等的才正确,这里只用于释义。
int main(void)
{
// /* 创建启动任务 */
// xTaskCreate((TaskFunction_t )start_task, //任务函数
// (const char* )"start_task", //任务名称
// (uint16_t )START_STK_SIZE, //任务堆栈大小
// (void* )NULL, //传递给任务函数的参数
// (UBaseType_t )START_TASK_PRIO, //任务优先级
// (TaskHandle_t* )&StartTask_Handler); //任务句柄
// /* 任务调度 */
// vTaskStartScheduler();
//511、471,5e-2
kalman_struct test_kaerman1;
kalman_struct test_kaerman;
float test_fast[]={17.9,23.5,27,32.4,40.5,45.3,50.8,54.7,56.8,60.8,61.4};
float test_slow[]={14.8,16.8,18.6,21.2,24.2,27.3,29.6,30.4,32,33.1,33.7,33.6,32.8,31.7,31.5,31.7,33.2,34.6};
float kaerman_filter_slow[18];
float kaerman_filter_fast[11];
float esp_init = 20;
float kaerman_output_slow = 0;
float kaerman_output_fast = 0;
kalman_init(&test_kaerman,0,2);
kalman_init(&test_kaerman1,0,2);
while(1)
{
//阻抗测量
// impedance_measurement_run();
int i;
for(i = 0;i < esp_init;i++)
{
kaerman_filter_slow[i] = kalman_filter(&test_kaerman1,test_slow[i]);
kaerman_output_slow += kaerman_filter_slow[i];
}
for(i = 0;i < 11;i++)
{
kaerman_filter_fast[i] = kalman_filter(&test_kaerman,test_fast[i]);
kaerman_output_fast += kaerman_filter_fast[i];
}
}下面试程序运行结果,可以很明显的看出,在经过滤波后数据曲线明显更加平滑,这就是我理解的卡尔曼滤波的作用,在线性曲线函数中过滤误差数据,提升数据精度,在对数据精度要求很高的模型中应该会用到的很多,当然,前提是有足够的运行反应时间且算法正确。
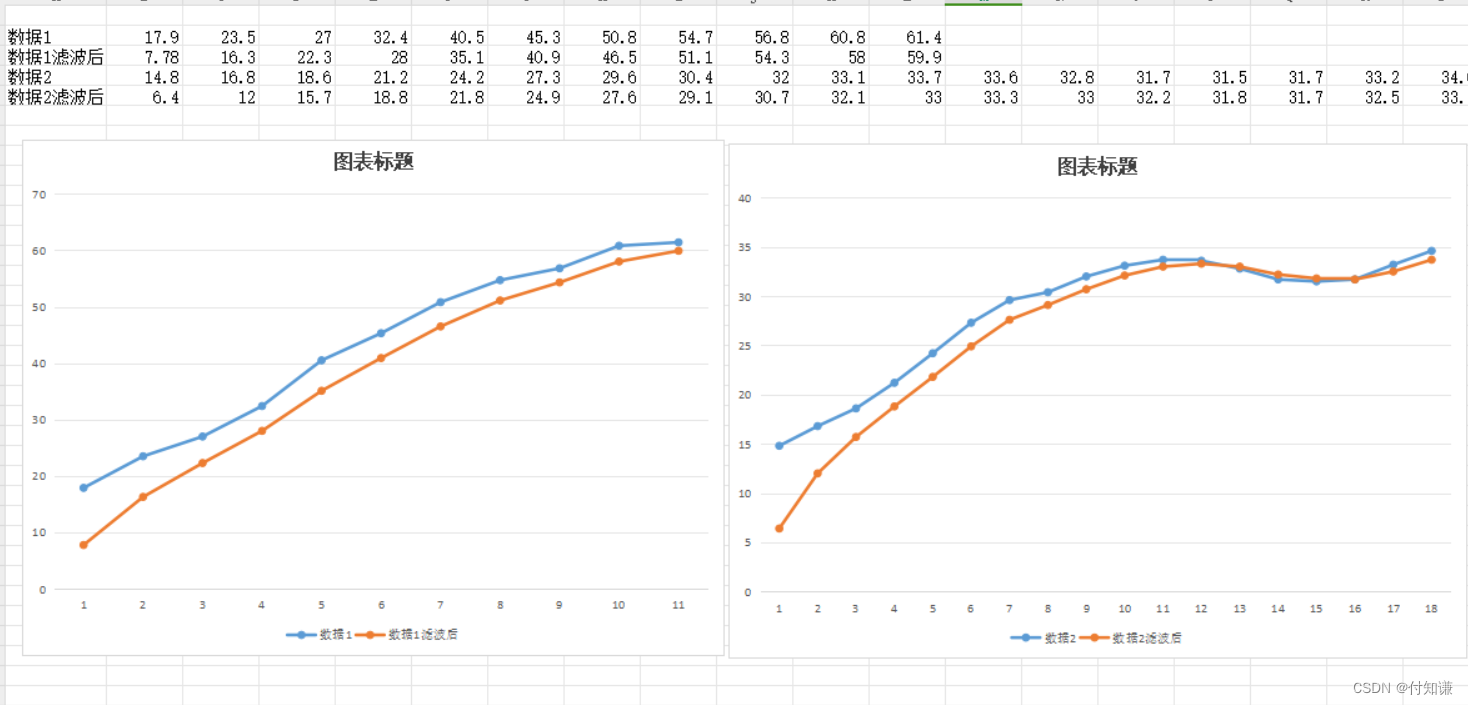
对于卡尔曼滤波的后值可以通过调节里面的参数值来改变他的滤波结果,这种滤波方法需要大量的数据去推导最佳参数,最后才能使模型适应这个滤波算法。
以上就是我的全部学习理解了!

















 3395
3395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









