






HyDE
HyDE介绍
HyDE,全称为Hypothetical Document Embeddings,是一种用于改进信息检索的方法。它通过生成可用于回答用户输入问题的假设文档,来对齐查询和文档的语义空间。这些文档是由大型语言模型(LLM)根据它们自身学习到的知识生成的,然后这些文档被向量化,用于从索引中检索文档。HyDe的工作过程是从使用LLM基于查询生成假设文档开始的,在完成了假设文档的生成后将生成的假设文档输入编码器,将其映射到密集向量空间中。计算生成文档的向量的平均值,该向量保存来自用户的查询和所需答案模式的信息,使用向量从文档库中检索答案,以提高检索的准确性和召回率。
HyDE(Hypothetical Document Embeddings)的优越性主要体现在以下几个方面:
- 无需人工标注数据:HyDE能够在没有人工标注数据的情况下进行zero-shot稠密检索,这使得它在没有足够训练数据的场景下也能发挥作用。
- 提高语义对齐:HyDE通过生成假设文档来对齐查询和文档的语义空间,这有助于改善查询和检索文档之间的语义匹配,尤其是在原始查询较短或措辞不准确时。
- 提升检索效果:HyDE通过生成的假设文档来增强检索结果的相关性,这可以提高检索的准确性和召回率。
- 适应性强:HyDE能够适应不同的查询类型,包括那些需要高级概念抽象推理的查询,通过生成假设文档来改善检索结果。
- 易于集成:HyDE可以与现有的检索系统和大型语言模型(LLM)集成,无需对现有系统进行大规模修改即可提升性能。
- 改善特定查询的召回效果:对于某些特定的查询,HyDE通过生成包含关键信息的假设文档,能够显著提升召回效果,尤其是当原始查询难以直接匹配到相关文档时。
- 无监督学习:HyDE不需要训练任何模型,它使用的生成模型和对比编码器都保持不变,这减少了对训练数据的依赖。
- 提升向量检索的解释性:HyDE通过生成假设文档,可以提高向量检索的可解释性,使得检索结果更容易被理解和分析。
这些优越性使得HyDE成为一种强大的工具,可以显著提升信息检索系统的性能,尤其是在需要处理复杂查询或缺乏标注数据的情况下。任何一种技术方案有优点就会有缺点,HyDE的缺点如下:
- 生成文档的准确性:生成的假设文档可能包含错误的细节,这会影响检索结果的相关性。虽然HyDE使用无监督编码来过滤错误细节,但生成文档的准确性仍然是一个挑战。
- 计算和存储成本:HyDE涉及生成文档和向量化处理,这可能导致较高的计算和存储成本,尤其是在处理大规模文档库时。
- 索引时间:生成假设文档并进行编码可能需要一定的时间,这可能会影响检索系统的响应速度。
- 结果解释性:虽然HyDE提高了检索的语义对齐,但生成的假设文档可能难以解释,这可能会降低检索结果的可解释性。
- 特定查询的限制:HyDE可能在某些特定类型的查询上表现更好,而在其他类型的查询上可能效果不佳,这取决于生成的假设文档与实际文档的相关性。
- 对训练数据的依赖:尽管HyDE是一种无监督学习方法,但它的性能仍然可能受到语言模型训练数据质量和数量的影响。
- 可能的偏差:大型语言模型可能存在偏差,这可能会通过生成的假设文档传递到检索结果中,导致偏差或不公平的检索结果。
- 技术复杂性:HyDE的实现可能相对复杂,需要专业知识来集成和优化,这可能限制了其在某些应用场景中的使用。
- 对特定领域知识的适应性:HyDE可能需要针对特定领域进行调整,以生成更准确的假设文档,这可能需要额外的领域知识或定制化的工作。
HyDE的代码实现
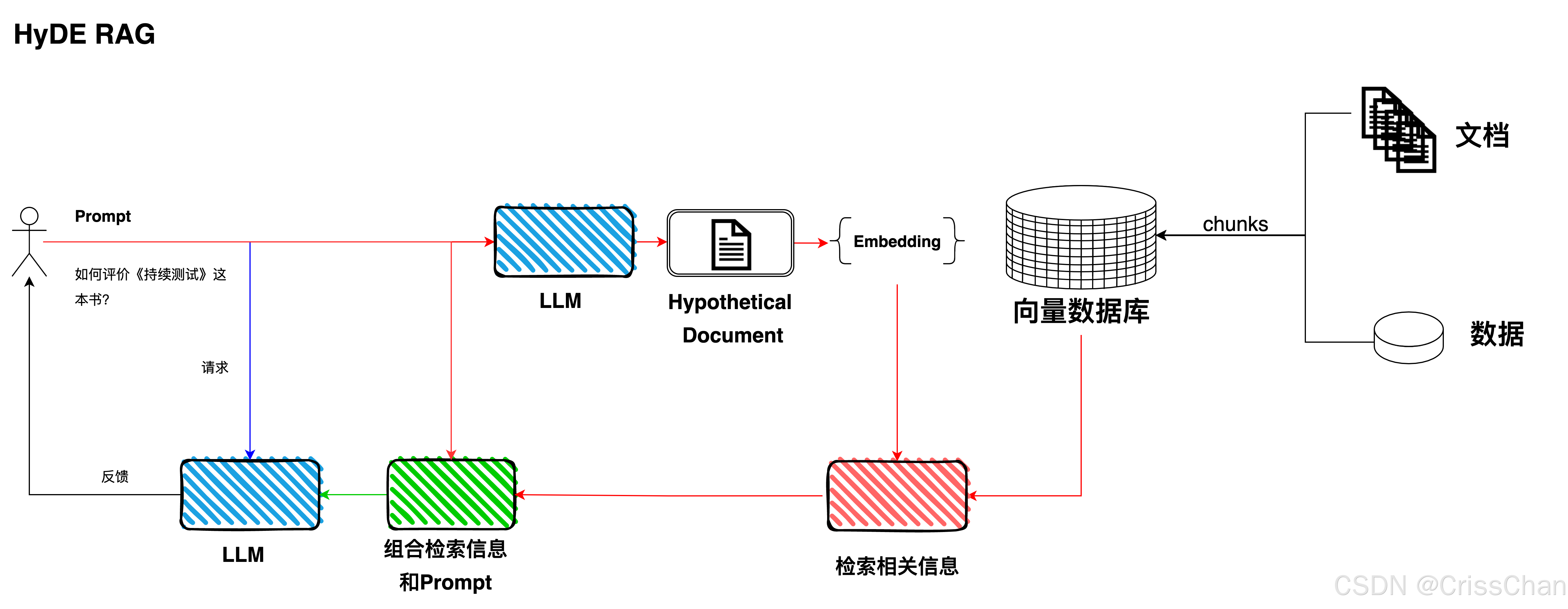
HyDE既有显著提升信息检索系统的性能的优点,也有一些潜在的缺点,但是HyDE仍然是一种有前景的技术,仍然在信息检索领域发挥重要作用。LlamaIndex就提供了HyDE的实现方式,具体如下代码。
首先引入依赖
from llama_index.core import (
SimpleDirectoryReader,
VectorStoreIndex,
StorageContext,
Settings,
get_response_synthesizer)
from llama_index.core.query_engine import RetrieverQueryEngine, TransformQueryEngine
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.schema import TextNode, MetadataMode
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.ollama import Ollama
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.indices.query.query_transform import HyDEQueryTransform
import qdrant_client
import logging
初始化变量
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# load the local data directory and chunk the data for further processing
docs = SimpleDirectoryReader(input_dir="data", required_exts=[".pdf"]).load_data(show_progress=True)
text_parser = SentenceSplitter(chunk_size=512, chunk_overlap=100)
text_chunks = []
doc_ids = []
nodes = []
创建向量存储
# Create a local Qdrant vector store
logger.info("initializing the vector store related objects")
client = qdrant_client.QdrantClient(host="localhost", port=6333)
vector_store = QdrantVectorStore(client=client, collection_name="research_papers")
初始化llm和embeddingmodle
# local vector embeddings model
logger.info("initializing the OllamaEmbedding")
embed_model = OllamaEmbedding(model_name='mxbai-embed-large', base_url='http://localhost:11434')
logger.info("initializing the global settings")
Settings.embed_model = embed_model
Settings.llm = Ollama(model="llama3", base_url='http://localhost:11434')
Settings.transformations = [text_parser]
完成HyDE的调用
logger.info("enumerating docs")
for doc_idx, doc in enumerate(docs):
curr_text_chunks = text_parser.split_text(doc.text)
text_chunks.extend(curr_text_chunks)
doc_ids.extend([doc_idx] * len(curr_text_chunks))
logger.info("enumerating text_chunks")
for idx, text_chunk in enumerate(text_chunks):
node = TextNode(text=text_chunk)
src_doc = docs[doc_ids[idx]]
node.metadata = src_doc.metadata
nodes.append(node)
logger.info("enumerating nodes")
for node in nodes:
node_embedding = embed_model.get_text_embedding(
node.get_content(metadata_mode=MetadataMode.ALL)
)
node.embedding = node_embedding
logger.info("initializing the storage context")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
logger.info("indexing the nodes in VectorStoreIndex")
index = VectorStoreIndex(
nodes=nodes,
storage_context=storage_context,
transformations=Settings.transformations,
)
logger.info("initializing the VectorIndexRetriever with top_k as 5")
vector_retriever = VectorIndexRetriever(index=index, similarity_top_k=5)
response_synthesizer = get_response_synthesizer()
logger.info("creating the RetrieverQueryEngine instance")
vector_query_engine = RetrieverQueryEngine(
retriever=vector_retriever,
response_synthesizer=response_synthesizer,
)
logger.info("creating the HyDEQueryTransform instance")
hyde = HyDEQueryTransform(include_original=True)
hyde_query_engine = TransformQueryEngine(vector_query_engine, hyde)
logger.info("retrieving the response to the query")
response = hyde_query_engine.query(
str_or_query_bundle="what are all the data sets used in the experiment and told in the paper")
print(response)
client.close()



















 4668
4668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











