本讲将从基础的马尔科夫过程开始讲解,到马尔科夫奖励过程,马尔科夫决策过程,最后也会用代码巩固这部分理论. 马尔科夫过程 马尔科夫奖励过程 马尔科夫决策过程 编程实践 参考 在上一讲我们提到过,在一个时序过程中,如果
t
+
1
t+1
t + 1
S
t
S_t
S t
t
t
t
t
t
t
S
t
S_t
S t 如果过程中每一个状态都具有马尔科夫性,则这个过程具备马尔科夫性.具备了马尔科夫性的随机过程被称为马尔科夫过程(Markov process),又称马尔科夫链(Markov property).而且一旦
S
t
S_t
S t
S
1
,
⋯
,
S
t
−
1
S_1,\cdots,S_{t-1}
S 1 , ⋯ , S t − 1
S
t
+
1
S_{t+1}
S t + 1 描述一个马尔科夫过程的核心是状态转移矩阵:
P
s
s
′
=
P
[
S
t
+
1
=
s
′
∣
S
t
=
s
]
(
2.1
)
P_{ss'} = P[S{t+1} = s'|S_t = s] (2.1)
P s s ′ = P [ S t + 1 = s ′ ∣ S t = s ] ( 2 . 1 ) 这个公式中的状态转移概率矩阵定义了从任意一个状态s到其所有后继状态
s
′
s'
s ′ 其中每一行的数据表示从某一个状态到所有n个状态的转移概率值,每一行这些值加起来的和应该为1
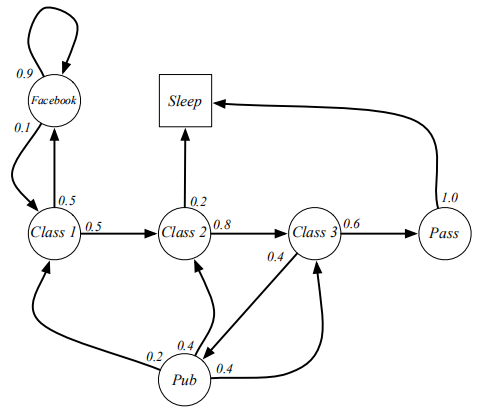
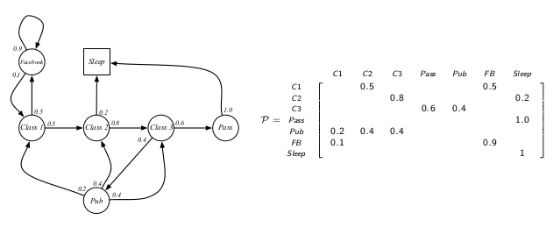
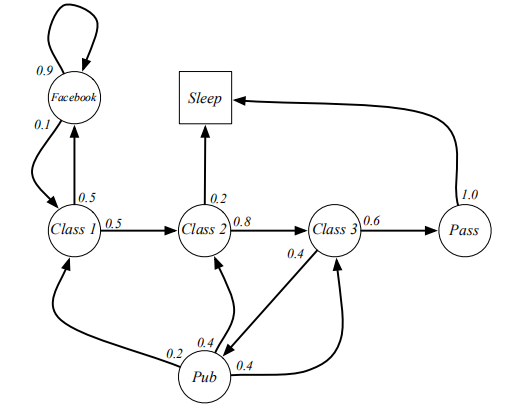
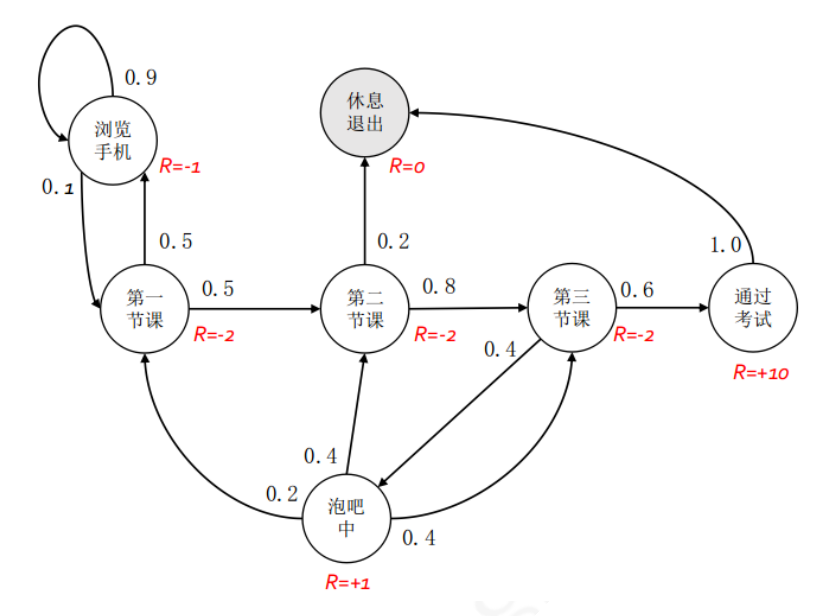
本讲都会使用一个学生学习一门课程这个例子来讲解马尔科夫过程.在这个随机过程中,学生需要顺利完成三节课并且最终通过考试来完成这门课程的学习. 学生处在第一节课(Class1)时,他有50%的几率会参加第2节课(Class2);同时在也有50%的几率进入到浏览facebook这个状态中。在浏览facebook这个状态时,他有90%的几率在下一时刻继续浏览,也有10%的几率重新听第一堂课。当学生进入到第二节课(Class2)时,会有80%的几率继续参加第三节课(Class3),也有20%的几率觉得课程较难而退出(Sleep)。当学生处于第三节课这个状态时,他有60%的几率通过考试,继而100%的通过考试,也有40%的可能性因为觉得课程太简单去酒吧(Pub)了,此后根据其对课堂内容的理解程度,又分别有20%、40%、40%的几率返回值第一、二、三节课重新继续学习。 在上图中,我们使用带有文字的空心圆圈来描述学生所在的状态,连接状态的箭头表示状态转移过程,箭头附近的数字表明着发生箭头所示方向状态转移的概率. 假设学生现在正在状态"第一节课(Class 1)"中,我们按照马尔科夫过程给出的状态转移概率可以得到若干学生随后的状态转化序列.例如下面的这四个序列都是可能存在的状态转化序列(注:Sleep状态是一个终止状态): C1-C2-C3-Pass-Sleep C1-FB-FB-C1-C2-Sleep C1-C2-C3-Pub-C2-C3-Pass-Sleep C1-FB-FB-C1-C2-C3-Pub-C1-FB-FB-FB-C1-C2-C3-Pub-C2-Sleep 该学生马尔科夫过程的状态转移矩阵如下图: 从符合马尔科夫过程给定的状态转移概率矩阵生成一个状态序列的过程称为采样(sample).采样将得到一系列状态转换过程,本书我们称为状态序列(episode).当状态序列的最后一个状态是终止状态时,该状态序列成为完整的状态序列. 马尔科夫过程只涉及到状态之间的转移概率,并没有涉及到我们第一讲提到的伴随状态转换的奖励反馈.如果把奖励也考虑进马尔科夫过程中,则成为马尔科夫奖励过程(Markov Reward Process).它是由<
S
,
P
,
R
,
γ
S,P,R,\gamma
S , P , R , γ
S
S
S
P
P
P
R
R
R
R
s
=
E
[
R
t
+
1
∣
S
t
=
s
]
R_s = E[R_{t+1}|S_t = s]
R s = E [ R t + 1 ∣ S t = s ]
γ
\gamma
γ 细心的读者应该会发现,奖励函数中的奖励是
t
t
t
t
+
1
t+1
t + 1 学生到达每一个状态能获得多少奖励不是学生自己能决定的,而是由充当环境的授课老师来确定,从强化学习的角度来说,奖励由环境动力学确定.在该学生马尔科夫奖励过程中,授课老师的主要目的是希望学生能够尽早的通过考试,因而给了pass这个状态比较高的奖励,而对于过程中的其他状态多数给的是负奖励.从学生的角度来说,学生的目标是在学习一门课程的过程中尽可能多的累积奖励,对于这个例子来说也就是尽早到达pass这个状态从而进入sleep这个终止状态,完成一个完整的状态序列.在强化学习中,我们给这个累计奖励一个新的名字"收获". 收获是一个马尔科夫奖励过程中从某一个状态
S
t
S_t
S t
G
t
=
R
t
+
1
+
γ
R
t
+
2
+
⋯
=
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
(
2.3
)
G_t = R_{t+1} + \gamma R_{t+2} + \cdots = \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} (2.3)
G t = R t + 1 + γ R t + 2 + ⋯ = ∑ k = 0 ∞ γ k R t + k + 1 ( 2 . 3 ) 收获是对应于状态序列中的某一个时刻的状态的,计算从该状态开始直至结束还能获得的累积奖励.从这个式子我们也可以看出,收获并不是后续状态的奖励直接相加,而是引入了一个衰减系数
γ
\gamma
γ 衰减系数是一个0到1的数,引入这个系数使得后续某一状态对当前状态收获的贡献要小于奖励.这样设计从数学上可以避免在计算收获时陷入循环而无法求解.从现实考虑也反映了远期奖励对于当前状态具有一定的不确定性,需要折扣计算.也符合人类更看重眼前利益的性格 当
γ
\gamma
γ
γ
\gamma
γ 价值是马尔科夫奖励过程中状态收获的期望,数学表达式为
v
(
s
)
=
E
[
G
t
∣
S
t
=
s
]
(
2.4
)
v(s) = E[G_t|S_t = s] (2.4)
v ( s ) = E [ G t ∣ S t = s ] ( 2 . 4 ) 从式(2.4)可以看出,一个状态的价值是该状态收获的期望,也就是说从该状态开始依据状态转移概率矩阵采样生成一系列的状态序列,对每一个状态序列计算该状态的收获,然后对该状态的所有收获计算平均值得到一个平均收获. 这里我们举G1的例子来说明这个问题 我们可以看到class 1是有4条路径的,每条路径都有对应的概率,那如果我们要计算class 1的价值,那么我们就要先分别求出这四个状态序列收获的期望(上图已算出),然后再求平均(我们假设这四条路径的概率都有1/4):
v
(
s
)
=
(
−
2.25
+
(
−
3.125
)
+
(
−
3.41
)
+
(
−
3.20
)
)
/
4
=
2.996
v(s) = (-2.25+(-3.125)+(-3.41)+(-3.20))/4 =2.996
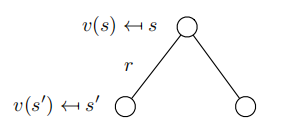
v ( s ) = ( − 2 . 2 5 + ( − 3 . 1 2 5 ) + ( − 3 . 4 1 ) + ( − 3 . 2 0 ) ) / 4 = 2 . 9 9 6 如果存在一个函数,给定一个状态就能得到该状态对应的价值,那么该函数就被称为价值函数.价值函数建立了从状态到价值的映射. 从价值的定义可以看出,得到每一个状态的价值进而得到状态的价值函数对于强化学习是非常重要的.但是通过计算收获的平均值来求解状态的价值不是一个可取的方法,因为一个马尔科夫过程针对一个状态可能可以产生无穷多个不同的序列 我们对价值函数中的收获按照它的定义展开: 这个推导过程对于大家来说应该不难,主要的疑问可能是在倒数第二行到最后一行的时候,将
G
t
+
1
G_{t+1}
G t + 1
v
(
S
t
+
1
)
v(S_{t+1})
v ( S t + 1 )
t
+
1
t+1
t + 1
v
(
s
)
=
E
[
R
t
+
1
+
γ
v
(
S
t
+
1
)
∣
S
t
=
s
]
(
2.5
)
v(s) = E[R_{t+1} + \gamma v (S_{t+1})|S_t = s] (2.5)
v ( s ) = E [ R t + 1 + γ v ( S t + 1 ) ∣ S t = s ] ( 2 . 5 ) 在式2.5中,根据马尔科夫奖励过程的定义,
R
t
+
1
R_{t+1}
R t + 1
R
t
+
1
R_{t+1}
R t + 1
s
′
s'
s ′
s
s
s 那么上述方程可以写成:
v
(
s
)
=
R
s
+
γ
∑
s
′
∈
S
P
s
s
′
v
(
s
′
)
(
2.6
)
v(s) = R_s + \gamma \sum_{s' \in S} P_{ss'}v(s') (2.6)
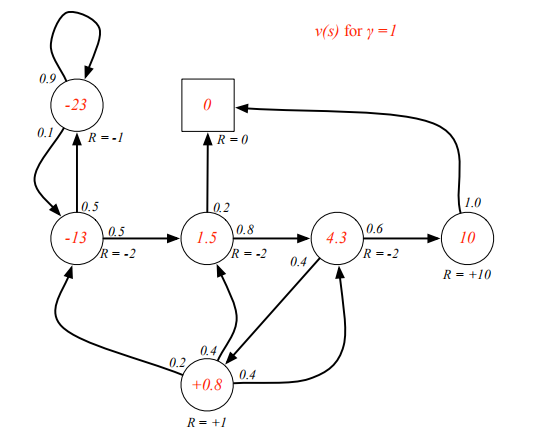
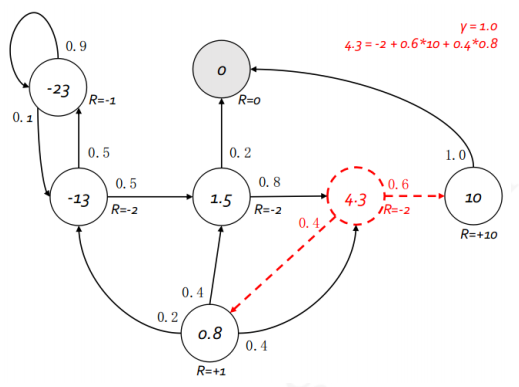
v ( s ) = R s + γ ∑ s ′ ∈ S P s s ′ v ( s ′ ) ( 2 . 6 ) 上式称为马尔科夫奖励过程中的贝尔曼方程(Bellman equation),它提示一个状态的价值由该状态的奖励以及后续状态价值按概率分布求和按一定衰减比例联合组成 下图根据奖励值和衰减系数的设定给出了学生马尔科夫奖励过程中各状态的价值,并对状态"第三节课"进行了验证演算 贝尔曼方程可以写成如下矩阵的形式:
v
=
R
+
γ
P
v
(
2.7
)
v = R + \gamma P v (2.7)
v = R + γ P v ( 2 . 7 ) 它表示: 因为贝尔曼过程是一个线性方程组,所以理论上该方程可以直接求解: 计算复杂度是
O
(
n
3
)
O(n^3)
O ( n 3 )
n
n
n 通过马尔科夫奖励过程,我们明白如果个体知道了每一个状态的价值,就可以通过比较后续状态价值的大小而得到自身努力的方向是那些拥有较高价值的状态,这样一步步朝着拥有最高价值的状态进行转换.从第一讲我们可以知道,个体需要采取一定的行为才能实现状态的转换,而状态转换又与环境动力学有关.很多时候个体期望自己的行为能够到达下一个价值较高的状态,但是它并不能顺利实现,这个时候个体更需要考虑在某一个状态下采取从所有可能的行为方案中选择哪个行为更有价值,这就要引入马尔科夫决策过程,行为,策略等概念. 马尔科夫决策过程是由<
S
,
A
,
P
,
R
,
γ
S,A,P,R,\gamma
S , A , P , R , γ
S
S
S
A
A
A
P
P
P
P
s
s
′
a
=
E
[
R
t
+
1
∣
S
t
=
s
,
A
t
=
a
]
P^a_{ss'} = E[R_{t+1}|S_t = s, A_t = a]
P s s ′ a = E [ R t + 1 ∣ S t = s , A t = a ]
A
A
A
R
R
R
R
s
a
=
E
[
R
t
+
1
∣
S
t
=
s
,
A
t
=
a
]
R^a_s = E[R_{t+1}|S_t = s, A_t = a]
R s a = E [ R t + 1 ∣ S t = s , A t = a ]
γ
\gamma
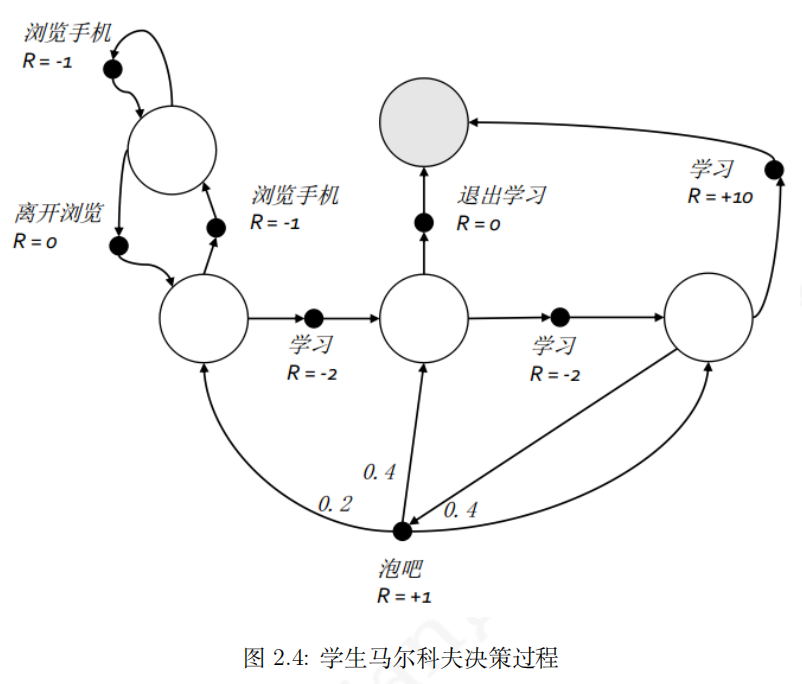
γ 下图给出了一个可能的MDP状态转化图.图中新增了一类黑色实心圆圈表示个体的行为.根据马尔科夫决策过程的定义,奖励和状态转移概率均与行为直接相关,同一个状态下采取不同的行为得到的奖励是不一样的.此图还把通过考试和睡觉状态合并成一个终止状态;另外当个体在状态"第三节课"后选择"泡吧"这个动作时,将被动被环境按照动力学特征分配到另外三个状态,也就是说此时个体没有选择权决定去哪一个状态. 个体在给定状态下从行为集中选择一个行为的依据称为策略(policy),用字母
π
\pi
π
π
\pi
π
π
(
a
∣
s
)
=
P
[
A
t
=
a
∣
S
t
=
s
]
\pi(a|s) = P[A_t = a|S_t = s]
π ( a ∣ s ) = P [ A t = a ∣ S t = s ] 在马尔科夫决策过程中,策略仅通过依靠当前状态就可以产生一个个体的行为,可以说策略仅与当前状态相关,而与历史状态无关.对于不同的状态,个体依据同一个策略也可能产生不同的行为;对于同一个状态,个体依据相同的策略也可能产生不同的行为.策略描述的是个体的行为产生机制,是不随状态变化而变化的,也不与时间有关,所以被认为是静态的(但是个体可以随着时间更新策略) 当给定一个马尔科夫决策过程:$M = <S, A, P, R, \gamma> $ 和一个策略
π
\pi
π
S
1
,
S
2
,
⋯
S_1,S_2,\cdots
S 1 , S 2 , ⋯
的
采
样
.
类
似
的
,
联
合
状
态
和
奖
励
的
序
列
的采样.类似的,联合状态和奖励的序列
的 采 样 . 类 似 的 , 联 合 状 态 和 奖 励 的 序 列
是
一
个
符
合
马
尔
科
夫
奖
励
过
程
是一个符合马尔科夫奖励过程
是 一 个 符 合 马 尔 科 夫 奖 励 过 程 上述公式体现了马尔科夫决策过程中一个策略对应了一个马尔科夫过程和一个马尔科夫奖励过程.不难理解,同一个马尔科夫决策过程,不同的策略会产生不同的马尔科夫(奖励)过程,进而会有不同的状态价值函数.因此在马尔科夫决策过程中有必要扩展先前我们定义的价值函数.
π
\pi
π 定义:价值函数
v
π
(
s
)
v_{\pi}(s)
v π ( s )
π
\pi
π
s
s
s
π
\pi
π 基于策略
π
\pi
π
q
π
(
s
,
a
)
q_{\pi}(s,a)
q π ( s , a )
π
\pi
π
s
s
s
a
a
a 定义了基于策略
π
\pi
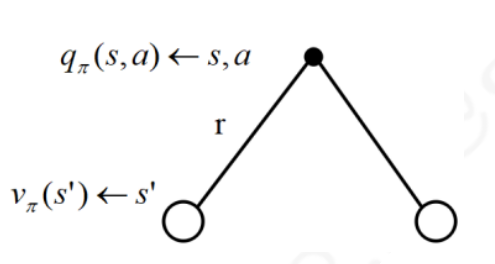
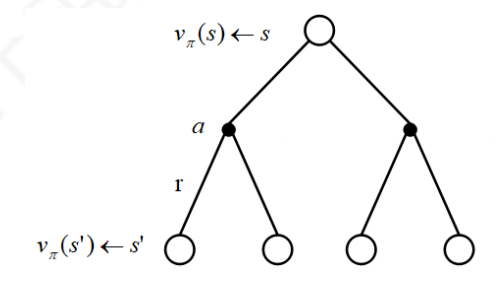
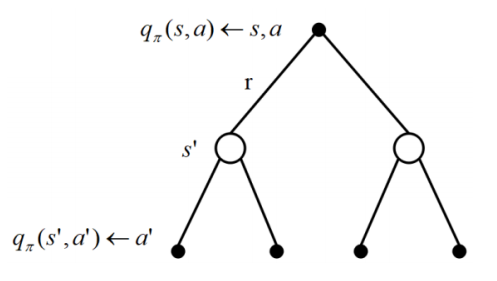
π 由于行为是连接马尔科夫决策过程中状态转换的桥梁,一个行为的价值与状态的价值关系紧密.具体表现为一个状态的价值可以用该状态下所有行为价值来表达: 用下图来表示这个公式,空心较大的圆圈表示状态,黑色实心小圆表示的是动作本身.可以看出,在遵循策额
π
\pi
π
s
s
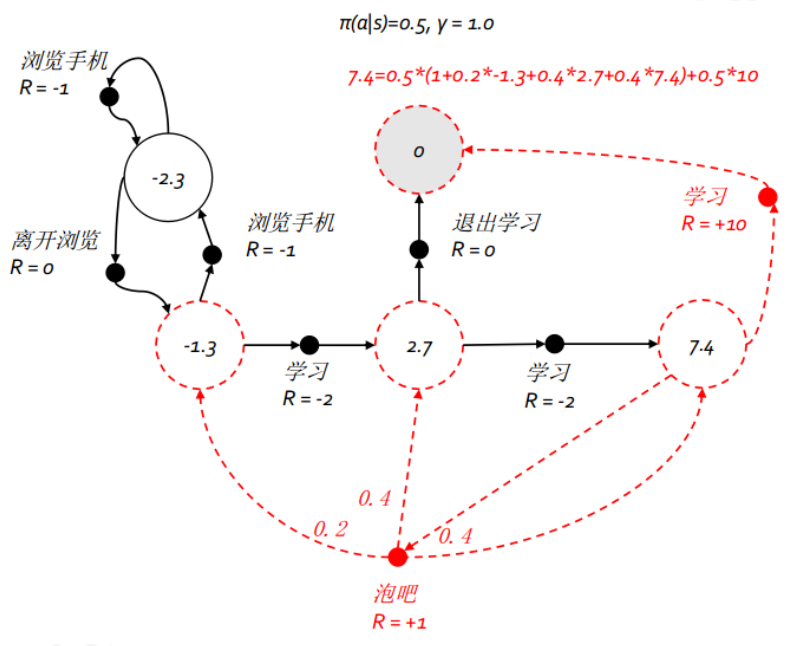
s 类似的,一个行为的价值可以用该行为所能到达的后续状态的价值来表达: 它表明,某一个状态下采取某个行为的价值可以分为两部分,其一是离开这个状态的价值,其二是所有进入新的状态的价值与其状态概率乘积的和 如果把上两式合并,可以得到下面的结果: 也可以得到下面的结果: 下图给出了一个给定策略下学生马尔科夫决策过程的价值函数.每一个状态有且只有两个实质可发生的行为,我们的策略是两种行为以均等(各0.5)的概率被选择执行,同时衰减因子
γ
=
1
\gamma = 1
γ = 1 解决强化学习问题意味着要寻找一个最优的策略让个体在与环境交互过程中获得始终比其他策略都要多的收获,这个最优策略用
π
∗
\pi ^*
π ∗
π
∗
\pi ^*
π ∗ 最优状态价值函数是所有策略下产生的众多状态价值函数中的最大者: 最优行为价值函数是所有策略下产生的众多行为价值函数中的最大者: 定义:策略
π
\pi
π
π
′
(
π
≥
π
′
)
\pi'(\pi \geq \pi')
π ′ ( π ≥ π ′ )
s
s
s
v
π
(
s
)
≥
v
π
′
(
s
)
v_{\pi}(s) \geq v_{\pi'}(s)
v π ( s ) ≥ v π ′ ( s ) 存在如下的结论:对于任何马尔科夫决策过程,存在一个最优策略
π
\pi
π
v
π
∗
(
s
)
=
v
∗
(
s
)
v_{\pi *}(s) = v_*(s)
v π ∗ ( s ) = v ∗ ( s )
q
π
∗
(
s
,
a
)
=
q
∗
(
s
,
a
)
q_{\pi *}(s,a) = q_*(s,a)
q π ∗ ( s , a ) = q ∗ ( s , a ) 最优策略可以通过最大化最优行为价值函数
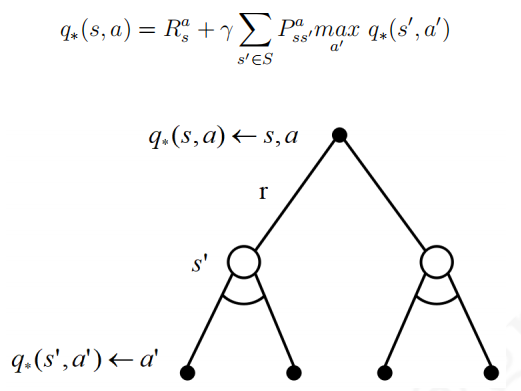
q
∗
(
s
,
a
)
来
获
得
q_*(s,a)来获得
q ∗ ( s , a ) 来 获 得 这个式子表明,在最优行为价值函数已知时,在某一状态
s
s
s
q
∗
(
s
,
a
)
q_*(s,a)
q ∗ ( s , a )
π
∗
(
a
∣
s
)
\pi_*(a|s)
π ∗ ( a ∣ s )
q
∗
(
s
,
a
)
q_*(s,a)
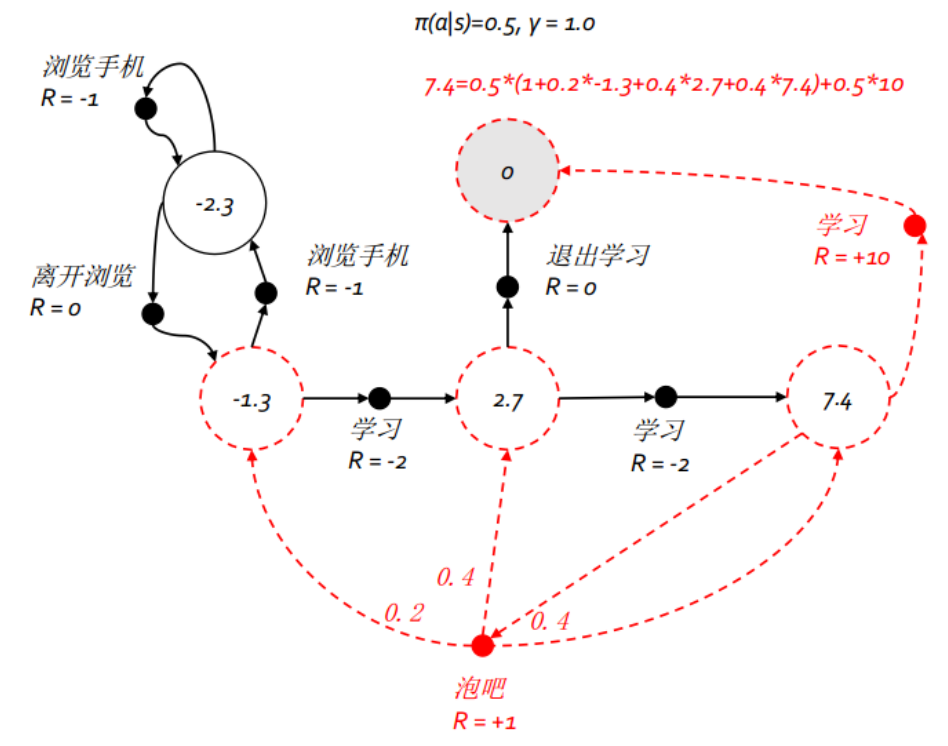
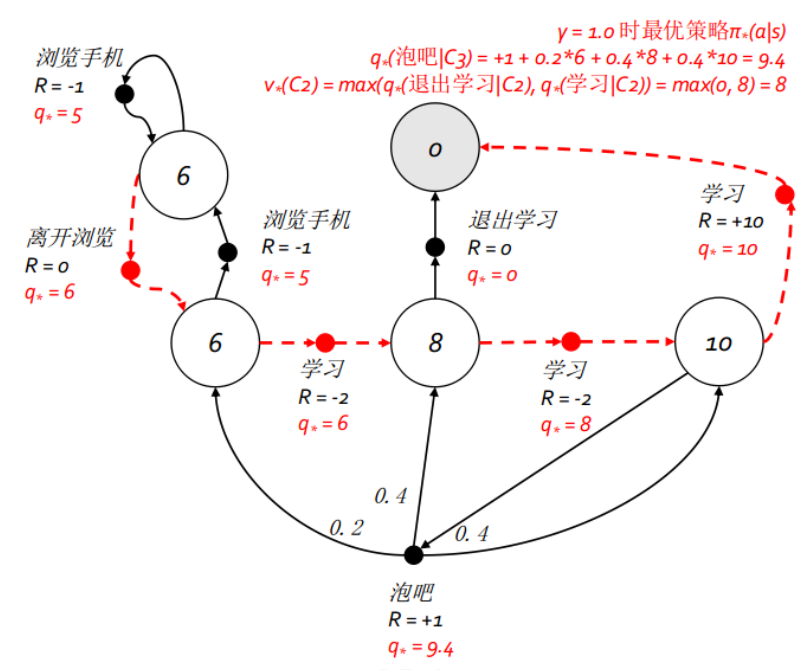
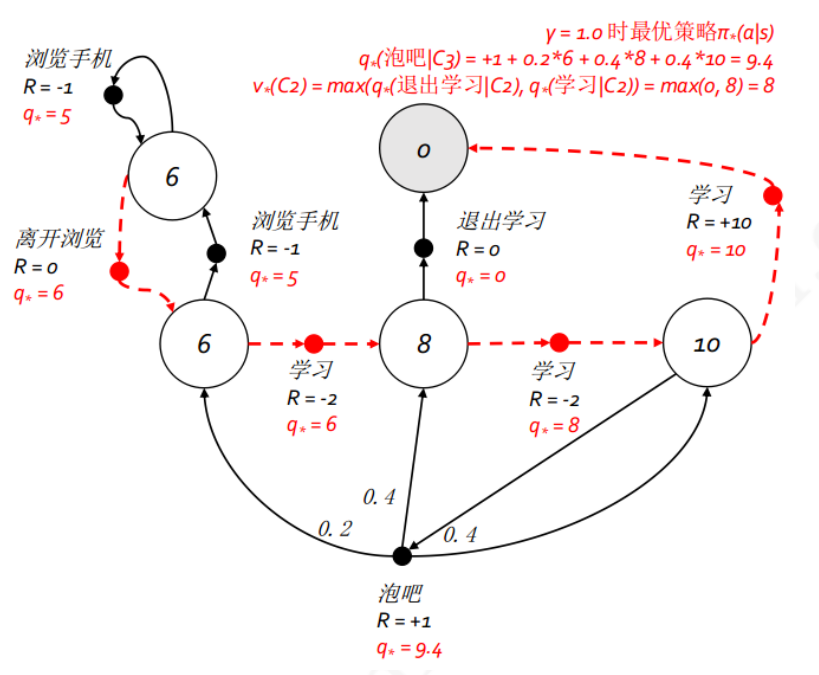
q ∗ ( s , a ) 拿学生马尔科夫决策过程来说,下图中的粗虚箭头指出了最优策略,同时也对应了某个状态下的最优行为价值 在这个例子中,各状态以及相应行为对应的最优价值可以通过回溯法法递归计算得到.其中状态
s
s
s 这个公式表明,一个状态的最优价值是该状态下所有行为对应的最优行为价值的最大值.这不难理解,对于上面的例子学生的状态"第三节课",可以选择的行为有"学习"和"泡吧"两个,其对应的最优行为价值分别为10和9.4,因此状态"第三节课"的最有价值就是两者中最大的10 由于一个行为的奖励和后续状态并不由个体决定,因此在状态
s
s
s
a
a
a 这个公式表明一个行为的最优价值由两部分组成,一部分是执行该行为后环境给予的确定的即时奖励,另一部分则由后续可能状态的最优状态价值按发生概率求和乘以衰减系数得到 同样在学生例子中,考虑学生在"第三节课"时选择行为"泡吧"的最优行为价值,先计入学生采取该行为后得到的即时奖励+1,学生选择该行为后,并不确定下一个状态是什么,环境根据一定的概率确定学生的后续状态时第一节课,第二节课还是第三节课.此时要计算泡吧的行为价值势必不能取这三个状态的最大值,而只能取期望值了,也就是按照进入各种可能状态的概率来估计总的最优价值,具体表现为
6
∗
0.2
+
8
∗
0.4
+
10
∗
0.4
=
8.4
6 ∗ 0.2 + 8 ∗ 0.4 + 10 ∗ 0.4 = 8.4
6 ∗ 0 . 2 + 8 ∗ 0 . 4 + 1 0 ∗ 0 . 4 = 8 . 4
γ
=
1
\gamma = 1
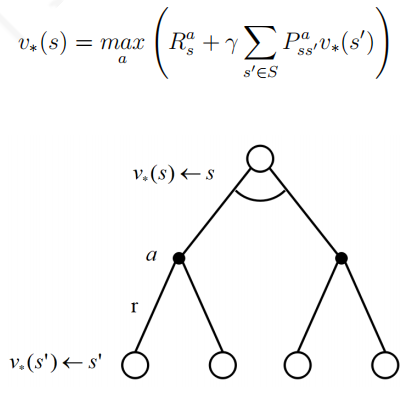
γ = 1 可以看出,某状态的最优价值等同于该状态下所有的行为价值中最大者,某一行为的最优行为价值可以由该行为可能进入的所有后续状态的最优状态价值来计算得到.如果把两者联系起来,那么一个状态的最优价值就可以通过后续可能状态的最优价值计算得到: 类似的,最优行为价值函数也可以由后续最优行为价值函数来计算得到: 贝尔曼最优方程不是线性方程,无法直接求解,通常采用迭代法来求解,具体有价值迭代,策略迭代,Q-learning等多种迭代方法,后续几章将陆续介绍. 本讲的实践将以学生马尔科夫奖励和决策两个示例为核心,通过编写程序并通过观察程序运行结果来加深对马尔科夫奖励过程,马尔科夫决策过程,收获和价值,贝尔曼期望方程和贝尔曼最优方程等知识的理解.
上图给出定义学生马尔科夫奖励过程所需要的信息.其中状态集
S
S
S
7
∗
7
7 * 7
7 ∗ 7 import numpy as np
num_states = 7
i_to_n = { }
i_to_n[ "0" ] = "C1"
i_to_n[ "1" ] = "C2"
i_to_n[ "2" ] = "C3"
i_to_n[ "3" ] = "Pass"
i_to_n[ "4" ] = "Pub"
i_to_n[ "5" ] = "FB"
i_to_n[ "6" ] = "Sleep"
n_to_i = { }
for i, name in zip ( i_to_n. keys( ) , i_to_n. values( ) ) :
n_to_i[ name] = int ( i)
Pss = [ [ 0.0 , 0.5 , 0.0 , 0.0 , 0.0 , 0.5 , 0.0 ] ,
[ 0.0 , 0.0 , 0.8 , 0.0 , 0.0 , 0.0 , 0.2 ] ,
[ 0.0 , 0.0 , 0.0 , 0.6 , 0.4 , 0.0 , 0.0 ] ,
[ 0.0 , 0.0 , 0.0 , 0.0 , 0.0 , 0.0 , 1.0 ] ,
[ 0.2 , 0.4 , 0.4 , 0.0 , 0.0 , 0.0 , 0.0 ] ,
[ 0.1 , 0.0 , 0.0 , 0.0 , 0.0 , 0.9 , 0.0 ] ,
[ 0.0 , 0.0 , 0.0 , 0.0 , 0.0 , 0.0 , 1.0 ] ,
]
Pss = np. array( Pss)
rewards = [ - 2 , - 2 , - 2 , 10 , 1 , - 1 , 0 ]
gamma = 0.5
至此,学生马尔科夫奖励过程就建立了.接下来我们要建立一个函数用来计算一状态序列中某一状态的收获.由于收获值是针对某一状态序列里的某一状态的,因此我们给传递的这个方法的参数需要有一个马尔科夫链,要计算的状态以及衰减系数值,使用计算奖励收获的公式来计算,代码如下: def compute_return ( start_index = 0 , chain = None , gamma = 0.5 ) - > float :
'''
计算一个马尔科夫奖励过程中某状态的收获值
:param start_index: 要计算的状态在链中的位置
:param chain: 要计算的马尔科夫过程
:param gamma: 折扣因子
:return: 收获值
'''
retrn, power, gamma = 0.0 , 0 , gamma
for i in range ( start_index, len ( chain) ) :
retrn += np. power( gamma, power) * rewards[ n_to_i[ chain[ i] ] ]
power += 1
return retrn
我们定义一下几条以S1为初始状态的马尔科夫链,并使用刚才定义的方法来验证最后一条马尔科夫链起始状态的收获值: chains = [
[ "C1" , "C2" , "C3" , "Pass" , "Sleep" ] ,
[ "C1" , "FB" , "FB" , "C1" , "C2" , "Sleep" ] ,
[ "C1" , "C2" , "C3" , "Pub" , "C2" , "C3" , "Pass" , "Sleep" ] ,
[ "C1" , "FB" , "FB" , "C1" , "C2" , "C3" , "Pub" , "C1" , "FB" , \
"FB" , "FB" , "C1" , "C2" , "C3" , "Pub" , "C2" , "Sleep" ]
]
print ( compute_return( 0 , chains[ 3 ] , gamma= 0.5 ) )
接下来我们将使用矩阵运算直接求解状态的价值,编写一个计算状态价值的方法如下: def compute_value ( Pss, rewards, gamma = 0.05 ) :
'''
通过求解矩阵方程的形式直接计算状态的价值
:param Pss: 状态转移概率矩阵 shape(7,7)
:param rewards: 即时奖励 list
:param gamma: 折扣因子
:return: values 各状态的价值
'''
rewards = np. array( rewards) . reshape( ( - 1 , 1 ) )
values = np. dot( np. linalg. inv( np. eye( 7 , 7 ) - gamma * Pss) , rewards)
return values
values = compute_value( Pss, rewards, gamma= 0.99999 )
print ( values)
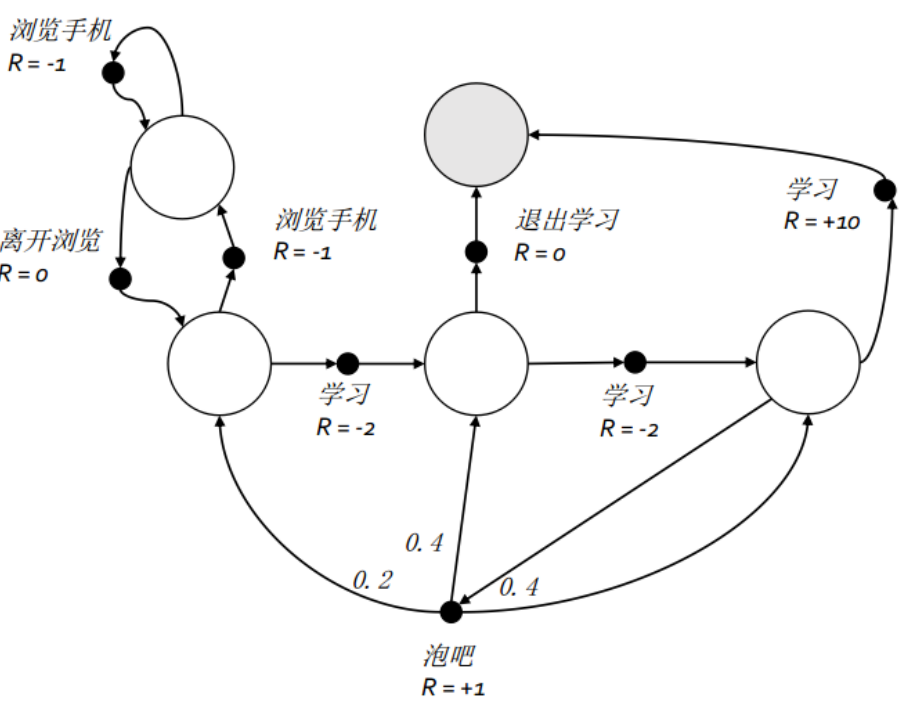
这部分将使用学生马尔科夫决策过程的例子中的数据,如下图所示,图中的状态数变成了5个,为了方便理解,我们把这五个状态分别命名为‘浏览手机中’,‘第一节课’,‘第二节课’,‘第三节课’,‘休息中’;行为总数也是 5 个,但具体到某一状态则只有 2 个可能的行为,这 5 个行为分别命名为:‘浏览手机’,‘学习’,‘离开浏览’,‘泡吧’,‘退出学习’。与马尔科夫奖励过程不同,马尔科夫决策过程的状转移概率与奖励函数均与行为相关。本例中多数状态下某行为将以 100% 的概率到达一个后续状态,但除外在状态‘第三节课中’选择‘泡吧’行为。在对该马尔科夫决策过程进行建模时,我们将使用字典这个数据结构来存放这些概率和奖励,数据。我们已经事先写好了一些工具方法来操作字典,包括根据状态和行为来生成一个字典的键、显示和读取相关字典内容等,读者可以在最后找到这些代码。我们要操作的字典除了记录了状态转移概率和奖励数据的两个字典外,还将设置一个记录状态价值的字典以及下文会提及的一个策略字典。具体如下:
from utils import str_key, display_dict
from utils import set_prob, set_reward, get_prob, get_reward
from utils import set_value, set_pi, get_value, get_pi
S = [ '浏览手机中' , '第一节课' , '第二节课' , '第三节课' , '休息中' ]
A = [ '浏览手机' , '学习' , '离开浏览' , '泡吧' , '退出学习' ]
R = { }
P = { }
gamma = 1.0
set_prob( P, S[ 0 ] , A[ 0 ] , S[ 0 ] )
set_prob( P, S[ 0 ] , A[ 2 ] , S[ 1 ] )
set_prob( P, S[ 1 ] , A[ 0 ] , S[ 0 ] )
set_prob( P, S[ 1 ] , A[ 1 ] , S[ 2 ] )
set_prob( P, S[ 2 ] , A[ 1 ] , S[ 3 ] )
set_prob( P, S[ 2 ] , A[ 4 ] , S[ 4 ] )
set_prob( P, S[ 3 ] , A[ 1 ] , S[ 4 ] )
set_prob( P, S[ 3 ] , A[ 3 ] , S[ 1 ] , p = 0.2 )
set_prob( P, S[ 3 ] , A[ 3 ] , S[ 2 ] , p = 0.4 )
set_prob( P, S[ 3 ] , A[ 3 ] , S[ 3 ] , p = 0.4 )
set_reward( R, S[ 0 ] , A[ 0 ] , - 1 )
set_reward( R, S[ 0 ] , A[ 2 ] , 0 )
set_reward( R, S[ 1 ] , A[ 0 ] , - 1 )
set_reward( R, S[ 1 ] , A[ 1 ] , - 2 )
set_reward( R, S[ 2 ] , A[ 1 ] , - 2 )
set_reward( R, S[ 2 ] , A[ 4 ] , 0 )
set_reward( R, S[ 3 ] , A[ 1 ] , 10 )
set_reward( R, S[ 3 ] , A[ 3 ] , 1 )
MDP = ( S, A, R, P, gamma)
至此,描述学生马尔科夫决策过程的模型就建立好了.当该MDP构建好之后,我们可以调用显示字典的方法来查看我们的设置是否正确: print ( "----状态转移概率字典(矩阵)信息:----" )
display_dict( P)
print ( "----奖励字典(函数)信息:----" )
display_dict( R)
一个MDP中状态的价值是基于某一策略的,要计算或验证该学生马尔科夫决策过程,我们需要先指定一个策略,这里考虑使用均一随机策略,也就是在某状态下所有可能的行为被选择的概率想等,对于每一个状态只有两种可能行为的该马尔科夫决策过程来说,每个可选行为的概率均为0.5.初始条件下所有状态的价值均设为0.与状态转移概率和奖励函数一样,策略与价值也各一个字典来维护.在编写代码时,我们使用Pi来代替
π
\pi
π
Pi = { }
set_pi( Pi, S[ 0 ] , A[ 0 ] , 0.5 )
set_pi( Pi, S[ 0 ] , A[ 2 ] , 0.5 )
set_pi( Pi, S[ 1 ] , A[ 0 ] , 0.5 )
set_pi( Pi, S[ 1 ] , A[ 1 ] , 0.5 )
set_pi( Pi, S[ 2 ] , A[ 1 ] , 0.5 )
set_pi( Pi, S[ 2 ] , A[ 4 ] , 0.5 )
set_pi( Pi, S[ 3 ] , A[ 1 ] , 0.5 )
set_pi( Pi, S[ 3 ] , A[ 3 ] , 0.5 )
print ( "----策略转移概率字典(矩阵)信息:----" )
display_dict( Pi)
print ( "----价值字典(函数)信息:----" )
V = { }
display_dict( V)
下面我们将编写代码计算在给定MDP和状态价值函数V的条件下如何计算某一状态
s
s
s
a
a
a
q
(
s
,
a
)
q(s,a)
q ( s , a ) def compute_q ( MDP, V, s, a) :
'''
根据给定的MDP,价值函数V,计算状态行为对s,a的价值q_sa
:param MDP: 马尔科夫决策函数
:param V: 价值函数V
:param s: 状态
:param a: 行为
:return: 在s状态下a行为的价值q_sa
'''
S, A, R, P, gamma = MDP
q_sa = 0
for s_prime in S:
q_sa += get_prob( P, s, a, s_prime) * get_value( V, s_prime)
q_sa = get_reward( R, s, a) + gamma * q_sa
return q_sa
依据下面这个公式,我们可以编写如下方法来计算给定策略Pi下如何计算某一状态的价值: def compute_v ( MDP, V, Pi, s) :
'''
给定MDP下依据某一策略Pi和当前状态价值函数V计算某状态s的价值
:param MDP: 马尔科夫决策过程
:param V: 状态价值函数V
:param Pi: 策略
:param s: 某状态s
:return: 某状态的价值v_s
'''
S, A, R, P, gamma = MDP
v_s = 0
for a in A:
v_s += get_pi( Pi, s, a) * compute_q( MDP, V, s, a)
return v_s
至此,我们就可以验证学生马尔科夫决策过程中基于某一策略下各状态以及各状态行为的价值了.不过在验证之前,我们先给出在均一随机策略下该学生马尔科夫决策过程的最终状态函数.下面两个方法将完成这个功能.在本章对下面代码不作要求,读者可以在学习第三章内容后再来理解这段代码:
def update_V ( MDP, V, Pi) :
'''
给定一个MDP和一个策略,更新该策略下的价值函数
'''
S, _, _, _, _ = MDP
V_prime = V. copy( )
for s in S:
V_prime[ str_key( s) ] = compute_v( MDP, V_prime, Pi, s)
return V_prime
def policy_evaluate ( MDP, V, Pi, n) :
'''
使用n次迭代计算来评估一个MDP在给定策略Pi下的状态价值,初始时为V
'''
for i in range ( n) :
V = update_V( MDP, V, Pi)
return V
V = policy_evaluate( MDP, V, Pi, 100 )
display_dict( V)
我们来计算一下在均一随机策略下,状态"第三节课"的最终价值,写入下面两行代码: v = compute_v( MDP, V, Pi, "第三节课" )
print ( "第三节课在当前策略下的最终价值为{:.2f}" . format ( v) )
可以看出结果与下图吻合. 不同策略下得到各个状态的最终价值并不一样,特别地,在最优策略下最优状态价值的计算将遵循下面这个公式,此时一个状态的价值是该状态下所有行为价值中的最大值.我们编写如下方法来实现计算最优策略下最优状态价值的功能: def compute_v_from_max_q ( MDP, V, s) :
'''
根据一个状态下的所有可能的行为价值中最大一个来确定当前状态价值
'''
S, A, R, P, gamma = MDP
v_s = - float ( 'inf' )
for a in A:
qsa = compute_q( MDP, V, s, a)
if qsa >= v_s:
v_s = qsa
return v_s
下面这段代码实现了在给定MDP下得到最优策略以及对应的最优状态价值的一种办法,同样这段代码可以在学习了第三章内容后再来理解: def update_V_without_pi ( MDP, V) :
'''
在不以来策略的情况下直接通过后续状态的价值来更新状态价值
'''
S, _, _, _, _ = MDP
V_prime = V. copy( )
for s in S:
V_prime[ str_key( s) ] = compute_v_from_max_q( MDP, V_prime, s)
return V_prime
def value_iterate ( MDP, V, n) :
'''
价值迭代
'''
for i in range ( n) :
V = update_V_without_pi( MDP, V)
return V
V = { }
print ( "----最优状态价值信息----" )
V_star = value_iterate( MDP, V, 4 )
display_dict( V_star)
这段代码输出的各个状态的最终价值与下图相同. 有了最优状态价值,我们可以依据公式计算最优行为价值,我们将不必再为此编写一个方法,之前的方法compute_q就可以完成这个功能.使用下面的代码来验证状态’第三节课’时选择’泡吧’行为的最优价值:
s, a = "第三节课" , "泡吧"
q = compute_q( MDP, V_star, s, a)
print ( "在状态{}选择行为{}的最优价值为:{:.2f}" . format ( s, a, q) )
本次的编程实践就到此结束,下面的代码是马尔科夫决策过程中一开始导入的那些方法,这些方法保存在与之前代码同一文件夹下,文件名为’utils.py’ def str_key ( * args) :
'''
将参数用"_"连接起来作为字典的键,需注意参数本身可能会是tuple或者list型,
比如类似((a,b,c),d)的形式
'''
new_arg = [ ]
for arg in args:
if type ( arg) in [ tuple , list ] :
new_arg += [ str ( i) for i in arg]
else :
new_arg. append( str ( arg) )
return "_" . join( new_arg)
def set_dict ( target_dict, value, * args) :
target_dict[ str_key( * args) ] = value
def set_prob ( P, s, a, s1, p= 1.0 ) :
set_dict( P, p, s, a, s1)
def get_prob ( P, s, a, s1) :
return P. get( str_key( s, a, s1) , 0 )
def set_reward ( R, s, a, r) :
set_dict( R, r, s, a)
def get_reward ( R, s, a) :
return R. get( str_key( s, a) , 0 )
def display_dict ( target_dict) :
for key in target_dict. keys( ) :
print ( "{}: {:.2f}" . format ( key, target_dict[ key] ) )
print ( "" )
def set_value ( V, s, v) :
set_dict( V, v, s)
def get_value ( V, s) :
return V. get( str_key( s) , 0 )
def set_pi ( Pi, s, a, p = 0.5 ) :
set_dict( Pi, p, s, a)
def get_pi ( Pi, s, a) :
return Pi. get( str_key( s, a) , 0 )








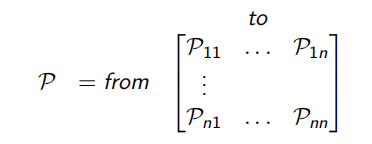


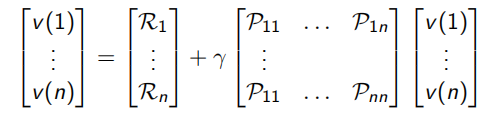
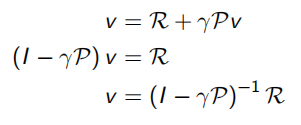
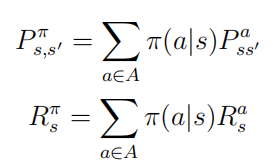
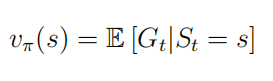
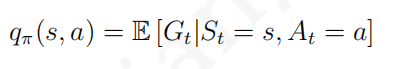
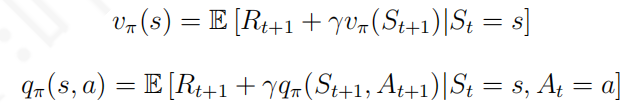

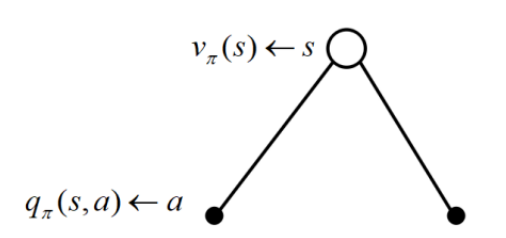
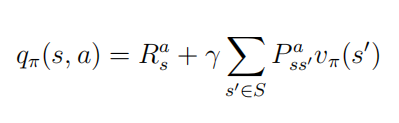
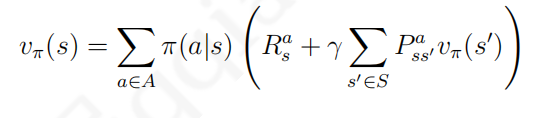
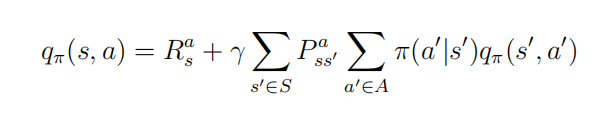
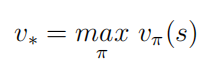
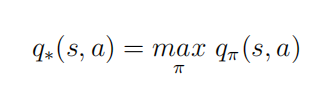

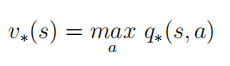

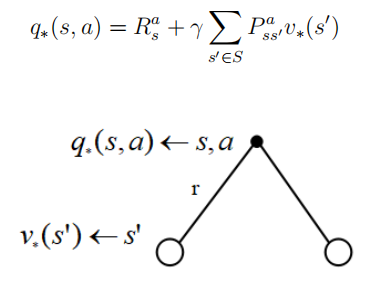
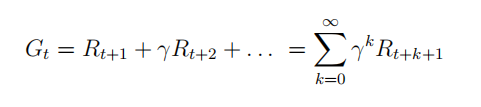
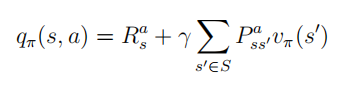
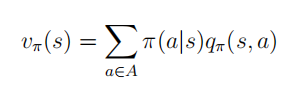
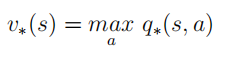















 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









