









探索和利用
3要素:action reward state
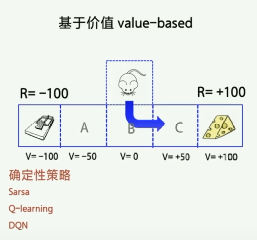
value base:
基于价值来优化。
为每一个转台赋予一个价值的概念,V;
某个状态的价值越大代表这个价值越接近目标;或,代表状态的好坏。
训练目标:价值函数最优为止。
价值函数最优后,agent在某状态下输出唯一的动作值,即确定性策略。
最优策略:在某状态下只往价值最高的状态走。
policy based:
基于策略来优化。

分类:

实现库:

最快的学习方法:看代码。
PARL

仿真环境库:




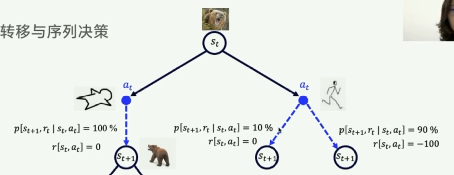
强化学习4元组:

MDP、RL:时间序列决策的过程。
![]()

状态转移概率:
![]() :在st状态下执行
:在st状态下执行,下一状态变为
而且拿到奖励rt,这件事情发生的概率,用p函数表示。


强化:怎么去更新Q表格。
时序差分、TD、下一步的Q价值来更新这一步的价值、单步更新。

未来收益总和:Reward
单步收益:
期望收益、理想收益值(训练完成后、直到Q表不再发生变化):
时序差分的方法来更新:

Q(st,at):理解为,在st执行at的未来总收益之和。
只需要st at rt st+1 at+1 就能对当前Q(st,at)进行更新。
Sarsa命名由来

强化的过程、学习的过程中:知道Q表的更新规则后还不够,还需要知道如何选择action,仅探索、仅利用、探索与利用。怎样选择action才能让Q表收敛最快?E贪心算法??等等。。。


Sarsa算法:在第k+1步更新第k步的Q(sk,ak)值。
过程:
在第k步,观察到sk,通过贪心算法选择动作ak,
在第k+1步,观测到sk+1,Rk+1,通过贪心算法选择动作ak+1,根据时序差分公式更新Q(sk,ak)的值。
在第k+2步......
Qlearning算法:更加大胆,更新Q(sk,ak)时,不需要用贪心算法选择ak+1取执行,而是选择max Q(sk+1,*),即最大的Q(sk+1,*)。



Qlearning 是off policy ,Sarsa是on policy。


状态量、动作量都是可数的,并且少量的:可用Q表格来实现强化学习;
当状态量不可数,或很庞大时,用Q表格不再现实。
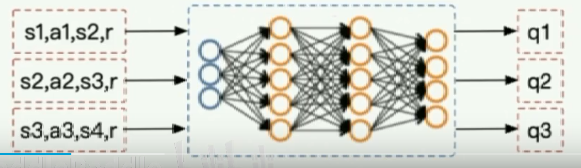
DQN:
本质:Qlearning
用神经网络逼近Q表格。Q表格,输入s、a输出一个累积奖赏值。
那么问题来了,Qlearning 和Sarsa的目标是更新Q表格直到收敛,那么用神经网络代替(逼近)Q表格后,强化学习的目标变成,更新神经网络以逼近Target Q table。
那么问题又来了:如何更新神经网络呢????




batch:小批量随机梯度下降

在更新网络时需要用到target Q: ![]()
然而targetQ也是受网络的影响,所以需要在一小时间端内固定用于计算targetQ的网络的w参数,其实创建了两个Q网络,一个用于计算targetQ,一个用于逼近target Q。


分解成3个部分,分别为:


DQN代码分析:
1.建立能逼近Q表格的神经网络:

2.网络的更新方法:

经验回放:小批量随机梯度下降(要先学习什么是批量梯度下降、什么是随机梯度下降,再学习小批量随机梯度下降)
predict函数:即计算Q网络的输出值,输入为s,输出为Q(s,a1),Q(s,a2),... ,Q(s,an)。
policy based
在value based 中,利用函数取你和Q function 然后根据Q function来选取最优动作,这些最优动作序列即最优策略。
而在policy based中,用函数取你和策略,用到策略梯度。
policy based 中,对于动作的选取不再根据动作价值函数,而是在某个概率下降一条策略走到底,然后再评估该策略的最后总收益来决定。
策略梯度算法。



Q网络、Policy网络



时序差分、蒙特卡洛

策略函数:

一个episode的轨迹:

策略梯度:




policy 梯度:在跑episode的时候网络不变,即不更新,跑完一个episode后再根据该episode策略轨迹,针对每一个action,一步一步更新网络的参数


运行episode的时候,如何选择并执行action:
根据网络的输出的概率进行选择,例如,当前状态为s1,经过策略网络后输出为:π(s1,a1)=0.2,π(s1,a2)=0.3,π(s1,a3)=0.5,则以0.2 0.3 0.5 的概率选中a1 a2 a3 并执行。代码实现在agent的sample函数中。
 DDPG:
DDPG:








DDPG控制四旋翼悬停:
经典学习资料:


致谢老师,么么哒!
















 219
219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









