







02分布式
体系结构模型的种类
核心系统架构
- Client-Server 客户服务器模型
- peer to peer 点对点模型
更多的架构
设计分布式架构的需求
性能问题
- Responsiveness 响应性
- throughput 吞吐量
- balancing computational loads 平衡计算负载
服务质量 Quality of Service QoS
Caching和Replication的使用
Distributed Concurrency 分布式并发
导引
Physical clocks 物理时钟
- Real-Time Clock RTC
用于底层的模型
- Cristian's Algorithm(克里斯蒂安算法)
- The Berkeley Algorithm
- Averaging Algorithms 比如NTP
- 逻辑时钟
体系结构模型的种类
核心系统架构

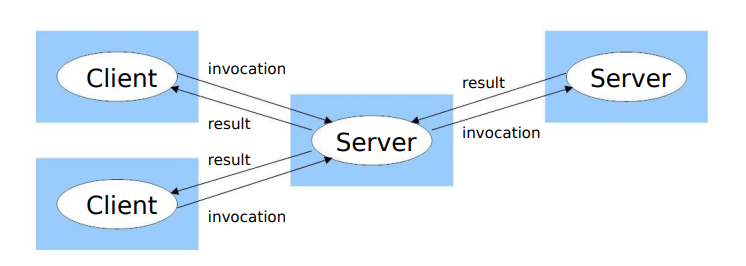
Client-Server 客户服务器模型
- 客户端上的进程与各服务器进程交互,以访问共享资源
- 服务器本身也可能是其他服务器的客户端
- 比如万维网
- 通常使用标准化的通信协议,例如HTTP(用于Web应用程序)、TCP/IP(用于通用网络通信)。定义了客户端和服务器之间的消息格式和通信规则
-
peer to peer 点对点模型
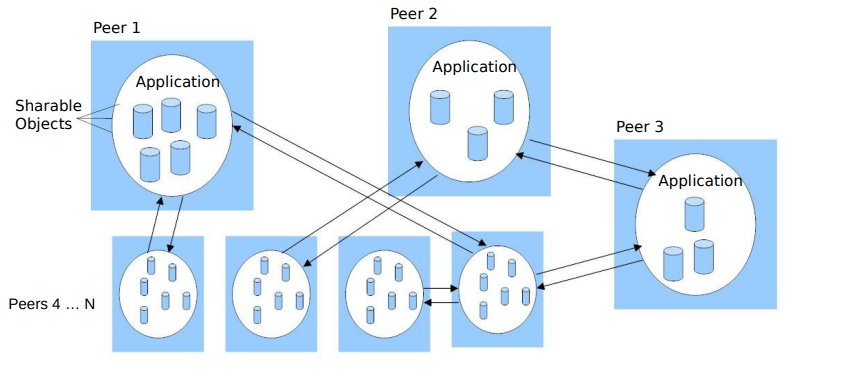
- 相关的进程扮演类似的角色,作为对等体进行写作,不区分客户服务器的进程,不区分执行的计算机
- 既能请求资源和服务,也能提供资源和服务。
- 点对点网络通常是分散的,没有中央服务器或集中式控制。节点之间直接通信,而不需要通过中间服务器
- 比如区块链(blockchain),skype
- 如安全性和管理问题,因为缺乏集中式控制和监管。不同的点对点应用程序可能采用不同的架构和协议来满足其特定需求
-
更多的架构
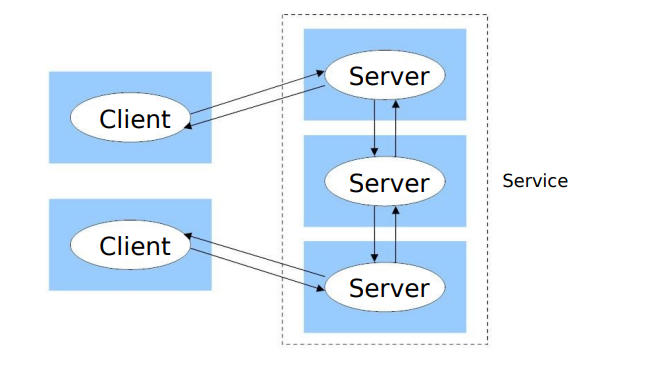
- 通过multiple servers提供服务
- 一个特定的服务不仅可以由单个服务器提供,而且可以由多个服务器一起提供。这种方法可以提高服务的可用性和性能。
- 这些服务器进程可以根据需要相互交互,以提供完整的服务。这意味着它们可以协作工作,共同完成客户端的请求。
- 有时,服务器可以将服务所基于的对象分成多个部分,然后将这些部分分配给不同的服务器来处理。这被称为对象分区。这有助于提高并行性和性能。
- 另一种方法是将数据复制到多个服务器上,每个服务器都维护一份数据的副本。这可以提高数据的可用性和冗余性,以防止单点故障。
-
-

-

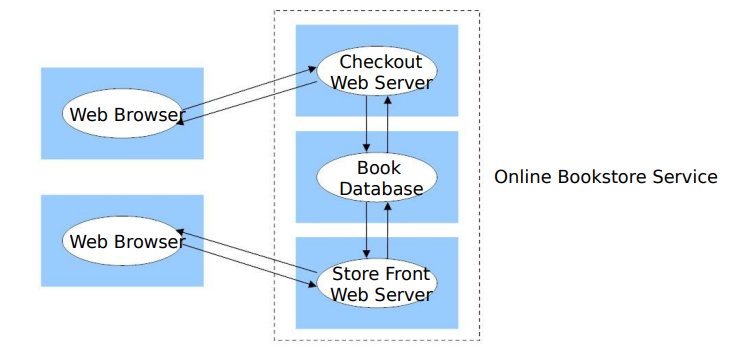
- 比如这个例子,用户在网上书城买书,需要在前端界面查看书籍信息,这个交给一个服务器,然后这个服务器需要向数据库寻求服务,接着选定之后回到达结账服务器结账
-
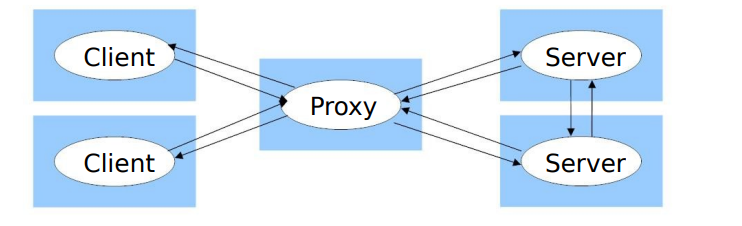
- proxy servers and Caches 代理服务和缓存
- 缓存是对最近使用的数据对象的存储,临时存储区域。缓存用于提高数据访问的速度和效率,因为它可以存储那些频繁使用的数据,使它们更容易和更快地被访问。访问缓存优先于直接访问对象
- 缓存更新:当计算机接收到新的数据对象时,它将该对象添加到缓存中,如果需要的话,可能会替换缓存中的一些现有对象。这有助于确保缓存中的数据保持最新和相关。
- 缓存查询:如果进程需要一个对象,首先检查缓存
- 如果有缓存就直接用;如果没有就找那个对象,然后存到缓存里,然后再给进程使用
- 缓存可以存在客户端本地,也可以存在共享代理服务器
- 本地的一般是频繁使用的,代理的是为更多客户端提供服务,存储使用次数较多但也不那么多的,毕竟刚需存在本地即可
- 代理服务器是位于网络中的一台服务器,它充当客户端和其他服务器之间的中介intermediary
- 代理服务器可以缓存经常访问的网页或内容,以减轻原始服务器的负载,并提高客户端访问速度。
- 代理服务器可以用于防火墙、内容过滤和安全性检查,以确保安全地访问互联网资源。
- 代理服务器可以限制客户端对特定资源的访问,实施访问策略和过滤规则。
- 简而言之就是代理服务器先得到客户端请求然后发给真正服务器,此时自己有缓存就直接给客户端了;然后服务器回应的信息先给代理缓存,然后代理再给客户端
-
- Mobile Code 移动代码
- 是指可以从一台计算机发送到另一台计算机并在目标计算机上运行的代码
- 可以在本地执行,因此具有良好的交互响应时间。这在需要增强客户端基本功能的情况下非常有用
- 主要挑战之一是安全性。因为移动代码在本地执行,存在潜在的风险,可能会导致恶意活动
- 还有平台兼容性这个缺点,其他平台不一定能直接使用传过来的代码
- Java是特例,Java有自己的虚拟机
-

- Network computers NC 网络计算机
- 操作系统和应用程序远程下载: 网络计算机通常不像传统桌面计算机那样在本地安装操作系统和大多数应用程序。相反,它们通常只包含最小的永久数据存储(通常只有处理器和内存),并从远程服务器下载操作系统和所需的应用程序。
- 本地应用程序运行: 尽管操作系统和应用程序是从远程服务器下载的,但应用程序通常是在本地计算机上运行的。这意味着用户可以像使用传统桌面计算机一样运行应用程序。
- 用户文件管理: 网络计算机通常将用户文件存储在远程文件服务器上,而不是在本地计算机上。这意味着用户的数据文件可以在多台网络计算机之间共享,并且可以更轻松地备份和管理。
- Where permanent data storage is provided, only a minimal amount of software is maintained, with most of the space used as a cache to improve download speeds.
- 目标:to reduce the cost of a computer, to mini mise the technical knowledge required to maintain it, and to support migratory user
- 现在已经不常见了 用不上 现在都只利用了这个概念
- 虚拟桌面基础设施(VDI): VDI 技术允许将虚拟桌面部署到远程服务器上,然后通过网络连接到客户端设备上。这种方法与NC的理念相符,因为用户访问的是虚拟化的桌面环境,而不是本地计算机。就是远程桌面。类似QQ
- 移动设备和移动应用程序: 移动设备如智能手机和平板电脑通常依赖于云服务和远程服务器来运行应用程序和存储数据。这种分散计算和存储的方式与NC的理念有相似之处。
- 云计算: 云计算提供了类似于NC的虚拟化和远程资源管理的概念,但规模更大、更灵活。用户可以通过互联网连接到云服务提供商的远程服务器来获取计算资源和应用程序,而不必关心本地硬件或软件的维护和升级。
- thin clients 瘦客户端
- 主要特点是在本地用户计算机上支持窗口化用户界面,但执行应用程序在远程计算机上
- 就是远程控制。类似vsCode控制
- 窗口化用户界面: 瘦客户端提供了窗口化的用户界面,使用户可以在本地计算机上操作和查看应用程序的图形界面,就像使用传统桌面计算机一样。
- 远程执行应用程序: 瘦客户端不在本地计算机上运行应用程序,而是将应用程序在远程计算服务器上执行。通常,这些远程服务器是多处理器机器或集群,可以提供计算和存储资源。
- 低管理和硬件成本: 类似于网络计算机(NC)的理念,瘦客户端通常具有较低的管理和硬件成本。因为应用程序在远程服务器上运行,所以用户计算机通常不需要高性能的硬件或大量的本地存储。
- 对网络的依赖性: 瘦客户端的一个主要缺点是它完全依赖于网络连接。如果网络发生故障,正在执行的程序可能会丢失数据,用户界面的更新可能会受到网络延迟的影响,性能在图形使用增加时可能会迅速下降。
- 图形性能限制: 由于图形数据需要通过网络传输,所以瘦客户端的图形性能可能受到限制,尤其是对于需要大量图形处理的应用程序。
设计分布式架构的需求
性能问题
Responsiveness 响应性
- 交互式应用需要fast and consistent的响应
- 响应性的关键因素是响应时间,即用户发起交互请求后,系统需要多快时间来产生相应的反馈。短响应时间通常被认为是良好用户体验的关键。
- 因为客户端有时候需要访问共享资源,所以远程服务器的load和性能、网络的延迟和性能、中间件的时间花费、操作系统通信服务的时间花费、具体实现服务所需的处理时间都会影响
- 如何实现最大响应能力
- 最小化程度程序使用的软件层数,减少不必要的中间层和步骤
- 减少传输的数据量
- 比如web浏览器。本地缓存网页和图片更快,以为不是远程下载的。文本响应比视频图片快,因为传输的数据量少
throughput 吞吐量
- 是计算工作完成的速率。主要关注任务完成时间而不是接口更新时间
- 受客户机服务器对于数据处理速度的影响
- 需要考虑体系结构中每个软件层的吞吐量。这包括客户端、服务器以及可能的中间层
balancing computational loads 平衡计算负载
- DS目标在于使任务并发执行,不让大量任务竞争相同的资源,而是同时利用所有可用的资源:处理器,内存,网络容量
- 为了提高吞吐量,可以将网站复制到多个Web服务器上,并使用负载均衡技术来分散负载。这可以通过使用单一域名的多个地址来实现。
- JS可以由浏览器本身运行,而不靠web服务器的资源
- 目的为了增加吞吐量
服务质量 Quality of Service QoS
- reliability,security,performance衡量的
- 更多的,adaptability也被考虑到。系统需要满足不断变化的系统配置和资源可用性的能力
- 有时时间关键性(time-critically)也影响性能,必须以固定的速率处理某些数据
Caching和Replication的使用
-
是克服性能和QoS的关键技术
-
缓存可显著减少Client的响应时间。本地资源减少了访问远程服务器的需要
-
复制可以降低网络成本,平衡计算负载
- 复制是将资源的多个副本分布式存储在不同的位置或计算机上。
- 降低网络成本,因为客户端可以访问距离最近的资源副本,从而减少了数据在网络上的传输。
- 平衡计算负载。例如,在多台服务器上复制网站内容,然后使用负载均衡技术,可以将客户请求分散到不同的副本服务器上,以提高性能和可用性。
- 减少对资源的竞争,因为多个副本意味着多个客户可以同时访问资源的不同副本,而不会互相干扰。
-
缓存(Caching) 更多地用于本地客户端或中间层,其目的是减少对远程服务器的访问,提高响应时间和减轻网络负担。例如,Web浏览器可以在本地缓存Web页面和图像,以减少再次下载相同内容的需要。应用程序也可以使用缓存来存储临时数据,以避免重复计算或网络请求。
-
复制(Replication) 更多地用于远程服务器,特别是在分布式系统中,以提高可用性、可伸缩性和负载均衡。通过在不同的服务器上复制资源,可以使客户端能够访问最接近它们的资源副本,从而减少网络延迟和降低网络负担。复制还可以用于确保系统的高可用性,因为即使一个服务器失败,其他副本仍然可用。
-
需要注意的是,这只是一般情况,具体应用取决于系统的设计和要求。有时也可能在本地客户端或中间层中使用复制,以提高可用性和性能。在设计分布式系统时,需要根据具体的用例和目标来决定何时使用缓存和复制,以最好地满足需求。
Distributed Concurrency 分布式并发
并发(Concurrency)是计算机科学和软件工程领域的重要概念,指的是在同一时间段内处理多个任务或操作的能力。具体来说,它涉及到多个任务在同一时间段内开始、执行和完成的情况。
以下是关于并发的一些关键概念:
- 并发任务(Concurrent Tasks): 并发涉及到多个任务、进程或线程同时运行。这些任务可以在相同的计算机系统上运行,也可以在不同的计算机系统上运行。
- 并行性 (parallel)vs. 并发性: 虽然"并行性"和"并发性"这两个术语经常被混用,但它们有细微的区别。并行性指的是同时执行多个任务,通常需要多个处理单元(例如,多核处理器)来实现。而并发性是指任务在同一时间段内启动和执行,但不一定是同时执行。在单核处理器上,任务可以通过快速切换来实现并发性,每个任务都有机会执行。
- 资源竞争(Resource Concurrency): 当多个任务尝试访问相同的共享资源时,可能会导致资源竞争。这种竞争可能导致数据不一致或不稳定的结果,因此需要使用同步机制来管理资源的访问。
- 并发控制(Concurrency Control): 并发控制是一种管理并发访问共享资源的技术。它包括锁定、信号量、事务处理等方法,以确保多个任务之间的协同和数据的一致性。
- 并发性的优点: 并发性可以提高系统的性能和响应能力。通过同时处理多个任务,系统可以更有效地利用计算资源,并在多核处理器上实现更好的性能。
- 并发性的挑战: 管理并发性是有挑战的,因为需要处理任务之间的竞争条件、死锁、资源管理等问题。不正确的并发管理可能导致程序中的难以调试的错误。
总之,并发是现代计算系统中的重要概念,用于提高性能、可伸缩性和响应能力。然而,管理并发性需要小心谨慎,以确保多个任务能够安全地共享资源并产生正确的结果
- 环境和范围:
- 并发是指在单个计算机或处理器上处理多个任务或操作的能力。这些任务可以交替执行,共享计算机的资源(例如,CPU、内存),并且它们之间可能需要同步和通信。
- 分布式并发是指在分布式系统中处理多个任务或操作的能力,这些任务可以分布在不同的计算节点或服务器上。这涉及到跨网络的通信和协同工作,以实现分布式系统的目标。
- 通信和同步:
- 在并发中,通信和同步通常是在单一计算机内进行的,使用多线程或多进程来协调任务的执行。
- 在分布式并发中,通信和同步涉及跨越网络的多个计算节点之间的操作。这需要考虑网络延迟、故障处理和分布式锁管理等问题。
- 数据一致性:
- 并发通常更容易管理数据一致性,因为任务在同一个计算机内共享相同的内存空间,可以使用共享内存或线程安全的数据结构来处理。
- 分布式并发需要更多的关注数据一致性问题,因为数据可能分布在不同的节点上,需要采用分布式事务、一致性协议等技术来确保数据的一致性。
- 性能和可伸缩性:
- 并发通常用于提高单个计算机或处理器上的性能,例如,多线程编程可以充分利用多核处理器的性能。
- 分布式并发用于实现系统的可伸缩性,允许多个计算节点并行处理任务,以处理大规模的工作负载。
并发更关注单个计算机内的多任务处理,而分布式并发更关注多个计算节点之间的任务处理,通常涉及跨网络的通信和数据一致性问题
导引
- centralized system 集中式系统有单一的公共存储器和时钟,可以确定事件发生的时间。这使得事件的时间戳(timestamp)和顺序非常明确。
- 分布式没有,所以不好确定事件发生时间
- 但分布式需要时间,来确定系统组件component发生时间的全局顺序和同步组件的活动
- 分布式系统通常使用各种时钟同步协议和分布式算法来确保事件的有序发生和组件之间的协同工作。
- 我们能否设置所有时钟为同一时间?
- 不大现实。因为分布式系统的计算节点可以分布在不同的地理位置,它们受到网络延迟和不同的硬件时钟精度等因素的影响。但是,可以采取一些措施来尽量使分布式系统的时钟保持同步
- 时钟同步协议(Clock Synchronization Protocols): 使用时钟同步协议可以让分布式系统中的时钟保持一定程度的同步。常见的时钟同步协议包括NTP(Network Time Protocol)和PTP(Precision Time Protocol)。这些协议可以帮助不同计算节点的时钟调整到接近一致的时间。
- 逻辑时钟(Logical Clocks): 在分布式系统中,有时候更关注事件的相对顺序而不是绝对时间。逻辑时钟,如Lamport时钟和Vector时钟,可以用于记录事件之间的因果关系和相对顺序,而不需要完全同步的物理时钟。
- 时钟校准(Clock Calibration): 定期校准计算节点上的时钟可以减少时钟漂移,以确保它们保持在一定的同步范围内。
- 通常更重要的是关注事件的相对顺序和因果关系,而不是绝对的全局时间。
Physical clocks 物理时钟
略,介绍物理知识
International Atomic Time (TAI): mean of the reported clock ticks from these 50 cesium 133 clocks.
TAI is mean number of ticks of cesium 133 clocks since midnight on January 1, 1958 divided by 9,192,631,770 . Universal Coordinated Time (UTC): It is based on International Atomic Time (TAI) with leap seconds added at irregular intervals to compensate for the slowing of the Earth's rotation
Real-Time Clock RTC
- 计算机内部的时钟。由电池独立供电进行时间流逝。操作系统会从RTC读取时间初始化所有进程使用的虚拟时钟
- 时间值的差异叫clock skew,是不同计算机RTC产生的差异
- 所以需要一定的协议和措施保证时间戳的顺利
用于底层的模型
- 时钟中断和计时器: 不同计算机上的时钟通常由硬件计时器产生中断来维护。这些中断以固定的频率(例如每秒H次)触发,中断处理程序会在中断发生时记录已经过去的时间(即ticks数)。
- 时钟值和UTC时间: 每台计算机上的时钟值(Cp(t))表示了自某个过去的时间点开始经过的时间。而世界协调时间(UTC)是一种全球标准时间,用于表示全球统一的时间。
- UTC代表正确的t,每个机器p的时间是Cp(t)
- 理想时刻是这俩相等
- 时钟同步问题: 在分布式系统中,时钟值(Cp(t))不一定等于UTC时间(t)。因为不同计算机上的时钟可能存在时钟漂移或中断频率不同,导致它们的时钟值不同步。
- 时钟同步协议: 为了解决时钟同步问题,分布式系统通常使用时钟同步协议,例如NTP(Network Time Protocol)或PTP(Precision Time Protocol)。这些协议允许计算机之间定期进行时间同步,以减小时钟偏移并保持一致性。
-

- 时钟漂移(Clock Drift): 时钟漂移指的是计算机时钟的不精确性或不准确性,导致时钟的速度略有偏移。这是因为计算机内部时钟的精确度是有限的,因此随着时间的推移,它们可能会与真实时间存在微小的差距。
- 漂移范围和最大漂移率(Maximum Drift Rate): 漂移范围指的是时钟可能偏离真实时间的最大范围。最大漂移率(ρ)是制造商规定的时钟漂移的最大速率。在您的描述中,漂移范围在215,998到216,002个“tick”之间变化。
- 时钟同步算法(Clock Synchronization Algorithms): 为了保持分布式系统中的时钟同步,可以使用时钟同步算法。这些算法会定期对不同计算机上的时钟进行校准,以确保它们保持一致。
- 时钟重同步(Clock Resynchronization): 为了确保两个时钟永远不会相差超过某个特定值(例如,δ),时钟需要定期进行重同步。根据您的描述,时钟应该每δ/(2ρ)秒进行一次重同步,以保持在可接受的范围内。
- 集中式算法是系统的单个组件负责通用的全局系统时间;分布式算法是多个组件负责通用的全局系统时间
Cristian's Algorithm(克里斯蒂安算法)
- 用于分布式系统中,其中一个机器充当时间服务器,而其他机器需要与时间服务器保持同步
- 时间服务器: 一个机器被选为时间服务器,它拥有一个精确的时钟,通常通过WWV(无线电时间信号)或GOES(地球观测卫星)接收器来获取准确的时间信息。
- 时钟同步请求: 每台需要同步的机器定期(每δ/(2ρ)秒)向时间服务器发送时钟同步请求。这些请求包含了机器当前的本地时间。
- 时间服务器响应: 时间服务器接收到请求后,会回复带有当前时间的消息,称为CUTC(Current UTC Time)消息。
- 本地时间校准: 接收到时间服务器的响应后,每台机器可以使用CUTC消息来校准自己的本地时钟,以便使本地时钟尽量与全球协调世界时(UTC)保持一致。
- 但也会受网络延迟的影响
-
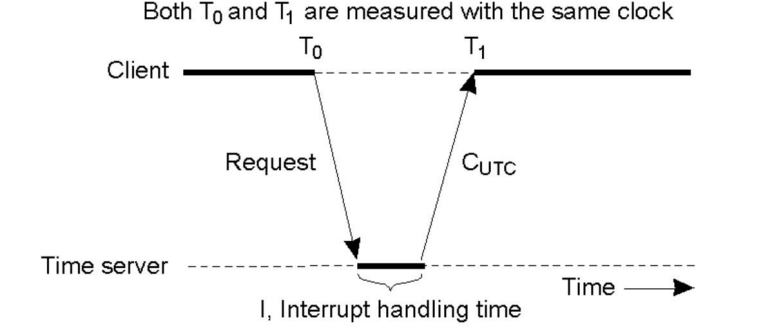
- 对于克里斯蒂安算法中可能存在的问题,即从服务器到客户端的单程延迟可能显著且变化较大,可以采取以下措施来解决:
- 测量延迟并添加到CUTC: 在时间服务器回复时,客户端可以测量从服务器到客户端的单程延迟,并将其添加到CUTC值中。这可以更准确地估计时间。
- 延迟阈值处理: 如果测得的延迟(T1 - T0)超过某个阈值,可以选择忽略该测量值,因为它可能不准确或不可靠。
- 减去服务器中断处理时间: 如果服务器的中断处理时间(I)是已知的,可以将其从延迟测量中减去,以更精确地估计单程延迟。
- 使用平均延迟测量或相对延迟: 客户端可以根据多次测量的平均延迟来估计单程延迟,或者可以使用已记录的最短延迟作为相对延迟。
- 需要注意的是,客户端使用自己的时钟来估计来回时延(Round Trip Time,RTT),因此受到客户端时钟漂移的影响。但是,如果客户端时钟漂移相对于实际RTT值很小,那么这种影响通常是可以忽略的。
- 另一个比较大的问题是客户端时钟较快,因此到达的CUTC值会小于客户端当前时间C。这可能导致时间向后流逝,这是不可接受的
- 逐渐减小客户端时钟速度: 为了避免时间向后流逝,可以逐渐减小客户端时钟的速度,即每个时钟滴答(tick)增加的时间要更少。这可以通过逐渐增加时钟滴答之间的时间间隔来实现,从而使客户端时钟的速度逐渐减慢。
- 可以通过时钟调整算法来实现,其中客户端根据CUTC值和本地时钟的差异来动态调整自己的时钟速度
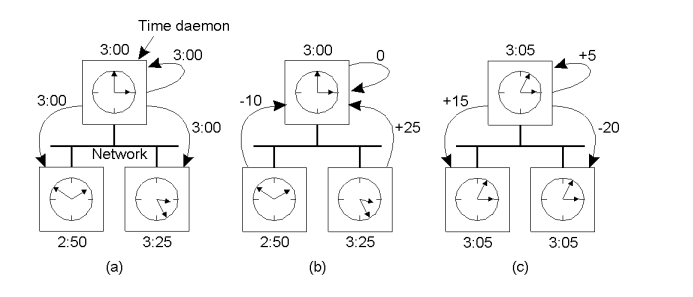
The Berkeley Algorithm
- 这是用于内部时钟同步的方法,通常用于局域网LAN中
- 主从结构: 在这种方法中,有一个计算机被选为主机(master),其他计算机被视为从机(slaves)。主机负责协调时钟同步操作。
- 主机轮询从机: 主机定期轮询所有从机,使用类似于克里斯蒂安算法的方式,向从机请求其时间值。每个从机回复主机的请求,提供其本地时间。
- 主机计算平均时间: 主机收集从机的时间值后,计算这些时间值的平均值,得出一个估计的全局时间。
- 调整从机时钟: 主机将计算得出的平均时间与每个从机的本地时钟进行比较,然后告诉每个从机如何调整自己的时钟,以便与平均时间保持一致。这样可以实现各个从机之间的时钟同步。
- 主机故障处理: 如果主机发生故障或不可用,需要选择一个新的主机。这通常涉及到从机之间的选举过程,以确定哪台从机将成为新的主机。
- 通过使用多个从机的时间值来计算平均时间,可以获得更准确的时间估计,相对于仅使用单个客户端的时间值。
-

-
Averaging Algorithms 比如NTP
- 广播时间同步: 在这种算法中,每台计算机每隔R秒广播其当前时间。其他计算机接收并记录这些广播的时间样本。
- 简单平均算法: 在一定的时间间隔S内,本地计算机收集所有其他计算机广播的时间样本,并将其值的平均值设置为新的本地时间。这种算法的一个问题是,它对于存在故障时钟的情况可能不够鲁棒。
- 优化平均算法: 更复杂的算法可以排除一些异常值,例如排除最高m个值和最低m个值,以减小故障时钟的影响。这可以提高时钟同步的准确性。
- 网络时间协议(NTP): NTP是一种广泛用于互联网的时钟同步协议。它使用分层的、分布式的体系结构,通过与可信任的时间服务器通信,实现全球范围内的时间同步。NTP可以实现毫秒级的准确性。
- 时间服务器网络: 这种方法使用一组时间服务器,这些服务器通过一个同步子网树(synchronization subnet tree)相互连接。时间服务器是分布式系统中的关键节点,用于提供准确的时间信息。
- 同步子网树: 同步子网树是一种层次结构,其中根节点是网络中的一个时间服务器。每个节点可以连接到一组子节点,从而形成了一个分层的结构。
- 根节点直接调整: 根节点(通常是顶层时间服务器)直接调整自己的时钟以保持准确的时间。这个根节点可能连接到外部可信的时间源,如GPS卫星或原子钟,以获得高精度的时间。
- 节点之间同步: 子节点会与其父节点同步,以便将时间信息传播到整个同步子网树中的所有节点。这种层次结构允许时间同步从根节点向下传播,确保所有处理器的时钟保持同步。
- 构建了一个分层的、分布式的同步结构,以确保所有处理器的时钟保持准确。
- 从上往下依次会获得正确的时间,这个是树状图,一个节点会只受一个父节点的影响,大大降低故障率
逻辑时钟
-
这个是重点在于事情的发生顺序的,如果a先于b发生,那么a的信号到达b之后,b的时间应该晚于a,b回发信号给a,那么到达a的时刻也应该晚于b发送的时刻,如果a的那个时刻比b早,a需要调整时间
-
实现Lamport逻辑时钟,每个时钟进程Pi维护一个局部计数器Ci,计数器按照如下步骤进行更新:
- 执行一个事件之前,P执行Ci=Ci+1;
- 当进程Pi发送一个消息m给Pj,在执行1的步骤后,把m的时间戳ts(m)设置为Ci;
- 在接收到消息m时,进程Pj调整自己的局部计数器为Cj=max(Cj, ts(m)),然后执行第一步,并把消息传送给应用程序。
- Lamport逻辑时钟有一个重要前提是:两个事件不会完全同时发生。















 2008
2008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









