






目录
目录前言机器翻译的基本概念Transformer架构的核心思想机器翻译模型的构建代码示例应用场景注意事项架构图与流程图总结参考文献作者简介
(二)多头注意力机制(Multi-Head Attention)
前言
机器翻译(Machine Translation, MT)是自然语言处理(NLP)领域的重要应用之一,其目标是将一种语言的文本自动翻译成另一种语言。随着深度学习技术的发展,尤其是Transformer架构的提出,机器翻译的性能得到了显著提升。Transformer架构通过引入自注意力机制(Self-Attention),能够更高效地处理序列数据,并捕捉长距离依赖关系。
本文将详细介绍如何构建和优化基于Transformer架构的机器翻译模型,包括概念讲解、代码示例、应用场景、注意事项以及相关的架构图和流程图。通过本文的介绍,读者可以系统地掌握Transformer架构在机器翻译中的应用。
机器翻译的基本概念
(一)机器翻译的定义
机器翻译是指利用计算机技术将一种自然语言文本自动翻译成另一种自然语言文本的过程。机器翻译的目标是实现高质量、高效率的跨语言信息交流。
(二)机器翻译的发展历程
机器翻译的发展经历了多个阶段:
-
基于规则的机器翻译(RBMT):依赖人工编写的翻译规则,灵活性差,难以处理复杂的语言现象。
-
基于统计的机器翻译(SMT):通过统计模型学习源语言和目标语言之间的对应关系,但依赖大量双语语料,且难以捕捉长距离依赖关系。
-
基于神经网络的机器翻译(NMT):利用神经网络模型直接将源语言映射为目标语言,能够捕捉复杂的语言模式,但早期的RNN和LSTM模型存在训练效率低、难以并行化等问题。
-
基于Transformer的机器翻译:引入自注意力机制,能够高效处理序列数据,捕捉长距离依赖关系,显著提升了翻译质量和效率。
(三)机器翻译的应用场景
机器翻译在多个领域都有广泛的应用,以下是一些常见的场景:
-
跨语言信息检索:帮助用户在不同语言的文档中检索信息。
-
在线翻译服务:如Google Translate、百度翻译等,为用户提供实时翻译服务。
-
多语言文档翻译:帮助企业和个人快速翻译文档。
-
跨文化交流:促进不同语言背景的人之间的交流与合作。
Transformer架构的核心思想
(一)自注意力机制(Self-Attention)
自注意力机制是Transformer架构的核心。它允许模型在计算某个位置的表示时,同时考虑整个序列的信息,从而捕捉长距离依赖关系。自注意力机制的计算公式如下:
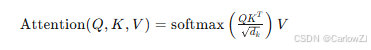
其中,Q、K、V分别表示查询(Query)、键(Key)和值(Value)矩阵,dk是键向量的维度。
(二)多头注意力机制(Multi-Head Attention)
多头注意力机制通过将输入分成多个头(Head),分别计算自注意力,然后将结果拼接起来,进一步提升了模型的表达能力。多头注意力的计算公式如下:
![]()
其中,![]()
(三)位置编码(Positional Encoding)
由于Transformer架构不依赖于序列的顺序信息,因此需要引入位置编码来为模型提供位置信息。位置编码可以通过正弦和余弦函数生成:

(四)Transformer架构的组成
Transformer架构由编码器(Encoder)和解码器(Decoder)组成:
-
编码器:将输入序列编码为上下文表示。
-
解码器:根据上下文表示生成目标序列。
编码器和解码器都由多个层(Layer)组成,每一层包含多头注意力机制和前馈神经网络(Feed-Forward Neural Network, FFNN)。
机器翻译模型的构建
(一)数据准备
1. 数据收集
机器翻译需要大量的双语语料,数据来源可以包括:
-
公开语料库:如WMT(Workshop on Machine Translation)提供的双语语料。
-
爬取数据:从互联网上爬取双语网页或文档。
-
人工翻译数据:由专业翻译人员翻译的数据。
2. 数据预处理
数据预处理是机器翻译的重要步骤,主要包括以下内容:
-
文本清洗:去除无关字符、HTML标签、特殊符号等。
-
分词:将文本分割为单词或短语。对于中文,需要使用分词工具(如jieba)。
-
对齐:确保源语言和目标语言的句子对齐。
-
构建词汇表:根据训练数据构建源语言和目标语言的词汇表。
3. 数据增强
可以通过以下方法增加数据多样性:
-
同义词替换:将某些单词替换为同义词。
-
句子重组:在保持语义的前提下,对句子进行重组。
(二)模型构建
1. 编码器(Encoder)
编码器由多个层组成,每一层包含多头注意力机制和前馈神经网络。编码器的输入是源语言的嵌入表示,输出是上下文表示。
2. 解码器(Decoder)
解码器也由多个层组成,每一层包含多头注意力机制和前馈神经网络。解码器的输入是目标语言的嵌入表示和编码器的上下文表示,输出是目标语言的翻译结果。
3. 损失函数

(三)模型训练与优化
1. 模型训练
使用深度学习框架(如TensorFlow、PyTorch)进行模型训练。训练过程包括:
-
数据加载:将数据分批次加载到模型中。
-
前向传播:计算模型的输出。
-
损失计算:计算模型的损失函数。
-
反向传播:更新模型的权重。
2. 模型优化
优化模型性能的方法包括:
-
超参数调整:调整学习率、批大小、隐藏层大小等超参数。
-
正则化:使用L2正则化、Dropout等方法防止过拟合。
-
早停机制:在验证集上监控模型性能,提前停止训练以防止过拟合。
(四)模型评估
使用测试集评估模型性能,常用的评估指标包括:
-
BLEU分数(Bilingual Evaluation Understudy):衡量翻译质量的指标,越高越好。
-
TER分数(Translation Edit Rate):衡量翻译编辑距离的指标,越低越好。
-
ROUGE分数(Recall-Oriented Understudy for Gisting Evaluation):衡量翻译召回率的指标,越高越好。
代码示例
(一)数据预处理
import re
import jieba
from sklearn.model_selection import train_test_split
def preprocess_text(text):
# 去除无关字符
text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9]', '', text)
# 分词
words = jieba.cut(text)
return " ".join(words)
# 示例文本
source_texts = ["这是一个测试句子。", "机器翻译很有趣。"]
target_texts = ["This is a test sentence.", "Machine translation is interesting."]
# 数据预处理
source_texts = [preprocess_text(text) for text in source_texts]
target_texts = [preprocess_text(text) for text in target_texts]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(source_texts, target_texts, test_size=0.2, random_state=42)(二)模型构建与训练(使用Transformer)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
from transformers import TransformerEncoder, TransformerDecoder
# 定义Transformer模型
class TransformerModel(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, embedding_dim, hidden_dim, num_layers, num_heads, dropout):
super(TransformerModel, self).__init__()
self.encoder = TransformerEncoder(src_vocab_size, embedding_dim, hidden_dim, num_layers, num_heads, dropout)
self.decoder = TransformerDecoder(tgt_vocab_size, embedding_dim, hidden_dim, num_layers, num_heads, dropout)
self.fc_out = nn.Linear(hidden_dim, tgt_vocab_size)
def forward(self, src, tgt):
encoder_output = self.encoder(src)
decoder_output = self.decoder(tgt, encoder_output)
return self.fc_out(decoder_output)
# 超参数设置
src_vocab_size = 10000 # 源语言词汇表大小
tgt_vocab_size = 10000 # 目标语言词汇表大小
embedding_dim = 512 # 词嵌入维度
hidden_dim = 512 # 隐藏层维度
num_layers = 6 # 编码器和解码器的层数
num_heads = 8 # 多头注意力的头数
dropout = 0.1 # Dropout概率
batch_size = 32
epochs = 10
# 构建数据集
train_dataset = TensorDataset(torch.tensor(X_train), torch.tensor(y_train))
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 初始化模型、优化器和损失函数
model = TransformerModel(src_vocab_size, tgt_vocab_size, embedding_dim, hidden_dim, num_layers, num_heads, dropout)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 训练模型
for epoch in range(epochs):
model.train()
total_loss = 0
for batch in train_loader:
src, tgt = batch
optimizer.zero_grad()
outputs = model(src, tgt)
loss = criterion(outputs.view(-1, tgt_vocab_size), tgt.view(-1))
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}/{epochs}, Loss: {total_loss/len(train_loader)}")(三)模型评估
from nltk.translate.bleu_score import sentence_bleu
# 测试模型
model.eval()
with torch.no_grad():
predictions = []
for src in X_test:
tgt = model(src)
predictions.append(tgt.argmax(-1).numpy())
# 计算BLEU分数
bleu_scores = []
for pred, tgt in zip(predictions, y_test):
bleu_scores.append(sentence_bleu([tgt], pred))
average_bleu = sum(bleu_scores) / len(bleu_scores)
print(f"Average BLEU Score: {average_bleu:.4f}")应用场景
(一)在线翻译服务
如Google Translate、百度翻译等,为用户提供实时翻译服务。这些服务通常基于Transformer架构的机器翻译模型,能够快速准确地翻译文本。
(二)多语言文档翻译
帮助企业和个人快速翻译文档,提高工作效率。例如,翻译技术文档、法律文件、学术论文等。
(三)跨语言信息检索
帮助用户在不同语言的文档中检索信息。例如,通过翻译查询关键词,帮助用户找到相关的外语文档。
(四)跨文化交流
促进不同语言背景的人之间的交流与合作。例如,在国际会议、跨国企业中,机器翻译可以帮助人们更好地理解彼此。
注意事项
(一)数据质量的重要性
机器翻译的性能高度依赖于数据质量。以下是一些注意事项:
-
数据清洗:去除无关字符、HTML标签、特殊符号等。
-
数据标注:确保标注数据的准确性,避免标注噪声。
-
数据平衡:确保源语言和目标语言的句子对齐,避免数据偏差。
(二)模型选择与优化
-
选择合适的模型:根据数据特点和任务需求选择合适的Transformer架构。
-
超参数调整:通过网格搜索或随机搜索调整超参数,找到最优的模型配置。
-
正则化:使用Dropout、L2正则化等方法防止过拟合。
(三)模型泛化能力
-
使用验证集:在验证集上监控模型性能,提前停止训练以防止过拟合。
-
数据增强:通过数据增强技术(如同义词替换、句子重组等)增加数据多样性,提高模型的泛化能力。
(四)计算资源
-
硬件需求:Transformer模型的训练需要大量的计算资源,建议使用GPU或TPU加速训练。
-
分布式训练:对于大规模数据,可以使用分布式训练技术提高训练效率。
总结
本文详细介绍了基于Transformer架构的机器翻译模型的构建与优化,包括概念讲解、代码示例、应用场景、注意事项以及相关的架构图和流程图。Transformer架构通过引入自注意力机制,能够高效处理序列数据,并捕捉长距离依赖关系,显著提升了机器翻译的性能。
在实际应用中,读者可以根据自己的需求进一步优化和调整模型。希望本文能够为读者提供有价值的参考,帮助大家更好地理解和应用基于Transformer架构的机器翻译技术。
参考文献
-
[1] Vaswani, A., et al. "Attention is all you need." Advances in Neural Information Processing Systems 30 (2017).
-
[2] Bahdanau, D., et al. "Neural machine translation by jointly learning to align and translate." ICLR (2015).
-
[3] Sutskever, I., et al. "Sequence to sequence learning with neural networks." Advances in Neural Information Processing Systems 27 (2014).



















 3714
3714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











