







大家好,在现代科技发展的背景下,机器学习任务对分布式计算的依赖日益加深。这些任务包括网络训练、超参数调优、模型部署和数据处理等,都对计算资源有着巨大的需求。缺乏集群计算支持,会导致这些任务处理速度缓慢,严重降低工作效率。
Ray这一分布式计算框架的出现,为解决计算瓶颈提供了有效途径。它专为Python语言设计,并且能够与PyTorch等深度学习库无缝协作,提升机器学习应用的开发速度和部署效率。
本文将介绍Ray生态系统的核心元素以及如何将其与PyTorch配合使用。
1.Ray简介

Ray是一个开源的Python库,专注于并行和分布式计算。
上图展示了从宏观角度观察,Ray的生态系统主要由三个关键部分组成:
1) Ray系统的核心:提供基础的并行和分布式计算能力
2) 可扩展的机器学习库:包括Ray团队开发的原生库,也包括社区贡献的第三方库。
3) 工具:用于在各种集群环境或云服务上轻松启动和管理集群。
这样的架构设计使Ray能够灵活适应不同的计算需求和环境,为用户提供强大的计算支持。
2.Ray的核心优势
Ray框架能够让Python应用程序在多个CPU核心或计算机上并行运行,显著提高了处理速度和计算效率。以下是Ray的主要优势:
-
简单性:不用重构代码,即可实现扩展Python应用程序,无论是在单机还是多台机器环境。
-
稳健性:即便面临硬件故障或任务抢占,应用仍能稳定运行,不受影响。
-
高性能:任务执行延迟低至毫秒级,可以扩展到数万个核心,同时在处理数值数据时保持低序列化开销。
3.库生态系统
由于Ray框架具有通用性,开发者社区已在其基础上开发出众多库和工具,用以应对各种不同的计算任务。这些库大多数都能与PyTorch兼容,且对原有代码的改动极小,实现了各个库之间的无缝集成。以下是Ray生态系统中众多库的若干示例。
3.1 RaySGD
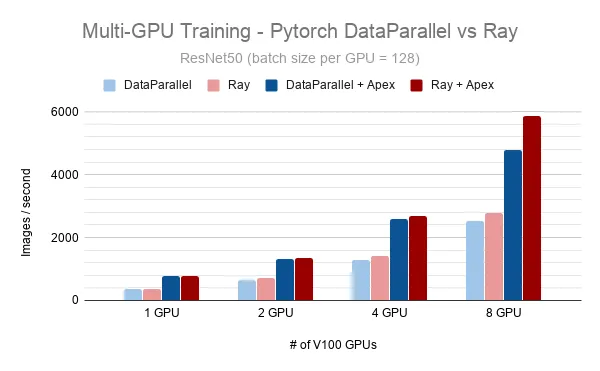
PyTorch的DataParallel与Ray在p3dn.24xlarge实例上的比较
RaySGD是一个专为数据并行训练提供分布式训练封装工具的库,旨在简化并加速训练流程。例如,RaySGD TorchTrainer是围绕torch.distributed.launch的封装器,通过提供Python API,可以将分布式训练集成到更广泛的Python应用中。这样一来,开发者无需将训练代码嵌入到复杂的bash脚本里,便能实现训练的分布式运行。
此外,RaySGD库还具备以下优势:
-
易用性:无需密切监控各个计算节点,即可扩展PyTorch的DistributedDataParallel。
-
可扩展性:支持从单一CPU到多节点、多CPU和多GPU集群的灵活扩展,仅需简单修改几行代码。
-
加速训练:内置支持使用NVIDIA Apex进行混合精度训练。
-
容错性:当云计算资源被抢占时,能够自动进行恢复。
-
兼容性:与其他库如Ray Tune和Ray Serve无缝集成。
可以通过安装Ray(pip install -U ray torch)并运行以下代码来开始使用TorchTrainer:
import torch
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
import torchvision.transforms as transforms
import ray
from ray.util.sgd.torch import TorchTrainer
from ray.util.sgd.torch import TrainingOperator
# https://github.com/kuangliu/pytorch-cifar/blob/master/models/resnet.py
from ray.util.sgd.torch.resnet import ResNet18
def cifar_creator(config):
"""Returns dataloaders to be used in `train` and `validate`."""
tfms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465),
(0.2023, 0.1994, 0.2010)),
]) # 均值和标准差的转换
train_loader = DataLoader(
CIFAR10(root="~/data", download=True, transform=tfms), batch_size=config["batch"])
validation_loader = DataLoader(
CIFAR10(root="~/data", download=True, transform=tfms), batch_size=config["batch"])
return train_loader, validation_loader
def optimizer_creator(model, config):
"""Returns an optimizer (or multiple)"""
return torch.optim.SGD(model.parameters(), lr=config["lr"])
CustomTrainingOperator = TrainingOperator.from_creators(
model_creator=ResNet18, # 返回nn.Module的函数
optimizer_creator=optimizer_creator, # 返回优化器的函数
data_creator=cifar_creator, # 返回数据加载器的函数
loss_creator=torch.nn.CrossEntropyLoss # 损失函数
)
ray.init()
trainer = TorchTrainer(
training_operator_cls=CustomTrainingOperator,
config={"lr": 0.01, # 用于optimizer_creator
"batch": 64 # 用于data_creator
},
num_workers=2, # 并行化的程度
use_gpu=torch.cuda.is_available(),
use_tqdm=True)
stats = trainer.train()
print(trainer.validate())
torch.save(trainer.state_dict(), "checkpoint.pt")
trainer.shutdown()
print("success!")
该脚本将下载CIFAR-10数据集,并使用ResNet-18模型进行图像分类。通过改变一个参数(num_workers=N),可以利用多个GPU来加速训练过程。
3.2 Ray Tune
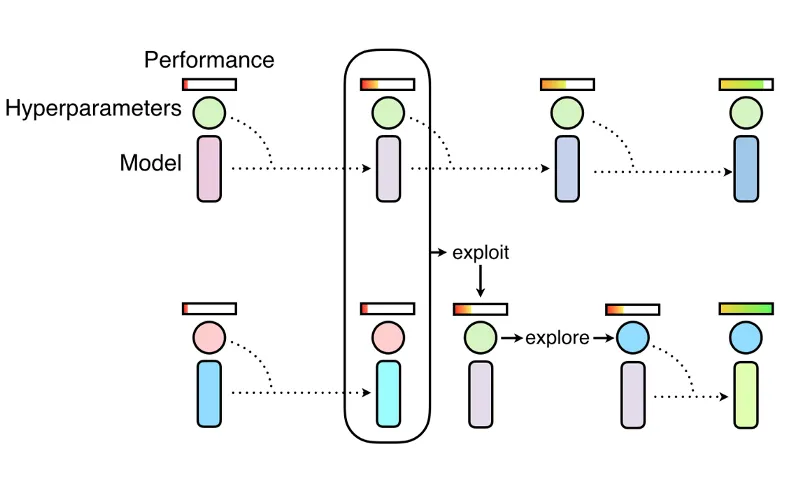
Ray Tune实现了诸如Population Based Training(如上图所示)等优化算法,这些算法可以与PyTorch一起使用,以构建性能更优的模型。
Ray Tune是一个用于实验执行并进行超参数优化的Python库,适用于不同规模的项目。该库的一些优点包括:
-
能够在不到10行代码的情况下,即可开展多节点的分布式超参数搜索。
-
兼容所有主流的机器学习框架,包括PyTorch。
-
提供对GPU的直接支持,优化计算效率。
-
自动进行模型检查点的保存,并支持将训练过程记录到TensorBoard,方便追踪和可视化。
可以通过安装Ray(pip install ray torch torchvision)并运行以下代码来开始使用Ray Tune。
import numpy as np
import torch
import torch.optim as optim
from ray import tune
from ray.tune.examples.mnist_pytorch import get_data_loaders, train, test
import ray
import sys
if len(sys.argv) > 1:
ray.init(redis_address=sys.argv[1])
import torch.nn as nn
import torch.nn.functional as F
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(1, 3, kernel_size=3)
self.fc = nn.Linear(192, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 3))
x = x.view(-1, 192)
x = self.fc(x)
return F.log_softmax(x, dim=1)
def train_mnist(config):
model = ConvNet()
train_loader, test_loader = get_data_loaders()
optimizer = optim.SGD(
model.parameters(), lr=config["lr"], momentum=config["momentum"])
for i in range(10):
train(model, optimizer, train_loader, torch.device("cpu"))
acc = test(model, test_loader, torch.device("cpu"))
tune.track.log(mean_accuracy=acc)
if i % 5 == 0:
# 这会将模型保存到试验目录中
torch.save(model.state_dict(), "./model.pth")
from ray.tune.schedulers import ASHAScheduler
search_space = {
"lr": tune.choice([0.001, 0.01, 0.1]),
"momentum": tune.uniform(0.1, 0.9)
}
analysis = tune.run(
train_mnist,
num_samples=30,
scheduler=ASHAScheduler(metric="mean_accuracy", mode="max", grace_period=1),
config=search_space)3.3 Ray Serve
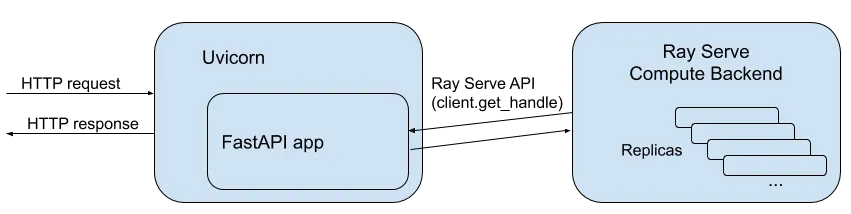
Ray Serve不仅可以单独用于部署模型,还可以用来扩展其他服务工具,比如FastAPI。
Ray Serve是个易于使用的可扩展模型服务库,该库的一些优点包括:
-
能够通过统一的工具集处理和服务各类模型,包括但不限于深度学习模型(如PyTorch、TensorFlow)以及scikit-learn模型,同时也支持任意Python业务逻辑的部署。
-
具备跨多台机器扩展服务的能力,无论这些机器位于本地数据中心还是云环境中。
-
与许多其他库如Ray Tune和FastAPI等具有良好的兼容性。
3.4 RLlib
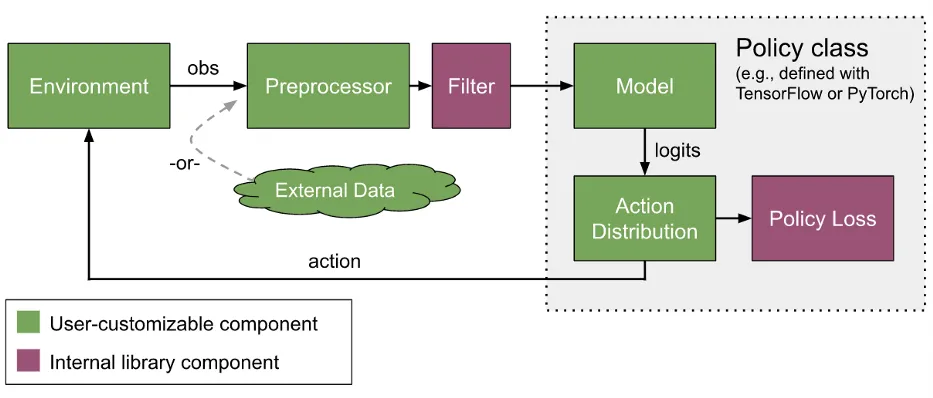
RLlib提供了定制训练几乎各个方面的方法,包括神经网络模型、动作分布、策略定义、环境以及样本收集过程。
RLlib是个强化学习库,提供了高度可扩展性和统一的API,适用于各种应用场景。一些优势包括:
-
原生兼容多个深度学习框架,包括PyTorch、TensorFlow Eager模式以及TensorFlow的1.x和2.x版本。
-
支持多种强化学习算法,如模型无关的算法、基于模型的算法、进化算法、规划算法以及多智能体算法。
-
通过简单的配置和自动封装机制,轻松实现复杂模型结构的构建,例如注意力网络和LSTM堆栈。
3.5 Cluster Launcher(集群启动器)
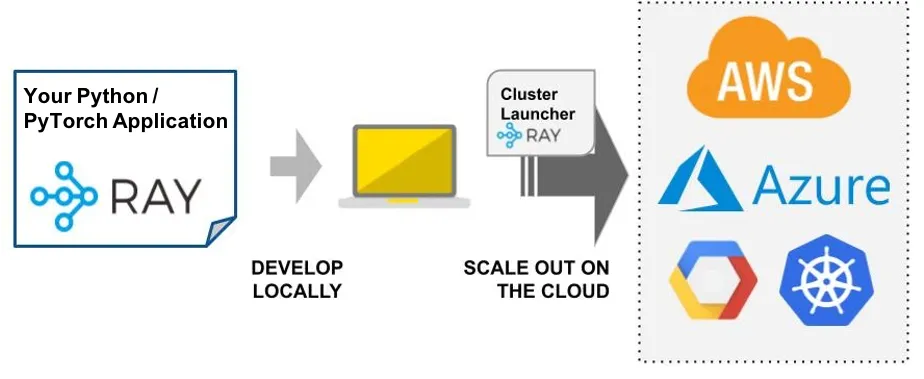
Ray集群启动器简化了在任何集群或云服务提供商上启动和扩展的过程。
当开发者在笔记本电脑上开发完应用程序,并打算将其部署到云端以处理更大规模的数据或利用更多的GPU资源时,接下来的部署步骤可能会显得有些复杂。通常,可以选择让基础设施团队来协助配置,或者自己手动完成以下操作:
-
选择一个云服务提供商,如AWS、GCP或Azure。
-
通过管理控制台配置实例类型、安全组、竞价价格、实例限制等参数。
-
确定如何在集群中部署和运行您的Python脚本。
为了简化这一过程,可以使用Ray集群启动器,它能够在任何云服务提供商或集群环境中快速启动和扩展计算资源。Ray集群启动器支持自动扩缩容、文件同步、脚本提交和端口映射等功能,让开发者能够在Kubernetes、AWS、GCP、Azure或私有集群上无缝运行Ray集群,而无需深入了解集群管理的具体细节。
4.总结

Ray为蚂蚁集团的融合引擎提供了分布式计算基础
综上所述,本文介绍了Ray在PyTorch生态系统中所带来的一系列优势。Ray已经得到了广泛应用,涵盖了从蚂蚁集团使用Ray支持其金融业务,到LinkedIn在Yarn上部署Ray,以及Pathmind将Ray用于将强化学习技术整合到模拟软件中的多个场景。


















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











