







 本文详细介绍了如何使用Python和深度学习技术,特别是LSTM序列到序列模型,来创建一个在Twitter平台上提供客户服务的聊天机器人。从技术要求到模型训练,再到实际应用,涵盖了聊天机器人的架构、LSTM模型的建立和推特数据的处理,以及训练和推断过程。
本文详细介绍了如何使用Python和深度学习技术,特别是LSTM序列到序列模型,来创建一个在Twitter平台上提供客户服务的聊天机器人。从技术要求到模型训练,再到实际应用,涵盖了聊天机器人的架构、LSTM模型的建立和推特数据的处理,以及训练和推断过程。
在现实场景中,很难判断是否需要聊天机器人。但是,可以根据图8-1所示的流程图来做出判断:

图8-1 用户互动模型
本章后面的内容将覆盖如下主题:
·聊天机器人的架构
·用于聊天机器人的LSTM序列到序列模型
·用序列到序列模型建立一个推特(Twitter)聊天机器人
1 技术要求
你需要具备Python 3、TensorFlow和Keras的基本知识。
本章的代码文件可以在GitHub上找到:
https://github.com/PacktPublishing/Intelligent-Projects-using-Python/tree/master/Chapter08
2 聊天机器人的架构
聊天机器人的核心是其自然语言处理框架。这个框架对用户提交的输入数据做分词(parsing)、翻译处理后,基于对用户输入数据的理解来给出响应。为了保证给出响应的合理性,聊天机器人也许需要向知识库和历史交易数据库寻求帮助。
因此,聊天机器人可以被粗略地分成两个类别:
·检索模型(Retrieval-based model):一般来说,这类模型依赖于查询表或者知识库,它能从预定义好的一系列回答中选择一个来返回给用户。尽管这种方法显得有些简单,但大多数商业化的聊天机器人都属于这一类。不同模型的差别在于从查询表或者知识库里选择一个最佳答案的算法,其精细程度不同。
·生成模型(Generative model):不同于检索模型,生成模型在模型运行时才生成答案。大多数生成模型为概率模型或者基于机器学习的模型。直到最近,生成模型大多使用马尔科夫链(Markov chain)模型来生成答案。随着深度学习不断成熟,基于循环神经网络的模型流行起来。又由于LSTM的循环神经网络模型能更好地处理长句子,聊天机器人的实现大多使用基于LSTM的生成模型来实现。
检索模型和生成模型都有各自的优缺点。检索模型从固定的答案集中给出答案,无法处理那些没有被事先定义好的问题或者请求。生成模型更加灵活,能理解用户的输入并生成类似人类才会给出的回答。然而,生成模型很难训练,需要更多的数据来学习,而且生成模型给出的回答会存在语法错误的情况,检索模型则不存在这种问题。
3 基于LSTM的序列到序列模型
序列到序列模型的架构很适合用来捕捉用户输入的上下文,并基于此生成合适的响应。图8-2展示了一个能自动回答问题的序列到序列模型的框架图。

图8-2 基于LSTM的序列到序列模型
从图8-2可以看到,编码器LSTM将单词的输入序列编码为一个隐藏状态向量 和一个单元状态向量
和一个单元状态向量 。LSTM编码器最后一步得到的隐藏状态和单元状态向量和基本上捕捉了整个输入句子的上下文。
。LSTM编码器最后一步得到的隐藏状态和单元状态向量和基本上捕捉了整个输入句子的上下文。
编码之后的信息和被送给解码器LSTM,作为其初始隐藏和单元状态。每个步骤中的解码器LSTM基于当前单词试图预测下一个单词,即当前单词是其输入。
在预测第一个单词时,送给LSTM的输入是一个代表开始的占位关键词,这意味着一个句子的开头。类似地,占位关键词代表句子的结尾。LSTM给出的预测值时,意味着输出停止。
在训练一个序列到序列模型时,我们知道作为解码器LSTM输入的前一个词。但是在推断阶段,我们没有这些目标单词,因此我们使用前一步作为输入。
4 建立序列到序列模型
本章用来实现聊天机器人的序列到序列模型与图8-2所示的基本模型稍有不同。修改之后的架构见图8-3。
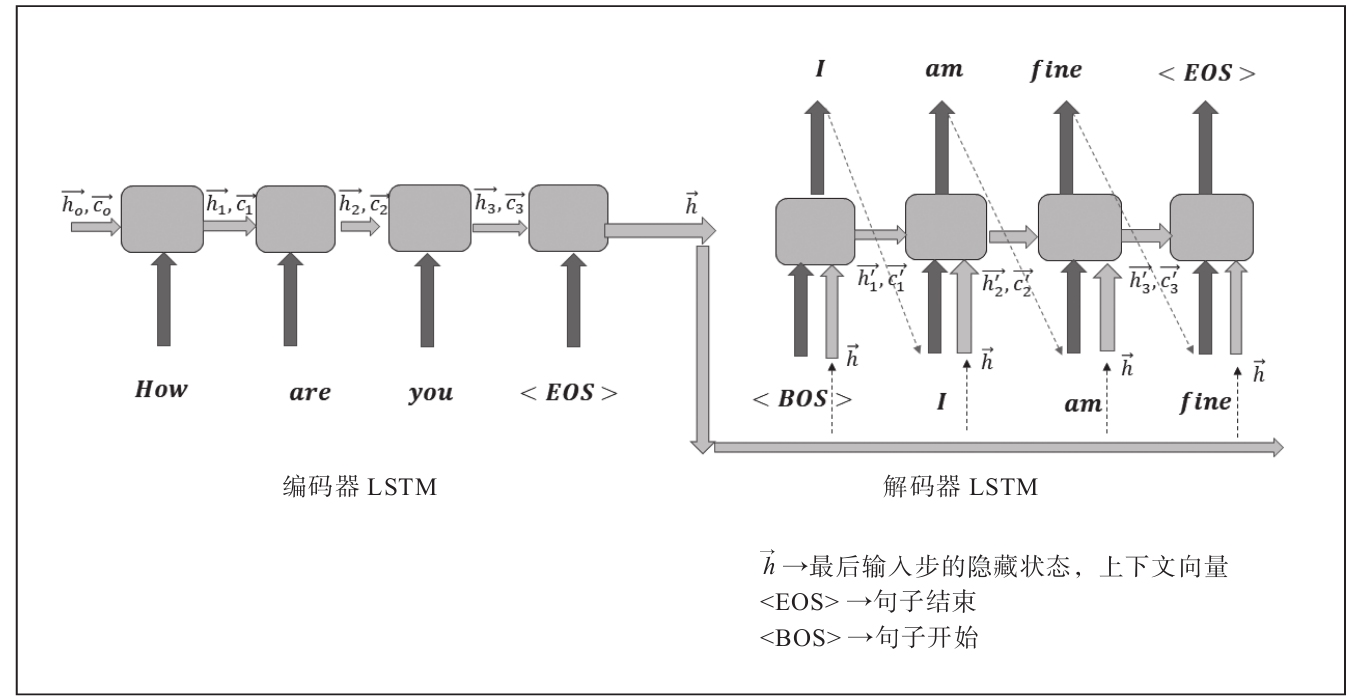
图8-3 序列到序列模型
这个模型没有用编码器最后一步输出的隐藏状态和单元状态作为解码器LSTM的初始隐藏状态和单元状态,取而代之的做法是把作为每一步解码器LSTM的输入。即在第t步,用前一个目标单词wt-1和同一个隐藏状态来预测目标单词wt。
5 Twitter平台上的聊天机器人
接下来我们将基于循环神经网络,并使用20个大品牌相关的用户推特数据和客服响应数据来创建一个聊天机器人。数据集twcs.zip位于在https://www.kaggle.com/thoughtvector/customer-support-on-twitter。数据集中,每条推特用tweet_id来标识区分,域text下是推特文字内容,域in_response_to_tweet_id用于识别用户推特:用户推特数据的域in_response_to_tweet_id值为null;客服推特的域in_response_to_tweet_id值是对应用户推特的tweet_id。
5.1 构造聊天机器人的训练数据
我们提取in_response_to_tweet_id值为null的推特数据来获得由用户发布的进站推特数据。类似地,提取in_response_to_tweet_id值不为null的推特数据为客服回应的出站数据。整理好进站和出站数据之后,合并进站数据和tweet_id、出站数据和in_response_to_tweet_id,从而得到用户给出的输入推特数据和客服给出的输出推特数据。数据的整理函数代码如下:
def process_data(self,path):
data = pd.read_csv(path)
if self.mode == 'train':
data = pd.read_csv(path)
data['in_response_to_tweet_id'].fillna(-12345,inplace=True)
tweets_in = data[data['in_response_to_tweet_id'] == -12345]
tweets_in_out =
tweets_in.merge(data,left_on=['tweet_id'],right_on=
['in_response_to_tweet_id'])
return tweets_in_out[:self.num_train_records]
elif self.mode == 'inference':
return data
5.2 将文本数据转换为单词索引
推特数据被输入神经网络之前,会被进一步切分、转化为数字。采用计数向量化(count vectorizer)方法来保留一定数量的高频单词,以生成聊天机器人的词汇空间。同时引入三个新的标记来标志一个句子的开头(START)、结尾(PAD)和任意的未知单词(UNK)。对推特数据进行分词的函数如下:


现在,切分好的词语需要转化为单词索引,才能被RNN直接处理。代码如下:
def words_to_indices(self,sent):
word_indices =
[self.vocabulary.get(token,self.UNK) for token in
self.analyzer(sent)] +
[self.PAD]*self.max_seq_len
word_indices = word_indices[:self.max_seq_len]
return word_indices
也可以把RNN预测的单词索引转化为单词,以构成一个句子。对应的代码如下:
def indices_to_words(self,indices):
return ' '.join(self.reverse_vocabulary[id] for id in indices if id
!= self.PAD).strip()
5.3 替换匿名用户名
在对推特数据进行分词处理之前,将数据中的匿名用户名替换为通用用户名能提高聊天机器人的泛化性,对应代码如下:

5.4 定义模型
基础版RNN架构本身因为存在梯度消失的问题,无法记住长句子文本中的长期数据依赖关系。借助于结构中的三个“门(gate)”,LSTM能有效记住长期依赖关系。因此,这里采用RNN的LSTM版本来构建序列到序列模型。
该模型用到了两个LSTM结构。第一个LSTM把输入的推特数据编码为一个上下文语境向量。这个语境向量对应编码器LSTM最后输出的隐藏状态(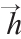 ∈Rn),n为隐藏状态向量的维度。推特数据
∈Rn),n为隐藏状态向量的维度。推特数据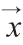 ∈Rk为单词索引的序列,作为编码器LSTM的输入,k是输入推特数据的序列长度。在送给LSTM之前,单词索引值基于单词嵌入被映射为向量w∈Rm,这里词嵌入使用一个嵌入矩阵[W∈Rm×N],这里N表示词汇表中单词的数目。
∈Rk为单词索引的序列,作为编码器LSTM的输入,k是输入推特数据的序列长度。在送给LSTM之前,单词索引值基于单词嵌入被映射为向量w∈Rm,这里词嵌入使用一个嵌入矩阵[W∈Rm×N],这里N表示词汇表中单词的数目。
第二个LSTM是一个解码器,它试图将编码器LSTM构建的上下文向量→h解码为有意义的输出。在每一步,同一个上下文向量和“前一个单词”一起生成当前单词。第一步时,没有“前一个单词”,这时用单词START代替,代表开始用解码器LSTM生成单词序列。推断时和训练时使用的“前一个单词”也不同。在训练时,前一个单词是已知的。然而在推断时,前一个单词是未知的,因此把上一步中预测得到的单词作为下一步中的解码器LSTM的输入。每一步中隐藏状态t'被输入神经网络,它在最后的softmax层之前经历了多个全连接层。此刻,将Softmax层中最大概率值对应的单词作为预测结果输出,而它是下一步(t+1时刻)的解码器LSTM的输入。
Keras中的TimeDistributed函数能快速获取每一步中解码器LSTM预测结果,其代码如下:


5.5 用于训练模型的损失函数
模型基于类别的交叉熵损失来进行训练,并在解码器LSTM的每一步预测目标单词。在任意一步,基于类别的交叉熵损失都会覆盖词汇表中的所有单词,表示如下:
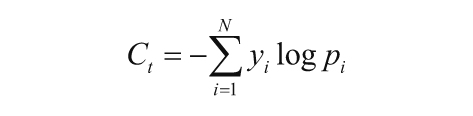
标签[yi]Ni=1代表目标单词的独热编码,其中,词汇表中第i个单词对应的标签是1,其余是0。项Pi是词汇表中第i个单词的概率值。为了得到每个输入/输出推特对(tweet pair)的总损失C,将对解码器LSTM在所有步骤计算得到的损失进行求和。由于词汇表中的单词可能非常多,每一步都为目标单词创建一个独热编码向量 会非常昂贵。这里采用sparse_categorical_crossentropy的损失函数将会更有利,即用目标单词的索引作为目标标签,而不用把目标单词转换为独热编码向量。
会非常昂贵。这里采用sparse_categorical_crossentropy的损失函数将会更有利,即用目标单词的索引作为目标标签,而不用把目标单词转换为独热编码向量。
5.6 训练模型
Adam因为其稳定收敛的可靠性,被用于模型训练。一般来说,循环神经网络模型容易存在梯度爆炸的问题(虽然对LSTM而言这不是大问题)。因此,最好在梯度变得过大时做梯度修剪。基于Adam优化器和sparse_categorical_crossentropy,模型的定义和编译代码块如下:

既然已经有了所有基本函数,训练函数的代码如下:

在train_model函数的开头,创建了input_y_train和input_y_test变量。这两个变量分别是y_train和y_test的拷贝,并且在每一步进行偏移,这样每一步中解码器的输入值是前一个单词。偏移之后,序列的第一个词是关键词START,作为第一步解码器LSTM的输入值。自定义的工具函数include_start_token如下:
def include_start_token(self,Y):
print(Y.shape)
Y = Y.reshape((Y.shape[0],Y.shape[1]))
Y = np.hstack((self.START*np.ones((Y.shape[0],1)),Y[:, :-1]))
return Y
回到训练函数train_model,如果10个轮次之后损失没有减少,则可以通过Eearly-Stopping来提前终止训练。类似地,如果误差在2个轮次之后没有减少,那么ReduceLR-OnPlateau会将当前的学习率减为一半。每当误差减少的时候,通过ModelCheckpoint来保存模型。
5.7 从模型生成输出响应
模型训练好后,我们希望用它对输入推特生成响应,该过程包括如下步骤:
1.替换输入推特中的匿名用户名为通用名。
2.转换输入推特数据为单词索引。
3.将单词索引序列输入编码器LSTM,并将START关键词输入解码器LSTM生成第一个预测单词。从下一步开始,把上一步预测得到的单词替代START关键词输入解码器LSTM。
4.继续执行上述步骤,直到预测出代表句子结尾的关键词PAD。
5.反向查询词汇表,把预测得到的单词索引转换为单词,并形成句子。
函数respond_to_input根据输入推特数据生成输出序列,其参考代码如下:
def respond_to_input(self,model,input_sent):
input_y = self.include_start_token(self.PAD *
np.ones((1,self.max_seq_len)))
ids =
np.array(self.words_to_indices(input_sent)).reshape((1,self.max_seq_len))
for pos in range(self.max_seq_len -1):
pred = model.predict([ids, input_y]).argmax(axis=2)[0]
#pred = model.predict([ids, input_y])[0]
input_y[:,pos + 1] = pred[pos]
return
self.indices_to_words(model.predict([ids,input_y]).argmax(axis=2)[0])
5.8 所有代码连起来
把所有代码连起来,main函数可以包含训练和推断两个流程。在训练函数中,也会根据输入推特序列来生成一些预测响应结果,从而检查模型训练得怎么样。main函数的参考代码如下:


5.9 开始训练
通过带参数运行模块chatbot.py(代码可在这个项目的GitHub上找到),可以开始训练,模块的调用指令如下:

下表是chatbot.py使用的一些重要参数及其描述以及模型训练时使用的参数值:
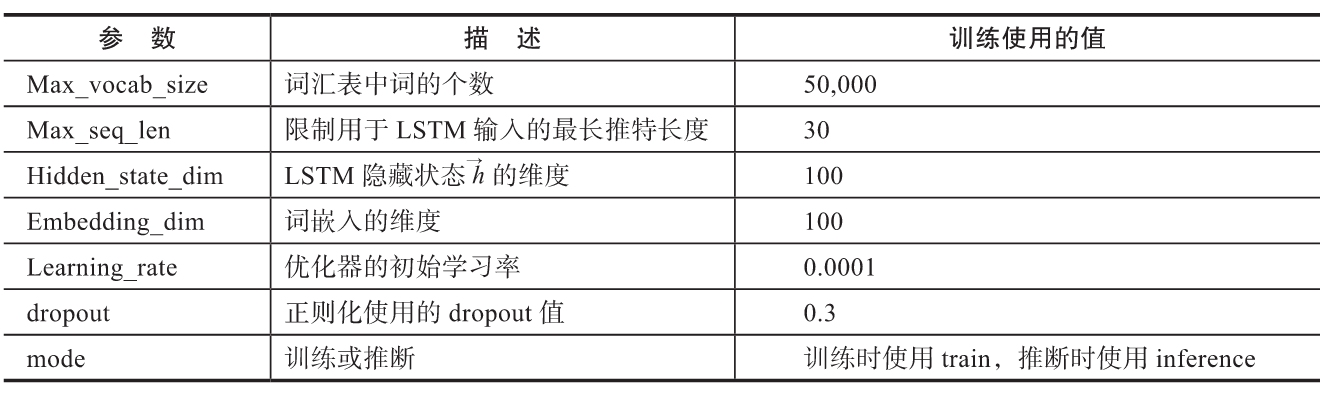
5.10 对一些输入推特的推断结果
训练得到的序列到序列模型能生成一些相关的推特内容,作为对输入推特的响应。推断指令的示例如下,参数data_path是用于测试的输入推特数据的位置。


推断的结果如下表所示:
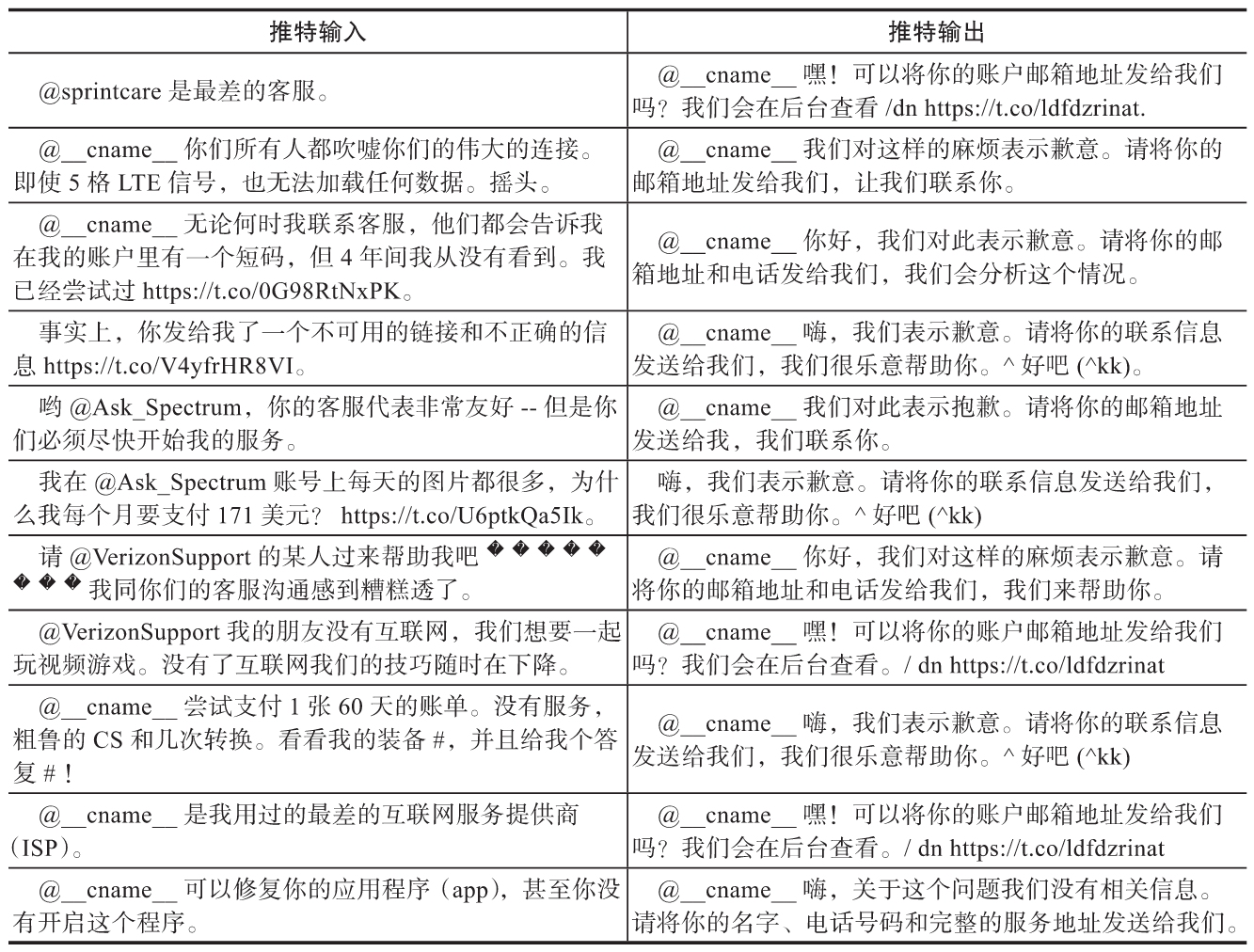
查看全部内容>>
VIP可查看全书完整内容(如下目录),戳链接,立即查看:https://book.csdn.net/book/detail/31658d10ef7c4ab2bd72800b50842ebb
CSDN会员享有VIP专享特权,立即使用VIP权益>>>
- N次资源下载、
- 近千本电子书免费阅读、
- 千门课程免费学习
- 35000+篇VIP专享文章免费阅读
- 博客自定义域名
- 全站免广告

















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









