










本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:实战 | 用Google Gemini实现目标检测(完整代码+步骤)
多模态 LLM 的一个更被低估的功能是它们能够生成边界框来检测对象。我记得我们向一些朋友展示您可以使用 Moondream 和 Qwen VL 检测物体,他们非常震撼。
然而,这些都是相对较小的模型。所以今天,我想写一篇关于其中一家大公司 Google 的 GenAI 模型的博客。我们将介绍如何使用结构化输出围绕此功能构建强大的工作流。我还将分享使用这些模型的局限性和经验教训。
使用 Gemini 进行对象检测
Gemini 模型经过训练,当提示明确提到类似"Detect the 2D bounding boxes of the ...." 的内容时,默认情况下会返回边界框。每个项目都包含一个格式为[y0, x0, y1, x1]的边界框 (box_2d) ,其标准化坐标范围为 0 到 1000,以及一个标识对象的标签 (label) 。

如下所示:
[{"box_2d": [57, 247, 385, 527], "label": "label1"},{"box_2d": [236, 664, 653, 860], "label": "label2"}]
结构化输出
但是,您知道我是结构化输出的大力倡导者。我们利用结构化输出,而不是依赖模型始终返回一致的 JSON 而不使用额外的文本,或者求助于复杂的正则表达式来解析 JSON 响应。结构化输出是 JSON 模式的后继者,通过直接返回捕获预期响应的数据模型实例来解决这些常见问题。
在内部,结构化输出指示 LLM 遵循由我们的数据模型验证的 JSON 架构。大多数主要参与者都支持此功能,并且许多框架都促进了结构化输出集成,我们将在下一节中探讨。
前面描述的关于检测到的边界框的所有逻辑都可以使用 Pydantic 模型(此处不包含代码)简洁地表示。
class BoundingBox(BaseModel):box_2d: list[int] = Field(..., description="[y1, x1, y2, x2]")label: str = Field(..., description="Unique Object label with unique feature")class BBoxList(BaseModel):bounding_boxes: list[BoundingBox]
Instructor + Gemini
Google GenAI 端点支持结构化输出。但是,我一点都不喜欢他们的 API,所以我们将使用 Instructor 来返回一个gemini-2.5-pro-preview-05-06BBoxList,让我们简单介绍 Instructor。
Instructor 是一个轻量级框架,旨在与各种 LLM 客户端轻松集成,支持“开箱即用”的结构化输出。Instructor 通过修补现有客户端来运行,增强它以接受名为 .genairesponse_model
提供此关键字参数后,Instructor 会在内部强制 Gemini 严格遵守 Pydantic 数据模型定义的架构,确保我们始终收到 .Pydantic 模型充当架构验证器,捕获边界框和标签。BBoxList
动手实践!
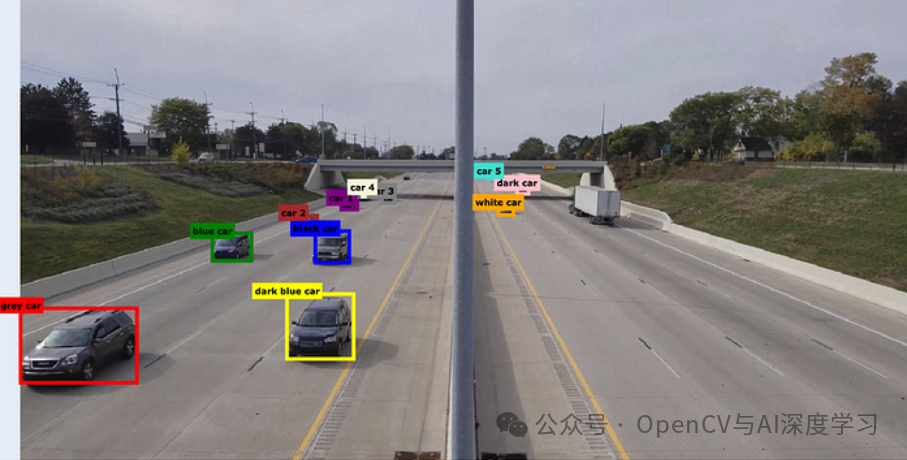
我们将使用一个经典示例。我们将检测下图中的汽车:

因此,让我们创建以下文件结构。
文件.env将包含您的GEMINI_API_KEY .你可以在这里得到一个。请注意,闪光灯是免费的,但对于专业型号(在本博客中使用),您需要添加您的信用卡。它们超级便宜,所以不用担心!
首先,让我们通过创建requirements.txt包含以下内容的文件来安装一些依赖项。
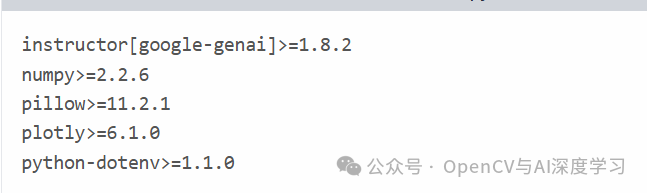
我们应用程序的核心
在我们的 Python 脚本 (app.py) 中,我们:
-
-
使用 Instructor 修补 genai 客户端。
-
定义捕获边界框逻辑的数据模型。
-
定义一个函数以将我们的图像转换为 base64 字符串。
-
创建一个函数,通过 Instructor 修补的客户端向 Gemini 发送请求。
-
import osimport ioimport base64import instructorfrom PIL import Imagefrom dotenv import load_dotenvfrom pydantic import BaseModel, Fieldfrom pathlib import Pathfrom google import genaifrom textwrap import dedentload_dotenv()client = genai.Client(api_key=os.getenv("GEMINI_API_KEY"))client = instructor.from_genai(client,mode=instructor.Mode.GENAI_TOOLS,)MODEL = "gemini-2.5-pro-preview-05-06"class BoundingBox(BaseModel):box_2d: list[int] = Field(..., description="[y1, x1, y2, x2]")label: str = Field(...,description=dedent("""Short label. Needs to be a unique label for each object,use numbers or unique features to generate unique labels"""),)class BBoxList(BaseModel):bounding_boxes: list[BoundingBox] = Field(..., description="Maximum of 20 elements")def convert_image2bs64(image_path: str) -> str:with Image.open(image_path) as img:buffer = io.BytesIO()img.save(buffer, format="PNG")buffer.seek(0)encoded_bytes = base64.b64encode(buffer.getvalue())bs64string = encoded_bytes.decode("utf-8")return bs64stringdef detect_objects(query: str, image_path: str) -> BBoxList:"""Detect objects based on a query."""bs64string = convert_image2bs64(image_path=image_path)return client.chat.completions.create(model=MODEL,messages=[{"role": "system","content": dedent("""You are a precise object detection agent who always checks and verifies whether the bounding box of the detected object is correct.You think step by step, always verifying that the bounding boxes are accurate."""),},{"role": "user","content": [query,instructor.multimodal.Image.from_base64(f"data:image/png;base64,{bs64string}"),],},],response_model=BBoxList,)if __name__ == "__main__":query = "Detect all cars in the image"image_path = Path(__file__).parent.parent / "test.png"bbox_list = detect_objects(query=query, image_path=str(image_path))print(bbox_list)
运行查询 “Detect all cars in the image” 会生成如下所示的边界框和标签!
bounding_boxes=[BoundingBox(box_2d=[689, 6, 834, 142], label='grey suv front left'), BoundingBox(box_2d=[506, 206, 585, 270], label='blue minivan left'), BoundingBox(box_2d=[644, 292, 787, 378], label='dark blue sedan left'), BoundingBox(box_2d=[501, 323, 576, 383], label='silver suv left center'), BoundingBox(box_2d=[446, 358, 479, 383], label='dark sedan left mid 1'),...]似乎一切都在正常。现在,我们将绘制结果以直观地验证它们。
让我们来显示它
我们将获取BBoxList实例的内容,并使用 Plotly 在图像顶部显示检测到的边界框。plot_bounding_boxes_go函数将逐步处理此任务。
以下是以下的细分:plot_bounding_boxes_go
-
-
使用 PIL 加载或解码 base64 图像
-
转换为 NumPy 数组,获取 ,确保 RGBh, w
-
使用 创建 Plotly 图go.Figure(go.Image(z=arr))
-
循环框:非规范化坐标,添加矩形和标签
-
显示图 (fig.show()) 并返回
-
# plot_tool.pyimport ioimport base64import numpy as npimport plotly.graph_objects as gofrom PIL import Image, ImageColoradditional_colors = list(ImageColor.colormap.keys())# Base palette of distinct colorsbase_colors = ['red', 'green', 'blue', 'yellow', 'orange', 'pink','purple', 'brown', 'gray', 'beige', 'turquoise','cyan', 'magenta', 'lime', 'navy', 'maroon','teal', 'olive', 'coral', 'lavender', 'violet','gold', 'silver']colors = base_colors + additional_colorsdef plot_bounding_boxes_go(image_input:str,noun_phrases_and_positions: list[tuple[str, tuple[int]]]) -> go.Figure:"""Plot image with colored bounding boxes and labels using Plotly go.Accepts either a PIL Image or a base64-encoded PNG string.noun_phrases_and_positions: List of (label, (y1, x1, y2, x2)) in 0–1000 normalized coords."""# Load or decode the imageheader, _, b64data = image_input.partition(',')raw = base64.b64decode(b64data or header)img = Image.open(io.BytesIO(raw)).convert('RGB')arr = np.array(img)h, w = arr.shape[:2]if arr.ndim == 2:arr = np.stack((arr,) * 3, axis=-1)fig = go.Figure(go.Image(z=arr))shapes, annotations = [], []for i, (phrase, (y1, x1, y2, x2)) in enumerate(noun_phrases_and_positions):color = colors[i % len(colors)]# Denormalize coordsabs_x1, abs_y1 = x1/1000*w, y1/1000*habs_x2, abs_y2 = x2/1000*w, y2/1000*h# Thicker rectangleshapes.append({'type': 'rect','x0': abs_x1, 'y0': abs_y1,'x1': abs_x2, 'y1': abs_y2,'line': {'color': color, 'width': 6}})# Filled label box, bold textannotations.append({'x': abs_x1,'y': abs_y1 - 4,'xref': 'x', 'yref': 'y','text': f"<b>{phrase}</b>",'showarrow': False,'font': {'color': 'black', 'size': 14},'bgcolor': color,'borderpad': 4,'align': 'left'})fig.update_layout(margin={'l': 0, 'r': 0, 't': 0, 'b': 0},xaxis={'visible': False},yaxis={'visible': False, 'autorange': 'reversed'},shapes=shapes,annotations=annotations)# Show figurefig.show()return fig
现在我们添加逻辑以将 LLM 响应连接到我们的 plot_tool.py 函数。
import osimport ioimport base64import instructorfrom PIL import Imagefrom dotenv import load_dotenvfrom pydantic import BaseModel, Fieldfrom pathlib import Pathfrom google import genaifrom textwrap import dedentfrom blog.plot_tool import plot_bounding_boxes_goload_dotenv()client = genai.Client(api_key=os.getenv("GEMINI_API_KEY"))client = instructor.from_genai(client,mode=instructor.Mode.GENAI_TOOLS,)MODEL = "gemini-2.5-pro-preview-05-06"class BoundingBox(BaseModel):box_2d: list[int] = Field(..., description="[y1, x1, y2, x2]")label: str = Field(...,description=dedent("""Short label. Need to be Unique label for each object,use numbers or unique features to generate unique labels"""),)class BBoxList(BaseModel):bounding_boxes: list[BoundingBox] = Field(..., description="Max 20 elements")def convert_image2bs64(image_path: str) -> str:with Image.open(image_path) as img:buffer = io.BytesIO()img.save(buffer, format="PNG")buffer.seek(0)encoded_bytes = base64.b64encode(buffer.getvalue())bs6string = encoded_bytes.decode("utf-8")return bs6stringdef detect_objects(query: str, image_path: str) -> BBoxList:"""Detect objects based on a query"""bs6string = convert_image2bs64(image_path=image_path)return client.chat.completions.create(model=MODEL,messages=[{"role": "system","content": dedent("""You are a precise object detection agent who always checks and thinks whether the bounding box of the detected object is correct.You think step by step, always verifying that the bounding boxes are accurate."""),},{"role": "user","content": [f"{query}",instructor.multimodal.Image.from_base64(f"data:image/png;base64,{bs6string}"),],},],response_model=BBoxList,)if __name__ == "__main__":query = "Detect all cars in the image"image_path = Path(__file__).parent.parent / "test.png"bbox_list = detect_objects(query=query, image_path=str(image_path))bbox2plot = [(bbox.label, bbox.box_2d) for bbox in bbox_list.bounding_boxes]img = convert_image2bs64(str(image_path))plot_bounding_boxes_go(img, bbox2plot)
如您所见,它运行良好。您已准备好使用案例对此进行测试。请注意,这与用例无关;您只需提供自己的查询,模型就会提供。
但是,我不想过度推销这一点,所以让我们讨论一下限制。
局限性
总体而言,Gemini 尚未与传统的对象检测模型(如 YOLO)或自定义训练模型相媲美。确定的主要限制包括:
-
-
标签和边界框位置的可变性,缺乏确定性。
-
Flash 模型的性能和可靠性较低,仅适用于明显的用例。
-
像 Gemini-2.5-pro 这样的大型型号提供了更好的结果,但偶尔仍会出现不一致的情况。
-
该模型有时会过度生成边界框;因此,限制最大检测次数是有益的。
-
这是一个使用gemini-2.5-flash-preview-04-17明显出错的输出:

我试图改进的地方
我尝试了各种提示技术和技巧来改善结果,但总的来说我失败了。我尝试的一些方法包括:
-
-
使用另一个模型来验证边界框并提供纠正反馈,这并没有显着改变 Gemini 的结果。
-
为单个对象检测进行异步 API 调用以提高边界框的准确性,但效果不佳。
-
采用另一种模型进行详细标记和精确边界框放置的成功率有限。
-
为了获得更好的结果,可能需要微调或蒸馏 YOLO 模型或直接将 YOLO 用作补充工具。尽管存在这些限制,Gemini 仍因其对象检测功能在主要的 LLM 提供商中脱颖而出。
Gemini 座的替代品
其他几个具有类似功能的型号,例如 Qwen VL 系列,已经进行了测试。还提供许多更小、适合微调的模型,提供值得探索的可行替代方案。请继续关注未来的博客,我将更深入地研究这些替代模型。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 209
209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









