







随着生成式AI技术“火爆出圈”,预示着人工智能未来发展趋势的同时,也为我国人工智能市场注入源源不断的活力,更多企业关注如何将“超级工具”应用到实际业务中去。
生成式人工智能技术在通用任务上表现优秀,但面对垂直业务领域,还无法给出精确的回答。如何在垂直领域针对特定知识构建企业专属问答并且确保生成的内容可控,是垂直领域服务的关键。
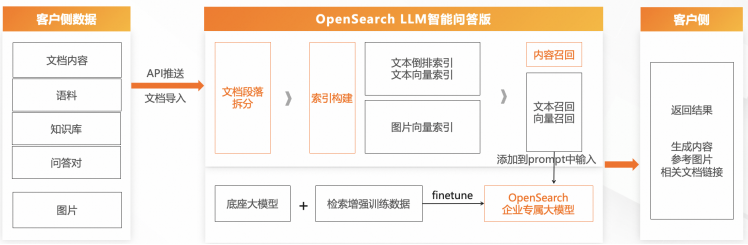
检索增强生成(Retrieval-augmented Generation,RAG),是当下最热门的大模型前沿技术之一。如果将“微调(finetune)”理解成大模型内化吸收知识的过程,那么RAG就相当于给大模型装上了“知识外挂”,基础大模型不用再训练即可随时调用特定领域知识。
阿里云智能开放搜索OpenSearch支持3种解决方案构建RAG系统,可快速在业务场景中进行实践及应用。
本文将介绍“OpenSearch LLM智能问答版”、“OpenSearch向量检索版+大模型”,以及“阿里开源搜索引擎Havenask+大模型”的实践方案,如何帮助企业快速搭建RAG系统。

阿里云OpenSearch LLM智能问答版——一站式端到端RAG系统
核心能力:两分钟、三步搭建企业级RAG系统
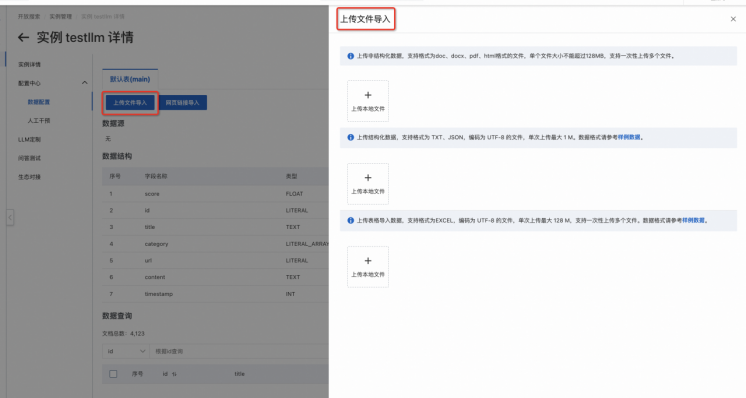
Step1:上传业务数据
通过控制台/API,快速上传业务数据
Step2:问答参数调整
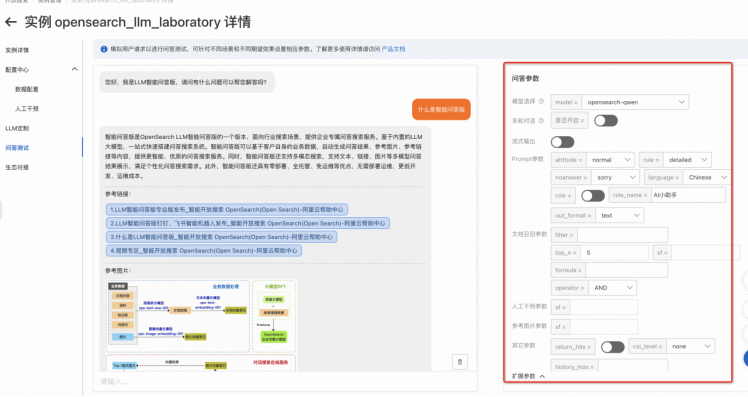
调整语言、检索、模型、Prompt等参数,测试RAG效果
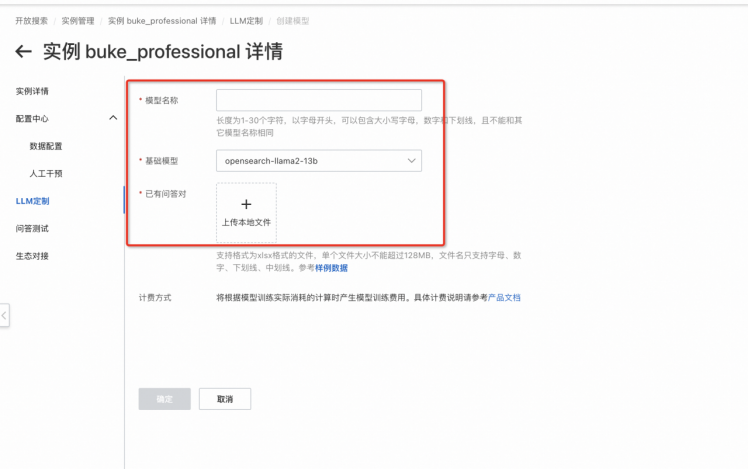
Step3:专属模型定制(可选)
基于个性化数据,定制企业专属LLM,进一步提升RAG准确率并降低幻觉率
产品优势:
一站式端到端RAG服务,简单易用:内置非结构化数据处理、向量模型、文本&向量检索、LLM的一站式开箱即用RAG方案,用户只需上传业务数据即可搭建RAG系统
精细化的RAG处理,效果过关:支持多样性的数据处理能力,基于多年沉淀的中文检索能力,配合数百个客户打磨的实战大模型,保障更优RAG效果
低成本、灵活计费方式:支持按量付费/GPU租用模式,每天最低5元即可实现RAG服务,大幅降低企业开发、运维、人力成本
典型用户:
应用场景:企业知识库、智能客服、电商导购、课程助手、搜索场景升级等
开发周期短,期望在短时间内快速构建RAG系统
企业内部无算法团队或有少量算法团队,期望结合自身业务构建RAG相关应用

阿里云OpenSearch向量检索版+大模型——PaaS化组件能力
核心能力:
对业务数据进行预处理,构建并存储向量索引
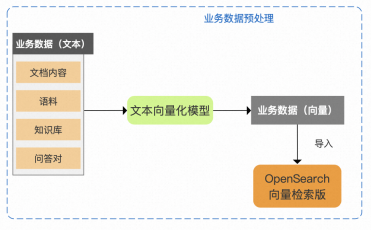
接收到用户请求后,对已有知识库进行向量检索,找到相关的信息,并作为Prompt输入到LLM中
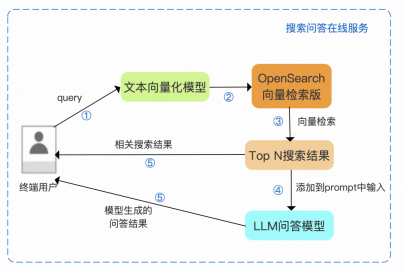
产品优势:
高性能向量检索服务:支持千亿数据毫秒级响应,实时数据更新秒级可见;向量检索性能优于开源向量搜索引擎数倍,在高QPS场景下召回率明显优于其他向量搜索引擎
更灵活的方案选型:灵活适配不同大模型服务,可根据自身业务情况按需对接大模型
低成本、快速搭建向量检索服务与RAG系统:通过数据压缩、精细索引结构设计、非全内存加载等方案,优化使用成本、降低所需的资源消耗
典型用户:
应用场景:企业知识库、智能客服、技术文档、课程助手等
已有成熟的大模型服务,但需要向量存储库和向量检索为大模型提供知识输入
企业内部有算法团队,期望结合自身业务构建RAG相关应用

阿里开源搜索引擎Havenask+大模型——开源方案
核心能力:
使用阿里巴巴自研的开源大规模高性能检索引擎Havenask进行文本+向量检索服务
基于Havenask-LLM工具,可将Havenask强大的向量检索能力与大模型结合,基于开源模型构建RAG系统
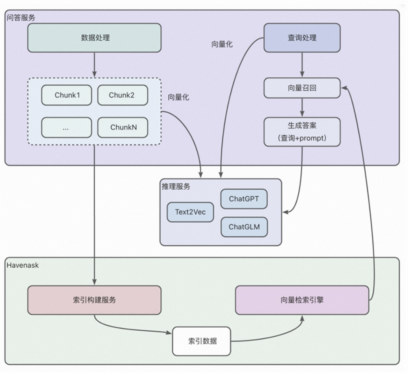
产品优势:
丰富积累的高性能检索引擎:支持单机10亿,超大规模高性能向量检索;千亿级数据实时检索,百万QPS查询;保障高并发情况下的性能和准确性
全开源、可定制、业务调整空间大:向量检索、大模型均使用开源方案,可使用丰富灵活的部署方式,业务适配性更高,发挥空间大
典型用户:
应用场景:企业知识库、智能客服、技术文档、课程助手等
业务数据相对敏感,需要私有化部署
期望使用更为灵活的开源技术栈
企业内部有资源丰富的工程、算法团队,期望结合自身业务构建RAG相关应用

方案对比与选型建议
方案对比:
功能对比 | LLM智能问答版 | 向量检索版 | Havenask |
切片服务 | √ | ||
向量模型 | √ | √ | |
向量检索 | √ | √ | √ |
LLM | √ | ||
是否开源 | √ |
选型建议:
用户类型 | 选型建议 |
期望一站式快速搭建RAG系统的用户 | OpenSearch-LLM智能问答版 |
已有明确大模型选型方案,期望搭建向量检索知识库的客户 | OpenSearch-向量检索版 |
期望使用开源方案自行部署向量检索的用户 | Havenask |


















 5884
5884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











