







一、卷积层
1、卷积层(Convolutional Layer)介绍
卷积神经网络中每层卷积层由若干卷积单元(卷积核)组成,每个卷积单元的参数都是通过反向传播算法最佳化得到的
卷积运算的目的是特征提取,第一层卷积层可能只能提取一些低级的特征,如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征
2、卷积核(Filter)的四大要素
卷积核 - Filter - 过滤器 - 模型参数
(1)卷积核个数
(2)卷积核大小
(3)卷积核步长
(4)卷积核零填充大小
接下来我们通过计算案例讲解,假设图片是黑白图片(只有一个通道)
3、卷积如何计算-大小
卷积核我们可以理解为一个观察的人,带着若干权重和一个偏置去观察,进行特征加权运算
注:上述要加上偏置
输入的图像:5 * 5,filter是3 * 3 * 1,乘以1个通道1
步长:是1,一次移动1格
输出:3 * 3 * 1
卷积核常用的大小:1 * 1,3 * 3,5 * 5
通常卷积核大小选择这些大小,是经过研究人员实验证明比较好的效果
观察之后会得到一个运算结果,那么这个人想观察所有这张图的像素怎么办?那就需要平移: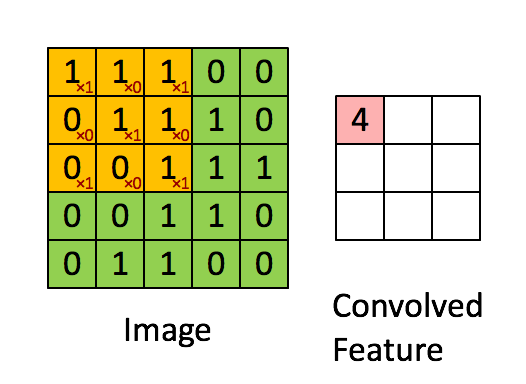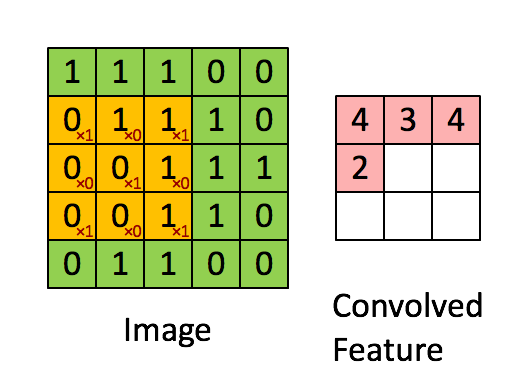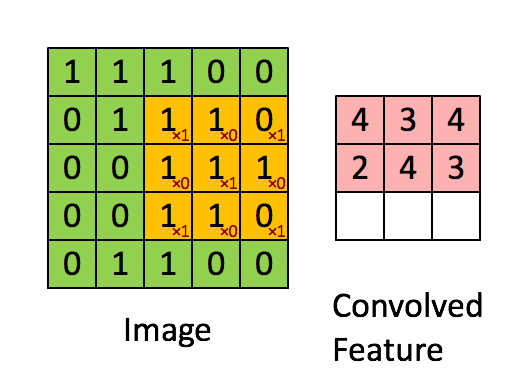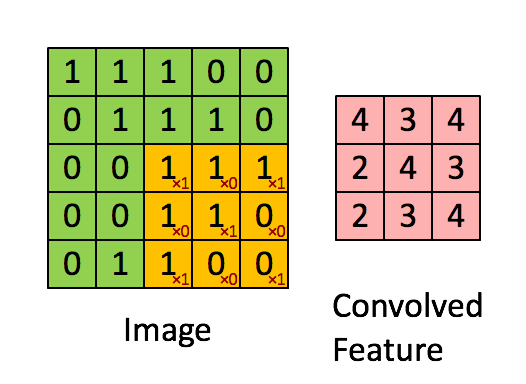
4、卷积如何计算-步长
需要去平移卷积核观察这张图片,需要的参数就是步长
假设移动的步长为一个像素,那么最终这个人观察的结果以下图为例:
5 * 5的图片,3 * 3的卷积大小,一个步长运算得到3 * 3的大小观察结果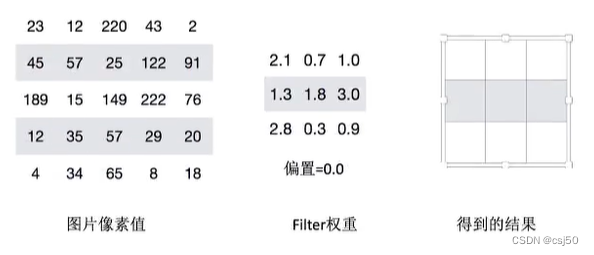
如果移动的步长变成2,那么结果是这样:
5 * 5的图片,3 * 3的卷积大小,2个步长运算,得到2 * 2的大小观察结果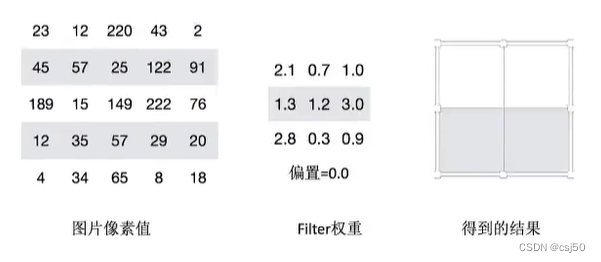
5、卷积如何计算-卷积核个数
那么如果在某一层结构当中,不止是一个人观察,多个人(卷积核)一起去观察,那就得到多张观察结果(盲人摸象?)
不同的卷积核带的权重和偏执都不一样,即随机初始化的参数
我们已经得出输出结果的大小由大小和步长决定的,但是只有这些吗?
还有一个就是零填充。Filter观察窗口的大小和移动步长有时会导致超过图片像素宽度!
6、卷积如何计算-零填充大小
零填充就是在图片像素外围填充一圈值为0的像素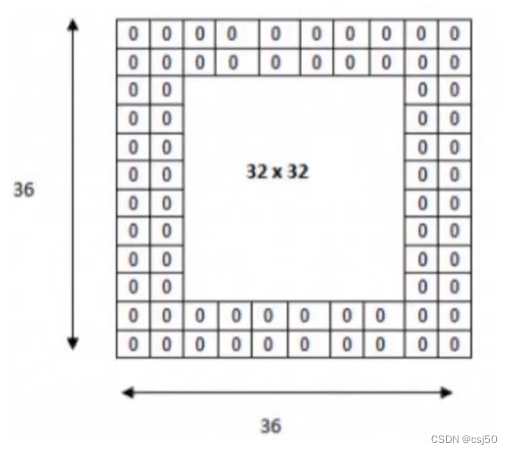
7、总结-输出大小计算公式
如果已知输入图片形状,卷积核数量,卷积核大小,以及移动步长,那么输出图片形状如何确定?
通过一个例子来理解公式:
计算案例:
(1)假设已知条件:输入图像32*32*1,50个Filter,大小为5*5,移动步长为1,零填充大小为1。请求出输出大小?
H1 = 32
W1 = 32
D1 = 1
K = 50
F = 5
S = 1
P = 1
H2 = (H1 - F + 2P) / S + 1 = (32-5+2*1)/1+1 = 30
W2 = (H1 - F + 2P) / S + 1 = (32-5+2*1)/1+1 = 30
D2 = K = 50
所以输出大小为[30, 30, 30]
(2)假设已知条件:输入图像32*32*1,50个Filter,大小为3*3,移动步长为1,未知零填充,输出大小32*32,求零填充大小?
H1 = 32
W1 = 32
D1 = 1
K = 50
F = 3
S = 1
P = ?
H2 = 32
H2 = (H1 - F + 2P) / S + 1 = (32-3+2*P)/1+1 = 32
W2 = (H1 - F + 2P) / S + 1 = (32-3+2*P)/1+1 = 32
所以零填充大小为:1 * 1
8、多通道图片如何观察
如果是一张彩色图片,那么就有三种表分别为R,G,B。原本每个需要带一个3*3或者其他大小的卷积核,现在需要带3张3*3的权重和一个偏置,总共就27个权重。最终每个人还是得出一张结果:
输入图片:7 * 7 * 3
Filter:3 * 3 * 3 + bias,有2个filter
H1 = 5
D1 = 3
K = 2
F = 3
S = 2
P = 1
H2 = (5-3+2)/2+1 = 3
W2 = 和H2一样 = 3
D2 = 2
输出:3 * 3 * 2
9、卷积网络API
tf.nn.conv2d(input, filter, strides=, padding=, name=None)
说明:
(1)计算给定4-D input和filter张量的2维卷积
(2)input:输入图像,给定的输入张量,具有[batch, height, width, channel]四阶的形状,类型为float32,64
(3)filter:指定过滤器的权重数量,[filter_height, filter_width, in_channels, out_channels]
filter_height:filter的高
filter_width:filter的宽
in_channels:输入图片的通道数
out_channels:输出图片的通道数
(4)strides:需要传一维数组,strides = [1, stride, stride, 1],步长
(5)padding:"SAME","VALID",具体解释见下面
Tensorflow的零填充方式有两种,SAME和VALID
(1)SAME:越过边缘取样,取样的面积和输入图像的像素宽度一致
公式:ceil(H/S)
H为输入的图片的高或者宽,S为步长
无论过滤器的大小是多少,零填充的数量由API自动计算
(2)VALID:不越过边缘取样,取样的面积小于输入人的图像的像素宽度。不填充
在Tensorflow当中,卷积API设置"SAME"之后,如果步长为1,输出高宽与输入大小一样(重要)
二、激活函数
1、sigmoid函数
随着神经网络的发展,大家发现原有的sigmoid等激活函数并不能达到好的效果,所以采取新的激活函数
2、ReLU函数
当输入的值小于0,就都置为0;输入的值大于0,保持原状。就是在输入值和0之间求最大值
效果是一批数,只取了第一象限
3、为什么采用新的激活函数
ReLU优点:
(1)有效解决梯度消失问题
(2)计算速度非常快,只需要判断输入是否大于0。SGD(梯度下降)的求解速度远快于sigmoid和tanh
sigmoid缺点:
(1)采用sigmoid等函数,计算量相对大,而采用ReLU激活函数,整个过程的计算量节省很多
(2)在深层网络中,sigmoid函数反向传播时,很容易就会出现梯度消失的情况
(3)输入值的范围[-6, 6]
sigmoid:1/(1 + e^-x)
4、playground演示不同激活函数作用
网址:https://playground.tensorflow.org/
(1)ReLU
(2)tanh
(3)sigmoid
5、由于图像像素点是0-255,不会小于0,所以用ReLU可以符合识别图像特征
6、ReLU激活函数API
tf.nn.relu(features, name=None)
说明:
(1)features:卷积后加上偏置的结果
(2)return:经激活函数之后的结果
三、池化层
1、介绍
池化层(Pooling)主要的作用是特征提取,通过去掉Feature Map中不重要的样本,进一步减少参数数量。Pooling的方法很多,通常采用最大池化
(1)max_pooling:取池化窗口的最大值
(2)avg_pooling:取池化窗口的平均值
(3)池化层其实相当于变种的relu
如左图所示:池化前长宽高是224*224*64当经过池化后变成112*112*64
如右图所示:整个图片被不重叠的分割成若干个同样大小的小块(pooling size)。每个小块内只取最大的数字,再舍弃其他节点后,保持原有的平面结构得出output
2、池化层计算
池化层也有窗口的大小以及移动步长,那么之后的输出大小怎么计算?计算公式同卷积计算公式一样
计算:224*224*64,窗口为2,步长为2,输出结果?
h2 = (224 - 2 + 2*0)/2 + 1 = 112
w2 = (224 - 2 + 2*0)/2 + 1 = 112
通常池化层采用2*2大小、步长为2窗口
3、池化层API
tf.nn.max_pool(input, ksize, strides, padding, data_format=None, name=None)
说明:
(1)输入上执行最大池化层
(2)value:输入的特征图,通常为4-D Tensor,形状为[batch, height, width, channels],batch表示样本数,height和width表示特征图的高度和宽度,channels表示通道数
(3)ksize:池化窗口大小,通常是一个四维张量,形状为[1, pool_height, pool_width, 1],pool_height表示池化窗口的高,pool_width表示池化窗口的宽
(4)strides:步长大小,通常是一个四维张量,形状为[1, stride_height, stride_width, 1],stride_height表示池化窗口在高度上的步长,stride_width表示池化窗口在宽度上的步长
(5)padding:指定是否在输入的四周填充0,可选值SAME和VALID,分别表示使用零填充和不填充
(6)data_format:指定输入数据的格式,默认为NHWC,表示(batch, height, width, channels)
四、全连接层(Full Connection)
1、前面的卷积和池化相当于做特征工程,最后的全连接层在整个卷积神经网络中起到“分类器”的作用
五、使用卷积神经网络实现mnist手写数字识别
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import models, layers
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.datasets import mnist
# 加载数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 搭建LeNet网络
def LeNet():
network = models.Sequential()
network.add(layers.Conv2D(filters=6, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)))
network.add(layers.AveragePooling2D((2, 2)))
network.add(layers.Conv2D(filters=16, kernel_size=(3, 3), activation='relu'))
network.add(layers.AveragePooling2D((2, 2)))
network.add(layers.Conv2D(filters=120, kernel_size=(3, 3), activation='relu'))
network.add(layers.Flatten())
network.add(layers.Dense(84, activation='relu'))
network.add(layers.Dense(10, activation='softmax'))
return network
network = LeNet()
network.compile(optimizer=RMSprop(learning_rate=0.001), loss='categorical_crossentropy', metrics=['accuracy'])
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float') / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# 训练网络,用fit函数, epochs表示训练多少个回合, batch_size表示每次训练给多大的数据
network.fit(train_images, train_labels, epochs=10, batch_size=128, verbose=2)
test_loss, test_accuracy = network.evaluate(test_images, test_labels)
print("test_loss:", test_loss, " test_accuracy:", test_accuracy)
之前全连接神经网络训练100个回合:
Epoch 100/100
469/469 - 1s - loss: 0.5069 - accuracy: 0.9679
313/313 [==============================] - 1s 1ms/step - loss: 0.6087 - accuracy: 0.9515
test_loss: 0.6087245941162109 test_accuracy: 0.9514999985694885
卷积神经网络训练10个回合:
Epoch 10/10
469/469 - 10s - loss: 0.0171 - accuracy: 0.9948
313/313 [==============================] - 2s 4ms/step - loss: 0.0356 - accuracy: 0.9882
test_loss: 0.03556874766945839 test_accuracy: 0.9882000088691711
全连接神经网络训练1次1s,卷积神经网络训练1次10s,所以全连接训练100次和卷积训练10次,总体时间行差不多,但是卷积训练出的损失和准确率比全连接好很多















 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









