









Wang P, Zhang H, Zhu M, et al. MGIML: Cancer Grading with Incomplete Radiology-Pathology Data via Memory Learning and Gradient Homogenization[J]. IEEE transactions on medical imaging. 2024
IF 10.6 SCIE JCI 2.38 Q1 医学1区 Top
【核心思想】
本文提出了一个新的框架,名为MGIML,用于处理不完整的放射学-病理学数据进行癌症分级。主要创新在于利用记忆学习和梯度均衡化来处理数据的不完整性问题。具体来说,论文介绍了两个关键方案:记忆驱动的异质模态补全(MH-Complete)和旋转驱动的梯度均衡化(RG-Homogenize)。这些方法旨在提高模型在处理不完整数据时的性能,通过记录和阅读跨模态记忆来补充丢失的模态信息,同时优化梯度方向和大小的冲突,以提高癌症分级的准确性和效率。
【Introduction】
本文的引言部分写的很好,这里直接全文翻译如下:
本文的引言部分指出,癌症分级是一个重要的临床任务,它依赖于放射学和病理学数据。然而,这些数据往往是不完整的,这对癌症分级的准确性构成了挑战,值得构建一个能够有效适应不同模态缺失情况的稳健模型。最近的主流解决方案包括:(1)知识蒸馏方法,将多模态教师学到的知识转移到单模态学生; (2)模态生成方法,使用可用的模态合成缺失的模态,以提供完整的模态输入数据; (3)共享信息提取方法,学习提取模态不变信息,从而使模型保持稳定和有效的性能; (4)模态掩蔽方法,通过随机丢弃一些模态来模拟模态丢失的情况来提高模型的鲁棒性。
利用不完整的放射病理学数据训练一个强大的癌症分级模型仍然面临两个挑战:(1)模态特定信息的丢失; (2) 模态缺失情况之间的冲突。
首先,由于任务只涉及两种模态,缺少一种模态通常会导致丢失相应的模态特定信息。与同质多模态 MRI 或 PET 图像不同,放射学和病理学数据具有对比的成像模式。因此,缺失模态特定信息中的许多判别性表示很难从现有模态中提取,这将影响一些缺失模态方法的性能。此外,跨模态合成是一种直观有效的解决方案,它采用可用的模态来生成缺失的模态以获得完整的多模态输入。然而,由于图像外观、颜色和结构之间存在巨大差距,直接使用图像级模态生成方法生成异构放射学和病理学数据具有挑战性。为了减少模态间成像间隙,另一种方法是在特征级别生成缺失的模态。最近的研究表明,记忆网络可以有效地记录通用特征模式,然后产生高相关性记忆特征。考虑到这一点,论文在特定于模态的分类记忆库中记录放射学和病理学特征,并设计一种有效的跨模态记忆读取策略来填充缺失的模态信息,这可以解决第一个挑战。其次,最近的工作建议在训练中采用部分不完整的多模态数据来模拟可能的缺失模态情况,以提高模型的鲁棒性。在本文中作者发现缺失模态特征通常由现有模态主导,导致缺失模态情况之间的梯度不一致。具体来说,这些缺失模态的情况将表现出不同的性能,并在优化过程中做出不一致的贡献。一方面,当梯度大小冲突时,高性能的情况将主导优化,导致优化不平衡问题。另一方面,当梯度方向冲突时,所有缺失模态的情况都将遭受不充分的优化。以前的缺失模态方法未能深入考虑这些问题,但最近的多任务学习工作表明,减轻任务之间的梯度冲突有利于解决上述问题。因此,可以将每个缺失模态的情况视为一个独立的任务,然后消除梯度方向和幅度冲突来处理第二个挑战。
在本文提出了一种记忆和梯度引导的不完整模态学习(MGIML)框架来实现不完整的放射病理数据癌症分级。首先提出了一种记忆驱动的异模态补充(MH-Complete)方案来弥补由于模态缺失而导致的模态特定信息的丢失。在MHComplete中,作者构建了模态特异性记忆库,在训练中分别记录放射学和病理学特征,并设计了跨模态记忆读取策略,采用现有模态读取缺失模态记忆库,从而提供缺失的模态特异性信息。作者还提出了粗粒度内存增强(CMB)和细粒度内存一致性(FMC)损失,以分别提高内存项的质量和跨模式内存读取的准确性。然后,提出了一种旋转驱动的梯度均质化(RG-Homogenize)方案来共同缓解缺失模态情况之间的梯度方向和幅度冲突。提出估计特定于实例的旋转矩阵来平滑缩小特征级梯度之间的方向差距,从而消除负迁移问题,而不是直接改变参数级梯度方向。同时,根据预测置信度在每个训练步骤中产生动态同质化权重,这些权重很好地平衡了不同缺失模态梯度的贡献,从而缓解了优化不平衡问题。主要贡献总结如下:
- 在多模态学习中,作者发现在缺失模态情况下存在潜在的梯度冲突,这会带来优化不平衡和负面转移问题,从而限制性能,论文从梯度优化的角度解决这些问题。
- 提出了MH-Complete来弥补缺失模态信息,通过记录特定模态的特征模式和阅读跨模态记忆来实现。
- 提出RG-Homogenize来解决优化不平衡和负面转移问题。它通过执行特征层级的梯度旋转和基于信心的梯度调制,分别减轻梯度方向和大小的冲突。
- 实验表明,提出的框架在不完整的放射学-病理学数据癌症分级方面优于现有最先进的方法,并有助于解决临床相关问题。
【II. RELATED WORKS】
A. Multi-modal Learning with Missing Modalities
主要讨论了在多模态学习中处理缺失模态的问题。这一部分强调了多模态学习在医学成像和其他领域的重要性,尤其是在数据可能不完整或缺失某些模态的情况下。在实际应用中,例如医学成像,由于各种原因(如技术限制、成本或患者条件等),收集到的数据可能不包含所有相关的模态信息。常见的处理方式如:知识蒸馏、模态生成方法、共享信息提取方法。这些方法通常忽略了缺失的异模态中重要的模态特定特征。
B. Memory Learning
记忆学习是一种特殊的机器学习方法,它通过构建和利用内部记忆机制来存储和检索重要信息。这种方法在处理缺失模态的情况下尤为重要,因为它可以帮助补充丢失的信息,并提高模型的整体性能。在多模态学习的背景下,记忆学习可以用于记录每个模态的特定特征模式。当某个模态缺失时,这些记录的模式可以用于预测或估计缺失模态的信息,从而允许模型利用所有相关模态进行更准确的决策和预测。在多模态学习的背景下,记忆学习可以用于记录每个模态的特定特征模式。当某个模态缺失时,这些记录的模式可以用于预测或估计缺失模态的信息,从而允许模型利用所有相关模态进行更准确的决策和预测。本文提出的MHComplete用于具有缺失模态的多模态学习,它记录模态特定信息并在训练中学习跨模态阅读,从而可以在测试中从存储良好的记忆中有效地补救缺失模态信息。
C. Gradient Optimization
在多任务学习中,许多研究证明梯度优化可以有效缓解优化不平衡和负迁移问题。在处理不完整的多模态数据时,可能会出现梯度方向和大小之间的冲突。这些冲突可能导致优化过程中的不平衡,进而影响学习模型的性能。例如,一个模态的强大梯度可能会压倒其他模态,导致模型无法有效地从所有可用模态中学习。因此,需要特别的策略来处理这些冲突,确保模型可以平衡地从所有模态中学习。
【III. METHODOLOGY】
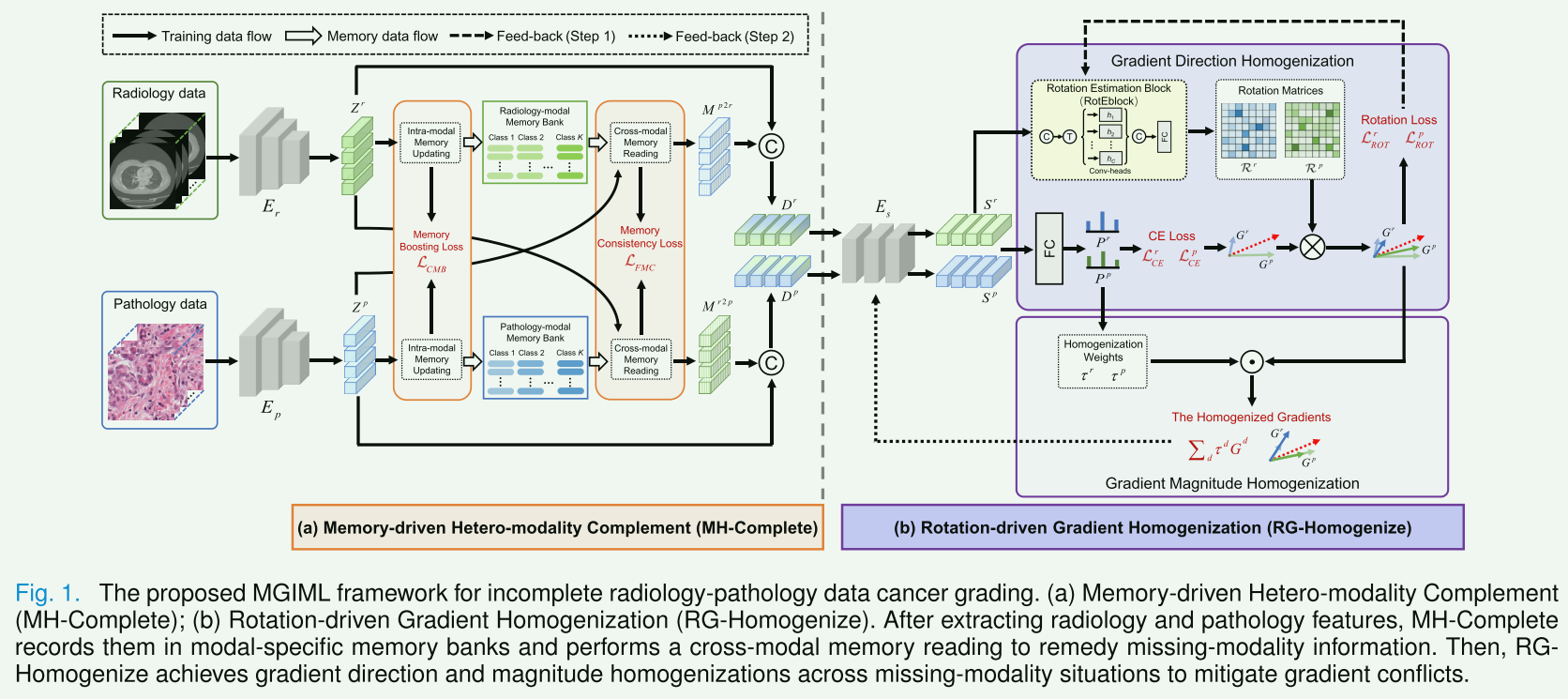
整体工作流程概述:给定放射学数据 { x n r , y n } n = 1 N \left\{x_{n}^{r}, y_{n}\right\}_{n=1}^{N} {xnr,yn}n=1N 和病理学数据 { x n p , y n } n = 1 N \left\{x_{n}^{p}, y_{n}\right\}_{n=1}^{N} {xnp,yn}n=1N 作为输入,其中 y n y_n yn 是共享的真实标签,我们首先采用特定于模态的编码器 E r E_r Er 和 E p E_p Ep 来提取放射学和病理学特征 Z r Z^r Zr 和 Z p Z^p Zp。
在 MH-Complete 中,构建特定于模态的记忆库,分别记录放射学和病理学特征模式,这些模式可以根据现有模态提供缺失模态信息。例如, Z r Z^r Zr 首先更新放射学模态记忆库的相应类别,然后转换为病理学模态查询 Zr2p,交叉读取病理学模态记忆库,产生基于记忆的病理学特征 Z r 2 p Z^{r 2 p} Zr2p。通过融合 Z r 2 p Z^{r 2 p} Zr2p 和 Z r Z^r Zr,产生缺失的病理学模态特征 D r D^r Dr。同样,可以获得缺失的放射学模态特征 D p D^p Dp。
在 RG-Homogenize 中,共享编码器 E s E_s Es 将 D r D^r Dr 和 D p D^p Dp 作为输入来预测特征 S r S^r Sr 和 S p S^p Sp。它们被输入到一个旋转估计模块(RotEblock)中,以估计用于特征级别梯度旋转的旋转矩阵 R r \mathcal{R}^{r} Rr 和 R p \mathcal{R}^{p} Rp。之后,RotEblock 通过一个精心设计的旋转损失进行优化,然后特征级别的缺失模态梯度分别与更新后的 R r \mathcal{R}^{r} Rr 和 R p \mathcal{R}^{p} Rp 相乘,以减少梯度方向冲突。另一方面,根据预测置信度计算的均衡化权重 τ r \tau^{r} τr 和 τ p \tau^{p} τp,用于平衡缺失模态情况的贡献,这缓解了梯度大小冲突。
采用交替优化方案来训练提出的框架。首先,使用旋转损失 L R O T \mathcal{L}_{R O T} LROT 优化 RotEblock 以产生旋转矩阵。接下来,使用它们来旋转特征级别的梯度,然后应用交叉熵( L C E \mathcal{L}_{C E} LCE)、CMB( L C M B \mathcal{L}_{C M B} LCMB)和 FMC( L F M C \mathcal{L}_{F M C} LFMC)损失来联合优化模型的其余参数。
A. Memory-driven Hetero-Modality Complement
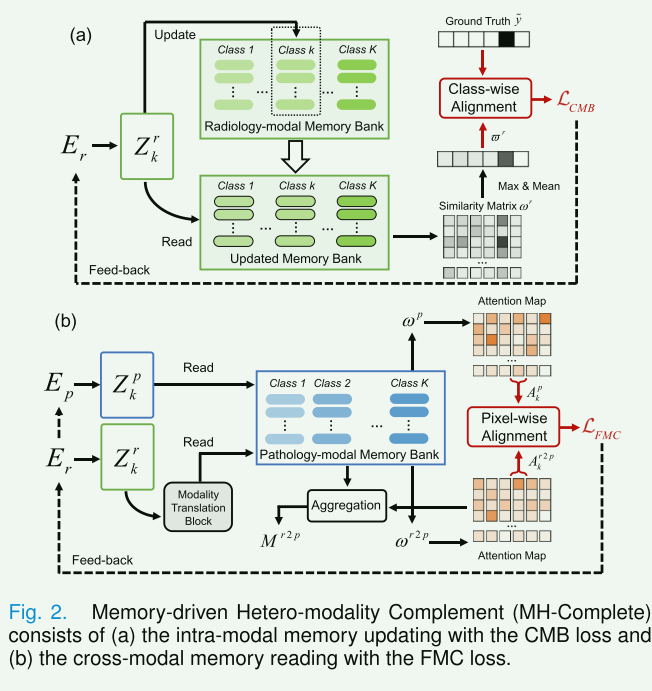
MH-Complete的目的:由于放射学和病理学数据之间的异质性,从现有模式中提取缺失模式信息非常困难。MH-Complete旨在记录模式特定的特征模式,然后为现有模式提供缺失模式信息。
MH-Complete的组成部分:
(1)模式内存更新:涉及在内存库中记录模式特定的特征模式。放射学和病理学的特征模式被分别记录,以提供缺失模式的信息。
具体流程:
-
特征提取:使用模式特定的编码器( E r E_r Er 和 E p E_p Ep)从放射学( X r X_r Xr)和病理学( X p X_p Xp)图像中提取特征( Z r Z^r Zr 和 Z p Z^p Zp)。这些特征被重塑为MH-Complete的输入。
-
内存库构建:构建放射学和病理学模式特定的内存库( Y r Y_r Yr 和 Y p Y_p Yp),用于分别存储放射学和病理学的类别特征。这些内存库可以存储类别信息,方便后续的特征匹配和更新。
-
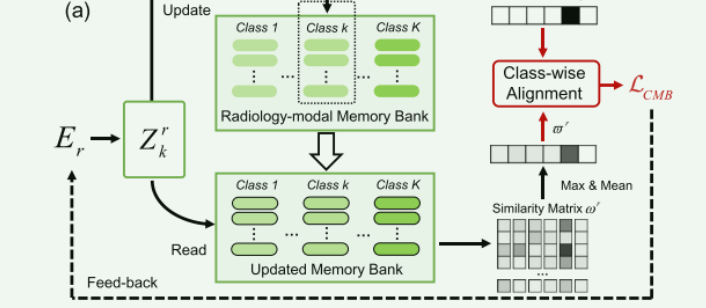
相似性计算与内存更新:
- 计算输入特征(例如 Z r Z^r Zr)和内存库(例如 Y r Y_r Yr)之间的相似性矩阵 ω r \omega^{r} ωr。这涉及计算内存项和查询项之间的余弦相似性: ω i , j , k r = m i , k ⋅ z j ∥ m i , k ∣ ∥ ∣ z j ∥ \omega_{i, j, k}^{r}=\frac{m_{i, k} \cdot z_{j}}{\left\|m _ { i , k } \left|\left\|\mid z_{j}\right\|\right.\right.} ωi,j,kr=∥mi,k∣∥∣zj∥mi,k⋅zj。
- 使用移动平均法根据相似性矩阵更新内存库中的相应类别。这意味着内存项会根据与它们最相似的查询项进行更新: m i , k ← γ m i , k + ( 1 − γ ) ∑ j 1 ( l ( j ) = i ) z j ∑ j 1 ( l ( j ) = i ) , if k = y m_{i, k} \leftarrow \gamma m_{i, k}+(1-\gamma) \frac{\left.\sum_{j} \mathbb{1}\left(l_{(} j\right)=i\right) z_{j}}{\left.\sum_{j} \mathbb{1}\left(l_{(} j\right)=i\right)} \text {, if } k=y mi,k←γmi,k+(1−γ)∑j1(l(j)=i)∑j1(l(j)=i)zj, if k=y
-
CMB损失的作用:
- 引入粗粒度内存增强(CMB)损失和细粒度内存一致性(FMC)损失,以提高内存项的质量和跨模式内存阅读的准确性。
- CMB损失的目的:旨在确保每个内存类别可以存储可靠的信息,并提高类内语义相似性和类间语义差异。
- **实现机制:**属于第 k k k类的特征可以在第 k k k个记忆类别中获得较高的相似度,而在其他记忆类别中获得较低的相似度。如:采用放射学特征 Z r Z^r Zr读取更新后的 Y r Y_r Yr,重新计算相似度矩阵 ω r \omega^{r} ωr。然后,通过对 ωr 的每一类进行max-mean值运算,得到粗粒度相似度矩阵 ϖ r ∈ R K \varpi^{r} \in \mathbb{R}^{K} ϖr∈RK: ϖ k r = 1 F H W ∑ i = 1 max j ( ω i , j , k r ) . \varpi_{k}^{r}=\frac{1}{F H W} \sum_{i=1} \max _{j}\left(\omega_{i, j, k}^{r}\right) . ϖkr=FHW1∑i=1maxj(ωi,j,kr).然后可以将粗粒度相似度矩阵 ϖ r \varpi^{r} ϖr 和独热 ground truth y ~ ∈ R K \tilde{y} \in \mathbb{R}^{K} y~∈RK 对齐,从而得到CMB损失,其中 ε \varepsilon ε是正则化参数: L C M B = ∥ y ~ − ϖ r ∥ 2 + ε 2 + ∥ y ~ − ϖ p ∥ 2 + ε 2 \mathcal{L}_{C M B}=\sqrt{\left\|\tilde{y}-\varpi^{r}\right\|^{2}+\varepsilon^{2}}+\sqrt{\left\|\tilde{y}-\varpi^{p}\right\|^{2}+\varepsilon^{2}} LCMB=∥y~−ϖr∥2+ε2+∥y~−ϖp∥2+ε2
- 引入粗粒度内存增强(CMB)损失和细粒度内存一致性(FMC)损失,以提高内存项的质量和跨模式内存阅读的准确性。
(2)模式间内存阅读策略:利用现有模式来访问缺失模式的内存库,从而提供缺失的模式特定信息。这种策略有助于获取具有缺失模式信息的特征,并建立模式间特征关联
具体流程
-
跨模态记忆读取和注意力图构建
-
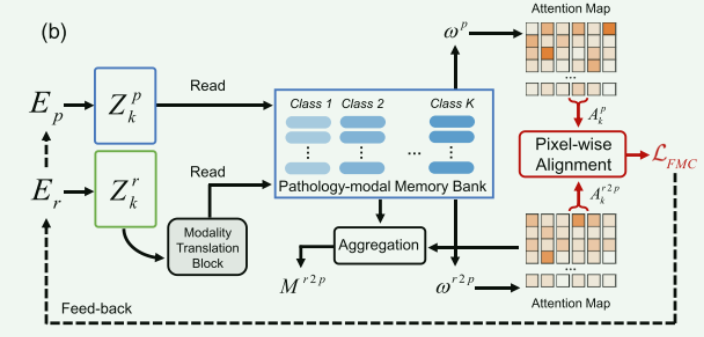
使用现有模式的特征(如 Z r Z_r Zr)作为查询项,来跨模式地读取另一模式(如病理学)的内存库(如 Y p Y_p Yp)。图 2 (b) 显示了放射学模态的工作流程,其中引入了通道号为 4 C 4C 4C 的额外 Swin Transformer 块作为模态转换块,以将现有模态特征 Z r Z_r Zr 传输为缺失模态查询 Z r 2 p Z^{r 2 p} Zr2p。然后,使用 Z r 2 p Z^{r 2 p} Zr2p读取病理模态存储库 Y p Y_p Yp以获得跨模态相似度矩阵 ω r 2 p \omega^{r 2 p} ωr2p。然后, ω r 2 p \omega^{r 2 p} ωr2p由softmax层传输作为注意力图 A r 2 p A^{r 2 p} Ar2p。
-
模态内记忆读取可以在训练中实现,并且比跨模态记忆读取更准确。考虑到这一点,论文使用病理特征 Z p Z_p Zp 读取 Y p Y_p Yp 以获得模态内相似度矩阵 ω p \omega^{p} ωp,然后生成相应的注意力图 A p A^p Ap
-
参考成熟的软注意力记忆读取方案,论文分别使用注意力图 A r 2 p A^{r 2 p} Ar2p和 A p 2 r A^{p 2 r} Ap2r聚合 Y r Y_r Yr和 Y p Y_p Yp,以产生跨模态记忆特征 M r 2 p M^{r 2 p} Mr2p和 M p 2 r M^{p 2 r} Mp2r,最后,通过分别concat Z r Z_r Zr 和 M r 2 p M^{r 2 p} Mr2p、 Z r p Z_rp Zrp 和 M p 2 r M^{p 2 r} Mp2r,获得缺失的病理学和放射学模态特征 D r D_r Dr 和 D p D_p Dp。
-
-
FMC损失作用: 使用KL散度对齐模态内和跨模态读取的注意力图: L F M C = KL ( A k r ∥ A k p 2 r ) + KL ( A k p ∥ A k r 2 p ) \mathcal{L}_{F M C}=\operatorname{KL}\left(A_{k}^{r} \| A_{k}^{p 2 r}\right)+\operatorname{KL}\left(A_{k}^{p} \| A_{k}^{r 2 p}\right) LFMC=KL(Akr∥Akp2r)+KL(Akp∥Akr2p)
B. Rotation-driven Gradient Homogenization
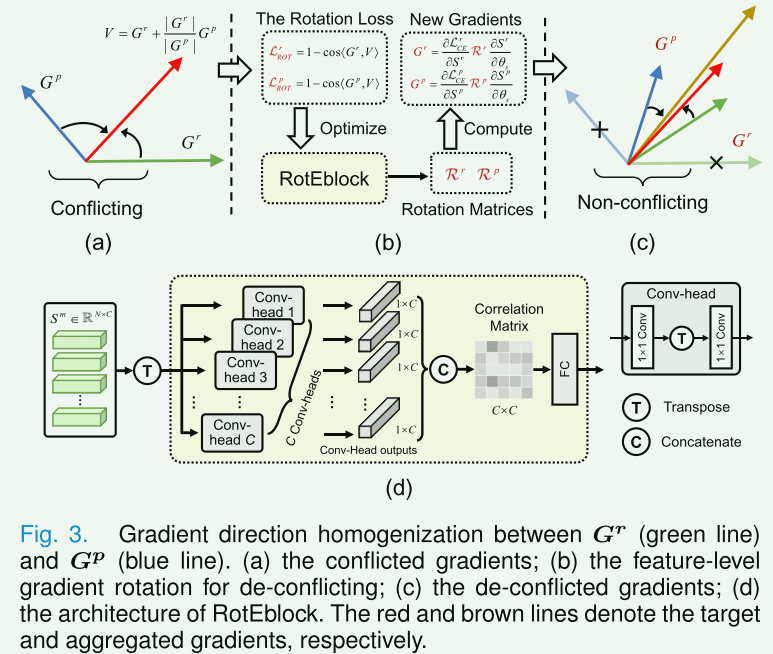
论文中提到三点之前研究中提出的问题:
1.梯度方向冲突可能导致负迁移问题(学习新技能或知识时,之前的经验或知识反而成为了学习新事物的障碍),从而限制了模型在每种缺失模态情况下的性能。
2.由于模态之间潜在的梯度冲突,很难充分利用多模态数据来优化多模态模型。
3.梯度幅值冲突会带来优化不平衡问题。
RG-Homogenize的目的:RG-Homogenize旨在解决多任务学习中常见的梯度冲突问题。它通过估计特定于实例的旋转矩阵来平滑地旋转特征级别的梯度,使其方向更加一致,同时利用预测置信度来解决梯度大小冲突。
**方向需要均衡的原因:**给定在上一步跨模态记忆读取和注意力图构建上得到的缺失的病理学和放射学模态特征 D r D_r Dr 和 D p D_p Dp,使用参数 θ s \theta_{s} θs 联合训练共享编码器 E s E_s Es,它们的梯度为 G r = ∇ θ s L C E r = ∂ L C E r ∂ θ s G^{r}=\nabla_{\theta_{s}} \mathcal{L}_{C E}^{r}=\frac{\partial \mathcal{L}_{C E}^{r}}{\partial \theta_{s}} Gr=∇θsLCEr=∂θs∂LCEr 和 G p = ∇ θ s L C E p = ∂ L C E p ∂ θ s G^{p}=\nabla_{\theta_{s}} \mathcal{L}_{C E}^{p}=\frac{\partial \mathcal{L}_{C E}^{p}}{\partial \theta_{s}} Gp=∇θsLCEp=∂θs∂LCEp 。采用梯度下降法,参数 θ s \theta_{s} θs的优化过程可以表示为: θ s t + 1 = θ s t − η ( G r + G p ) \theta_{s}^{t+1}=\theta_{s}^{t}-\eta\left(G^{r}+G^{p}\right) θst+1=θst−η(Gr+Gp),梯度方向冲突可以通过计算 G r G_r Gr和 G p G_p Gp之间的余弦相似度来定义。当 cos ⟨ G r , G p ⟩ ≠ 1 \cos \left\langle G^{r}, G^{p}\right\rangle \neq 1 cos⟨Gr,Gp⟩=1时,存在梯度方向冲突,可能导致所有缺失模态情况都被低估优化。
**幅值需要均衡的原因:**梯度幅值冲突会带来优化不平衡问题。设 w w w 为最后一个 FC 层,上面的梯度更新过程可以重新写为: θ s t + 1 = θ s t − η ( ∂ ( C E ⟨ w ⋅ S r , y ⟩ ) ∂ θ s + ∂ ( C E ⟨ w ⋅ S p , y ⟩ ) ∂ θ s ) \theta_{s}^{t+1}=\theta_{s}^{t}-\eta\left(\frac{\partial\left(\mathrm{CE}\left\langle w \cdot S^{r}, y\right\rangle\right)}{\partial \theta_{s}}+\frac{\partial\left(\mathrm{CE}\left\langle w \cdot S^{p}, y\right\rangle\right)}{\partial \theta_{s}}\right) θst+1=θst−η(∂θs∂(CE⟨w⋅Sr,y⟩)+∂θs∂(CE⟨w⋅Sp,y⟩)),其中的 S r S^r Sr和 S p S^p Sp是 E s E_s Es的输出。因此,高性能情况将主导优化过程,从而抑制另一种低性能情况。
(1)梯度方向均衡化:RG-Homogenize提出了一个梯度方向均衡化方案,其目的是直接学习旋转特征级别的梯度,以减轻缺失模式情况下的梯度方向冲突。它估计特定于实例的旋转矩阵来旋转特征级别的梯度,这些矩阵考虑了模式内实例级别的差异,更加灵活和可靠。
具体步骤:
旋转估计块(RotEblock):特征级别的梯度被输入到旋转估计块(RotEblock)中,以估计旋转矩阵 R r R_r Rr和 R p R_p Rp。这些矩阵用于减少梯度方向冲突,同时根据预测置信度计算的均衡权重 τ r \tau^{r} τr和 τ p \tau^{p} τp,用于平衡缺失模式情况下的梯度贡献。
-
估计实例特定的旋转矩阵:这一步骤旨在平滑地缩小特征级梯度方向之间的差距。不是直接改变参数级的梯度方向,而是估计特定于实例的旋转矩阵,以平滑地调整特征级梯度的方向。对于每个数据点,模型会尝试找到一个最佳的旋转矩阵,通过这个矩阵可以将梯度方向调整到一个更为一致和协调的状态。通过这种方式,即使在部分模态数据缺失的情况下,模型也能够更有效地学习,因为梯度方向的差异和冲突被有效缓和。这有助于提升模型对不完整数据的处理能力,减少负迁移的影响,从而提高学习效率和最终的性能。
-
生成动态同质化权重:是为了进一步解决多模态学习中的优化不平衡问题。这一步骤的关键在于如何在训练过程中平衡不同缺失模态梯度的贡献。动态同质化权重是根据模型在每个训练步骤中对不同模态数据的预测置信度动态生成的。这些权重用于调整每个模态梯度的影响力,确保在训练过程中不同模态之间保持一种动态的、平衡的关系。这些权重是基于模型对每个模态数据的预测置信度计算得出的。如果某个模态的预测置信度较高,那么这个模态在训练过程中的影响力也会相应增大;反之,则减小。这种方法可以确保模型不会过分依赖于任何一个单一模态,尤其是在部分模态数据缺失的情况下。
-
梯度方向均衡化的具体公式流程:
-
给定损失函数 L L L,可以将其参数级梯度 G G G 的表达式展开为: G = ∂ L ∂ θ = ∂ L ∂ S ∂ S ∂ θ G=\frac{\partial \mathcal{L}}{\partial \theta}=\frac{\partial \mathcal{L}}{\partial S} \frac{\partial S}{\partial \theta} G=∂θ∂L=∂S∂L∂θ∂S,其中 S S S 是输出特征, ∂ L ∂ S \frac{\partial \mathcal{L}}{\partial S} ∂S∂L 是特征级别梯度。定义一个旋转矩阵 R R R,通过矩阵乘法来旋转 ∂ L ∂ S \frac{\partial \mathcal{L}}{\partial S} ∂S∂L,这个过程会改变参数级梯度 ∂ L ∂ θ \frac{\partial \mathcal{L}}{\partial \theta} ∂θ∂L的方向,此外,上述过程还允许优化 R R R来控制 ∂ L ∂ S \frac{\partial \mathcal{L}}{\partial S} ∂S∂L的旋转,以消除梯度方向冲突。在所提出的框架中,给定缺失模态特征 S d S^d Sd,梯度方向去冲突过程可以写为: G d = ∂ L C E d ∂ S d R d ∂ S d ∂ θ s G^{d}=\frac{\partial \mathcal{L}_{C E}^{d}}{\partial S^{d}} \mathcal{R}^{d} \frac{\partial S^{d}}{\partial \theta_{s}} Gd=∂Sd∂LCEdRd∂θs∂Sd,其中 d ∈ { r , p } d \in\{r, p\} d∈{r,p}是缺失模态。
-
特征级别梯度之间存在明显的差距,因为它们依赖于不同的缺失模态特征。因此,旋转矩阵应该与相应的特征级梯度高度匹配。论文中构建了 RotEblock,它可以利用多个全局特征关系来估计特定于实例的旋转矩阵,与特定于任务的旋转矩阵相比,它更加有效和灵活。RotEblock 将缺失模态特征作为输入,并包含 C C C 个卷积头和一个 FC 层。给定输入 S d ∈ R C × L S^{d} \in \mathbb{R}^{C \times L} Sd∈RC×L,首先将其转置为 S d ∈ R C × L S^{d} \in \mathbb{R}^{C \times L} Sd∈RC×L,然后采用 C C C个卷积头来处理 S d S^d Sd,其中每个卷积头由两个1x1 1D卷积和一个转置层组成。第一个卷积将每个通道上的令牌信息相关联以建立令牌间关系。转置后,第二次卷积通过关联跨通道信息进一步建立通道间关系。至此,已经成功构建了 S d S^d Sd 的多个全局关系,其中每个 conv-head 产生一个特征 o c ∈ R C o_{c} \in \mathbb{R}^{C} oc∈RC: o c = Conv 2 ( Conv 1 ( S d ) T ) o_{c}=\operatorname{Conv}_{2}\left(\operatorname{Conv}_{1}\left(S^{d}\right)^{\mathrm{T}}\right) oc=Conv2(Conv1(Sd)T)。将它们连接起来以获得相关矩阵 O = [ o 1 , o 2 , … , o C ] ∈ R C × C O=\left[o_{1}, o_{2}, \ldots, o_{C}\right] \in \mathbb{R}^{C \times C} O=[o1,o2,…,oC]∈RC×C,由于这些转换头具有不同的参数, O O O中的每个元素都可以独立地描述 S d S^d Sd 的全局关系。最后,我们采用FC层将 O O O转换为旋转矩阵 R d \mathcal{R}^{d} Rd。
-
训练步骤:
-
第一步:使用旋转损失优化RotEblock来产生旋转矩阵。首先通过 RotEblock 估计旋转矩阵 R r \mathcal{R}^{r} Rr 和 R p \mathcal{R}^{p} Rp。然后,根据缺失模态 CE 损失 L C E r \mathcal{L}_{C E}^{r} LCEr 和 L C E p \mathcal{L}_{C E}^{p} LCEp 计算梯度 G r G_r Gr 和 G p G_p Gp,并使用 R r \mathcal{R}^{r} Rr 和 R r \mathcal{R}^{r} Rr 旋转特征级梯度 ∂ L C E r ∂ S r \frac{\partial \mathcal{L}_{C E}^{r}}{\partial S^{r}} ∂Sr∂LCEr 和 ∂ L C E p ∂ S p \frac{\partial \mathcal{L}_{C E}^{p}}{\partial S^{p}} ∂Sp∂LCEp 。为了平滑旋转梯度,定义目标梯度 V = G r + α G p V=G^{r}+\alpha G^{p} V=Gr+αGp,它是根据 G r G_r Gr和 G p G_p Gp动态生成的。这里,期望 V V V 和 G r G_r Gr 以及 V V V 和 G p G_p Gp 之间的角度一致。根据余弦相似度展开 V = G r + α G p V=G^{r}+\alpha G^{p} V=Gr+αGp, α \alpha α 推导为: ( G r + α G p ) ⋅ G r ∥ V ∥ ∥ G r ∥ = ( G r + α G p ) ⋅ G p ∥ V ∥ ∥ G p ∥ , α = ∥ G r ∥ ∥ G p ∥ \frac{\left(G^{r}+\alpha G^{p}\right) \cdot G^{r}}{\|V\|\left\|G^{r}\right\|}=\frac{\left(G^{r}+\alpha G^{p}\right) \cdot G^{p}}{\|V\|\left\|G^{p}\right\|}, \quad \alpha=\frac{\left\|G^{r}\right\|}{\left\|G^{p}\right\|} ∥V∥∥Gr∥(Gr+αGp)⋅Gr=∥V∥∥Gp∥(Gr+αGp)⋅Gp,α=∥Gp∥∥Gr∥
然后,定义旋转损失 L R O T \mathcal{L}_{R O T} LROT 来最大化 V V V 和 G d G^d Gd 之间的余弦相似度: L R O T = ∑ d ( 1 − cos ⟨ G d , V ⟩ ) + ∑ d ∥ ( R d ) T R d − I ∥ \mathcal{L}_{R O T}=\sum_{d}\left(1-\cos \left\langle G^{d}, V\right\rangle\right)+\sum_{d}\left\|\left(\mathcal{R}^{d}\right)^{\mathrm{T}} \mathcal{R}^{d}-\mathrm{I}\right\| LROT=∑d(1−cos⟨Gd,V⟩)+∑d (Rd)TRd−I
之后,引入两个约束来确保旋转矩阵的正交性。在 L R O T \mathcal{L}_{R O T} LROT 中添加正交正则化,通过最小化 ∑ d ∥ ( R d ) T R d − I ∥ \sum_{d}\left\|\left(\mathcal{R}^{d}\right)^{\mathrm{T}} \mathcal{R}^{d}-\mathrm{I}\right\| ∑d (Rd)TRd−I 来约束 ( R d ) T \left(\mathcal{R}^{d}\right)^{\mathrm{T}} (Rd)T 和 R d \mathcal{R}^{d} Rd 的乘积等于单位矩阵 I \text { I } I 。然后,进一步引入施密特正交化作为后处理的第二个约束,它可以确保 det ( R d ) = 1 \operatorname{det}\left(\mathcal{R}^{d}\right)=1 det(Rd)=1的严格正交旋转矩阵。
-
第二步:使用这些矩阵旋转特征级别的梯度,并应用交叉熵(CE)损失来优化编码器。将 S r S^r Sr 和 S p S^p Sp 重新输入 RotEblock 中,以估计更新后的旋转矩阵 R r \mathcal{R}^{r} Rr 和 R p \mathcal{R}^{p} Rp。将它们分别与特征级梯度 ∂ L C E r ∂ S r \frac{\partial \mathcal{L}_{C E}^{r}}{\partial S^{r}} ∂Sr∂LCEr 和 ∂ L C E p ∂ S p \frac{\partial \mathcal{L}_{C E}^{p}}{\partial S^{p}} ∂Sp∂LCEp 相乘,重新获得均匀化梯度 G r G^{r} Gr 和 G p G^{p} Gp 满足 0 < cos ⟨ G r , G p ⟩ ← 1 0<\cos \left\langle G^{r}, G^{p}\right\rangle \leftarrow 1 0<cos⟨Gr,Gp⟩←1,因此通过 G r G^{r} Gr 和 G p G^{p} Gp 优化编码器可以实现消除梯度方向冲突以提高癌症分级性能。
将 RG-Homogenize 中定义的上述子步骤总结为:(1): minimize θ Rot Eblock L R O T \underset{\theta_{\text {Rot Eblock }}}{\operatorname{minimize}} \mathcal{L}_{R O T} θRot Eblock minimizeLROT 和 (2): minimize θ r , θ p , θ s , w ∑ d L C E d \operatorname{minimize}_{\theta_{r}, \theta_{p}, \theta_{s}, w} \sum_{d} \mathcal{L}_{C E}^{d} minimizeθr,θp,θs,w∑dLCEd。
-
-
(2)Gradient Magnitude Homogenization
-
GMH的目的:GMH旨在解决不同缺失模态情况下表现不一致的问题,这可能导致训练过程中的优化不平衡。为此,GMH策略动态产生均衡化权重来平衡训练中梯度的贡献,这些权重根据相应的预测置信度来反映缺失模态的性能。
-
设计方法:RG-Homogenize中设计了一个基于置信度的调节机制来减轻梯度大小的冲突。通过计算置信度引导的均衡化权重,动态平衡梯度大小,从而同时减轻梯度方向和大小的冲突,避免了负面转移和优化失衡问题。
-
梯度大小均衡化策略:GMH策略使用一个偏移参数 β \beta β来控制梯度大小均衡化的程度。通过基于softmax的归一化 λ d \lambda^{d} λd,增强低性能情况的优化,同时抑制高性能情况的优化。根据该策略,每种缺失模态情况在训练中做出类似的贡献,从而可以解决梯度大小冲突问题。
-
梯度大小均衡化的具体公式流程:
-将 B t B_t Bt 定义为第 t t t 个训练步骤中的小批量,第 d d d 个缺失模态情况的预测置信度为:
λ m = 1 B t ∑ i ∈ B t 1 argmax ( P i d ) = y i k SD ( P i d ) , \lambda^{m}=\frac{1}{B_{t}} \sum_{i \in B_{t}} \mathbb{1}_{\underset{k}{\operatorname{argmax}\left(P_{i}^{d}\right)=y_{i}}} \operatorname{SD}\left(P_{i}^{d}\right), λm=Bt1∑i∈Bt1kargmax(Pid)=yiSD(Pid), 其中 P d = w ⋅ S d P^{d}=w \cdot S^{d} Pd=w⋅Sd是第 d d d个缺失模态情况的预测结果, S D ( ⋅ ) SD(·) SD(⋅)是标准差运算,表示每个样本的预测置信度。如果预测结果正确, S D SD SD 值越高表示结果越可信。
使用 λ d \lambda^{d} λd, d d d是模态,通过以下表达式动态调节训练中模态缺失情况的贡献。其中 β \beta β是控制梯度幅值均匀化程度的偏移参数, σ ( λ d ) = exp ( λ d ) exp ( λ r ) + exp ( λ p ) \sigma\left(\lambda^{d}\right)=\frac{\exp \left(\lambda^{d}\right)}{\exp \left(\lambda^{r}\right)+\exp \left(\lambda^{p}\right)} σ(λd)=exp(λr)+exp(λp)exp(λd)实现了对 λ d \lambda^{d} λd的基于softmax的归一化。
{ τ r = 1 − β ( σ ( λ r ) − σ ( λ p ) ) τ p = 1 − β ( σ ( λ p ) − σ ( λ r ) ) , \left\{\begin{array}{l} \tau^{r}=1-\beta\left(\sigma\left(\lambda^{r}\right)-\sigma\left(\lambda^{p}\right)\right) \\ \tau^{p}=1-\beta\left(\sigma\left(\lambda^{p}\right)-\sigma\left(\lambda^{r}\right)\right) \end{array},\right. {τr=1−β(σ(λr)−σ(λp))τp=1−β(σ(λp)−σ(λr)),
上述表达式可以通过提供较大的 τ d \tau^{d} τd来增强低性能情况的优化,同时抑制另一种高性能情况的优化。根据所提出的策略,每种缺失模态的情况在训练中都会做出类似的贡献,因此可以很好地缓解梯度幅度冲突。
(3)优化过程
在第 t t t 个训练步骤中,参数 θ = { θ r , θ p , θ s , w } \theta=\left\{\theta_{r}, \theta_{p}, \theta_{s}, w\right\} θ={θr,θp,θs,w}采用梯度下降优化:
θ t + 1 = θ t − η ( τ r G r + τ p G p ) \theta^{t+1}=\theta^{t}-\eta\left(\tau^{r} G^{r}+\tau^{p} G^{p}\right) θt+1=θt−η(τrGr+τpGp)
效果评估:通过消融研究,发现去除GDH和GMH方案会导致性能显著下降。增加GMH后,模型性能有所提升,而增加GDH则带来更大的性能改善,表明GDH比GMH对提升RG-Homogenize的贡献更大。

【数据集】
CPTAC-UCEC 数据集
CPTAC-PDA 数据集
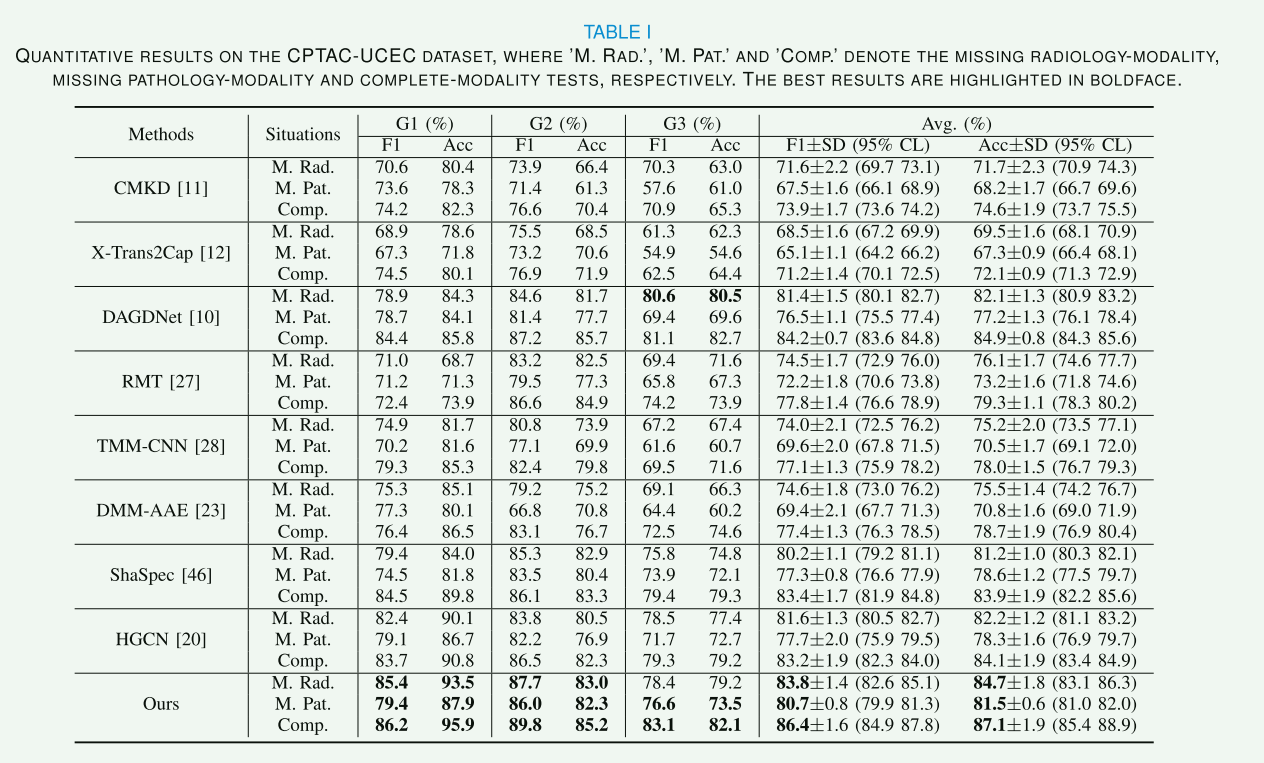
【性能】
【讨论】
A. Comparison with Upper and Lower Bounds
定义了单模态和多模态基线,单模态基线采用 Swin-T 作为主干,定义了在单一模态上训练并可以在其上进行测试的下限。多模态基线采用双编码器 Swin-T 作为主干,使用完整模态数据对其进行训练和测试以获得上限,MH-Complete 和 RG-Homogenize 均已从下限和上限中删除。
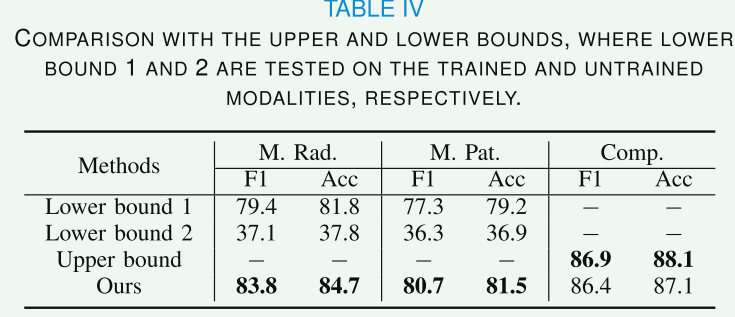
上述定量结果证明框架在缺少模式的真实医疗场景中是有效且稳健的。
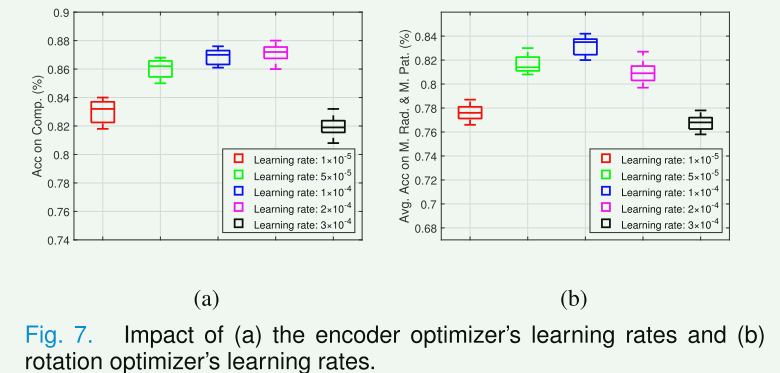
B. Analysis ofLearning Rates andTraining Costs
所提出的框架由 RotEblock 和编码器组成,它们在训练中交替优化。上述交替优化是一个非对称博弈,可以将RotEblock和编码器优化器分别视为领导者和跟随者,其中领导者和跟随者都会最小化相应的损失,但领导者知道跟随者对其移动的反应。
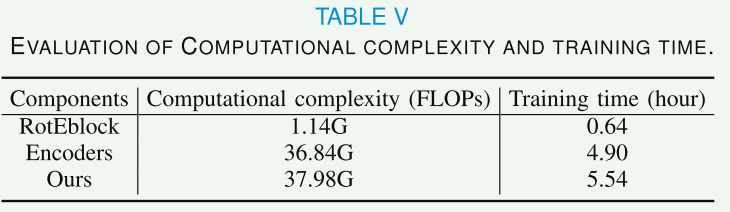
C. Analysis ofLoss Weights
λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2 分别控制 CMB 和 FMC 损失的贡献。最终选择损失权重 λ 1 = 0.5 \lambda_1 = 0.5 λ1=0.5 和 λ 2 = 0.1 \lambda_2= 0.1 λ2=0.1 以实现更好的癌症分级。
D. Analysis of Memory Items
MH-Complete 有两个关键的超参数:内存类别的数量和内存项的数量。前者取决于训练数据集,因此论文主要讨论后者对模型性能和复杂性的影响。合适的内存项可以有效平衡 MH-Complete 的性能和复杂度。论文通过实验将内存项 U U U的数量设置为512。
E. Analysis ofUnderlying Architectures
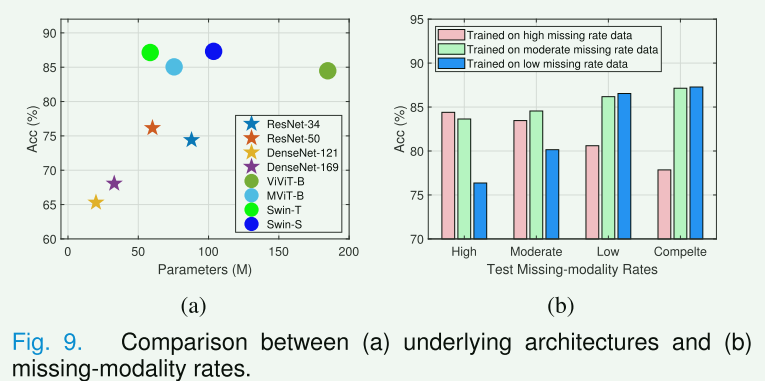
F. Analysis ofMissing-modality Rates
分析了不同缺失模态比例的训练和测试数据对模型性能的影响。定义了三种数据集:
- 高缺失率数据(完整/仅放射学/仅病理学数据比例为20%/40%/40%);
- 中等缺失率数据(40%/30%/30%);
- 低缺失率数据(80%/10%/10%)用于训练和测试。
在图9(b)中,报告了相应的测试结果。尽管框架在低缺失率数据上训练得到的模型在完整模态性能上表现出色,但它在高和中等缺失率的测试数据上表现不佳。此外,框架在中等和高缺失率数据上训练得到的模型在缺失模态性能上表现类似,但前者在完整模态测试数据上表现更好。上述实验表明,采用适当的不完整放射学-病理学数据进行训练,有效提高了所提出框架在现实世界多种缺失模态比例情况下的鲁棒性。
<一些思考>
1.memory learning方式memory Item的合适取值与记忆效率问题
2.旋转驱动的梯度均衡化方式,削弱了主导地位模态的贡献,增强了较弱或缺失模态,在诊断疾病某些模态实际就需要占主导地位的模态中,这种方式是否合理?均衡化是否会导致误判?














 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









