







文章目录
一、Lagrange函数与Lagrange对偶函数
1-Lagrange函数
Lagrange函数是微积分就了解的基础概念,简单复盘一下,考虑一个熟悉的优化问题,(不一定是一个凸优化问题)
min
f
0
(
x
)
s
.
t
.
f
i
(
x
)
≤
0
i
=
1...
m
h
i
(
x
)
=
0
i
=
1...
p
\min \quad f_0(x) \\ s.t. \quad f_i(x)\leq 0\quad i=1...m \\ \quad h_i(x) = 0 \quad i=1...p
minf0(x)s.t.fi(x)≤0i=1...mhi(x)=0i=1...p
这个优化问题的定义域为
x
∈
R
n
D
=
∩
i
=
0
m
d
o
m
f
i
∩
∩
i
=
1
p
d
o
m
h
i
x\in R^n\quad D=\cap_{i=0}^mdom f_i{\cap} \cap_{i=1}^pdom h_i
x∈RnD=∩i=0mdomfi∩∩i=1pdomhi,即所有限制条件与优化函数定义域的交集,假设目标函数最小的函数值为
p
∗
p^*
p∗,我们得到Lagrange函数
L
(
x
,
λ
,
ν
)
=
f
0
(
x
)
+
∑
i
=
1
m
λ
i
f
i
(
x
)
+
∑
i
=
1
p
ν
i
h
i
(
x
)
L(x,\lambda,\nu)=f_0(x)+\sum_{i=1}^m\lambda_if_i(x)+\sum_{i=1}^p\nu_ih_i(x)
L(x,λ,ν)=f0(x)+i=1∑mλifi(x)+i=1∑pνihi(x)
该函数是一个三变量的函数,其中
x
x
x是自变量和上面一样,
λ
\lambda
λ是一个
m
m
m维的向量,即不等式约束的维数,每个
λ
i
\lambda_i
λi称之为与不等式约束相关的拉格朗日乘子。而
ν
\nu
ν是一个
p
p
p维的向量,与等式约束的维数一样,
ν
i
\nu_i
νi称之为与等式约束相关的拉格朗日乘子。当然这些函数可能都是一些很一般的函数,我们只是对他们进行了线性的加权,并不能构造出很好的函数形式。
2-Lagrange对偶函数
对偶函数定义为如下形式:
g
(
λ
,
ν
)
=
inf
x
∈
D
L
(
x
,
λ
,
ν
)
g(\lambda,\nu)=\inf_{x\in D}L(x,\lambda,\nu)
g(λ,ν)=x∈DinfL(x,λ,ν)
即给定任意的
(
λ
,
ν
)
(\lambda,\nu)
(λ,ν),我们任意的选择
x
∈
D
x\in D
x∈D,使得拉格朗日函数的值取得最小。此时我们发现,该函数已经与
f
0
(
x
)
f_0(x)
f0(x)的凸性无关了,这变成了一个关于拉格朗日乘子
(
λ
,
ν
)
(\lambda,\nu)
(λ,ν)的函数。对偶函数有几个非常重要而且好用的性质:
- 拉格朗日对偶函数一定是凹函数,且其凹性与最优化函数和约束函数无关。证明放在appendix A中
- ∀ λ ≥ 0 , ∀ ν , g ( λ , ν ) ≤ p ∗ \forall \lambda\geq0,\forall \nu,g(\lambda,\nu)\leq p* ∀λ≥0,∀ν,g(λ,ν)≤p∗。即选择任意 λ ≥ 0 \lambda\geq0 λ≥0和 ν \nu ν, g g g的函数值不可能大于原优化问题的最优解,即构成了原问题最优值的下界?最优值下界的证明放在appendix B中。
二、三个实例理解对偶与其性质
1-线性约束得二次优化问题
首先来考虑一个具有线性约束的二次优化问题:
min
X
T
X
s
.
t
.
A
X
=
b
X
∈
R
n
b
∈
R
n
A
∈
R
p
∗
n
\min \quad X^TX \\ s.t. \quad AX=b\\ X\in R^n\quad b\in R^n\quad A\in R^{p*n}
minXTXs.t.AX=bX∈Rnb∈RnA∈Rp∗n
拉
格
朗
日
函
数
:
L
(
X
,
ν
)
=
X
T
X
+
ν
T
(
A
X
−
b
)
\mathbf{拉格朗日函数:L(X,\nu)=X^TX+\nu^T(AX-b)}
拉格朗日函数:L(X,ν)=XTX+νT(AX−b)
对
偶
函
数
:
g
(
ν
)
=
inf
X
∈
D
L
(
X
,
ν
)
=
inf
X
∈
D
X
T
X
+
ν
T
A
X
−
ν
T
b
\mathbf{对偶函数:g(\nu)=\inf_{X\in D}L(X,\nu)=\inf_{X\in D}X^TX+\nu^TAX-\nu^Tb}
对偶函数:g(ν)=X∈DinfL(X,ν)=X∈DinfXTX+νTAX−νTb
在这里面求最小值的话我们只需要对
X
X
X求个偏导,得到
2
X
+
A
T
ν
=
0
2X+A^T\nu=0
2X+ATν=0,那么
X
=
−
A
T
ν
2
X=-\frac{A^T\nu}{2}
X=−2ATν,将其带回,使得对偶函数完全变成一个
ν
\nu
ν的函数。
g
(
ν
)
=
ν
T
A
A
T
ν
4
−
ν
T
A
A
T
ν
2
−
ν
T
b
=
−
ν
T
A
A
T
ν
4
−
b
T
ν
\mathbf{g(\nu)=\frac{\nu^TAA^T\nu}{4}-\frac{\nu^TAA^T\nu}{2}-\nu^Tb=-\frac{\nu^TAA^T\nu}{4}-b^T\nu}
g(ν)=4νTAATν−2νTAATν−νTb=−4νTAATν−bTν
注意
b
,
ν
b,\nu
b,ν都是向量,所以内积总是常数,可以随便转置。也就是说我们将优化问题转化成了这个对偶函数,而该函数是一个凹函数,因为
−
A
A
T
-AA^T
−AAT一定是一个半负定的矩阵。
2-线性规划问题
考虑线性规划问题:
min
c
T
x
s
.
t
.
A
x
−
b
=
0
−
x
≤
0
\min \quad c^Tx \\ s.t. \quad Ax-b=0\\-x\leq 0
mincTxs.t.Ax−b=0−x≤0
注意不等式约束一定要写成
≤
0
\leq0
≤0的形式。
拉
格
朗
日
函
数
:
L
(
x
,
λ
,
ν
)
=
c
T
x
−
λ
T
x
+
ν
T
(
A
x
−
b
)
=
−
b
T
ν
+
(
c
+
A
T
−
λ
)
T
x
\mathbf{拉格朗日函数:L(x,\lambda,\nu)=c^Tx-\lambda^Tx+\nu^T(Ax-b)=-b^T\nu+(c+A^T-\lambda)^Tx}
拉格朗日函数:L(x,λ,ν)=cTx−λTx+νT(Ax−b)=−bTν+(c+AT−λ)Tx
对
偶
函
数
:
g
(
λ
,
ν
)
=
inf
x
∈
D
L
(
x
,
λ
,
ν
)
\mathbf{对偶函数:g(\lambda,\nu)=\inf_{x\in D}L(x,\lambda,\nu)}
对偶函数:g(λ,ν)=x∈DinfL(x,λ,ν)
当
−
b
T
ν
+
(
c
+
A
T
−
λ
)
T
x
-b^T\nu+(c+A^T-\lambda)^Tx
−bTν+(c+AT−λ)Tx一次项的系数等于0的时候,这个函数的最小值是
−
b
T
x
-b^Tx
−bTx,否则我们总能使得这个函数的值取得
−
∞
-\infty
−∞,因为在对偶函数里我们已经将原约束优化问题转化成了单独的一个函数,
x
x
x是
R
n
R^n
Rn上随便取得。因此对偶函数实际上是一个分段函数
−
b
T
ν
,
A
T
−
λ
+
c
=
0
−
∞
,
o
t
h
e
r
w
i
s
e
\color{blue}-b^T\nu,\quad A^T-\lambda+c=0\\ -\infty,\quad\quad otherwise
−bTν,AT−λ+c=0−∞,otherwise
A
T
−
λ
+
c
=
0
A^T-\lambda+c=0
AT−λ+c=0显然是一个超平面,而这整个函数可以看作
,
A
T
−
λ
+
c
=
0
,\quad A^T-\lambda+c=0
,AT−λ+c=0对应函数在全空间上的凹扩展,在这个超平面上取值固定,既凸又凹,因此总体是凹函数。
3-非凸函数,非凸限制
最后我们来看一个非凸函数,非凸限制得优化问题
min
x
T
W
x
s
.
t
.
x
i
2
−
1
=
0
,
i
=
1...
m
\min \quad x^TWx \\ s.t. \quad x_i^2-1=0,\quad i=1...m
minxTWxs.t.xi2−1=0,i=1...m
拉
格
朗
日
函
数
:
L
(
x
,
λ
,
ν
)
=
x
T
W
x
+
∑
i
=
1
n
ν
i
(
x
i
2
−
1
)
\mathbf{拉格朗日函数:L(x,\lambda,\nu)=x^TWx+\sum_{i=1}^n\nu_i(x_i^2-1)}
拉格朗日函数:L(x,λ,ν)=xTWx+i=1∑nνi(xi2−1)
将这个函数进行一步转化得到:
L
(
x
,
λ
,
ν
)
=
x
T
(
W
+
D
i
a
g
(
ν
)
)
x
−
1
T
ν
\color{red}L(x,\lambda,\nu)=x^T(W+Diag(\nu))x-1^T\nu
L(x,λ,ν)=xT(W+Diag(ν))x−1Tν
对
偶
函
数
:
g
(
λ
,
ν
)
=
inf
x
∈
D
x
T
(
W
+
D
i
a
g
(
ν
)
)
x
−
1
T
ν
\mathbf{对偶函数:g(\lambda,\nu)=\inf_{x\in D}x^T(W+Diag(\nu))x-1^T\nu}
对偶函数:g(λ,ν)=x∈DinfxT(W+Diag(ν))x−1Tν
那么我们对这个对偶函数进行一波分析,当该二次型得系数矩阵半正定时,这个函数能取到得最小值一定是
1
T
ν
1^T\nu
1Tν,否则,前一项一定可以使得这个函数得最小值取到
−
i
n
f
-inf
−inf。也就是说,这个函数是一个分段函数
−
1
T
ν
,
W
+
D
i
a
g
(
ν
)
⪰
0
−
∞
,
o
t
h
e
r
w
i
s
e
\color{blue}-1^T\nu,\quad W+Diag(\nu)\succeq0\\ -\infty,\quad\quad otherwise
−1Tν,W+Diag(ν)⪰0−∞,otherwise
那么我们只需要证明
W
+
D
i
a
g
(
ν
)
W+Diag(\nu)
W+Diag(ν)是一个凸集即可。这个利用
f
(
θ
ν
1
)
+
(
1
−
θ
)
f
(
ν
2
)
≤
θ
f
(
ν
1
)
+
(
1
−
θ
)
f
ν
2
)
f(\theta \nu_1)+(1-\theta)f(\nu_2)\leq \theta f(\nu_1)+(1-\theta)f\nu_2)
f(θν1)+(1−θ)f(ν2)≤θf(ν1)+(1−θ)fν2)即可证明。
三、对偶函数与共轭函数的联系
1-共轭函数
共轭函数在凸优化中有着非常重要的作用,是理解对偶的必不可少的元素。在书中,它被定义为
f
∗
(
y
)
=
sup
x
∈
d
o
m
f
(
y
T
x
−
f
(
x
)
)
f^*(y)=\sup_{x\in dom f}(y^Tx-f(x))
f∗(y)=x∈domfsup(yTx−f(x))
其中,
f
:
R
n
→
R
,
f
∗
:
R
n
→
R
f:R^n\rightarrow R,f^*:R^n\rightarrow R
f:Rn→R,f∗:Rn→R,
f
∗
f^*
f∗称为
f
f
f的共轭函数。也就是说,共轭函数是线性函数
y
T
x
y^Tx
yTx与原始函数
f
(
x
)
f(x)
f(x)的最大gap.
2-二者的联系
二者的去别主要在于
i
n
f
,
s
u
p
inf,sup
inf,sup这两个操作上,我们知道
i
n
f
f
(
x
)
=
−
s
u
p
−
f
(
x
)
inf f(x)=-sup -f(x)
inff(x)=−sup−f(x),因此举几个常规的例子来看一看写出来的共轭函数和对偶函数区别到底在哪里。最简单的:
min
f
(
x
)
s
.
t
.
x
=
0
\min f(x)\\ s.t.\quad x=0
minf(x)s.t.x=0
写出他的对偶函数
inf
(
x
)
+
v
T
x
;
d
o
m
L
∈
d
o
m
f
×
R
n
\inf(x)+v^Tx;dom L\in dom f×R^n
inf(x)+vTx;domL∈domf×Rn
他等价于 − sup ( − v T x − f ( x ) ) -\sup(-v^Tx -f(x)) −sup(−vTx−f(x))这就变成共轭函数的形式即 − f ∗ ( − v ) \mathbf{-f^*(-v)} −f∗(−v)( x x x并不是变量 v v v才是),其实对于任意一个函数的对偶函数,我们通过如上形式都可以将它变为以拉格朗日乘子为变量的共轭函数,
四、对偶问题与原问题
1-概念,定义以及重要性质
有了上述的对偶函数,我们知道对偶函数的最优解是原问题的最优值下界,那么我们就能得到两个定义:对偶问题(D:dual)与原问题(P:primary)
(
D
)
max
g
(
λ
,
ν
)
s
.
t
.
λ
⪰
0
(D) \max \quad g(\lambda,\nu)\\s.t.\quad \color{red}\lambda\succeq0
(D)maxg(λ,ν)s.t.λ⪰0
注意如果原问题有不等式约束,那么对偶问题种一定有
λ
⪰
0
\lambda\succeq 0
λ⪰0的约束条件。他的最优值记为
d
∗
d^*
d∗,原问题记为
(
P
)
min
f
0
(
x
)
s
.
t
.
f
i
(
x
)
≤
0
i
=
1
,
.
.
.
,
m
b
i
(
x
)
=
0
i
=
1
,
.
.
.
,
p
(P)\min f_0(x)\\s.t.\quad f_i(x)\leq0\quad i=1,...,m\\ b_i(x)=0\quad i=1,...,p
(P)minf0(x)s.t.fi(x)≤0i=1,...,mbi(x)=0i=1,...,p
原问题的最优解为
p
∗
p^*
p∗,根据最优值下界我们有
d
∗
≤
p
∗
d^*\leq p^*
d∗≤p∗
我们关注两个问题:
- 这个最优值下界好像没有什么意义,比如说我说你最少活2年,这显然是没有意义的,一定要给一个确界才比较好,比如能活100年。这表现在对偶问题中就是 p ∗ = d ∗ p^*=d^* p∗=d∗,如何能达到这一点是我们需要考虑的
- 我们知道对偶问题一定是一个凸问题,但是对偶问题的对偶问题不一定是原问题(同共轭函数的性质),非凸问题的对偶问题的对偶问题依然不会是非凸的,那么是么时候我们可以使得某个问题的对偶问题的对偶是它自身,这是第二个需要考虑的问题。
2-强对偶与弱对偶
- 我们定义对偶间隙为原问题的最优解与对偶问题的最优解的差 p ∗ − d ∗ p^*-d^* p∗−d∗(因为 d ∗ d^* d∗是最优值下界,此值一定不小于0)
- 强对偶:如果等式 d ∗ = p ∗ d^*=p^* d∗=p∗,即对偶间隙等于0,那么强对偶性成立。
- 弱对偶:对偶问题一般都具有的性质,只要满足 d ∗ < p ∗ d^*<p^* d∗<p∗即可。
3-强对偶性何时成立以及slate充分条件
相对内部(Relative
interior)
\textbf{\color{blue}{相对内部(Relative interior)}}
相对内部(Relative interior)
首先我们需要给出集合
D
D
D的相对内部(Relative interior),记作
r
e
l
i
n
t
D
\mathbf{relint} \;D
relintD,他定义如下:
r
e
l
i
n
t
D
=
{
x
∈
D
∣
B
(
x
,
r
)
∩
a
f
f
D
∈
D
,
∃
r
>
0
}
\mathbf{relint} \;D=\{x\in D|B(x,r)\cap\mathbf{aff} D\in D,\exist r>0\}
relintD={x∈D∣B(x,r)∩affD∈D,∃r>0}
这个概念其实很简单,我们分为三部分来理解它
- 首先 x ∈ D x\in D x∈D,表示了所有元素都在 D D D内部。
-
B
(
x
,
r
)
∩
a
f
f
D
∈
D
B(x,r)\cap\mathbf{aff} D\in D
B(x,r)∩affD∈D表示以
x
x
x为中心,我们能找到一个半径为
r
r
r的圆,他和
D
D
D的仿射包的交集依然在
D
D
D的内部。

可以看到上面,只有在边界上的时候,我们任取一个 x x x,找不到半径使得仿射集和圆的交集在 D D D内,其实相对内部的定义即去掉该集合的边界。
slate条件
\textbf{\color{blue}{slate条件}}
slate条件
slate条件回答了什么时候我们可以得到
p
∗
=
d
∗
p^*=d^*
p∗=d∗,这是一个充分条件,不满足时对偶问题的最优解也可能是一个下确界,它的定义如下:
对于一般问题,强对偶性不成立。但是如果当原问题是凸问题,即写为:
min
f
0
(
x
)
s
.
t
.
f
i
(
x
)
≤
0
i
=
1...
m
A
x
=
b
,
\min \quad f_0(x) \\ s.t. \quad f_i(x)\leq 0\quad i=1...m \\ Ax=b,
minf0(x)s.t.fi(x)≤0i=1...mAx=b,
其中
f
i
(
x
)
f_i(x)
fi(x)是凸函数,此时强对偶性通常(但不总是)成立的(即原问题是凸问题,它的对偶问题一般都具有强对偶性)。 必要的时候我们可以使用强对偶性成立的充分条件进行判断:
存在一点
x
∈
r
e
l
i
n
t
D
x\in \mathbf{relint}D
x∈relintD使得下列等式成立:
f
i
(
x
)
<
0
,
i
=
1
,
.
.
.
,
m
A
x
=
b
f_i(x)<0,i=1,...,m\quad\quad Ax=b
fi(x)<0,i=1,...,mAx=b
即不仅满足等式约束,而且所有的不等式约束都小于0,去掉了等于0的情况。但是这时候我们要找到这样一个
x
x
x来验证是非常难的,因此我们有了更弱一点的slate条件。
弱slate条件
\textbf{\color{blue}{弱slate条件}}
弱slate条件
如果原问题是一个凸问题,而且不等式约束全部为仿射约束时,只要可行域非空,必有
p
∗
=
d
∗
p^*=d^*
p∗=d∗。当不等式约束中存在仿射不等式时,这些仿射不等式不需要严格成立(即他们不需要<0,
≤
0
\leq0
≤0即可),只要我们能找到一个
x
∈
r
e
l
i
n
t
D
x\in\mathbf{relint}D
x∈relintD使得所有非仿射不等式严格成立,这个条件依然是可行的。
Appendix A:证明:对偶函数一定是凹函数,且其凹性与最优化函数和约束函数无关
如果了解保凸运算,那么我们知道函数的逐点上确界一定是一个凸函数,给定下列函数
L
(
λ
,
ν
)
=
sup
x
∈
D
f
0
(
x
)
+
∑
i
=
1
m
λ
i
f
i
(
x
)
+
∑
i
=
1
p
ν
i
h
i
(
x
)
L(\lambda,\nu)=\sup_{x\in D}f_0(x)+\sum_{i=1}^m\lambda_if_i(x)+\sum_{i=1}^p\nu_ih_i(x)
L(λ,ν)=x∈Dsupf0(x)+i=1∑mλifi(x)+i=1∑pνihi(x)
即对每个
(
λ
,
ν
)
(\lambda,\nu)
(λ,ν)我们求一个
x
x
x使得函数值最大,这样的函数叫做逐点上确界。而我们现在的函数,是关于
(
λ
,
ν
)
(\lambda,\nu)
(λ,ν)的线性函数,线性函数也是凸函数,那如果是求最小呢,就变成了仿射函数的下确界问题,是一个凹函数。我们给出详细的推导过程:
参考自:https://blog.csdn.net/u014540876/article/details/79153913
要证对偶函数一定是凹函数,根据凹函数的定义,就是要证
g
(
θ
λ
1
+
(
1
−
θ
)
λ
2
,
θ
ν
1
+
(
1
−
θ
)
ν
2
)
≥
θ
g
(
λ
1
,
ν
1
)
+
(
1
−
θ
)
g
(
λ
2
,
ν
2
)
θ
∈
R
g(\theta\lambda_1+(1-\theta)\lambda_2,\theta\nu_1+(1-\theta)\nu_2)\geq \theta g(\lambda_1,\nu_1)+(1-\theta)g(\lambda_2,\nu_2)\quad \theta\in R
g(θλ1+(1−θ)λ2,θν1+(1−θ)ν2)≥θg(λ1,ν1)+(1−θ)g(λ2,ν2)θ∈R
根据对偶函数的定义可知,对偶函数是拉格朗日函数在把
λ
\lambda
λ和
ν
\nu
ν当做常量,
x
x
x变化时的最小值,如果拉格朗日函数没有最小值(可以认为最小值为
−
∞
-\infty
−∞),则对偶函数取值为
−
∞
-\infty
−∞,所以,可以把对偶函数按照下面的方式表达:

即无穷多个x变化时,拉格朗日函数的最小值。另外,由于把λ和ν分开来写,式子太长了,为了简便,记
γ
=
(
λ
,
ν
)
\gamma = (\lambda, \nu)
γ=(λ,ν),那么我们有
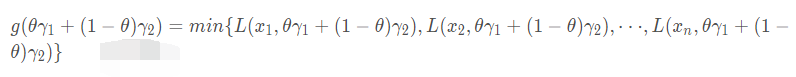
我们关注一下
L
L
L这个函数,他是一个关于
λ
,
ν
\lambda,\nu
λ,ν的线性函数,因此既是凸的也是凹的,利用凸性我们可以得到
L
(
x
,
θ
γ
1
+
(
1
−
t
h
e
t
a
)
γ
2
)
≥
θ
L
(
x
,
γ
1
)
+
(
1
−
θ
)
L
(
x
,
γ
2
)
L(x,\theta\gamma_1+(1-theta)\gamma_2)\geq \theta L(x,\gamma_1)+(1-\theta)L(x,\gamma_2)
L(x,θγ1+(1−theta)γ2)≥θL(x,γ1)+(1−θ)L(x,γ2),因此我们可以得到上式大于等于:

对min函数,我们有一个基本不等式
min
i
=
1
n
(
a
+
b
)
≥
min
i
=
1
n
(
a
)
+
min
i
=
1
n
(
b
)
\min_{i=1}^n(a+b)\geq \min_{i=1}^n(a)+\min_{i=1}^n(b)
mini=1n(a+b)≥mini=1n(a)+mini=1n(b),其中
a
=
{
a
1
,
.
.
.
a
n
}
,
b
=
{
b
1
,
.
.
.
,
b
n
}
a=\{a_1,...a_n\},b=\{b_1,...,b_n\}
a={a1,...an},b={b1,...,bn}都是向量。那么我们进一步化简上式得到:

所以原命题得证。
Appendix B:证明:对偶函数为最优值下界
我们之前假设的
p
∗
p*
p∗为原优化问题的最优解,也即全局最小,设此时自变量值为
x
∗
x^*
x∗。那么对于任意的
λ
≥
0
\lambda\geq0
λ≥0和
ν
\nu
ν,我们有
L
(
x
∗
,
λ
,
ν
)
=
f
0
(
x
∗
)
+
∑
i
=
1
m
λ
i
f
i
(
x
)
+
∑
i
=
1
p
ν
i
h
i
(
x
)
≤
p
∗
L(x^*,\lambda,\nu)=f_0(x^*)+\sum_{i=1}^m\lambda_if_i(x)+\sum_{i=1}^p\nu_ih_i(x)\leq p^*
L(x∗,λ,ν)=f0(x∗)+i=1∑mλifi(x)+i=1∑pνihi(x)≤p∗
原因很简单,因为
f
i
(
x
)
f_i(x)
fi(x)都是不等式约束,而我们的不等式约束都要小于0,而等式约束都等于0,即
∑
i
=
1
m
λ
i
f
i
(
x
)
+
∑
i
=
1
p
ν
i
h
i
(
x
)
≤
0
\sum_{i=1}^m\lambda_if_i(x)+\sum_{i=1}^p\nu_ih_i(x)\leq 0
∑i=1mλifi(x)+∑i=1pνihi(x)≤0,那么也就是给
f
0
(
x
∗
)
f_0(x^*)
f0(x∗)加上了一个非正项。而我们的对偶函数,
g
(
λ
,
ν
)
=
inf
x
∈
D
L
(
x
,
λ
,
ν
)
g(\lambda,\nu)=\inf_{x\in D}L(x,\lambda,\nu)
g(λ,ν)=x∈DinfL(x,λ,ν)
因为
x
∗
x^*
x∗总是在定义域里的,所以最小化这个值等价于最小化
L
(
x
∗
,
λ
,
ν
)
=
f
0
(
x
∗
)
+
∑
i
=
1
m
λ
i
f
i
(
x
)
+
∑
i
=
1
p
ν
i
h
i
(
x
)
≤
p
∗
L(x^*,\lambda,\nu)=f_0(x^*)+\sum_{i=1}^m\lambda_if_i(x)+\sum_{i=1}^p\nu_ih_i(x)\leq p^*
L(x∗,λ,ν)=f0(x∗)+∑i=1mλifi(x)+∑i=1pνihi(x)≤p∗。得证
拿两个书上的图加深理解

















 3880
3880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









