






点击下方卡片,关注“具身智能之心”公众号
作者 | 具身智能之心 编辑 | 具身智能之心
本文只做学术分享,如有侵权,联系删文

写在前面
想象一下,如果一种技术能利用大型语言模型(LLMs)的推理能力,为机器人生成准确的抓取位姿,是不是很酷?
最近,罗格斯大学与百度研究院的团队就实现了这一目标!
在此之前,许多研究已探索了机器人抓取与语言模型结合的可能性:
在机器人抓取领域,传统方法依赖于几何分析或接触力优化,但在处理未知或形状复杂的物体时表现有限。数据驱动方法(如基于卷积神经网络的模型)虽然更具灵活性,但容易过拟合,且缺乏对物体属性(如材质或用途)的深入推理能力。
在语言与机器人操作结合方面,早期研究探索了基于语言描述的抓取检测与操作任务分解。但这些方法大多依赖大量示例或基础动作库,效率与灵活性受限。
我们通过Reasoning Tuning(推理调优)方法,创新性地将LLMs的推理能力与机器人抓取任务结合,提出了一个全新流程:在预测前先进行推理阶段,以挖掘LLMs丰富的先验知识和多模态推理能力。不仅让LLMs能生成上下文感知、可调的数值预测(如抓取位姿),还通过Reasoning Tuning VLM Grasp 数据集进一步优化模型性能。
实验表明,这种方法在数据集和真实抓取场景中表现优异,不仅拓宽了LLMs在机器人领域的应用范围,还有效填补了文本规划与机器人直接控制间的鸿沟,为未来机器人操作的智能化发展提供了新思路!
内容出自国内首个具身智能全栈学习社区:具身智能之心知识星球,这里包含所有你想要的。
论文标题:RT-Grasp: Reasoning Tuning Robotic Grasping via Multi-modal Large Language Model
论文链接:https://arxiv.org/pdf/2411.05212
项目链接:https://sites.google.com/view/rt-grasp
作者单位:罗格斯大学 百度研究院
工作的创新和贡献
提出了一种名为推理调优(Reasoning Tuning)的新方法,利用预训练多模态 LLMs 的内在先验知识,推动其适配于需要数值预测的任务。
发布了Reasoning Tuning VLM Grasp数据集,专为多模态 LLMs 在机器人抓取任务中的微调而设计。
通过两种计算高效的训练策略对所提出的方法在机器人抓取任务中的表现进行了实证验证,并在真实硬件环境中开展了实验。实验结果表明,该方法不仅有效,而且能够根据用户指令优化抓取预测。
RT-Grasp方法设计详解
近年来,人工智能的发展得益于大语言模型(LLMs)的兴起,这些模型凭借其丰富的知识储备和先进的推理能力,彻底改变了我们处理各种任务(尤其是语言处理任务)的方式。在机器人领域,LLMs 在促进机器人与人类的直接交互方面发挥了关键作用。例如,在机器人操作规划任务中,许多研究利用 LLMs 解析用户的自然语言指令,并将其转化为可行的多步操作规划。然而,尽管 LLMs 在机器人领域具有巨大潜力,其应用仍主要局限于此类规划任务。一个显著的瓶颈在于 LLM 输出的文本特性,这种特性对需要精确数值输出的任务往往带来挑战。
近年来,多模态大语言模型(LLMs)通过理解文本和图像,进一步扩展了 LLM 的能力。在机器人领域,这些模型弥合了感知与规划之间的鸿沟,解决了多种具身推理任务。然而,其图像理解能力仍然存在精确性不足的问题,例如,它们虽然能够提供一般性描述,但往往难以准确确定物体位置。尽管如 GPT-4 with vision 等模型在物体检测任务中展现出潜力,但在需要进行独特数值预测(例如机器人抓取中的抓取姿态)时仍然面临困难(见图 1)。此外,多模态 LLMs 在机器人应用中的另一个显著挑战是其文本输出的不稳定性和冗长性,这使其在需要精确操控的任务中缺乏可靠性。尽管某些机器人任务可以从多模态 LLMs 的集成中受益,其直接数值预测能力仍然鲜有深入研究。
我们探讨了多模态大语言模型(LLMs)在数值预测任务中的潜在应用,重点关注机器人抓取领域。机器人抓取被认为是机器人学中一项基础但极具挑战性的任务,其核心在于生成精确的抓取姿态,这对后续的机器人操作至关重要。
传统的机器人抓取方法通常依赖于确定性预测,但由于缺乏推理能力,这些方法在实际场景中往往表现不佳。大多数现有方法基于 CNN 架构,尽管在基准数据集上的实验精度表现优异,却在实际应用中面临诸多挑战。例如,这些传统模型可能生成理论上正确但在执行中不可行的预测,如图 1 所示的无效抓取。这类预测由于机械臂的夹爪限制差异,难以在不同机器人间通用。此外,一些理论上正确的抓取可能导致不安全行为,例如抓取过程中夹持螺丝刀的锋利末端。
因此,采用具有推理能力的非确定性方法至关重要。这种能力不仅使模型能够生成适用于多种场景的实际抓取姿态,还能够根据用户指令优化预测结果。由此提出一个问题:LLMs 所具备的推理能力是否可以用于机器人领域的数值预测任务?我们对此给出了肯定的回答,展示了多模态 LLMs 在机器人抓取任务中的适应性与应用潜力。
为了高效利用多模态 LLMs 的推理能力进行数值预测,我们提出了一种新颖的方法,称为推理调优(Reasoning Tuning)。该方法在训练过程中引入了一个关键的推理阶段,置于数值预测步骤之前。推理阶段的主要目标是引导模型基于逻辑推理原则进行预测。例如,模型首先通过推理确定物体的类型、形状、位置以及基本的抓取原则,随后再从这一推理结果中得出数值预测。该推理阶段旨在解锁多模态 LLMs 中蕴含的宝贵信息,充分利用其对一般物体属性的广泛知识。通过实验证明,在引入推理阶段的基础上微调多模态 LLMs,能够显著提升其在机器人抓取任务中生成数值预测的效果。
我们研究了两种经济高效的训练策略来实现所提出的推理调优(Reasoning Tuning):预训练和LoRA微调。研究这些策略的目的是提供一种更为资源高效的方法,将多模态 LLMs 的能力迁移到下游的机器人任务中。
这里的工作重点在于将多模态 LLMs 适配于数值预测任务,特别是在机器人抓取领域。与传统的确定性方法相比,本文的方法不仅融入了先进的推理能力,还提出了一种全新的预测优化范式,如图 1 所示。
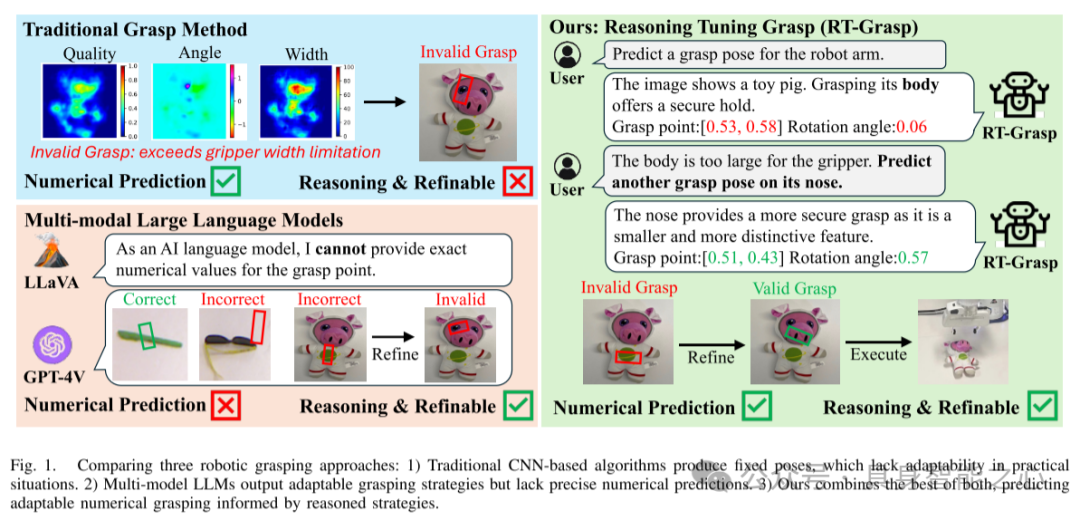
图 1. 三种机器人抓取方法的对比:
传统的基于 CNN 的算法:生成固定的抓取姿态,但在实际应用中缺乏适应性。
多模态 LLMs:输出适应性强的抓取策略,但缺乏精确的数值预测能力。
我们的方法:结合两者的优势,基于推理策略生成既适应性强又精确的数值抓取预测。
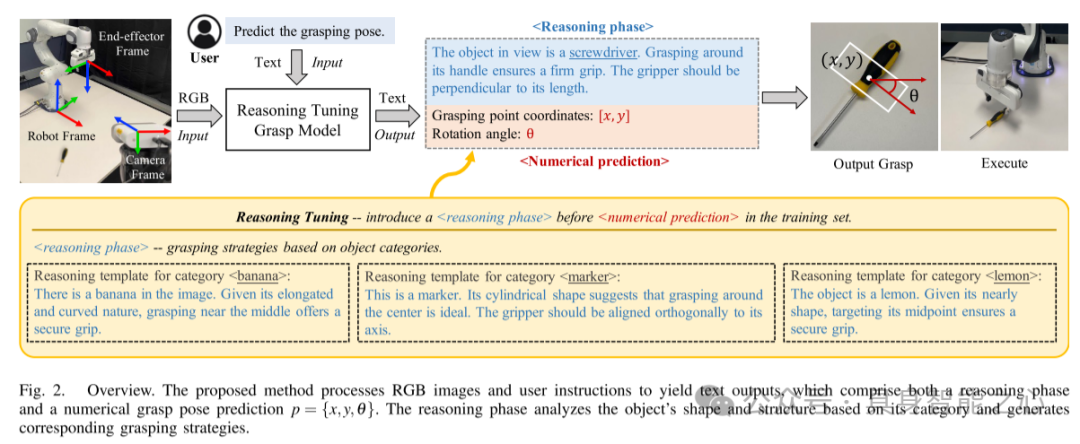
图 2. 方法概览所提出的方法通过处理 RGB 图像和用户指令,生成包含推理阶段和数值抓取姿态预测 的文本输出。推理阶段基于物体的类别分析其形状和结构,并生成相应的抓取策略。

图 3. Reasoning Tuning VLM Grasp 数据集样本示例数据样本的结构化文本答案包含推理阶段以及抓取姿态的真实值。

图 4. Reasoning Tuning VLM 数据集中的推理模板示例
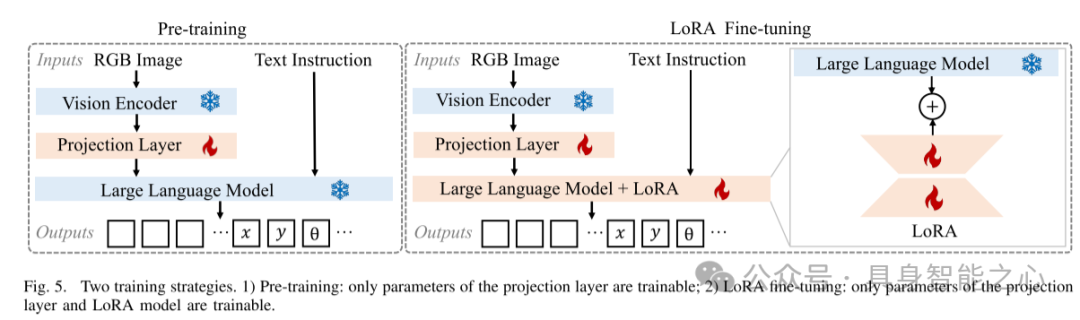
图 5. 两种训练策略
预训练:仅投影层的参数可训练;
LoRA 微调:仅投影层和 LoRA 模型的参数可训练。
实验验证:

图 6. 消融研究中的两种变体示意图
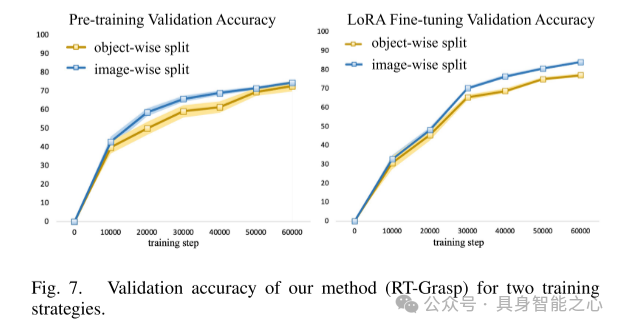
图 7. 本文方法(RT-Grasp)在两种训练策略下的验证精度

图 8. 用于真实抓取实验的家庭测试物体
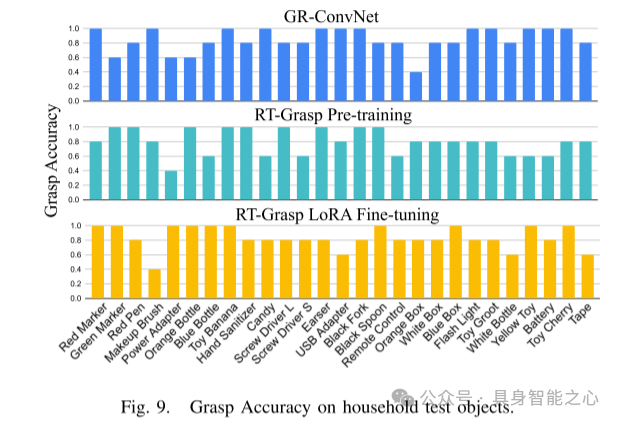
图 9. 家庭测试物体的抓取精度

图 10. 推理与交互式优化RT-Grasp 的输出包括推理阶段(蓝色部分)和数值抓取姿态。初始预测的抓取用红色标示,经过优化后的抓取用绿色标示。
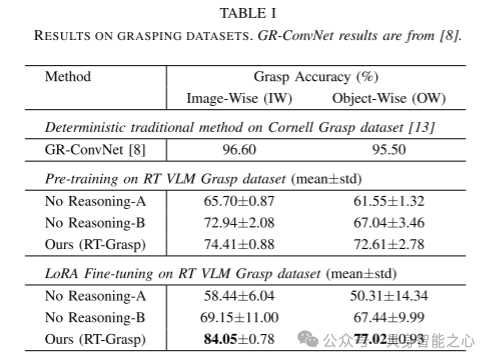
表 I 抓取数据集的实验结果GR-ConvNet 的结果引自文献。
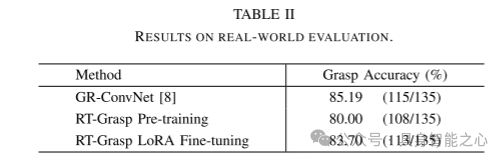
表 II 真实场景评估结果
最后,总结下
我们的研究突显了大语言模型(LLMs)在传统以文本为中心的应用之外的潜力。提出的方法充分利用了 LLMs 的丰富先验知识,用于数值预测,特别是在机器人抓取领域。通过在基准数据集和真实场景中的全面实验,验证了该方法的有效性。未来工作中,计划将方法的验证范围扩展到包含更多种类物体的抓取数据集,例如 Jacquard 数据集。此外,将多模态 LLMs 的数值预测能力适配于其他机器人操作任务也是一个值得探索的研究方向。
引用:
@misc{xu2024rtgraspreasoningtuningrobotic,
title={RT-Grasp: Reasoning Tuning Robotic Grasping via Multi-modal Large Language Model},
author={Jinxuan Xu and Shiyu Jin and Yutian Lei and Yuqian Zhang and Liangjun Zhang},
year={2024},
eprint={2411.05212},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2411.05212},
}“具身智能之心”公众号持续推送具身智能领域热点:
【具身智能之心】技术交流群
具身智能之心是首个面向具身智能领域的开发者社区,聚焦大模型、视觉语言导航、机械臂、双足机器人、四足机器人、感知融合、强化学习、模仿学习、规控与端到端、机器人仿真、产品开发、自动标注等多个方向,目前近60+技术交流群,欢迎加入!扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

【具身智能之心】知识星球
具身智能之心知识星球是国内首个具身智能开发者社区,近600人的社区。主要关注具身智能相关的数据集、开源项目、具身仿真平台、大模型、视觉语言模型、强化学习、具身智能感知定位、机器臂抓取、姿态估计、策略学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。扫码加入星球,享受以下专有服务:
1. 第一时间掌握具身智能相关的学术进展、工业落地应用;
2. 和行业大佬一起交流工作与求职相关的问题;
3. 优良的学习交流环境,能结识更多同行业的伙伴;
4. 具身智能相关工作岗位推荐,第一时间对接企业;
5. 行业机会挖掘,投资与项目对接;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









