






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天自动驾驶之心为大家分享港中文&上海人工实验室的最新工作—GPT4Scene!利用视觉语言模型从视频中理解3D场景!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
论文作者 | Zhangyang Qi
编辑 | 自动驾驶之心
写在前面&笔者的个人理解
具身人工智能是指能够通过与物理环境交互来执行各种任务的智能系统。它在工业检测、智能家居和智能城市中有着广泛的应用和发展前景。3D 场景理解涉及多模态语言模型理解室内环境整体布局和物体之间空间关系的能力。因此,具身智能的坚实基础在于能否有效地理解场景内容。
目前,基于3D点云大语言模型是一种流行的理解室内场景的方法,使用点云数据作为输入,并将点云数据特征与LLM对齐以执行场景理解任务。然而,这种方法有以下几个方面的局限性。
点云提供的详细信息有限,例如精细的几何细节、材料特性和复杂的纹理
尽管一些点云大语言模型尝试使用点云和多幅图像作为输入,但它们在对齐文本、图像和点云模态方面面临挑战
点云数据与文本/视频数据的数据量明显不平衡,这也带来了进一步的复杂性
这些限制促使我们探索使用纯视觉输入的室内场景理解。这种方法更符合人类的感知模式,因为人们可以在不依赖点云等显式 3D 数据信息的情况下理解 3D 场景。视觉语言模型 (VLM) 在图像文本多模态任务中表现出色。然而,它们在理解沉浸式 3D 室内场景中的应用尚未得到很好的探索和开发。我们进行了一项初步研究,通过将场景视频直接输入到VLM模型中来调查这种潜力。我们的实验结果表明,这种方法导致VLM无法理解 3D 场景。我们认为其核心问题在于缺乏全局场景信息,以及每帧的局部位置与整体背景的不一致。
针对上述提到的相关问题,我们提出了一个名为GPT4Scene 的框架来帮助 VLM 建立空间关系,其整体结构如下图所示。
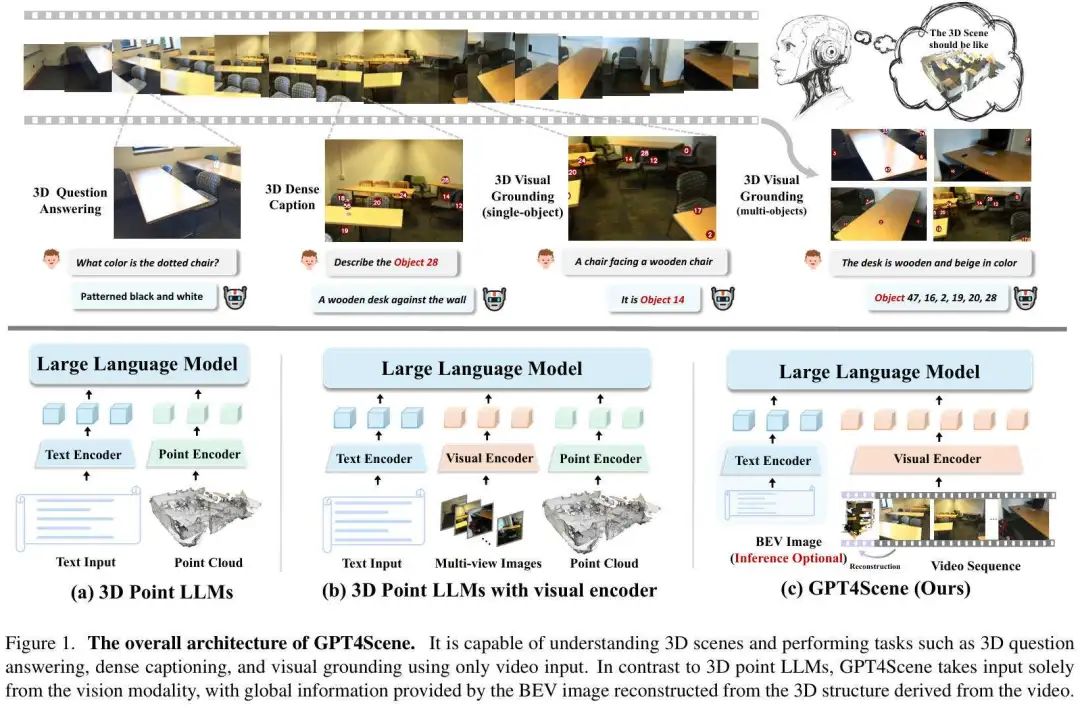
此外,我们也构建了一个由 165K 文本标注组成的处理后的视频数据集来微调开源的VLM模型,相关的实验结果表明,在所有 3D 理解任务上均实现了SOTA的性能。在使用 GPT4Scene 范式进行训练后,即使没有视觉prompt和 BEV 图像作为显式对应,VLM在推理过程中也可以不断改进。相关结果表明所提出的范式有助于 VLM 开发理解 3D 场景的内在能力。
论文链接:https://arxiv.org/abs/2501.01428
网络模型结构&细节梳理
在详细介绍本文提出的算法模型网络结构细节之前,下图展示了GPT4Scene算法模型的整体网络结构图,如下图所示。
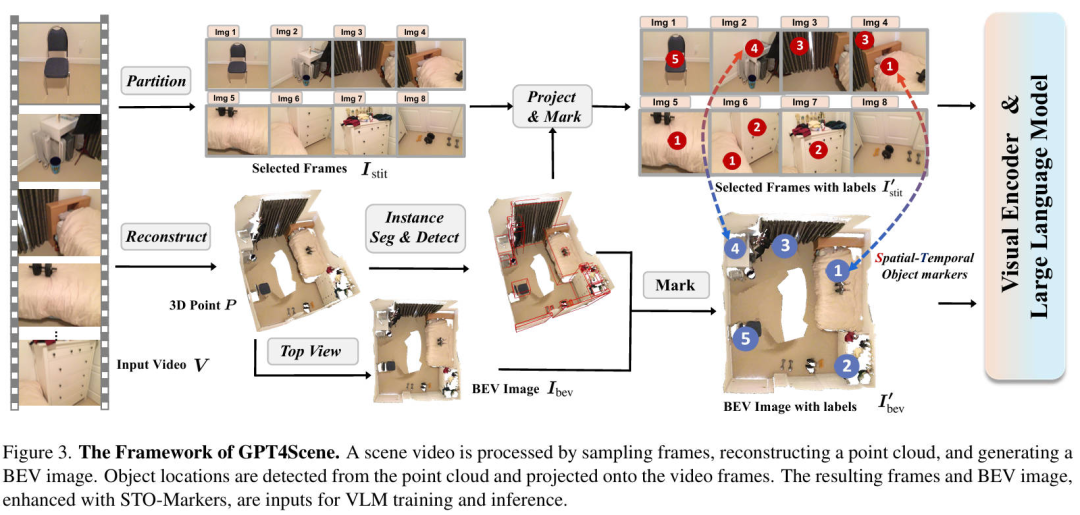
GPT4Scene Framework
首先,我们假设捕获的视频是在室内场景中移动时拍摄的。整个视频由帧图像组成。使用 VLM 处理图像序列面临着图像容量有限、上下文消耗快和推理成本高等挑战。因此,我们均匀采样帧图像。其中,代表采样的帧。我们把这种采样后的视频记作如下的表示形式:
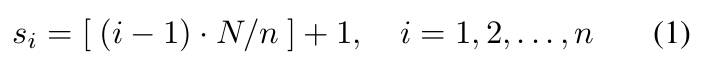
这种预选择大大减少了 VLM 在训练和推理过程中的时间和成本,同时又不会丢失重要的室内场景信息。
以自身为中心的视频仅仅捕获了局部信息,缺少更广泛的场景背景。为了解决这个问题,我们将整个场景重建为点云形式,并将全景图像渲染为鸟瞰图,为 VLM 提供完整的场景概览。具体来说,从室内场景视频和相应的相机外参开始,我们使用3D重建技术来生成3D网格和点云数据,其过程可以用下式的公式进行表示:
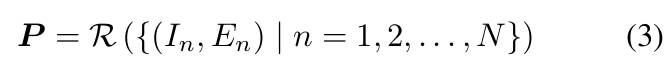
在公式中,表示重建过程,我们假设相机内参是已知的。然后,我们从全局点云生成场景的 BEV 图像,其过程可以用下式进行表示:

其中,代表自上而下视角相机的外参,代表基于相机外参相应视角的渲染过程,从而生成BEV场景的图片。值得注意的是,我们继续以图像的形式向 VLM 提供全局 3D 信息。
为了帮助 VLM 聚焦于特定目标,我们引入了 Spatial-Temporal Object Markers,确保 2D 帧和 3D BEV 图像之间的一致性。为了获取从输入视频重建3D点云,我们应用Mask3D等3D实例分割方法来生成实例Mask。
对于 BEV 图像,我们首先将 3D Mask投影到xy平面上,然后提取投影形成的边界框的中心坐标,然后将其显示在BEV 图像上。对于以自身为中心的 2D markers,我们首先将投影到视频帧上,然后使用 2D Mask形成的边界框的中心作为 2D标记。带有标记的 2D 帧和 BEV 图像可以用如下的公式进行表示:
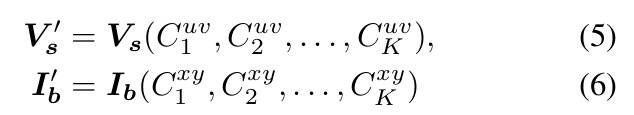
Unlocking VLMs with Zero-shot Prompts
我们在零样本设置中评估 VLM,最初重点关注强大的闭源 VLM(例如 GPT-4o),以评估 GPT4Scene 框架是否能够有效地实现 3D 场景理解。这个过程被称为“unlock”,它使 VLM 能够通过提示理解 3D 场景,而无需额外的训练。具体而言,我们输入和。为了减少开销,我们将中的图像拼接起来形成一张大的图像。我们评估了三项任务:3D 问答、密集字幕和视觉grounding。
在 3D 问答中,目标是回答与场景相关的问题,例如“地板的颜色是什么?”在密集字幕中,任务是描述特定目标,例如“描述 C5 所代表的目标。”在视觉grounding中,目标是从描述中识别目标ID,例如“窗户旁边的黑色椅子的 ID 是什么?”虽然问答与目标标签无关,但密集字幕和视觉grounding需要目标标记。这些任务涉及检测目标并根据其边界框的 IoU 进行过滤。与 Chat-Scene和 Robin3D一致,我们使用 Mask3D 分割结果作为预测边界框来计算 IoU。
除了传统任务外,我们还在这种零样本设置中进行了进一步的实验。相关的实验结果如下图所示。

通过输入和,VLM 可以理解室内场景的全局特征。此时,GPT-4o 仍然可以接受额外的第一人称视角帧,使其能够理解场景中的当前位置以规划下一步动作。此外,使用 GPT-4o 作为agent,VLM 可以根据给定的问题确定任务类型并选择合适的prompt。因此,GPT4Scene 框架作为下一代具身智能的核心技术展现出巨大的潜力。
Enhancing VLMs with ScanAlign Fine-Tuning
零样本prompt可以解锁强大的 VLM 的 3D 理解能力,但如下图所示,这种方法并不能改善较小的VLM的能力。因此,我们的目标是通过微调来增强开源、较小的 VLM。我们首先基于 ScanNet 构建一个室内场景数据集 ScanAlign,其中包含以自我为中心、BEV 图像和文本标注。
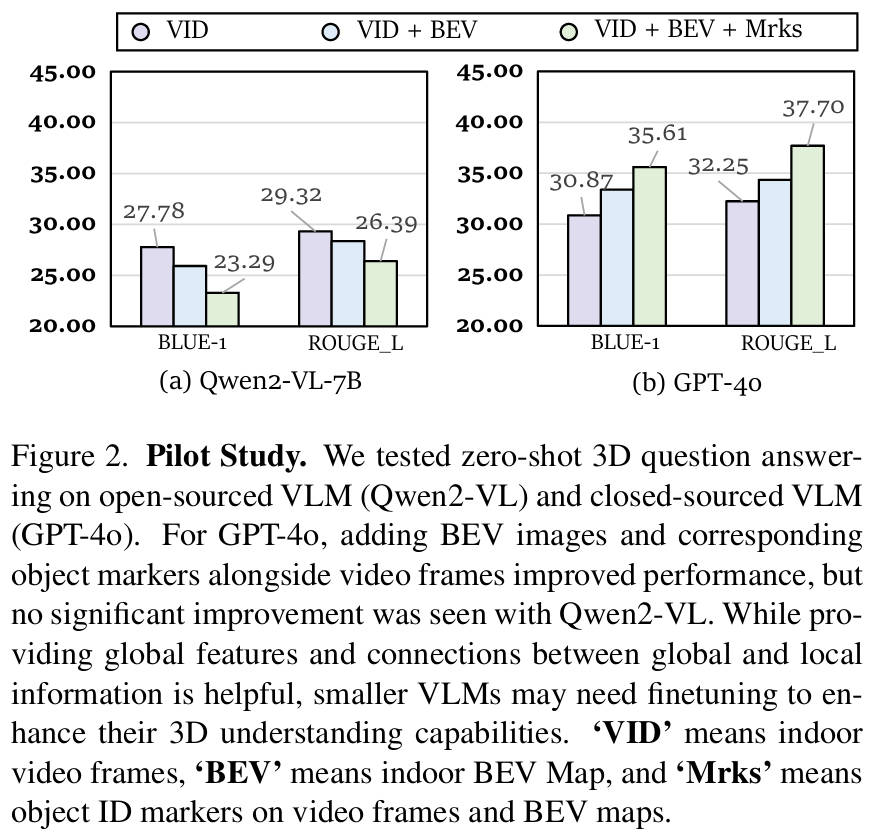
该数据集包括三个 3D 视觉相关任务,视觉输入包括带有 STO 标记的选定视频帧和 BEV 图像,表示从五个ScanNet标注中得出的文本标注,相关信息如下表所示。
我们使用提示随机改变标注格式以增加标注多样性。该数据集总共包含约 165K 条标注。由于我们的方法不需要额外的模态对齐步骤,我们可以直接在 ScanAlign 数据集上执行单阶段指令微调,以增强模型的 3D 空间理解能力。在训练阶段,训练损失是语言模型的交叉熵损失。我们的目标是通过最小化目标答案的负似然对数来优化可学习参数。我们统一了系统消息和用户的问题。因此,损失函数可以表示成如下的公式形式:
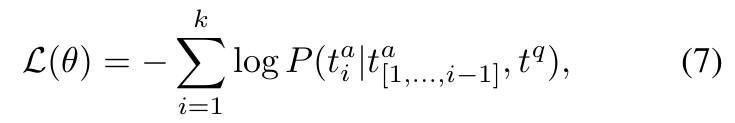
使用 ScanAlign 进行微调后,在推理过程中,我们可以输入,其中代表问题。或者,我们可以不使用 3D BEV 图像,而只使用进行推理。
对于 3D 问答任务,我们甚至可以删除所有目标标记,仅使用原始视频帧进行推理,而无需任何额外处理。对于 3D 问答任务,我们甚至可以删除所有目标标记,使用进行推理,仅使用原始视频作为输入。我们的实验表明,经过 ScanAlign 微调后,小规模 VLM 的 3D 场景理解能力得到显著增强。
实验结果&评价指标
各任务实验结果汇总
3D问答任务的实验结果汇总在下表当中。
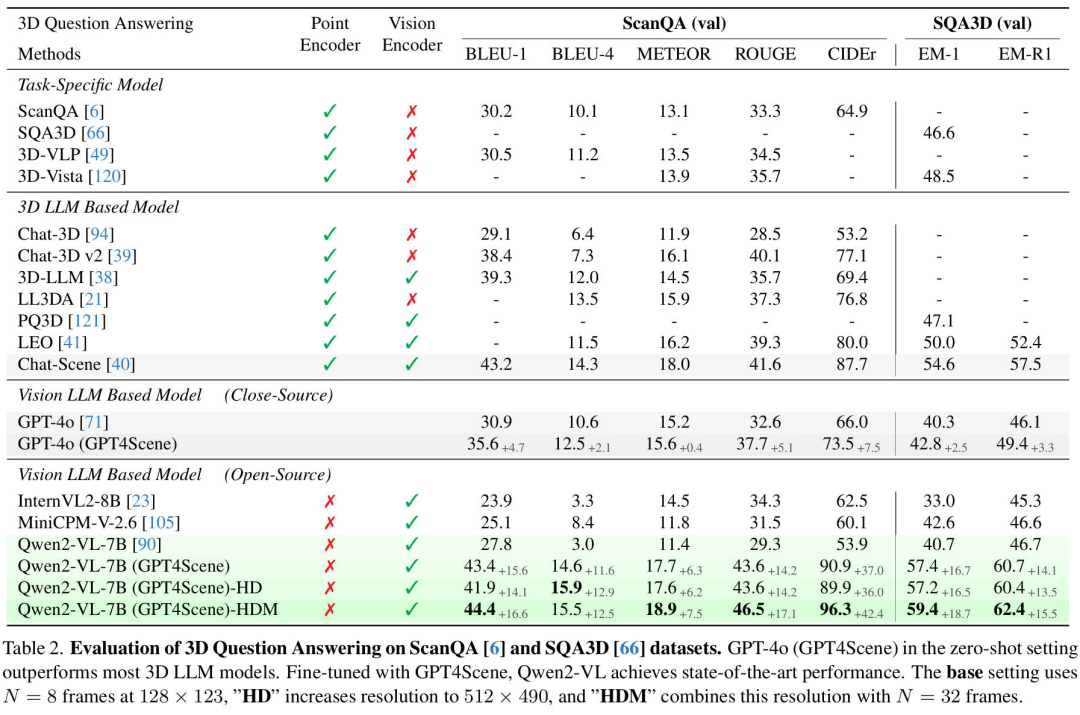
我们将这些方法分为三类:专注于3D问答任务的经典任务特定模型、基于 3D点云LLM 的模型和基于视觉 LLM 的模型。GPT-4o(GPT4Scene)在零样本模式下的表现优于所有任务特定模型,凸显了 GPT4Scene 作为prompt的有效性。相比之下,开源 VLM 在零样本模式下表现不佳,没有使用 GPT4Scene 进行微调,这与我们的实验研究结果一致。使用GPT4Scene提出的策略,我们对Qwen2-VL-7B进行了微调,取得了优异的问答结果。
值得注意的是,Qwen2-VL-7B(GPT4Scene)的表现优于所有其他方法,达到了最先进的性能。此外,与原始Qwen2-VL 7B相比,ScanQA中的BLEU-1提高了56.1%(27.8→43.4),CIDEr提高了68.6%(53.9→90.9)。在SQA3D中,EM-1得分上升41.0%(40.7→57.4)。相对于零样本模式下的GPT-4o,这些指标分别提高了21.9%、23.7%和34.1%。我们的方法极大地提高了模型对3D室内场景的理解。
此外,为了更加直观的展示我们提出的算法模型的有效性。我们在图 4 中展示了在 GPT-4o 上以零样本设置进行的定性结果。拼接的帧提供了场景的概览,而单独的帧则捕捉了细节和动作。除了目标字幕、空间描述和计数等标准任务之外,GPT4Scene 还可以处理具体任务,例如指导用户从附近的书架上取回纸张。在最后一行中,粉红色突出显示的片段表示 BEV 图像作为输入,增强了导航功能。GPT4Scene 还擅长导航和巡逻任务,通过观察机器指示器执行工业检查。
我们还评估了模型在密集字幕和视觉grounding方面的表现,这与问答不同,因为它们需要标记来完成这些任务。实验结果如下表统计所示。
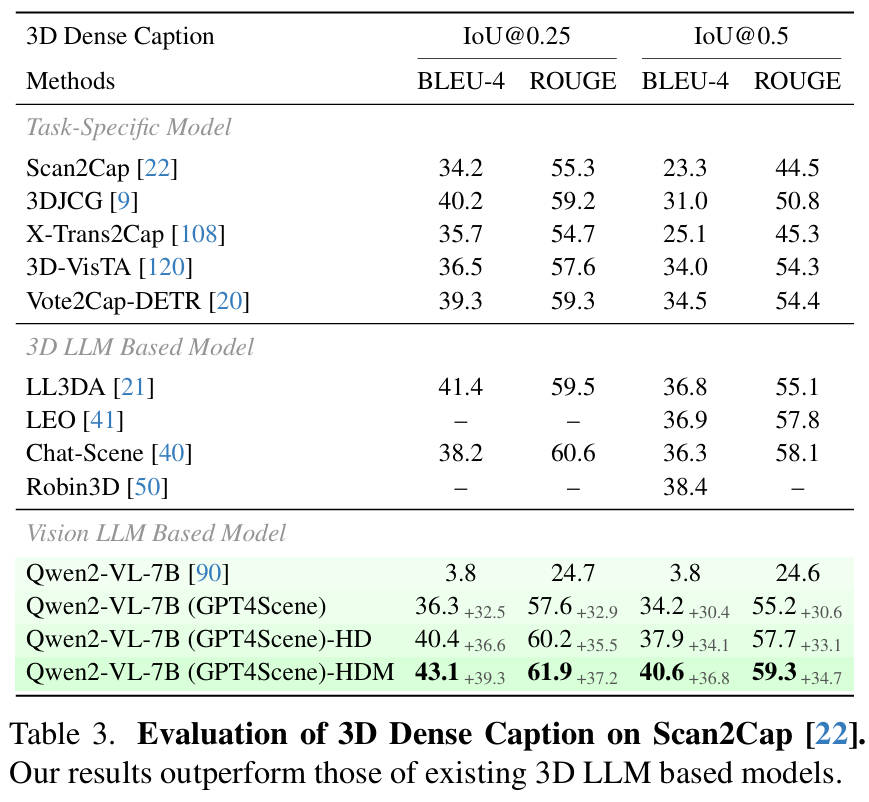
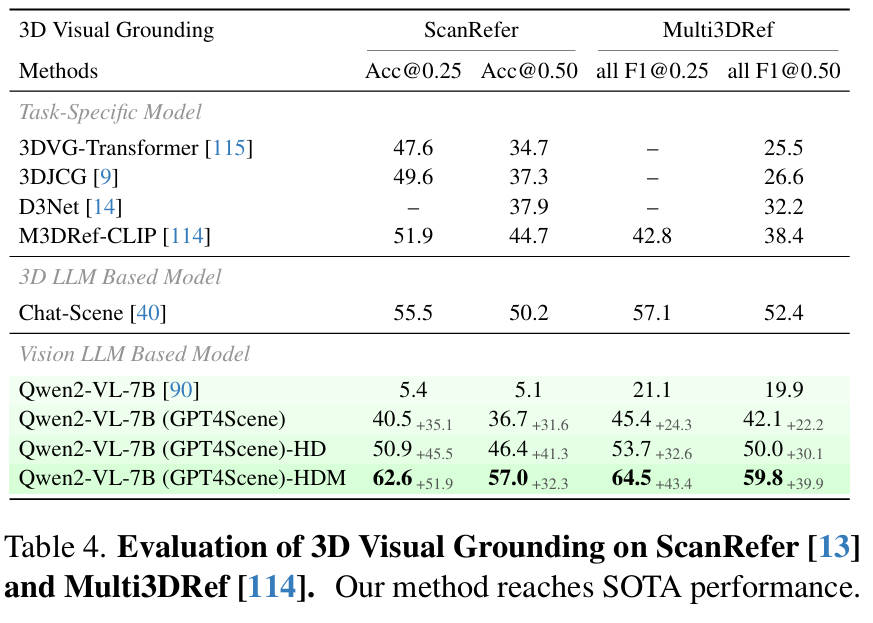
通过相关的实验结果可以看出,Qwen2-VL-7B 经过 GPT4Scene 微调,显著提高了 VLM 的 3D 字幕和基础能力。此外,在高分辨率和更大帧设置 (HD) 下,我们的模型实现了SOTA的性能,超越了所有现有的方法。
消融实验结果
图 2 表明BEV 图像和 STO 标记增强了空间理解。我们使用 3D 问答 (QA) 任务来进一步验证这一点,因为没有 STO标记或 BEV 图像的纯视频输入就足够了。同时,标记对于 3D 密集字幕和视觉grounding在评估过程中参考目标至关重要。如下表所示,在训练和推理过程中删除 BEV 图像会降低这两项任务的性能。进一步删除 STO 标记会导致 QA 性能进一步下降,凸显了 BEV 图像和 STO 标记在帮助 VLM 理解 3D 场景方面的关键作用。
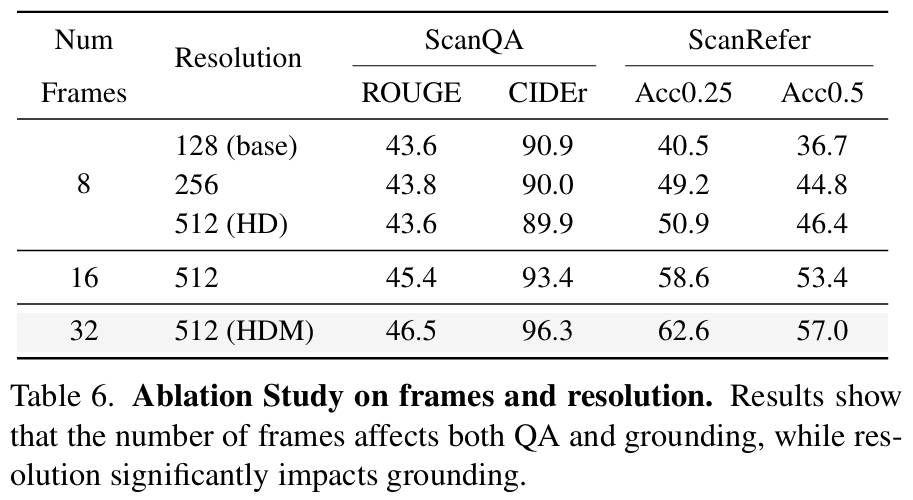
同时,我们也以 3D 问答和视觉grounding为基准,对附加因素进行了消融实验。结果如下表所示。前三行的实验结果显示,图像分辨率显著影响视觉grounding性能,但对 QA 任务的改进有限。此外,实验结果的最后三行表明,增加帧数可以增强室内场景理解,与 QA 中的有限改进相比,对grounding性能的影响更为明显。
结论
在本文中,我们引入了 GPT4Scene,这是一个增强视觉语言模型 (VLM) 的框架,可直接从纯视觉输入理解 3D 场景。我们的实验研究表明,全局场景信息以及视频帧与全局文本中目标之间的对应关系对于提高 VLM 的 3D 理解至关重要。我们建议从输入视频重建 3D 点云,以生成用于全局信息的 BEV(鸟瞰图)图像。
我们通过在视频帧和 BEV 图像中添加时空对象标记来建立全局和本地数据对应关系。GPT4Scene 使用零样本推理与 GPT-4o等闭源 VLM 配合使用,实现了出色的性能。对于较小的 VLM,例如 Qwen2-VL,我们创建了 ScanAlign 数据集,其中包括视频帧、BEV 图像、STO markers和 165K 文本标注。经过微调后,VLM 在场景理解方面显示出显着的改进,在问答任务中达到了最先进的性能。此外,经过微调的 VLM 可以在仅使用原始视频帧的问答任务上表现良好,表明提出的GPT4Scene可以使 VLM 能够有效地理解 3D 场景。
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 2351
2351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









