






点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享慕尼黑应用科技大学最新的工作—BEVDriver!LLM利用BEV地图实现稳健的闭环驾驶。如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>点击进入→自动驾驶之心『多模态大模型』技术交流群
编辑 | 自动驾驶之心
写在前面 & 笔者的个人理解
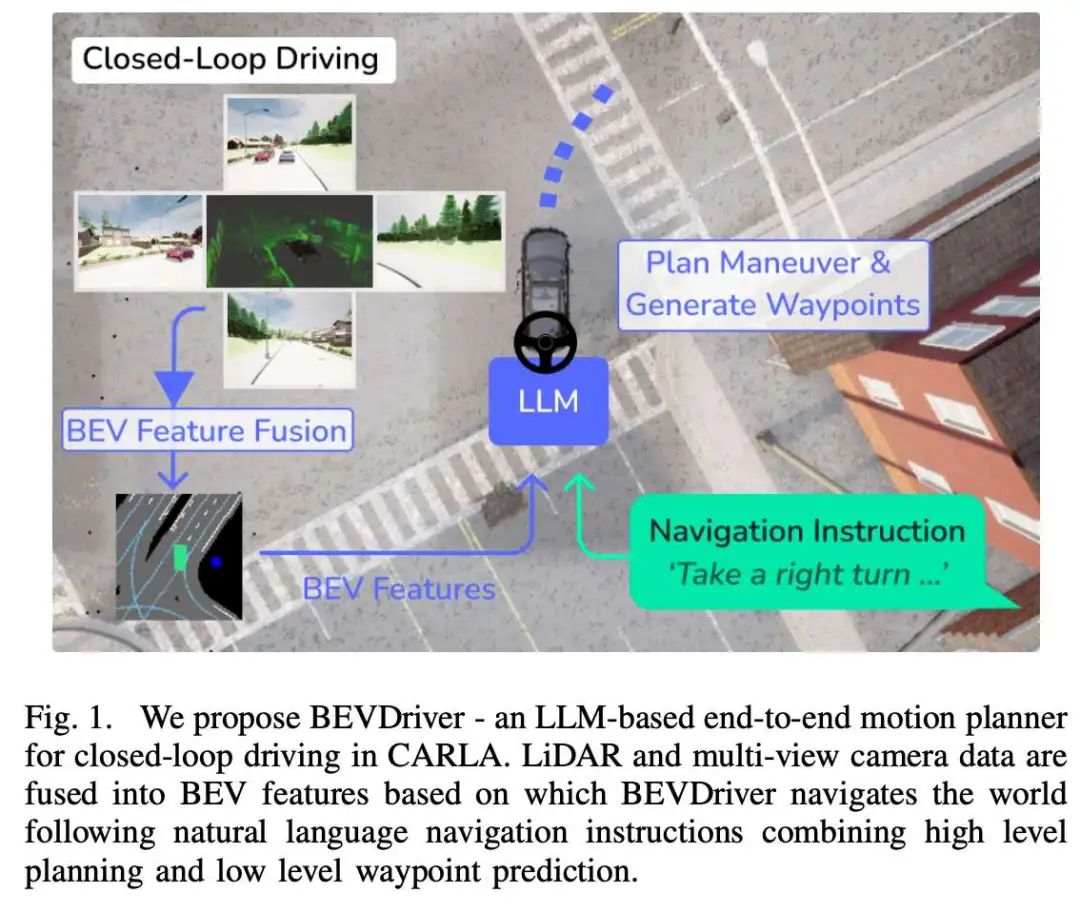
自动驾驶技术有望为未来出行效率奠定基础,但其研究领域需通过安全、可靠且透明的驾驶能力建立信任。大型语言模型(LLMs)凭借其推理能力和自然语言理解潜力,可作为通用决策者进行自车运动规划,并与人类交互及适应为人设计的驾驶环境。尽管这一方向前景广阔,当前自动驾驶方法在结合3D空间表征与LLMs的推理及语言能力方面仍面临挑战。本文提出BEVDriver,一种基于LLM的端到端闭环驾驶模型,在CARLA模拟器中利用潜在BEV(鸟瞰图)特征作为感知输入。
BEVDriver通过BEV编码器高效处理多视角图像与3D LiDAR点云数据。在共享的潜在空间中,BEV特征通过Q-Former与自然语言指令对齐,并传递至LLM以预测精确的未来轨迹,同时考虑导航指令与关键场景。在LangAuto基准测试中,我们的模型在驾驶得分(Driving Score)上较最先进方法(SoTA)提升高达18.9%。
论文链接:https://arxiv.org/abs/2503.03074
简介
在复杂且安全至上的自动驾驶领域,生成式端到端方法是基于规则或模块化预测与运动规划方案的有力替代方案。后者的泛化能力存在不足,而生成式方法则能通过更多训练数据提升性能,并高效优化最终驾驶任务。LLMs凭借其推理能力与自然语言理解,被视为高效且可解释的决策者。其内在的世界知识增强了上下文理解与推理能力,同时生成自然语言解释的潜力为解决生成模型的“黑箱”问题提供了途径。然而,LLMs在绝对空间理解上的局限性成为安全关键场景中的主要挑战,因为精确运动预测与轨迹规划至关重要。
基于Transformer的运动规划方法利用鸟瞰图(BEV)特征图,将单模态或多模态传感器数据转换为自车周围环境的俯视特征表示,为轨迹规划等任务提供鲁棒的空间输入。LMDrive首次实现了基于语言指令的CARLA模拟器端到端导航。该方法通过BEV编码器处理LiDAR与多视角相机数据,结合目标检测与交通灯状态等感知标记及未来路径点预测,验证了BEV编码器在LLM驱动的运动规划研究中的潜力。
基于此,本文进一步拓展LLMs的能力,证明其不仅能完成高层决策或路径点优化,还可直接通过BEV特征(包括3D LiDAR点云与多视角图像)端到端预测轨迹,融合自然语言指令,弥合高层决策与底层规划的鸿沟。与依赖预预测路径点作为输入的LMDrive不同,我们的方法直接使用感知训练的编解码器生成的原始潜在BEV特征,避免了轨迹特定预处理的依赖。这一设计通过LLM对高维特征的直接解释,提升了泛化能力,并支持自监督运动学习。
总结来说,本文的主要贡献如下:
提出BEVDriver,一种基于LLM的端到端闭环轨迹预测与规划模型,直接利用LiDAR与相机生成的原始BEV特征(图1),消除对预预测路径点的依赖,提升鲁棒性与自监督学习能力。
在LangAuto基准测试中,BEVDriver的驾驶得分较现有最佳方法提升高达18.9%,并开源模型权重、训练代码与数据集扩展,以推动语言引导自动驾驶研究。
第二章 相关工作回顾
a) BEV特征图
BEV特征图通过单模态或多模态输入数据生成自车周围环境的俯视表示。这种空间表征通过提供无遮挡的环境视角,增强了对复杂场景的鲁棒性。此外,统一的BEV表示为下游预测与规划模块的推理提供了便利。BEVDepth专注于基于相机输入的3D深度估计以实现目标检测。多模态BEV融合通过整合语义图像信息(如BEVFusion)提升传感器失效时的鲁棒性,这对安全关键场景至关重要。BEVFormer利用基于网格的空间查询与时间查询,实现LiDAR-图像融合与序列推理;而BEVFusion]则通过共享BEV表示保留语义信息。
b) 闭环驾驶
闭环评估根据环境反馈动态调整自车行为,而开环评估仅测量与真实轨迹的偏差。当前多数端到端方法聚焦于优化开环规划,但开环性能无法保证闭环场景的有效性,突显动态交互评估的必要性。CARLA模拟器提供闭环评估环境,其中BEV方法表现优异。InterFuser通过LiDAR与多视角图像的BEV投影增强场景理解;ReasonNet则在BEV地图中集成时序与全局推理模块以捕捉动态交互。
c) 基于LLM的驾驶
LLM凭借其世界知识与推理能力,被用于生成上下文感知的驾驶决策,如DriveLM、DriveVLM和EMMA等先进方法。自然语言处理通过生成解释性文本(如DriveGPT4、RAG-Driver、DriveMLM)提升模型可解释性。然而,LLM的空间理解能力仍受限。现有方法如OmniDrive通过3D标记化解码空间信息,CarLLaVA则利用视觉编码保留空间特征。BEV地图因其高效清晰的表示成为理想解决方案,如Talk2BEV结合BEV与视觉语言模型(VLM)实现感知与推理的统一。
BEVDriver详解
图2展示了BEVDriver的整体架构。多视角RGB图像与3D LiDAR点云通过BEV编码器融合为BEV特征图。该特征图通过Q-Former与导航指令对齐后输入LLM,LLM输出未来路径点并生成驾驶指令,最终由PID控制器执行。以下详细描述各模块设计。
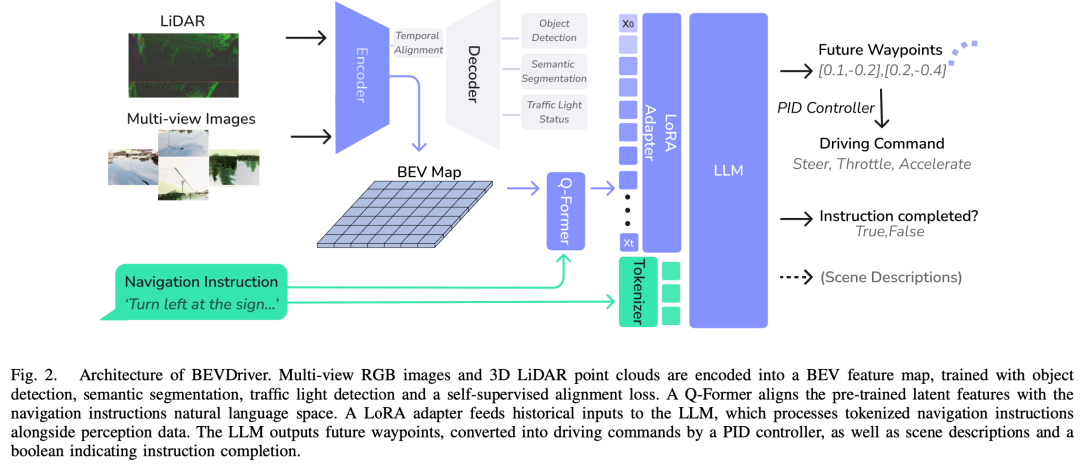
A. 感知模块
为生成BEV特征嵌入,我们基于InterFuser的编码器架构实现BEV编码器。该架构采用ResNet-50处理图像数据,ResNet-18处理LiDAR数据,确保高效的多模态特征提取。提取的特征通过基于Transformer的编码器映射至256维嵌入空间。
解码器部分复用InterFuser的交通检测头、交通灯状态预测头,并新增前视语义分割头。语义分割头采用金字塔场景解析网络,通过多尺度自适应平均池化(1、2、3、6尺度)捕获全局上下文,并通过投影层融合池化特征与输入特征以保留空间细节,最终输出精确的分割结果。
BEV编码器通过四类损失函数预训练:
L1交通检测损失:优化目标检测精度;
交叉熵交通灯状态损失:预测交通灯状态;
焦点损失(Focal Loss):加权交叉熵(α=0.9,γ=5)优化语义分割;
对比损失(Contrastive Loss):增强时序一致性,使相邻帧特征相似,远距离帧特征差异显著。
推理阶段,仅保留编码器部分,生成紧凑的BEV特征表示。编码器参数量为5.37M,推理频率达18Hz。
B. 端到端流程
端到端驾驶流程包含以下组件:
BEV编码器:融合多视角图像(前、左、右、后视)与LiDAR点云,生成BEV潜在特征。编码器可处理最多40帧历史数据以捕捉时序依赖。
Q-Former对齐模块:
采用改进的BLIP-2 Q-Former,将BEV特征与导航指令在自然语言潜在空间对齐;
使用32个可学习查询向量(768维),将BEV特征与指令语义关联。
LLM推理模块:
通过LoRA适配器(秩16,丢弃率32.5%)调整LLM参数,生成导航动作标记;
GRU网络基于LLM最后一层隐藏状态预测5个未来路径点;
2层MLP判断导航指令是否完成(布尔标志)。
控制执行:
纵向与横向PID控制器分别调节油门/刹车与转向,跟踪预测路径点。
实验结果分析
A. 实验设置
我们采用LLM模型Llama-7b和指令微调模型Llama-3.1 8B-Instruct,将BEVDriver与LMDrive和AD-H进行闭环评估对比。主要实验中,预训练的BEV编码器参数保持冻结。输入帧采样率为1,PID控制器的积分误差项设为20以增强控制稳定性。所有实验均在每场景重复3次取平均值。
B. 数据集与基准测试
a) LMDrive数据集:使用LMDrive提供的数据集,包含15k条序列,涵盖CARLA 8个城镇(Town 1-7、10)的路线数据,采样频率为10Hz,包含导航指令、控制信号、多视角RGB图像、LiDAR数据及元数据(如交通灯状态、地面真实路径点)。训练数据包含所有8个城镇,验证集保留3种天气-时段条件(soft rain午间、soft rain黄昏、hard rain夜间)。
b) BEVDriver语义数据集:在LMDrive的8个城镇中额外采集2k条序列,包含前、左、右视角的语义分割标注(涵盖行人、车辆、道路、交通标志等CARLA语义类别)。数据集与生成代码将公开。
c) CARLA基准测试:CARLA提供闭环基准测试Leaderboard 1.0。LangAuto基准将其适配为LLM评估,将7种离散导航指令映射为自然语言指令。测试场景包含多样的环境、天气、时段及复杂交互(如交叉路口、行人/骑行者突然穿行、多车道环岛)。路线分为短程(<150m)、中程(150-500m)、长程(>500m),并插入不可行任务以测试鲁棒性。
C. 评估指标
闭环规划采用三项指标:
驾驶得分(DS):路线完成率(RC)与违规得分(IS,含碰撞、闯红灯等)的乘积。
开放环路基线:使用平均位移误差(ADE)和最终位移误差(FDE),计算预测路径点与真实值的L2距离。
D. 训练细节
LLM训练:使用AdamW优化器(权重衰减0.06),余弦学习率调度器(初始学习率1e-4,最小1e-5,预热步数2000)。Llama-7b和Llama-3.1模型训练15轮(72小时),8块Nvidia A100 GPU,批量大小4。
BEV编码器训练:8块Nvidia A40 GPU,批量大小16,AdamW优化器(学习率5e-4,权重衰减0.05)。
E. 定性结果
图3展示BEVDriver在CARLA中的导航示例,模型能处理复杂场景(如环岛)并提前规划车道变换。图4显示语义分割与BEV检测结果,模型能准确识别远距离行人/交通标志,但对道路细节(如斑马线)存在局限。

F. 定量结果
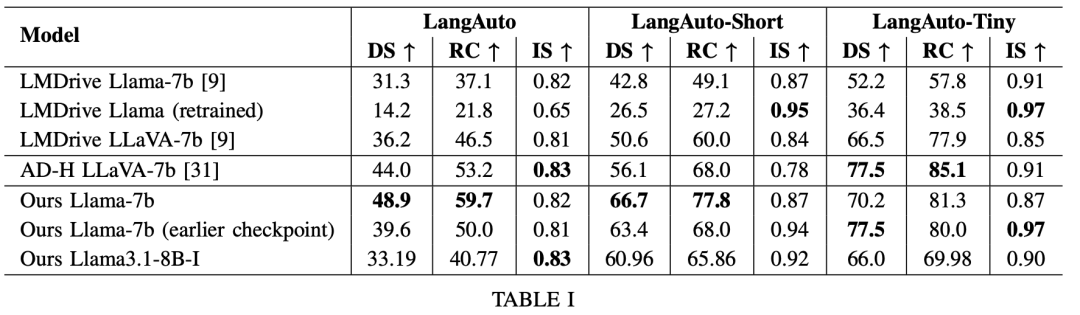
a) 闭环规划:表I对比BEVDriver与现有方法在LangAuto基准的表现。BEVDriver在驾驶得分(DS)和路线完成率(RC)上优于最先进方法。例如,在LangAuto长程测试中,Llama-7b版本DS较AD-H提升11.1%,RC提升12.2%。
b) 开环规划:BEVDriver在ADE和FDE指标上表现最佳(Llama-7b:ADE 0.04,FDE 0.07),优于LMDrive的LLaVA-7B(ADE 0.09,FDE 0.18)。
G. 消融实验
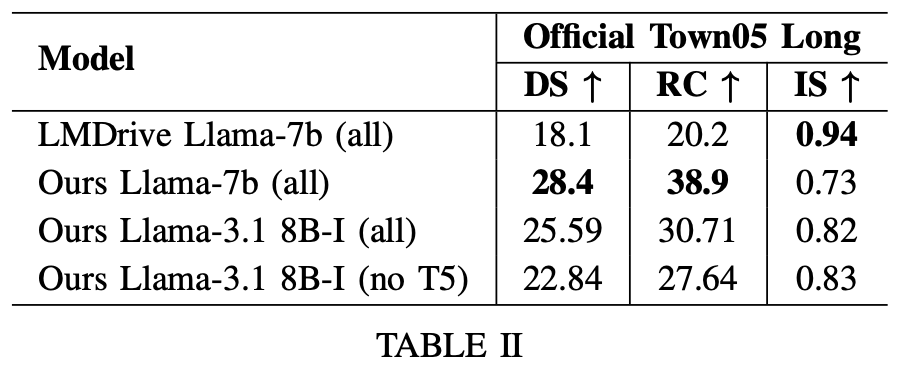
a) Town 5泛化测试:在未训练的CARLA Town 5长程测试中,BEVDriver(Llama-7b)DS为28.4%,RC为38.9%,优于其他模型。
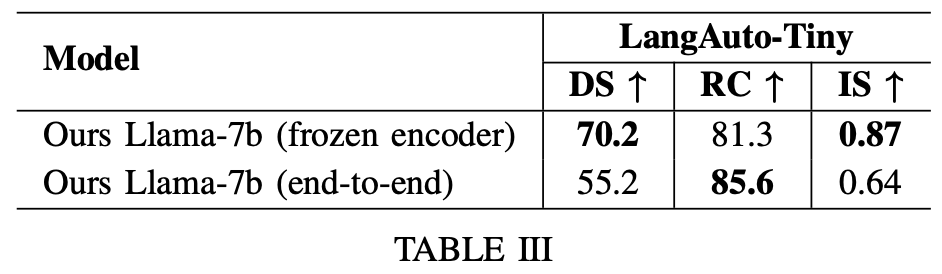
b) 端到端训练:解冻BEV编码器后,RC提升5%,但IS下降(表III),可能因交通灯状态监督缺失导致初期性能下降。
c) 无误导指令测试:移除误导指令后,BEVDriver DS降至70.2%(表IV),表明频繁指令可提升模型表现。
讨论
BEVDriver通过融合低层BEV特征与高层自然语言指令,实现了端到端的轨迹预测与规划,在LangAuto基准测试中较最先进方法(AD-H)的驾驶得分提升高达18.9%。与LMDrive的Llama-7b模型相比,BEVDriver在相同骨干网络下性能提升35.1%-56.2%,验证了BEV特征与LLM结合的有效性。
主要发现与局限性:
距离指令的执行挑战:模型对“x米后左转”等基于距离的指令存在误执行问题(如立即变道)。未来需通过时空注意力机制或增强距离指令与BEV表示的对齐解决。
闭环评估的重要性:CARLA与LangAuto框架虽提供闭环测试能力,但场景多样性不足和交通阻塞问题仍限制泛化性与指标可靠性。
端到端训练的潜力:消融实验表明,解冻BEV编码器可提升路线完成率(RC),但可能因交通灯状态监督不足导致初期违规增加,需进一步优化训练策略。
跨领域扩展性:
BEVDriver的架构可迁移至其他需自然语言交互的复杂环境导航任务(如服务机器人、辅助机器人),其核心思想——通过统一BEV表示融合感知与语言推理——具有广泛适用性。
未来工作:
增强时空推理能力(如自回归预测)以提升动态场景适应性;
通过生成场景描述语言标记提高模型可解释性(已开展初步实验);
开源代码库以推动语言引导自动驾驶研究。
结论
我们提出了BEVDriver,一种基于LLM的端到端运动规划器,通过统一的潜在BEV表示从自然语言指令中预测低层路径点并规划高层机动动作。通过融合相机与LiDAR数据,BEVDriver能够生成精确的未来轨迹,同时结合上下文驱动的决策(如转向与让行)。我们的模型性能优于最先进方法,驾驶得分(DS)提升高达18.9%,在相同Llama-7b骨干网络下较LMDrive的最佳模型提升35.1%,并在LangAuto基准测试中实现56.2%的性能改进。未来工作将聚焦于增强BEVDriver的鲁棒性、时序感知能力与可解释性。
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









