






点击下方卡片,关注“自动驾驶之心”公众号
Arxiv上又更新了很多自动驾驶优秀工作!自动驾驶即将开启o1时代,DriveLMM-o1 BenchMark问世!自动驾驶闭环重建新SOTA MuDG。本文内容均出自『自动驾驶之心知识星球』,欢迎加入交流。这里已经汇聚了近4000名自动驾驶从业人员,每日分享前沿技术、行业动态、岗位招聘、大佬直播等一手资料!欢迎加入~
新人大额优惠!欢迎扫码加入~

DriveLMM-o1
论文标题:DriveLMM-o1: A Step-by-Step Reasoning Dataset and Large Multimodal Model for Driving Scenario Understanding
论文链接:https://arxiv.org/abs/2503.10621
论文代码:https://github.com/ayesha-ishaq/DriveLMM-o1
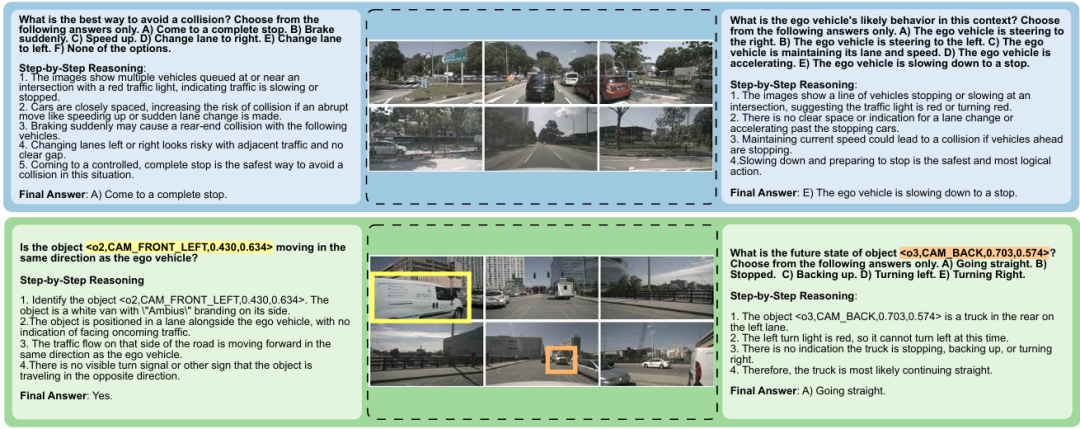
核心创新点:
1. 专用逐步推理数据集与多模态基准
提出首个面向自动驾驶场景的逐步推理数据集DriveLMM-o1,包含18k训练样本和4k测试样本,覆盖感知、预测、规划任务。
数据集集成多视角图像(multiview images)与LiDAR点云(LiDAR point clouds),并标注逻辑链式推理步骤,确保模型理解场景动态与空间关系。
2. 动态多模态模型架构与高效微调
基于InternVL2.5-8B构建模型,融合视觉Transformer编码器与LLaMA语言模型,支持动态图像分块(dynamic image patching),高效处理高分辨率多视角图像。
采用LoRA微调(Low-Rank Adaptation),仅调整0.49%参数,保留通用多模态能力的同时,适配自动驾驶推理任务,显著提升模型泛化性与计算效率。
3. 自动驾驶专用评估体系
设计逻辑连贯性指标(如Faithfulness-Step、Commonsense)与安全关键型指标(如风险识别准确率、交规遵循度),综合评估推理步骤的合理性与最终决策的可靠性。
结合人工验证与GPT-4o自动化评分,确保评测框架的严谨性。
4. 性能优势与领域适应性
模型在最终答案准确率上超越最佳开源基线7.49%,推理得分提升3.62%,尤其在场景感知(75.39分)与风险识别(73.01分)任务中表现突出。
相比通用视觉推理模型(如LlamaV-o1),DriveLMM-o1在复杂驾驶场景中展现更强的多模态融合能力与安全决策逻辑,减少黑盒推理缺陷。
A Survey of Sim-to-Real Methods in RL
论文标题:A Survey of Sim-to-Real Methods in RL: Progress, Prospects and Challenges with Foundation Models
论文链接:https://arxiv.org/abs/2502.13187
repo链接:https://github.com/LongchaoDa/AwesomeSim2Real.git
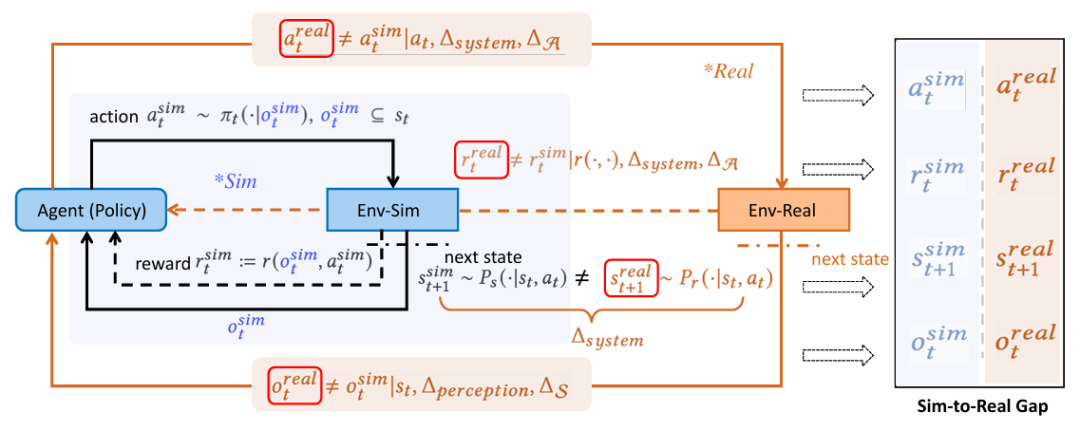
核心创新点:
1. MDP四要素系统化分类框架
提出基于马尔可夫决策过程(MDP)的Sim-to-Real技术分类体系,将方法论锚定于观察空间对齐 (Observation)、动作空间适配 (Action)、环境动力学建模 (Transition)及奖励函数设计 (Reward)四大维度,实现对经典与新兴技术(如扩散模型生成安全场景Diff-Scene)的统一表征。
2. 基础模型驱动的自动化流程革新
LLM赋能奖励函数生成 :提出Text2Reward框架,通过自然语言任务描述自动生成稠密奖励函数,减少人工设计依赖。
零样本视觉泛化 :构建视觉通用强化学习框架,利用预训练多模态模型实现跨场景策略迁移,突破传统Sim2Real对精确环境建模的依赖。
3. 复杂动力学建模与延迟补偿
随机延迟动态建模 :提出随机延迟强化学习框架,通过时序建模解决现实世界动作执行延迟问题。
非马尔可夫决策过程处理 :开发语义非马尔可夫仿真代理,增强长序列决策的可解释性与可扩展性。
4. 高保真评估基准与工具链
DISCOVERSE仿真平台:支持复杂高保真环境下的机器人策略验证,集成物理引擎与传感器噪声模拟。
NeuronsGym导航框架:融合仿真-现实混合训练,通过模块化设计量化信息瓶颈对Sim2Real迁移的影响。
MuDG
论文标题:MuDG: Taming Multi-modal Diffusion with Gaussian Splatting for Urban Scene Reconstruction
论文链接:https://arxiv.org/abs/2503.10604
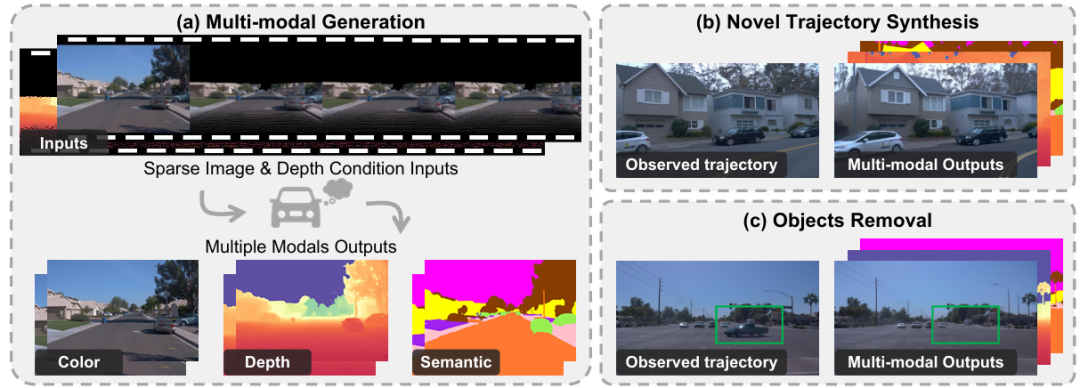
核心创新点:
1. 多模态扩散模型与高斯泼溅(3DGS)的协同框架
提出首个将可控多模态扩散模型(MDM)与3D高斯泼溅(3DGS)深度融合的框架,通过MDM生成新视角的RGB、深度及语义数据,作为监督信号优化3DGS表示,显著提升极端视角变化下的渲染鲁棒性。
2. 无需逐场景优化的前馈新视角合成
基于LiDAR点云投影的稀疏RGB-D条件输入,MDM通过视频扩散先验直接生成多模态密集输出,实现无需逐场景优化(per-scene optimization)的实时新视角合成,避免传统NeRF/GS方法的高计算开销。
3. 动态-静态解耦与多模态联合监督
通过追踪边界框(bbox tracking)分离动态与静态元素,构建融合LiDAR点云;利用生成的多模态数据(RGB、深度、语义)联合监督3DGS训练,强化几何-语义一致性,缓解极端视角外推时的性能退化。
4. 跨模态对齐的潜在空间编码
设计统一潜在空间编码策略,将单通道深度图扩展为伪RGB,语义图通过颜色映射适配VAE输入,实现多模态数据的高效对齐,确保扩散生成与3DGS优化的跨模态一致性。
Unlock the Power of Unlabeled Data in Language Driving Model
论文标题:Unlock the Power of Unlabeled Data in Language Driving Model
论文链接:https://arxiv.org/abs/2503.10586
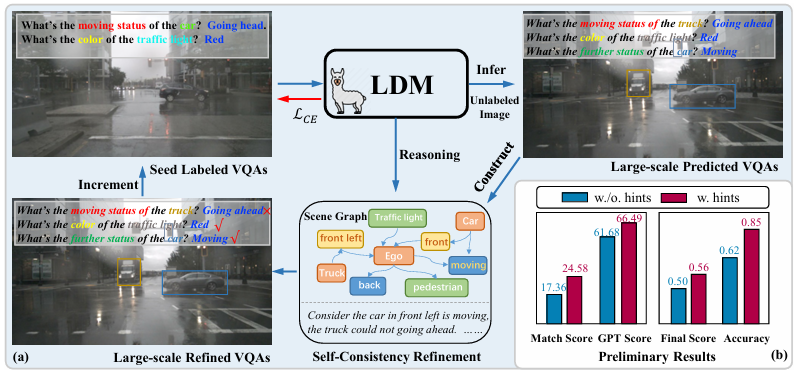
核心创新点:
1. 动态自监督预训练框架(Dynamic Self-Supervised Pre-training Framework)
提出分层渐进式掩码语言建模(Hierarchical Progressive Masked Language Modeling, HP-MLM),通过语义层级动态调整掩码策略(词级→短语级→句子级)
引入基于信息熵的自适应负采样机制,优化对比学习中的难负例挖掘(Hard Negative Mining)
2. 半监督知识蒸馏架构(Semi-Supervised Knowledge Distillation Architecture)
构建双通道异构模型结构(Dual-Channel Heterogeneous Architecture),实现教师模型(预训练LM)与学生模型(任务驱动LM)的协同训练
开发跨模态一致性正则化方法(Cross-Modal Consistency Regularization),通过未标记数据的隐式语义对齐增强模型泛化性
3. 数据-模型协同优化机制(Data-Model Co-Optimization Mechanism)
提出基于梯度相似性的动态数据筛选策略(Gradient Similarity-based Dynamic Data Selection),建立未标记数据质量评估的数学模型:
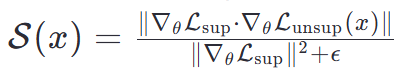
设计课程式数据增强管道(Curriculum Data Augmentation Pipeline),通过强化学习动态调整数据增强强度
OCCUQ
论文标题:OCCUQ: Exploring Efficient Uncertainty Quantification for 3D Occupancy Prediction
论文链接:https://arxiv.org/abs/2503.10605
论文代码:https://github.com/ika-rwth-aachen/OCCUQ
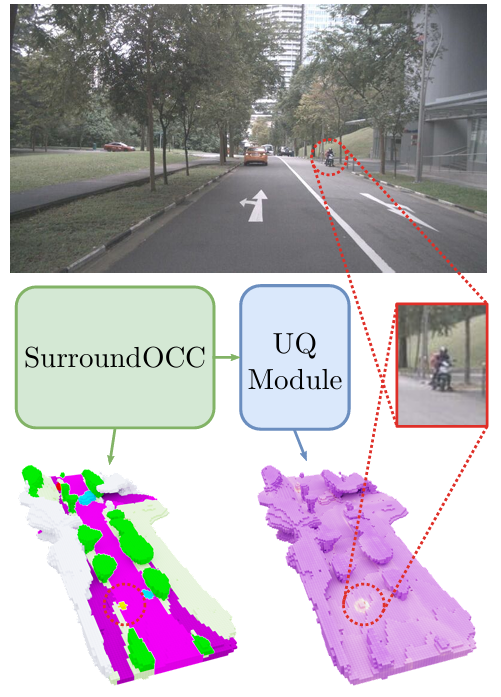
核心创新点:
1. 轻量级不确定性量化模块(UQ Module)
提出一种基于深度确定性不确定性(DDU)的轻量化模块,集成至3D占据预测网络(如SurroundOCC),通过单次前向传播实现认知不确定性(epistemic uncertainty)与 数据不确定性(aleatoric uncertainty)的高效解耦估计,计算开销仅增加0.02%参数量。
2. 高斯混合模型(GMM)特征密度估计
在特征空间中引入GMM建模,通过训练集特征分布拟合,将特征密度作为认知不确定性度量。结合谱归一化(Spectral Normalization)约束特征空间的双利普希茨连续性(bi-Lipschitz continuity),确保特征距离与输入语义变化的一致性。
3. 区域级OoD检测与腐蚀模拟
首次提出区域特定腐蚀(region-specific corruption)方法,通过单摄像头失效模拟局部传感器故障,构建体素级分布外(OoD)场景。在nuScenes数据集上验证了模型在区域级(如单摄像头腐蚀)和场景级(如雾、运动模糊)OoD检测的优越性(mAUROC提升10.6% vs Deep Ensembles)。
4. 动态置信度校准策略(UGTS)
提出基于不确定性的温度缩放(Uncertainty-Guided Temperature Scaling),根据认知不确定性动态调整分类logits的温度参数,在腐蚀数据上实现更优的校准效果(mECE降低61.5% vs 基线方法)。
Finetuning Generative Trajectory Model with Reinforcement Learning from Human Feedback
论文标题:Finetuning Generative Trajectory Model with Reinforcement Learning from Human Feedback
论文链接:https://arxiv.org/abs/2503.10434

核心创新点:
1. 人类反馈驱动的生成轨迹微调框架(TrajHF)
首次将强化学习与人类反馈(RLHF)系统性引入自动驾驶轨迹生成任务,通过构建偏好奖励函数和群体相对优势计算(Group Relative Advantage),实现多模态轨迹分布与人类驾驶风格的动态对齐。
2. 多条件去噪Transformer架构(MCD)
提出融合多模态感知(图像、LiDAR、历史动作)的条件去噪网络,通过交叉注意力机制实现状态-动作空间的可逆映射,在无锚点/词汇表约束下直接生成连续轨迹,解决传统方法模式坍缩问题。
3. 双重优化目标与行为克隆约束
设计复合奖励函数(R = w_avgR_avg + w_final R_final),同步优化轨迹平滑性与终端状态精度;引入行为克隆损失(BC Loss)防止微调过程中的灾难性遗忘,平衡风格迁移与基础驾驶能力保留。
4. SOTA性能与风格可解释性
在NavSim基准测试中达到93.95 PDMS,超越现有方法(如Hydra-MDP、GoalFlow等);通过人类评估实验(BOE指标)验证生成轨迹在"激进性"等风格维度的语义一致性,为个性化自动驾驶提供可解释的解决方案。
Learning Multiple Probabilistic Decisions
论文标题:Learning Multiple Probabilistic Decisions from Latent World Model in Autonomous Driving
论文链接:https://arxiv.org/pdf/2409.15730
项目链接:https://github.com/Sephirex-X/LatentDriver
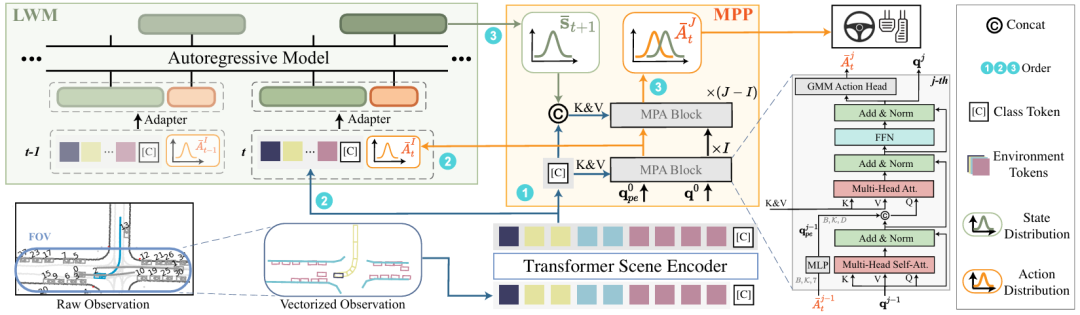
核心创新点:
1. 多概率决策建模
提出基于高斯混合模型(GMM)与拉普拉斯分布的混合分布框架,将环境状态转移与自车动作空间联合建模为多模态概率分布(mixture distribution)。通过多概率规划器(MPP)的分层Transformer结构,逐层优化动作分布参数,显式捕捉驾驶决策的随机性。
2. 潜在世界模型与规划的统一学习
设计双向随机交互机制:
潜在世界模型(LWM) :采用自回归Transformer预测环境潜在状态分布,通过适配器(Adapter)将动作-观测序列编码为低维隐空间表征;
规划-模型联合优化 :利用中间层动作采样(intermediate action sampling)生成估计动作分布,作为LWM的输入以缓解“自欺问题”(self-delusion),打破历史动作依赖的级联条件分布。
3. 场景泛化性提升
在Waymax闭环仿真中验证了方法在长尾场景(如U-turn、无保护左转)的专家级性能(mAR指标达89.3%),通过引入场景分类指标(mAR@[95:75])量化复杂交互下的决策鲁棒性,显著优于基于强化学习/模仿学习的PlanT、EasyChauffeur等基线模型。
『自动驾驶之心知识星球』,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫码加入~
新人大额优惠!欢迎加入最专业的技术社区~


















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









