






2025智驾竞争进入新阶段!特斯拉FSD入华,无论是完全端到端,还是专注于planner的模型,各家公司基本都投入较大人力去研发。小鹏、蔚来、理想、华为都对外展示了其端到端自动驾驶方案,效果着实不错,非常有研究价值。
端到端有哪些技术栈?
行业里面的端到端主要分为完全端到端方案、专注于planner的端到端方案(包括某鹏的XPlanner)。顾名思义,完全端到端是从传感器直接到规控;而专注于planner的端到端以感知模块的输出作为先验,替换原来以规则作为主要形式的PnC模块。
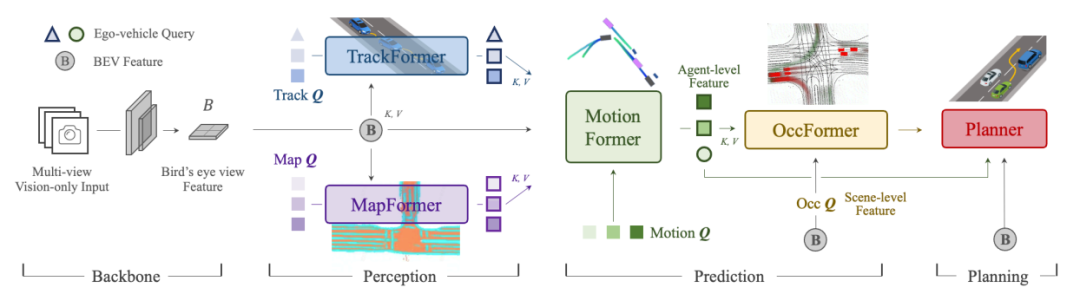
从传感器到控制策略的(如果把条件再放松下也可以到轨迹输出)完全端到端方案更为简约,但同样面临一个问题,可解释性差。UniAD用分阶段监督的方法逐步提高了可解释性,但训练仍然是个难题。在足够体量和质量的数据群下,效果能够得到保证,泛化性能也不错。
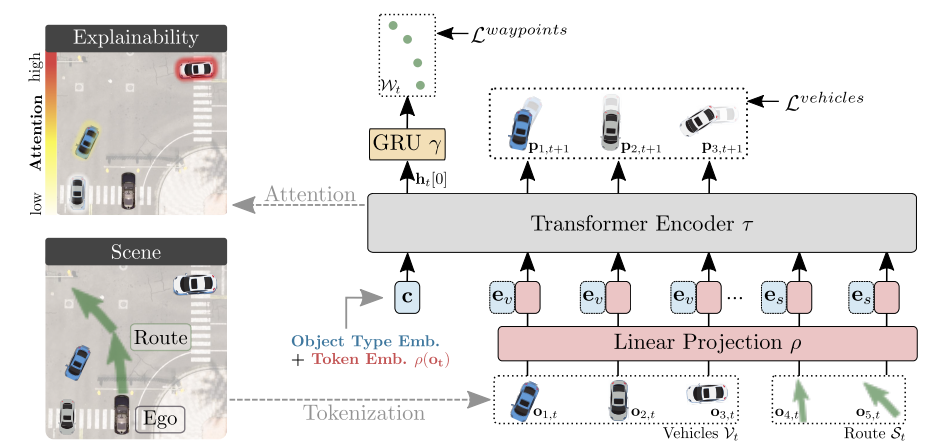
而专注于planner的端到端方案,如果深究的话,只能算狭义上的端到端,但更贴合当下的量产方案和任务,而且可解释性也较高,是目前主机厂和自动驾驶公司优先推行和落地的。
如果从信息输入的角度上来看,又可以分为纯视觉方案(UAD、UniAD这类)和多模态方案(FusionAD这类),传感器成本不断在下降,多模态方案也一直是行业里面都在关注的点。
端到端的难点在哪里?
端到端的优势非常突出,但仍然有很多难点需要攻克。主要在于数据难定义、数据难制作、网络不好训练、模型不好解释优化、评测定义多种多样!很多公司无法像特斯拉一样获取海量数据,这也是个巨大的瓶颈。今年年中,自动驾驶之心收到了很多同学关于端到端实战相关的需求,虽然我们已经筹备过相关的内容,但早期端到端方案不够成熟,更多是以论文切入。工业界使用的方案关注较少,代码层面上也很少提及。
欢迎扫码加入学习!

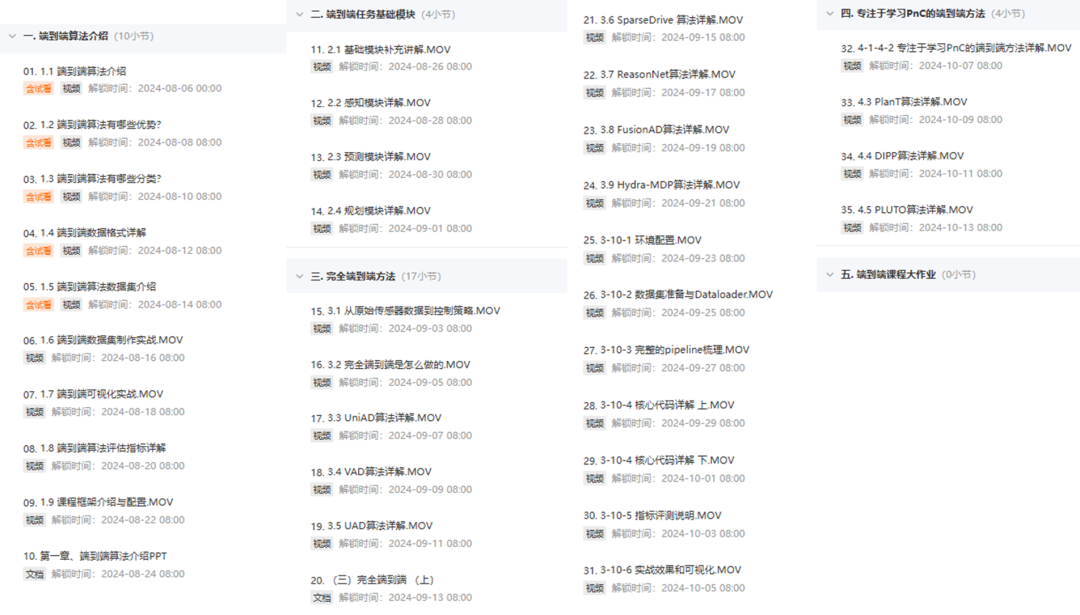
自动驾驶之心在调研大家的需求后,联合自动驾驶之心课研团队,出品了国内首个《面向工业级的端到端自动驾驶算法与实战》,主讲老师是一线头部自动驾驶公司端到端算法工程师。大纲如下:

课程目前已经基本完结,欢迎大家随时加入学习~~~
交流群内日常沟通一览~~
这门课程怎么将会展开?
课程对领域常用的纯视觉完全端到端方案、多模态完全端到端方案、专注于planner的端到端方案会有较深入的剖析。每种方法论会配有一个对应实战,让大家不仅仅明白算法是怎么做的,还要搞懂实现细节。最后将会有课程大作业,带着大家从零一起搭建一套端到端方案。
本门课程面向在校从事自动驾驶研究方向的硕士、博士,以及正在从事端到端算法研究的工作人员、想要转入端到端研究方向的同学,正在准备相关方向岗位的校招、社招同学,需要项目来提升自己的同学;
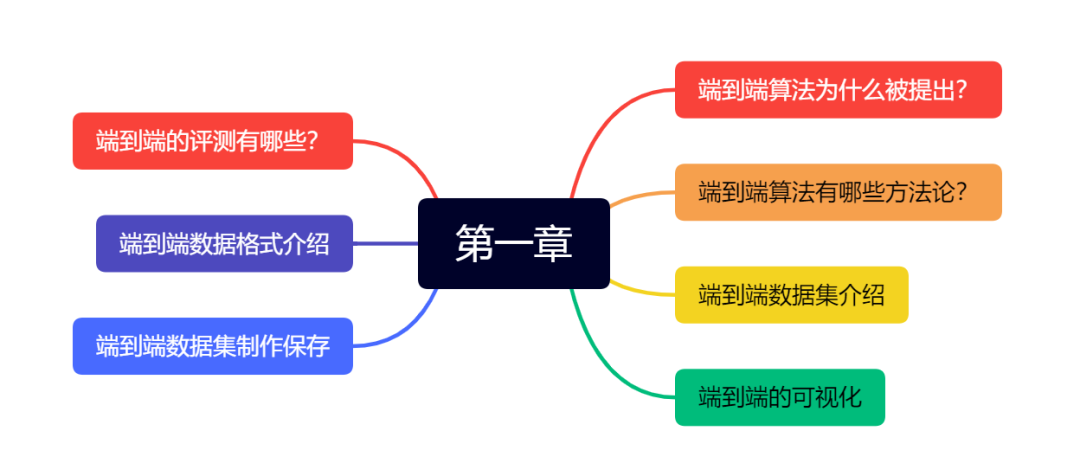
第一章 端到端算法基础
第一章为基础篇,主要为大家带来端到端基础相关内容,这一部分我们会从端到端的提出、端到端的分类、以及端到端数据集相关内容展开,大家比较关注的端到端数据集格式以及后续自己数据集的制作都会有涉及哦。除此之外,端到端输出结果的可视化也会提供给大家脚本。最后会为大家带来端到端模型学术界与工业界是怎么评测!
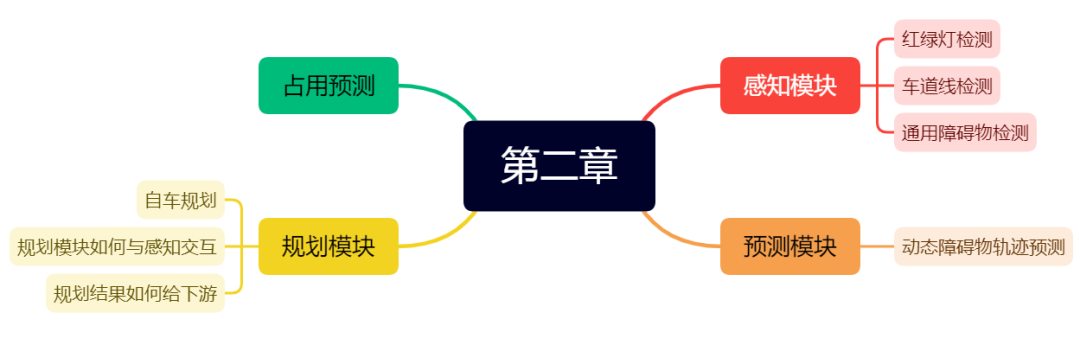
第二章 端到端任务基础模块
第二章主要给大家介绍端到端任务的基础模块,感知模块的输出有哪些?白名单策略是什么?预测模块的输入输出是什么?自车如何规划,规划和感知如何交互?规划结果如何给下游使用等等!
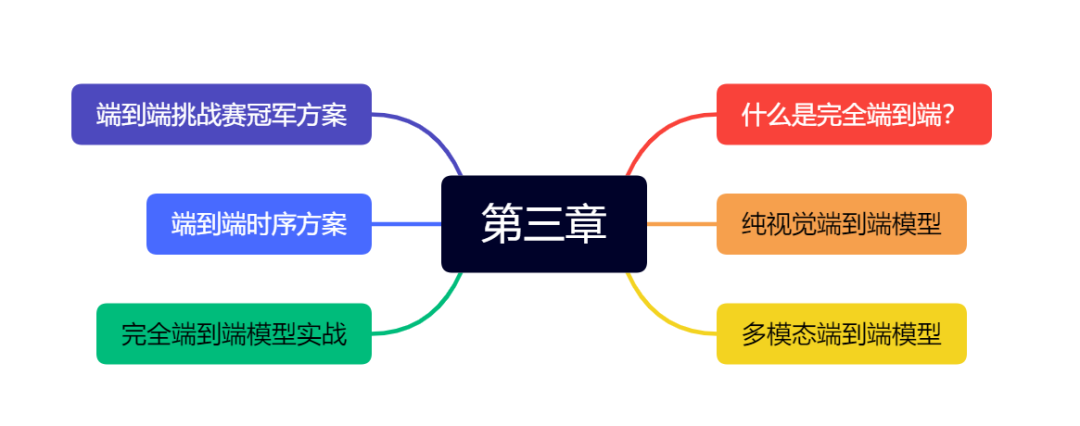
第三章 完全端到端方法
第三章主要为大家介绍从传感器数据到控制策略的完全端到端方法,包括纯视觉方案、多模态方案以及时序方案等等。本章最后一部分,将为大家带来完全端到端方案UniAD的实战,从环境配置、Dataloader、核心代码到指标评测和可视化,为大家梳理一套完整的端到端方案。
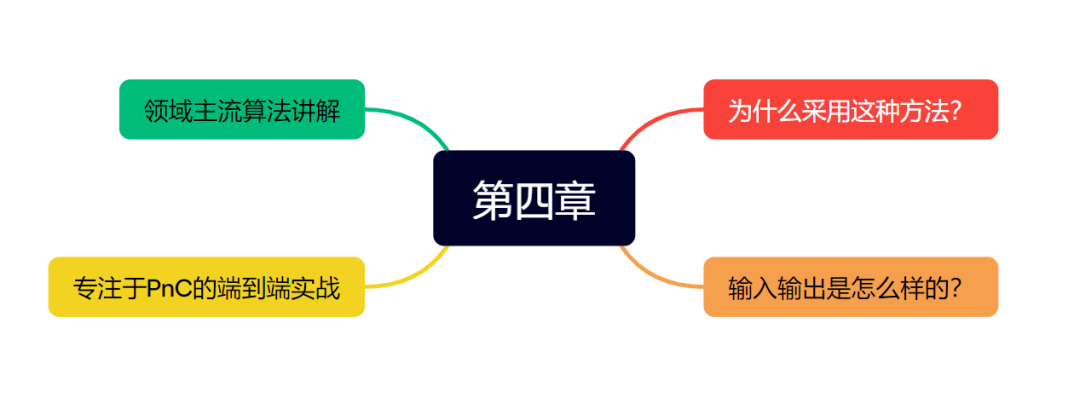
第四章 专注于学习PnC的端到端方法
第四章主要为大家带来专注于学习PnC的端到端方法,这类方法是目前车企投入研发较多的方案,更能衔接原有方案,解释性也相对更强。本章为大家带来了行业里比较经典的几种方法,并在最后部分带大家完成基于palnT算法的实战,从环境配置、Dataloader、核心代码到指标评测和可视化,为大家梳理一套完整的端到端方案。
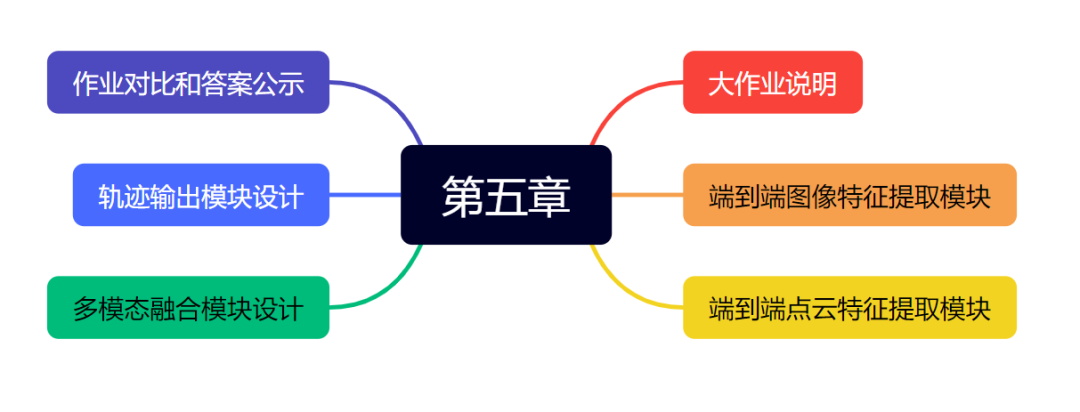
第五章 端到端课程大作业
第五章主要是大作业部分,课程大作业会带着大家从基础的数据读取、特征提取到多模态融合和轨迹输出预测完整的实现一遍,最后给出对应的参考代码和答案,也为大家增加相关的项目实践,助力简历上有更突出的端到端项目。
主讲老师介绍
kk老师,硕士毕业于中科院,某头部自动驾驶头部公司算法工程师,深耕自动驾驶算法领域多年。在人工智能领域发表多篇顶会论文,担任多个国际期刊审稿人,在自动驾驶算法设计、模型优化部署方面有着丰富的落地经验。
学习基础
需要自备GPU,推荐算力在3060及以上;
一定的自动驾驶领域基础,熟悉自动驾驶的基本模块;
一定的概率论和线性代数基础,熟悉常用的数学运算;
具备一定的python和pytorch语言基础;
学后有什么收获?
这门课程是首个面向端到端的算法与实战教程,我们期望能够推动端到端在工业界中的落地,助力更多想要加入到自动驾驶行业的同学真正理解端到端。我们期望学完本课程:
学完能够达到1年左右端到端自动驾驶算法工程师水平;
对端到端的上下游、完整的技术栈有着深刻了解;
能够将所学应用到项目中,真正搞懂如何设计自己的端到端模型;
无论是实习、校招、社招都能从中受益;
课程咨询与购买
欢迎扫码加入学习!

更多咨询小助理

其他说明
录播形式教学,vip群内答疑。购买后,3天内支持退款。

















 203
203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









