






作者 | 白鹡鸰 编辑 | 自动驾驶之心
原文链接: https://zhuanlan.zhihu.com/p/1896300972759810380
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『规划控制』技术交流群
本文只做学术分享,如有侵权,联系删文
大家好久不见,这里是白鹡鸰!今天带着我们刚刚被T-ITS接收的论文,来线上冒个泡~
简介
如何融合规则方法与学习方法的优势,实现高效、鲁棒且通用的路径规划,是自动泊车任务面临的关键挑战。本文提出了一种基于强化学习的混合策略路径规划器(HOPE: Hybrid pOlicy Path plannEr),在模拟与真实场景中均表现优异:在各类生成/来自真实数据集的狭窄平行泊车和垂直泊车场景中规划成功率超过97%,显著优于传统方法。实车场景测试中,本文算法还成功应对了“断头路垂直泊车”等未训练过的复杂场景,验证了其泛化能力与工程实用性。
论文:HOPE: A Reinforcement Learning-Based Hybrid Policy Path Planner for Diverse Parking Scenarios
代码:https://github.com/jiamiya/HOPE
研究背景
自动泊车是提升驾驶安全性与效率的关键技术,但复杂多变的泊车场景对传统路径规划方法提出了巨大挑战。基于规则的几何或采样搜索方法在简单常见场景中表现可靠,但在狭窄车位或障碍物密集的环境中易陷入局部最优甚至规划失败。学习型方法(如强化学习)虽具备环境理解与探索能力,但训练效率低且难以稳定收敛。此外,近年来相关研究多局限于有限数量和种类的场景,泛化能力不足,且面临训练效率与部署安全性的难题。如何融合规则方法与学习方法的优势,实现高效、鲁棒且通用的泊车路径规划,成为亟待解决的核心问题。
方法介绍
针对上述挑战,本文提出了一种基于强化学习的混合策略路径规划器。通过将强化学习策略与Reeds-Shepp曲线结合,在训练中通过规则方法引导智能体探索,提升训练效率与最终成功率。此外,为了应对神经网络策略安全性问题,本文设计了一种动作掩码方法,通过计算和编码碰撞约束,显著减少训练中的无效探索,并确保规划路径的安全性。
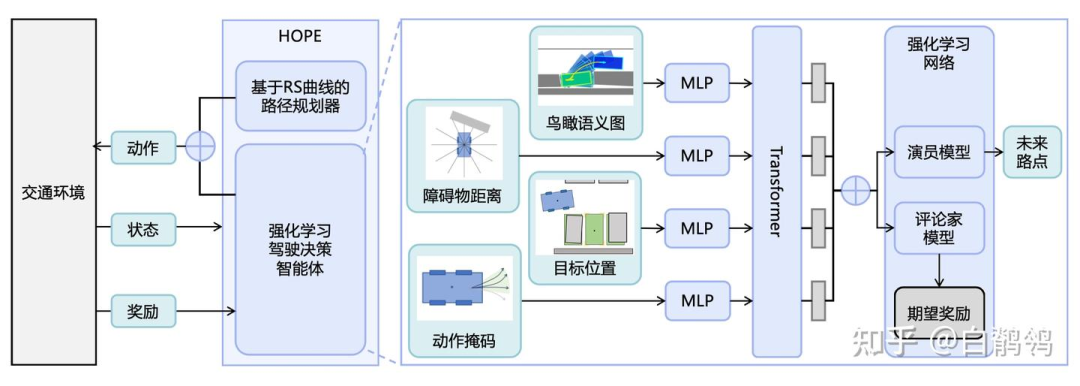
如果对方法实现细节感兴趣,请阅读我们的论文和附录,其中包括且不限于:
泊车场景中RS曲线类别选择
RS曲线与强化算法的结合方法
强化学习算法选择(PPO vs. SAC)效果对比
强化学习奖励函数的具体设计
动作掩码的具体设计
HOPE训练流程
实验场景设计
对于泊车任务来说,除却算法本身的设计,搭建合理的测试流程,证明算法的有效性是我们遇到的另一问题。由于目前缺少具有公信力的评价体系,我们参考《智能泊车辅助系统性能要求及试验方法》[1]自行搭建了一套泊车场景难度的划分规则:
简单场景
平行泊车:目标车位距离侧面障碍物的最小距离大于4.5米,车位前后距离为max(车长+1.0米,1.25*车长);
垂直泊车:目标车位距离前后障碍物的最小距离大于7.0米,车位左右总宽度大于车宽+0.85米;
复杂场景
平行泊车:目标车位距离侧面障碍物的最小距离大于4.0米,车位前后距离为max(车长+0.9米,1.2*车长);
垂直泊车:目标车位距离前后障碍物的最小距离大于6.0米,车位左右总宽度大于车宽+0.4米;
极端场景:
平行泊车:目标车位距离侧面障碍物的最小距离大于3.5米,车位前后距离为max(车长+0.6米,1.1*车长);
垂直泊车:暂无意义(车款+0.2米的话,驾驶员无法开门,虽然自车可以离车泊入,但是你能保证左右两边的车主不骂你吗?)
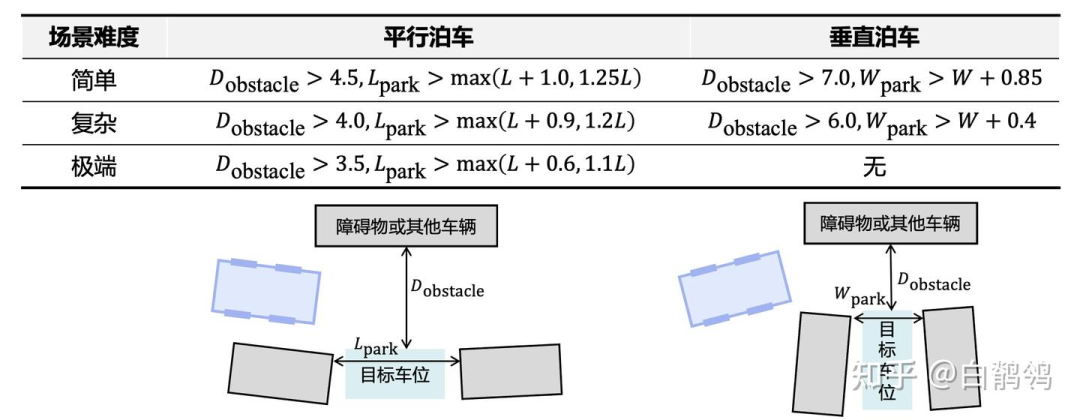
基于上述规则,我们使用Tactics2D[2]的原型随机生成了大量泊车场景,并筛选了DLP数据集[3]中的泊车场景作为HOPE的训练和测试数据。
实验结果
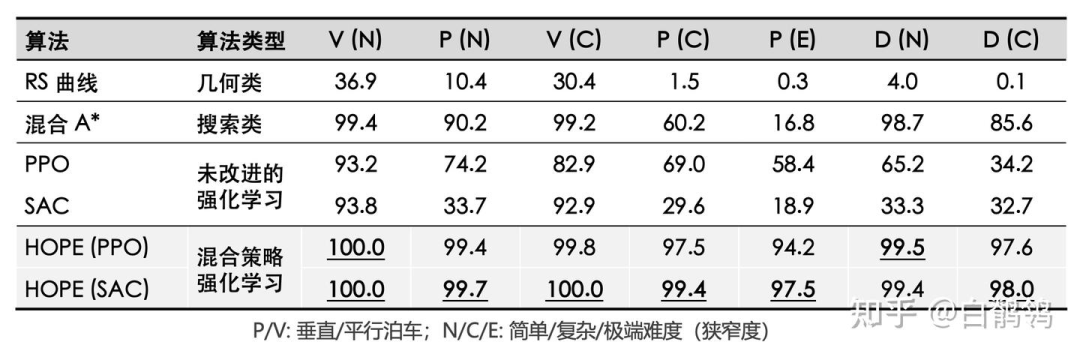
我们选取了如下算法作为比较基线:
RS曲线规划:几何类方法的代表
混合A* 算法:已在工业界落地的搜索类算法
PPO和SAC(未改进)
可以看出,HOPE在各种难度和类型的泊车场景中,成功率都高于基线算法,且稳定在90%以上。越是困难的泊车场景,越能展现HOPE算法的优势。
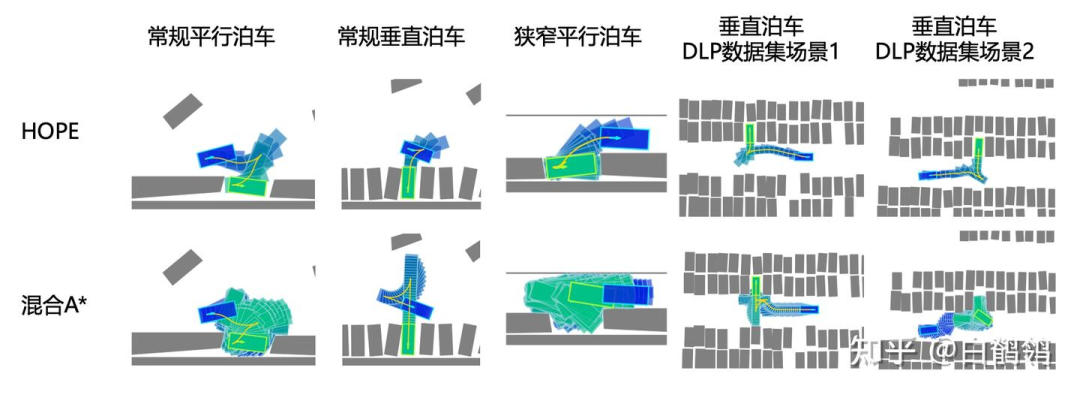
通过可视化HOPE和混合A* 算法生成的泊入轨迹,可以看出,HOPE的轨迹通常更加简洁高效。
实车场景测试中,本文算法成功应对“断头路垂直泊车”等未训练过的复杂场景,验证了其泛化能力与工程实用性。
参考
智能泊车辅助系统性能要求及试验方法 https://www.catarc.org.cn/upload/202012/29/202012290852465712.pdf
Tactics2D: A Highly Modular and Extensible Simulator for Driving Decision-Making https://ieeexplore.ieee.org/abstract/document/10561544
ParkPredict+: Multimodal Intent and Motion Prediction for Vehicles in Parking Lots with CNN and Transformer https://ieeexplore.ieee.org/abstract/document/9922162
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 1130
1130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









