






作者 | 刘伟杰 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/566618077
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『扩散模型』技术交流群
本文只做学术分享,如有侵权,联系删文
1. 前言
DDPM可用于由随机噪声生成图片,其效果堪比甚至优于GAN、VAE等模型。近年大火的多种扩散模型都是以此为基础的。一讲到扩散模型DDPM,很多博客上来就是堆公式推导,用变分推断和隐变量模型将读者砸晕,让读者望而生畏。笔者在琢磨了一段时间后,剥离那些复杂的公式,将要点总结于此,如果有错误的地方,欢迎批评指正。
2. DDPM模型要点
对于使用者只需要理解前向过程、反向过程、如何训练和如何使用这四点即可。
2.1 前向过程(扩散)
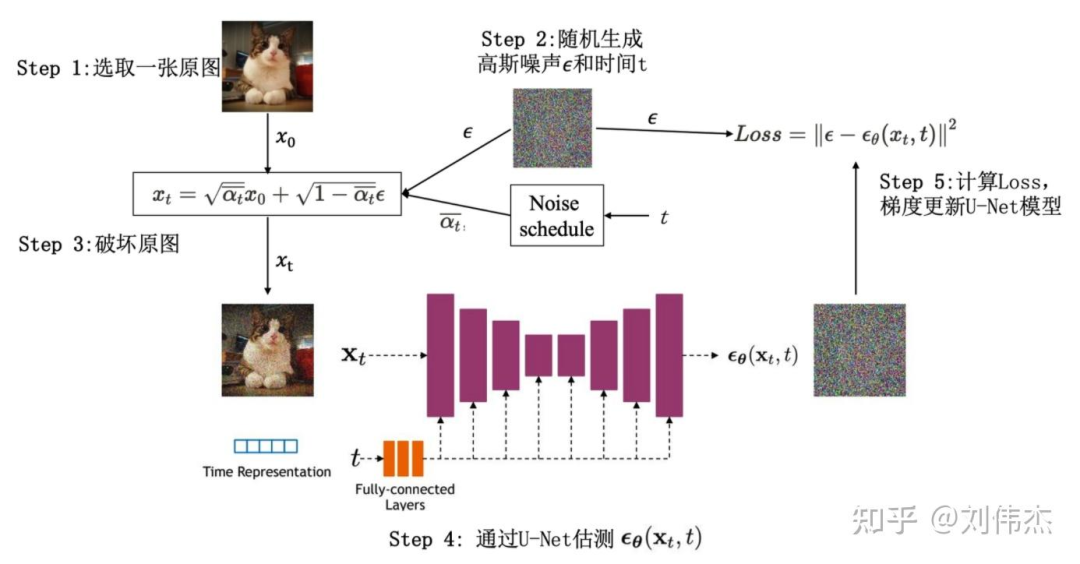
前向过程(forward process)又称为扩散过程(diffusion process),简单理解就是对原始图片 通过逐步加高斯噪声变成 ,从而达到破坏图片的目的,如下图
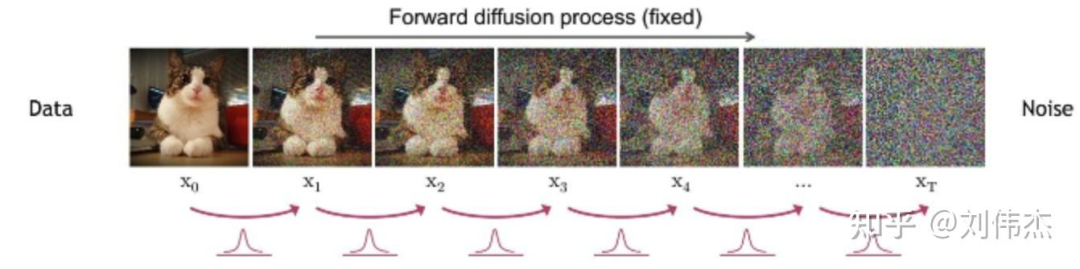
用公式表示就是
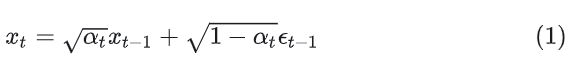
其中 是预先设定好的超参数,被称为Noise schedule,通常是一些列很小的值。 是高斯噪声。由公式(1)迭代推导,可以直接得出 到 的公式(详细过程可见[2]),如下,
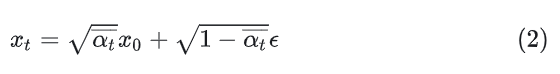
其中 ,这是随Noise schedule设定好的超参数, 也是一个高斯噪声。公式(1)或(2)就可以用来描述前向过程了,(1)用于将一张图片逐步破坏,(2)用于一步到位破坏。
2.2 反向过程(去噪)
反向过程就是通过估测噪声,多次迭代逐渐将被破坏的 恢复成 ,如下图

用公式表示就是
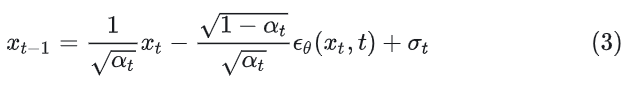
由于公式(2)中的真实噪声 在复原过程中不允许使用,因此DDPM的关键就是训练一个由 和 估测噪声的模型 ,其中 就是模型的训练参数, 也是一个高斯噪声 ,用于表示估测与实际的差距。在DDPM中,使用U-Net作为估测噪声的模型。
2.3 如何训练(获得噪声估计模型)
上文提到,DDPM的关键是训练 模型,使其预测的 与真实用于破坏的 相近,用L2距离刻画相近程度就好,因此我们的Loss就是如下公式。
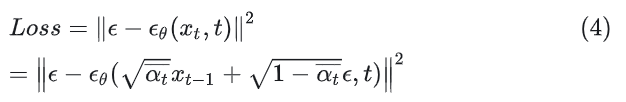
训练过程如下图描述。
用原论文中的伪代码表示也很容易理解。

这里有读者会有疑问,在训练过程中 表示的是从t到t-1时刻的噪声,而却用0到t的真实噪声 进行拟合,会不会有些不妥呢? 我的理解是0到t的真实噪声 只是指导方向,方向大概正确即可,后续用于生成时也不要求恢复出原图,只要能生成一个可看的图片即可,所以这样做是可以的。
2.4 如何使用(生成图片)
在得到噪声估测模型 后,想要生成模型就很简单了。从N(0,1)中随机生成一个噪声作为 ,然后再用该模型逐步从估测噪声,并用去噪公式逐渐恢复到 即可,见如下伪代码。

贴一些论文里生成的图片看一看,效果还是很惊艳的(论文实验的超参数 , )。

3. 总结DDPM
DDPM就是训练一个噪声估计模型 ,然后由一个随机噪声迭代生成图片。在训练模型时,先随机生成噪声 ,然后用此噪声破坏模型,再用破坏的图片预估噪声 ,期望预估的噪声与真实的噪声相近。想要深入理解DDPM,推荐看[1][2][3]三篇文献。
References
[1] Denoising Diffusion Probabilistic Models,https://arxiv.org/pdf/2006.11239.pdf
[2] 小小将, 扩散模型之DDPM,https://zhuanlan.zhihu.com/p/563661713
[3] 苏剑林,生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼,https://zhuanlan.zhihu.com/p/53
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 1175
1175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









