









CVPR2016
Learning Deep Representations of Fine-Grained Visual Descriptions
code: https://github.com/reedscot/cvpr2016
本文提出了一个模型,可以用来干什么了?就是给你一句话,搜出满足这句话的图像

怎么实现这个目标了?
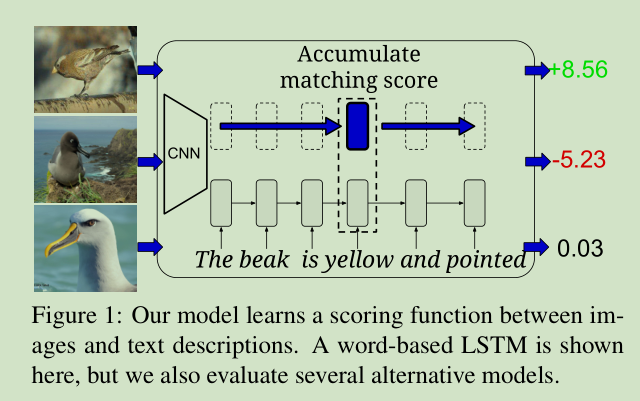
分别对图像 和 语句使用 CNN网络,提取出对应的特征,然后结合起来,给出每个图像满足这句话的概率。如上图所示,语义信息是 The beak is yellow and pointed。 使用 CNN网络对 每个图像提取特征,然后计算出每个图像满足该语义信息的概率。
本文主要提出了一个新的 CNN模型来提取语义信息特征的。如下图所示:
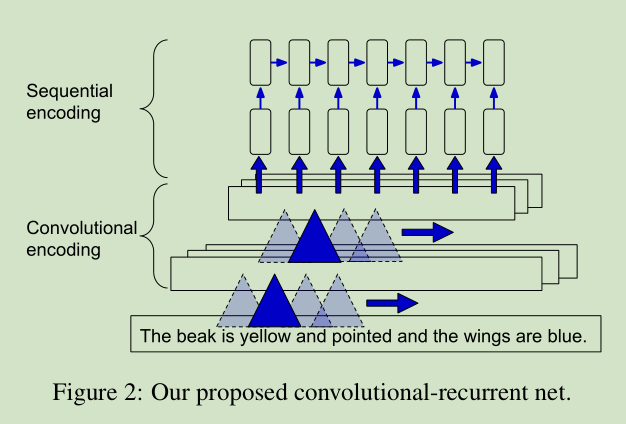
这里主要是将 recurrent models and CNNs 结合起来,先使用CNN提特征,再将特征给 recurrent models,如上图所示。
结果如下图所示:
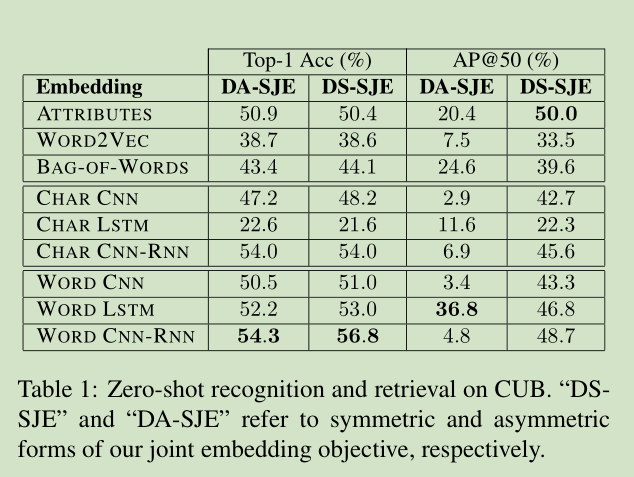
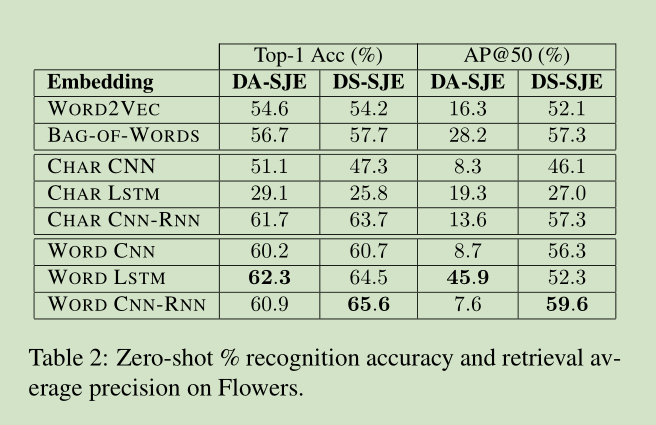















 3796
3796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









