








CVPR 2016
本文主要是解决图像中的文字定位问题的。将每个文字看做 Canny 算法中的边缘像素,用 Canny 边缘提取的思路来检测文字。
先上图看一下我们算法和其他算法的对比:

算法的流程如下:
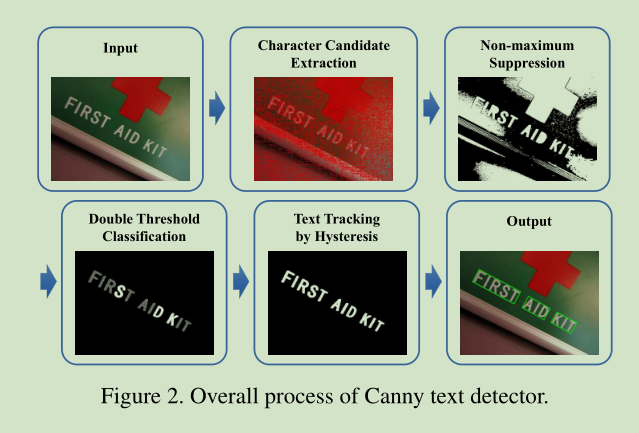
1)使用一个 MSER变体算法提取字符候选区域。
2)每个候选字符使用 AdaBoost classifier 评估一下,这里使用了双阈值,
得到强候选字符和弱候选字符
3)根据字符规则出现,使用hysteresis 将 可靠的字符找出来。
4) 字符组词或组句。
1) We first extract character candidates using
a variant of MSER.
2)Then, each candidate is evaluated using an AdaBoost classifier trained with a sort of local binary patterns. The classification step utilizes double threshold
to determine strong and weak candidates
3)after applying tracking by hysteresis, credible characters are finally selected.
4)The surviving characters are grouped into words or sentences.



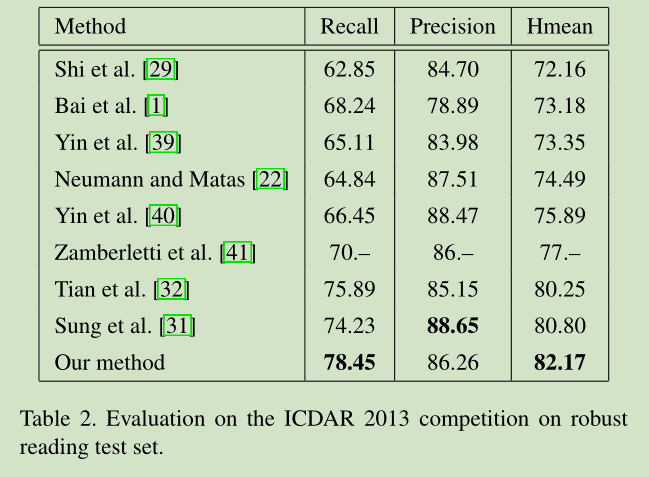
结果如下:
















 3963
3963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









