





CP-VITON:基于图像的特征保留虚拟试衣网络
原文链接:https://arxiv.org/pdf/1807.07688.pdf
1、引言
虚拟试衣使得用户能够在不用进行物理穿戴的情况下体验穿衣效果,因此,用户能够迅速的确定是否喜欢一件衣服然后决定是否进行购买。传统的方法是使用计算机图形学的方法进行3D建模,这种方法能够进行精确地几何变换和物理约束,但是需要大量人工和昂贵的设备去收集进行3D建模的信息,也会消耗大量的计算。
基于图像的虚拟试穿系统,将虚拟试穿转化为条件图像生成问题,提供了一种更经济的方法,也实现了比较好的结果。
给定两张图片:一张是人,另一张是商店里的衣服,上述方法的目的是合成一张满足以下要求的图像:
- 人穿着新的衣服
- 原始的身体和姿态都得到了保留
- 衣服被填充到了人体上,并且能够实现保真、平滑、无缝
- 衣服的特征,比如质地,logo,文字都被良好的保留,并且没有醒目的变形和缺陷。
条件图像生成技术在当前取得了很多研究进展,使得其自然而然地成为解决上述问题的一种方法。除了pixel-to-pixel losses和perceptual loss,adversarial losses也被用来减轻图片模糊的问题,但是仍然会丢失重要的细节。此外,这些方法只能应对输入-输出对大概对齐的案例,图像有较大变换时会产生失败。这些限制阻碍了其在虚拟试穿的应用。其中一个原因是在面对大型变换时较差的细节保留能力,比如非对齐的图片。在虚拟试穿里条件图像生成最好的实践是一个二阶的pipeline VITON,但是它的表现仍与预期效果差距较大。需要强调的是,我们认为主要原因在于,为了对齐衣物和身体形状使用了的不完美的形状-背景匹配,还有较差的的外观融合策略。
为了解决上述挑战,提出了一种新的方法。不同于手工进行形状背景匹配,通过使用一个裁剪的卷积神经网络,提出了一种可学习的thin-plate spline变换,为了实现衣物与目标人体良好的对其。网络的参数通过成对的图像(商店衣服和一个试穿者)训练,不需要任何显式的兴趣点对应。第二,模型将对齐的衣服和与衣服无关的描述性人物表示作为输入,并生成一个和原始人物姿态一致的图像,以及一个合成掩膜(mask),该掩膜表示合成图像中保留的对齐的衣服的细节。掩膜尝试利用对齐衣物中的信息,平衡合成图像的平滑度。广泛的实验表明提出的模型能够解决大形状和姿态变换,在VITON数据集上实现最先进的结果。
2、图像合成相关工作
cGANs(conditional GANs)在image-to-image转换方面取得了很好地结果, image-to-image的目标是将衣服图片从一个域转化到另一个域。与经常导致图像模糊的L1/L2损失相比,对抗性损失对image-to-image任务来说是一个流行的选择。最近的研究表明,对抗性损失对于高分辨率图像生成来说可能是不稳定的。我们发现对抗性损失对于我们的模型来说几乎没有改进。在image-to-image任务中一个隐含的假设是输入与输出图像基本上是对齐的,他们有相同的隐含的结构。然而,大多数方法在条件图像和输出图像之间有较强的空间畸变时都会产生问题。大多数条件输入非对齐图像的image-to-image转换任务采用coarse-to-fine的方法来增强结果的质量。VITON计算商店衣物和预测前景掩膜之间的shape context thin-plate spline(TPS) transofrmation ,非常耗时,容易出错。我们使用CNN预测TPS实现这个功能。

3、特性保留虚拟试衣网络(Characteristic-Preserving Virtual Try-On Network)
3.1人物表示(Person Representation)
原始的衣服不可知(cloth-agnostic)人物表示
p
p
p目的是丢弃原始衣服
c
i
c_i
ci的效果,比如颜色、质地、形状等,与此同时尽可能保留输入任务
I
i
I_i
Ii的信息,包括人物的脸,头发,身体形状和姿态。
p
p
p包含三个部分:
——姿态热度图(Pose heatmap):一个18通道的特征图,每个通道对应了一个人体姿态的关键点,用
11
×
11
11\times11
11×11的白色矩形表示
——身体形状(Body shape):一个1通道的模糊二值掩码特征图,粗略的覆盖了人体的不同部位
——保留区域(Reserved regions):一个包含了人体保留区域的RGB图像,为了维持人的特征,包括脸和头发



3.2几何匹配模块(Geometric Matching Module)
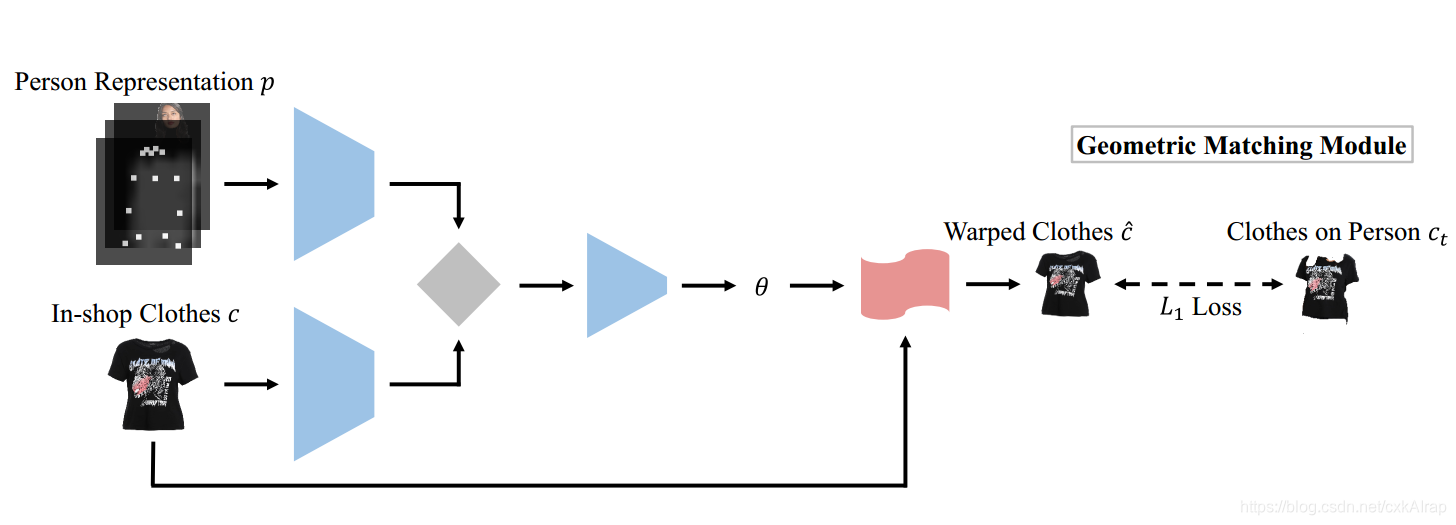
设计了一个几何匹配模块Geometric Matching Module (GMM)将目标衣服
c
c
c变换成变形后的衣服
c
^
\hat c
c^,
c
^
\hat c
c^能粗略的与输入任务特征
p
p
p对齐。GMM模块由四个部分组成:
(1)两个分别用于提取
p
p
p和
c
c
c高层次特征的卷积网络
(2)一个相关层,用于将两个特征结合成一个张量作为回归网络的输入
(3)回归网络,用于预测空间变换参数
θ
\theta
θ
(4)Thin-Plate Spline (TPS)变换模块,用于将输入衣服
c
c
c通过参数
θ
\theta
θ变换为变形后的衣服
c
^
\hat c
c^,即
c
^
=
T
θ
(
c
)
\hat c=T_\theta(c)
c^=Tθ(c)。
整个流程是端到端可学习的,使用
(
p
,
c
,
c
t
)
(p,c,c_t)
(p,c,ct)进行训练,使用的损失是
c
^
\hat c
c^和
c
t
c_t
ct之间的逐像素的
L
1
L_1
L1损失,其中
c
t
c_t
ct是目标人物
I
t
I_t
It身穿的衣服。
Loss:
L
G
M
M
(
θ
)
=
∣
∣
c
^
−
c
t
∣
∣
1
=
∣
∣
T
θ
(
c
)
−
c
t
∣
∣
1
\mathcal L_{GMM}(\theta) = ||\hat{c} - c_t||_1 = ||T_{\theta}(c) - c_t||_1
LGMM(θ)=∣∣c^−ct∣∣1=∣∣Tθ(c)−ct∣∣1

3.3试衣模块(Try-on Module)
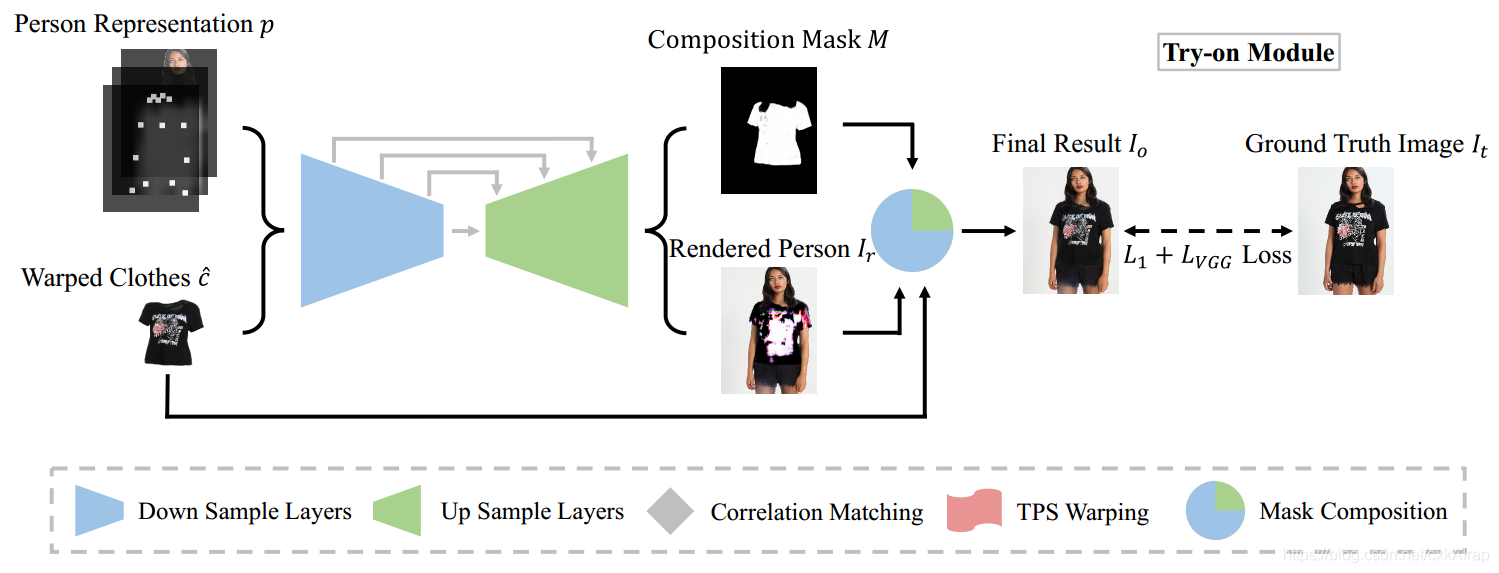
既然变形后的衣服
c
^
\hat c
c^已经大概和人体形状对齐,接下来的目标就是将它融合到目标人物上,合成最终试衣的结果。
一种直接的想法是直接将
c
^
\hat c
c^贴到人物上,好处是衣服的所有细节都被保留,但是会导致不自然的边界。另一种方法是将
c
^
\hat c
c^送入一个编解码网络,比如UNets,想以此来生成平滑无缝的图像。但是,想要完美的将衣服与目标人体对齐是不可能的,由于缺少明确的空间变换能力,即使是微小的不对齐也会使UNet的输出模糊。
TOM结合了以上两种方法。将人体特征表示
p
p
p和变形后的衣服
c
^
\hat c
c^使用UNet同时生成人物图像
I
r
I_r
Ir和一个掩码
M
M
M。然后使用掩码
M
M
M对
c
^
\hat c
c^和
I
r
I_r
Ir进行融合生成最终的试衣结果
I
o
I_o
Io:
I
o
=
M
⊙
c
^
+
(
1
−
M
)
⊙
I
r
I_o = M\odot \hat{c} + (1-M)\odot I_r
Io=M⊙c^+(1−M)⊙Ir,
⊙
\odot
⊙代表的是点乘
在训练阶段,给定三元样本
(
p
,
c
,
I
t
)
(p,c,I_t)
(p,c,It),TOM的目标是最小化网络输出
I
o
I_o
Io与ground truth
I
t
I_t
It之间的差距。这里使用的是在图像生成问题中被广泛采用的方法:结合
L
1
L_1
L1损失与VGG perceptual损失,VGG perceptual损失通过如下方法定义:
L
V
G
G
(
I
o
,
I
t
)
=
Σ
i
=
1
5
λ
i
∣
∣
ϕ
i
(
I
o
)
−
ϕ
i
(
I
t
)
∣
∣
1
\mathcal L_{VGG}(I_o,I_t)=\Sigma_{i=1}^5\lambda_i||\phi_i(I_o)-\phi_i(I_t)||_1
LVGG(Io,It)=Σi=15λi∣∣ϕi(Io)−ϕi(It)∣∣1
其中
ϕ
i
(
I
)
\phi_i(I)
ϕi(I)指的是视觉感知网络
ϕ
\phi
ϕ(其实就是在ImageNet上预训练过的VGG19)关于输入图像
I
I
I的第
i
i
i层特征图。
为了实现衣物特征保留的目的,在掩码
M
M
M上应用
L
1
L_1
L1正则化
∣
∣
1
−
M
∣
∣
1
||1-M||_1
∣∣1−M∣∣1,使得变形后的衣服
c
^
\hat c
c^能够保留尽可能多的特征。TOM的总体损失如下:
L
T
O
M
=
λ
L
1
∣
∣
I
o
−
I
t
∣
∣
1
+
λ
v
g
g
L
V
G
G
(
I
^
,
I
)
+
λ
m
a
s
k
∣
∣
1
−
M
∣
∣
1
\mathcal L_{TOM} = \lambda_{L_1}||I_o-I_t||_1 + \lambda_{vgg}\mathcal L_{VGG} (\hat I,I)+\lambda_{mask}||1-M||_1
LTOM=λL1∣∣Io−It∣∣1+λvggLVGG(I^,I)+λmask∣∣1−M∣∣1


















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









