






模型的微调一直是提升模型性能以适应特定任务的关键手段。然而,随着模型规模的不断扩大,传统的全量微调方法面临着资源消耗大、训练时间长等问题。低秩自适应(LoRA)技术的出现,为解决这些问题提供了一种高效的解决方案。
一、LoRA的基本原理
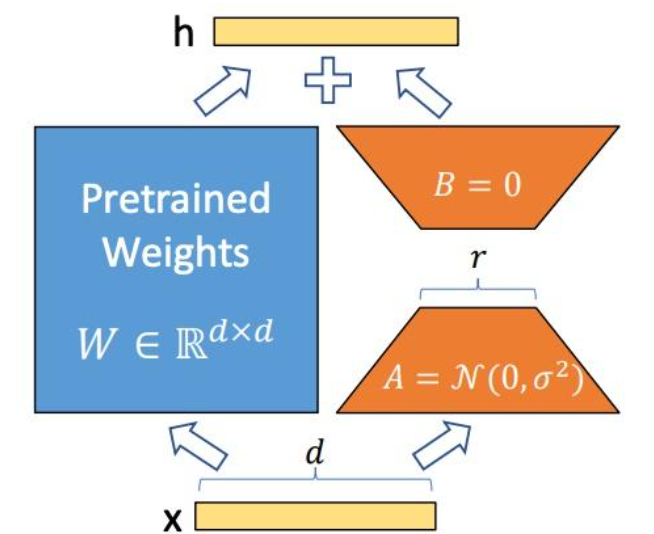
LoRA通过低秩分解来模拟参数的改变量,从而以极小的参数量实现大模型的间接训练。其核心思路是冻结预训练模型的矩阵参数,引入可训练的低秩矩阵A和B,在下游任务训练时仅更新A和B。在推理阶段,将BA加到原参数上,不引入额外的推理延迟。这种设计使得LoRA在保持模型性能的同时,大大减少了可训练参数的数量。
二、LoRA的优势与局限
2.1 优势
1. 参数存储优化:一个中心模型可服务多个下游任务,显著节省参数存储量。
2. 推理效率提升:推理阶段不引入额外计算量,几乎不增加推理延迟,因为适配器权重可与基本模型合并。
3. 方法组合灵活:与其它参数高效微调方法正交,可有效组合。
4. 训练稳定性高:训练任务表现稳定,效果良好。
2.2 局限
存在 LoRA参与训练的模型参数量有限,通常在百万到千万级别,因此在数据和算力充足的情况下,其效果相较于全量微调仍有差距。
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

三、LoRA的训练理论要点
3.1 权重合并
LoRA权重可合入原模型,即将训练好的低秩矩阵(B*A)与原模型权重相加,得到新的权重。
3.2 微调加速原理
1. 部分参数更新:如原论文选择只更新Self Attention的参数,实际也可选择只更新部分层的参数。
2. 通信时间减少:更新参数量减少,多卡训练时传输数据量降低,传输时间随之减少。
3. 低精度加速技术应用:采用FP16、FP8或INT8量化等技术加速训练。
3.3 继续训练策略
若已有LoRA模型仅训练了部分数据,可将之前的LoRA与base model合并后继续训练,同时加入部分之前的训练数据,以保留知识和能力,避免从头训练带来的高成本。
3.4 与全参数微调对比
在计算资源充足且数据量达10k以上时,全参数微调效果更佳。LoRA虽能在消费级GPU上训练,但训练时间更长,且在大量数据训练下,可训练参数量小导致效果不如全量微调。
3.5 LoRA作用于Transformer的参数矩阵选择
不应将所有微调参数置于attention的某一个参数矩阵,而应将可微调参数平均分配到Wq和Wk,效果最佳。即使秩取4,也能在∆W中获取足够信息。
3.6 微调参数量确定
LoRA模型中可训练参数数量取决于低秩更新矩阵大小,由秩r和原始权重矩阵形状决定,实际可通过选择不同的lora_target控制训练参数量。
3.7 Rank选取
Rank常见取值为8,理论上4 - 8之间效果较好,更高取值提升不明显。但在指令微调中,需根据指令分布广度,在8以上取值测试。
3.8 alpha参数选取
alpha为缩放参数,本质与learning rate相同,可默认alpha = rank,仅调整lr以简化超参。
3.9 避免过拟合
可通过减小r或增加数据集大小减少过拟合,也可尝试增加优化器的权重衰减率或LoRA层的dropout值。
3.10 内存使用影响因素
内存使用受模型大小、批量大小、LoRA参数数量及数据集特性影响,使用较短训练序列可节省内存。
3.11 LoRA权重合并
多套LoRA权重可合并,训练时保持独立,前向传播时相加,训练后合并权重简化操作。
3.12 逐层调整LoRA的最优rank
理论上可行,但实际中因增加调优复杂性很少执行。
3.13 Lora矩阵初始化
矩阵B初始化为0,矩阵A采用高斯分布初始化,此方式可在训练开始时维持网络原有输出,同时保证后续学习能更好收敛。若B、A均初始化为0,易导致梯度消失;若均高斯初始化,训练初期可能因偏移值过大引入过多噪声,难以收敛。
四、微调与推理示例
这里给出一个基于Transformer的模型进行微调和推理示例
4.1 微调
import torch
from torch import nn
from transformers import BertModel, BertTokenizer
# 假设我们有一个预训练的BERT模型
pretrained_model_name = 'bert-base-uncased'
model = BertModel.from_pretrained(pretrained_model_name)
# 定义LoRA模块
class LoRA(nn.Module):
def __init__(self, model):
super(LoRA, self).__init__()
self.model = model
# 为每个Transformer层的自注意力部分添加LoRA
for i, layer in enumerate(model.encoder.layer):
self.add_module(f'lora_layer_{i}', LoRALayer(layer.attention.self))
def forward(self, input_ids, attention_mask):
return self.model(input_ids, attention_mask=attention_mask)
class LoRALayer(nn.Module):
def __init__(self, attention):
super(LoRALayer, self).__init__()
self.attention = attention
# 假设我们使用秩为4的LoRA
self.rank = 4
self.B = nn.Parameter(torch.randn(self.rank, attention.in_proj_weight.shape[1]))
self.A = nn.Parameter(torch.randn(attention.in_proj_weight.shape[0], self.rank))
def forward(self, hidden_states, attention_mask):
# 计算LoRA的增量矩阵
delta = torch.matmul(self.B, self.A)
# 将增量矩阵应用到自注意力的权重上
self.attention.in_proj_weight = nn.Parameter(self.attention.in_proj_weight + delta)
# 正常的自注意力计算
outputs = self.attention(hidden_states, attention_mask=attention_mask)
# 将增量矩阵移除,恢复原始权重
self.attention.in_proj_weight = nn.Parameter(self.attention.in_proj_weight - delta)
return outputs
# 初始化LoRA模块
lora_model = LoRA(model)
# 准备数据集和优化器
# 假设我们有一个下游任务的数据集和对应的tokenizer
tokenizer = BertTokenizer.from_pretrained(pretrained_model_name)
# ... 数据加载和预处理代码 ...
# 定义损失函数和优化器
optimizer = torch.optim.Adam(lora_model.parameters(), lr=1e-5)
# 训练循环
for epoch in range(num_epochs):
for batch in dataloader:
input_ids, attention_mask, labels = batch
optimizer.zero_grad()
outputs = lora_model(input_ids, attention_mask)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
4.2 推理
import torch
from transformers import BertTokenizer
# 假设我们已经完成了LoRA模型的微调,并且保存了模型参数
model_path = 'path_to_saved_lora_model' # 微调后的LoRA模型路径
lora_model = LoRA(model) # 使用与训练相同的LoRA模型结构
lora_model.load_state_dict(torch.load(model_path)) # 加载微调后的模型参数
lora_model.eval() # 将模型设置为评估模式
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') # 加载与预训练模型相同的tokenizer
# 定义一个函数来进行推理
def infer_with_lora_model(input_text, model, tokenizer):
# 将输入文本编码为模型可以理解的格式
input_ids = tokenizer.encode(input_text, return_tensors='pt')
attention_mask = torch.ones_like(input_ids) # 创建一个与input_ids形状相同的attention_mask
# 推理时,将增量参数矩阵合并到预训练权重中
with torch.no_grad(): # 不计算梯度
outputs = model(input_ids, attention_mask=attention_mask)
# 处理模型输出,例如,获取最后一层的隐藏状态
last_hidden_states = outputs.last_hidden_state
# ...根据任务需求处理输出...
return last_hidden_states
# 使用模型进行推理
input_text = "Example input text for inference"
inference_output = infer_with_lora_model(input_text, lora_model, tokenizer)
# 打印推理结果
print(inference_output)
五、小结
LoRA作为一种高效的模型微调技术,在当前计算资源受限的情况下,为大模型的应用提供了更灵活、高效的解决方案。尽管其存在一定局限性,但通过合理的参数设置和训练策略优化,能够在多个下游任务中发挥重要作用。随着技术的不断发展,LoRA有望在更多领域得到广泛应用并持续优化。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料。包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程扫描领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程扫描领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程扫描领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程扫描领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程扫描领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

















 340
340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









