







1. 计算机神经网络与神经元
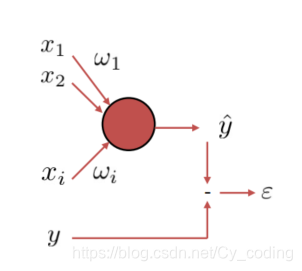
要理解神经网络中的梯度下降算法,首先我们必须清楚神经元的定义。如下图所示,每一个神经元可以由关系式 y = f ( ∑ i = 1 n w i x i + b ) y = f(\sum_{i=1}^nw_ix_i + b) y=f(∑i=1nwixi+b)来描述,其中 X = [ x 1 , x 2 , . . . , x n ] X = [x_1,x_2,...,x_n] X=[x1,x2,...,xn]就是N维的输入信号, W = [ w 1 , w 2 , . . . , w n ] W =[w_1,w_2,...,w_n] W=[w1,w2,...,wn]是与输入向量一一对应的n维权重, b b b bias 偏斜, y y y对应该神经元的输出, f f f函数称为激励函数,例如sigmoid函数,softmax函数等等。
那么一个神经网络是如何进行学习的呢?以一个神经元为例,在一组输入信号 X X X经过该神经元后,我们得到了一个输出信号称之为 y e t o i l e y_{etoile} yetoile,而训练集中给出的实际输出例如为 y y y,那么显而易见地,想要提高正确率,即正确地学习对于一组输入应该获得的输出 y y y,一个神经元所做的计算,就是一个最优化(最小化)问题,通过改变权重 W W W来最小化损失(误差) l ( y , y e t o i l e ) l(y,y_{etoile}) l(y,yetoile)。当然,这个误差的定义可以根据问题的不同有所区别,例如简单的向量L1,L2距离,MSE均方误差。对于整个训练集而言,当然不止包含了一组输入输出。因此整体而言,误差Loss Function L ( W ) = 1 N ∑ t = 1 K l ( y t , y t e t o i l e ) L(W) = \frac{1} {N}\sum_{t=1}^{K}l(y_t,y_{t_{etoile}}) L(W)=N1∑t=1Kl(yt,ytetoile) 是所有K组训练数据误差的总和的平均数。
我们已经知道了,Loss Function损失函数与神经元的权重息息相关,神经元要做的计算,就是找到能最小化该损失函数的权重 W W W。优化的算法纷繁多样,使用的较为广泛的就是梯度下降 g r a d i e n t d e s c e n t gradient\space\space descent gradient descent 及其衍生算法SGD随机梯度下降,BGD批量梯度下降。
2. 梯度下降算法 g r a d i e n t d e s c e n t gradient\space\space descent gradient descent
梯度下降算法,一言以蔽之,就是沿着梯度下降的方向不断迭代,最终逼近函数最小值的优化方法。如下图所示&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 6838
6838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









