







朴素贝叶斯理论
判断一封邮件是否是垃圾邮件。
首先在单词字典中(Vocabulary dictionary)列出所有的单词列表。假设字典中有100000个单词。然后设一个向量X,当一封邮件中的单词出现在字典中时,对应字典中的位置Xi为1,若字典中没有该单词则为0。如下图所示:当邮件中存在buy和a这两个单词时,

假设邮件中出现的每一个单词时相互独立的,就是说邮件是由随机生成的单词组成,(这就是朴素的原因)这我们去表现一封邮件的概率为:

我们用
ϕ
j
∣
y
=
0
=
P
(
X
j
=
1
∣
Y
=
0
)
\phi_{j|y=0}=P(X_j=1|Y=0)
ϕj∣y=0=P(Xj=1∣Y=0)表示如果是垃圾邮件则单词xj出现的概率。
ϕ
j
∣
y
=
1
=
P
(
X
j
=
1
∣
Y
=
1
)
\phi_{j|y=1}=P(X_j=1|Y=1)
ϕj∣y=1=P(Xj=1∣Y=1)表示如果不是垃圾邮件则单词xj出现的概率。对一个数据集{xi,yi}其联合概率密度为:

对其进行最大似然估计可得:

确定好参数后,则对于新的数据可以根据贝叶斯定理来判断:
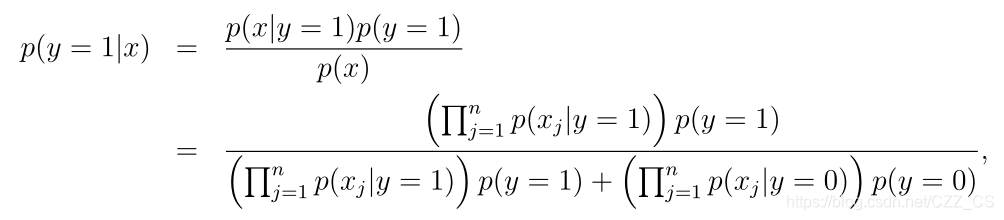
拉普拉斯平滑
由上可知针对新的数据可以使用贝叶斯定律判断,但是当一封新的邮件中出现在训练集中没有出现过的单词,假设该单词是字典中第35000个那么:

利用贝叶斯计算则:

因为没有见过则将概率判断为0,这在统计学中是错误的,所以我们在参数估计值的分子上加1,分母上加k,k是字典中的单词数。得到如下:

这样我们就能避免面对新单词时得到概率为0的情况了。
多相式事件模型
在上面的朴素贝叶斯理论中,实际上是采用的多元伯努利分布,在这个模型中,我们假设电子邮件的生成方式是首先随机确定(根据后验概率p(y)确定),然后电子邮件的发送者通过首先从单词的多项式分布p(x1 | y)生成x1来编写电子邮件。然后在生成x2,这样每件邮件的长度xn可能不同。因此文件的总概率为:

这样我们对训练集{(xi,yi),i=1,2,m},其中xi的长度为ni,其似然函数为:

其最大似然估计为:

加入拉普拉斯平滑为:















 4231
4231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









