






机器学习与运筹优化的结合是近年来数据科学和人工智能领域的重要研究方向,这种融合不仅加快了计算速度,还能挖掘出隐藏的价值,使优化结果更准确、更有用。
今天就这两种技术结合机器学习+运筹优化整理出了10篇论文+开源代码,以下是精选部分论文
更多论文料可以关注 :AI科技探寻,发送:111 领取更多[论文+开源码】
:AI科技探寻,发送:111 领取更多[论文+开源码】
论文1
Learning Encodings for Constructive Neural Combinatorial Optimization Needs to Regret
学习编码以用于构造性神经组合优化需要后悔
方法:
-
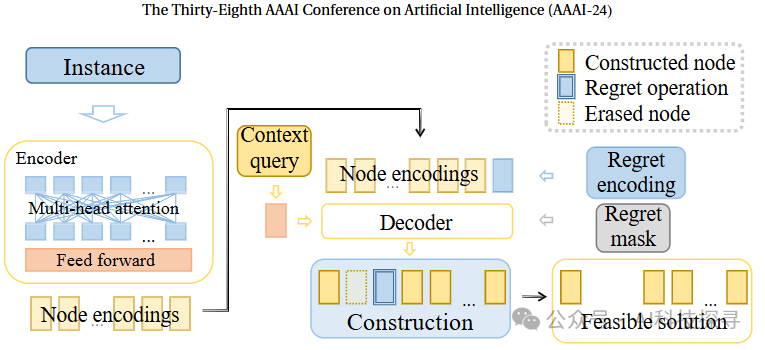
学习构造性启发式(LCH):通过快速自回归解构建过程实现高质量解。
-
后悔机制:提出一种新颖的基于后悔的机制,允许在构建解的过程中回滚到前一个节点。
-
可学习的后悔编码:引入一个128维的可学习向量作为后悔编码,与节点编码并行。
-
后悔掩码:为了避免无意义或非法的后悔操作,维护一个后悔掩码。
-
修改的马尔可夫决策过程(MDP):为后悔机制训练策略网络,引入新的状态、动作和策略定义。
创新点:
-
首次修改自回归解构建过程:LCH-Regret是第一个修改这一过程的方法,显著提升了收敛速度和编码质量。
-
模型不可知性:作为一种插件,可以应用于任何现有的基于LCH的DRL-NCO方法,无需重新设计特定模型结构。
-
性能提升:在旅行商问题(TSP)、有容量限制的车辆路径问题(CVRP)和灵活流水线问题(FFSP)等多个典型组合优化问题上,与之前的修改方法相比,LCH-Regret显著缩小了与最优解的差距。例如,在TSP问题上,POMO-Regret在100节点实例上的平均最优差距从POMO的0.37%降低到0.12%。
-
泛化能力:在不同分布的测试集上,LCH-Regret展现出更好的泛化能力,证明了其训练的节点编码更具代表性。
论文2
Distributed Constrained Combinatorial Optimization leveraging Hypergraph Neural Networks
利用超图神经网络的分布式约束组合优化
方法:
-
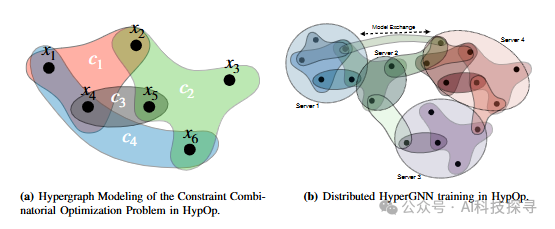
超图建模:将约束组合优化问题通过超图进行建模,每个约束对应一个超边。
-
超图神经网络(HyperGNN):作为可学习的转换函数,用于捕捉变量之间的复杂模式和相互依赖关系。
-
模拟退火(SA):与HyperGNN结合,用于将连续输出映射到离散值,避免陷入局部最优。
-
分布式和并行训练架构:提出两种多GPU HyperGNN训练算法,一种是分布式训练,另一种是并行训练,以提高训练效率和可扩展性。
创新点:
-
超图神经网络的应用:首次将超图神经网络应用于具有高阶约束的一般组合优化问题,显著提升了解决方案的准确性。
-
可扩展性:通过分布式和并行训练架构,使算法能够扩展到更大的问题规模,例如在OGB-Arxiv图(169343个节点和1166243条边)上,分布式训练比单GPU训练快近两倍。
-
知识转移:通过在同一超图内转移知识,展示了模型的泛化能力,并显著加速了优化过程。
-
性能提升:在多个基准测试中,包括超图MaxCut、可满足性问题和资源分配问题上,与现有的无监督学习求解器和通用优化方法相比,HypOp在运行时间上有显著改进。例如,在超图MaxCut问题上,与SA相比,HypOp的运行时间从3616秒降低到1679秒。
论文3
BQ-NCO: Bisimulation Quotienting for Efficient Neural Combinatorial Optimization
BQ-NCO:用于高效神经组合优化的双模拟商
方法:
-
组合优化问题(COPs)的马尔可夫决策过程(MDP)表述:提出了一种将COPs表述为MDP的通用方法,利用COPs的常见对称性来提高分布外泛化能力。
-
双模拟商(BQ):引入了一种基于MDP中的双模拟商的通用方法来减少状态空间,特别适用于具有递归性质的COPs。
-
递归性质的利用:对于具有递归性质的COPs,通过将部分解映射到新的(诱导的)实例,利用问题的对称性来简化MDP求解。
-
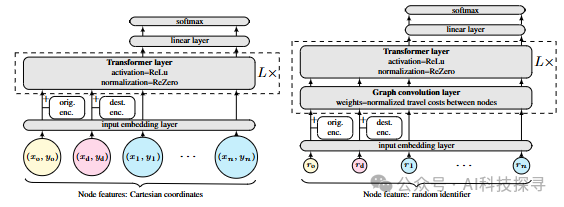
基于Transformer的策略网络:为BQ-MDP设计了一种基于Transformer的简单架构,适用于多种COPs,如欧几里得和非对称旅行商问题(TSP、ATSP)、有容量限制的车辆路径问题(CVRP)、定向问题(OP)和背包问题(KP)。
创新点:
-
通用MDP表述:首次提出了一种适用于任何COP的MDP表述方法,并证明了最优MDP策略与解决COP的等价性。
-
双模拟商的应用:通过双模拟商显著减少了状态空间,提高了学习效率,尤其是在递归COPs中,与直接MDP相比,状态空间大幅减少。
-
性能提升:在五个经典COPs上取得了新的最佳结果,特别是在分布外泛化方面表现出色,能够处理比训练时更大的实例。例如,在TSP问题上,与POMO相比,BQ-transformer在100节点实例上的平均最优差距从0.13%降低到0.01%。
-
计算效率:尽管模型复杂度为O(N^3),但通过单次策略回滚就能获得优秀结果,比相关Transformer模型更快地提供高质量解决方案。使用PerceiverIO架构替换Transformer可以显著加速推理,同时保持竞争力的性能。
论文4
The Interplay of Optimization and Machine Learning Research
优化与机器学习研究的相互作用
方法:
-
优化问题的核心地位:强调优化问题在大多数机器学习方法中的核心地位,讨论了如何通过选择适当的模型族和损失函数来训练模型。
-
数学规划理论的应用:利用数学规划理论提供最优解的定义——最优性条件,以及使用数学规划算法为机器学习研究者提供训练大型模型家族的工具。
-
凸优化的重要性:强调凸优化在数学规划中的关键作用,指出凸问题在算法和理论上更具可处理性,尽管非凸问题的复杂性可能急剧增加。
-
优化模型的多样性:介绍了多种数学规划模型,包括线性、二次、二阶锥、半定和半无限规划等,并讨论了它们在机器学习中的应用。
创新点:
-
优化与机器学习的融合:展示了机器学习研究者如何利用数学规划的最新进展来追求新的模型类型,以及数学规划如何从机器学习中获得新的挑战。
-
新型机器学习模型:提出了基于现有凸规划方法的新机器学习模型,如处理不确定性和缺失数据的二阶锥规划方法,以及用于假设选择的凸模型。
-
优化方法的改进:针对现有机器学习模型,提出了更高效的优化方法,如改进的SVM优化算法,包括活动集方法和序列最小优化(SMO)方法的改进。
-
模型重构与算法改进:通过小的模型重构,开发了更强大的新算法,如大规模多核学习的半无限线性规划方法,以及利用问题结构改进排名和结构化输出的方法。
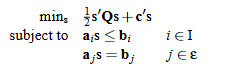
更多论文料可以关注:AI科技探寻,发送:111 领取更多[论文+开源码】

















 5101
5101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









