







原文链接:https://arxiv.org/pdf/2007.08199.pdf
github链接:GitHub - songhwanjun/Awesome-Noisy-Labels: A Survey
(本文仅做阅读笔记之用,如需了解细节可自行查看原文,翻译不周之处,敬请指正)
1. Introduction
据统计真实世界的数据集中存在的标注噪声范围在8%到38.5%。
深度神经网络(DNN)因为具有很强的拟合能力,所以很容易对噪声标签过拟合。
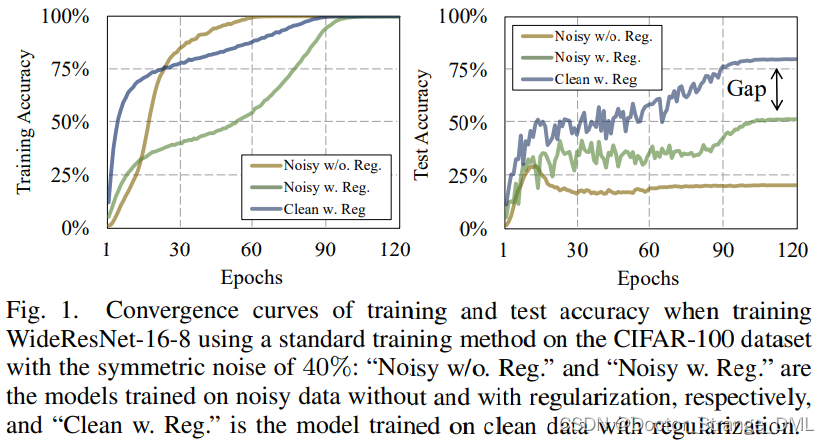
正则化技术(如数据增强,权重衰减,dropout,批次正则化(BN)等)虽然能缓解过拟合问题,但是光靠正则化并不能完全克服过拟合。如fig.1就形象地说明了这个问题:
- 无论训练数据是否有噪声(Noisy or Clean),或者是否使用了正则化技术(w/o Reg.),网络都能完全拟合训练集(train-acc 都达到了100%)
- 但是在测试集中存在严重的gap,用了正则化能有效缓解过拟合,但是和无噪声的数据集相比还有很大差距
此外,标签中的噪声比其他噪声(如输入的噪声)危害更大。
鲁棒训练(Robust training)还包括其他两个研究方向:对抗学习(Adversarial learning)和数据插补(data imputation),但是以上两个方向都是针对特征上的噪声,因此不在此综述(标签噪声)的讨论范围。
2. Preliminaries
A. 带噪声的全监督学习范式
符号定义,经验风险最小化,梯度下降......
B. 标签噪声的分类
(1)实例不相关的标签噪声
传统的标签噪声建模方法假设标签噪声是和数据特征无关的,使用一个过渡矩阵T来将真实标签变为噪声标签。根据此过渡矩阵的特点(标签转变的概率分布),标签噪声可以分为对称噪声(symmetric noise)和非对称噪声(asymmetric noise),非对称噪声还包括一种极端情况,此时一种标签只可能转变为另外一种噪声,称为对噪声(pair noise)。
(2)实例相关的标签噪声
在实际场景中,噪声更有可能与标签和数据本身的特征都有关系。(即某些困难样本或者模糊样本更有可能有标注错误)
C. 非深度学习的方法
- 数据清洗(data clean)
- 代理损失(surrogate loss)
- 概率方法(probabilistic method)
- 基于特定模型的方法(model-based method)
D. 带标签噪声的回归问题
回归问题的目标是建模特征和连续目标变量之间的关系(分类是离散的目标空间)
回归问题考虑考虑两种类型的标签噪声:
- 加性噪声(additive noise):
- 实例相关噪声(instance-dependent noise):
尽管目标空间不同,但是分类和回归都是学习从特征空间到标签的映射关系,因此用于分类问题的方法很容易扩展到回归问题。本文重点关注分类问题。
3. 基于深度学习的方法
共分为五类,如fig.2和fig.3所示,分别为:
- 鲁棒结构设计:
- 鲁棒正则化方法:减少对假样本的过拟合
- 鲁棒损失函数设计
- 损失调整:包括损失校正、损失重加权、标签翻新(label refurbishment)和元学习
- 样本选择&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









