






这是2020年关于Noisy Label的一篇综述,简要的做一记录。
文章链接:
https://arxiv.org/abs/2007.08199
Background
为什么要解决Noisy Labels的问题?
DNN's can easily fit an entire training dataset with any ratio of corrupted labels, which eventually resulted in poor generalizability on a test dataset.
也就是说,DNN强大的拟合能力导致在有噪声污染数据集上训练的模型,在测试集上的泛化能力变差;

从细节原因来看,有如下几点:
- 同其他的Noisy相比(比如input noise),Label Noise造成的危害更大;
- 现有的一些正则化方法,比如data arguments, dropout在解决Label Noisy问题上效果不佳;
该综述的论述范围
Supervised-Learning
Adversarial Learning:
Data imputation:
Feature Noise
前言Preliminaries
Label Noise的分类
- Instance-Independent Label Noise: 真实的样本标签已存在,标签的退化过程与数据特征是条件独立的;也就是说,噪声标签由一个transition matrix 转换而来;
- Symmetric Noise (Uniform Noise) : 真实标签污染成其他任意标签的概率是相同的,并不依赖于任一标签;
- Asymmetric Noise (Label dependent Noise): 真实标签更容易被污染为一个特定的标签(或者说,真实标签污染为某一个特定标签的概率最大!概率不同)
- Pair Noise: 真实标签只能转换为一种特定的标签;
- Instance-Dependent Label Noise: More Realistic noise Modeling,即更加真实的noise生成过程。噪声标签的生成概率依赖于数据特征和类别特征(data feature & class feature)
非深度学习方法
- Data Cleaning - Cons: over-cleaning
- Bagging and Boosting
- K-nearest neighbor
- Outlier Detection
- Anomaly Detection
- Surrogate Loss
- Probabilistic Method - Cons: 恶化overfitting
- Model-Based Method - Cons: infeasible in DeepLearning.
Deep Learning Approaches (深度学习方法)
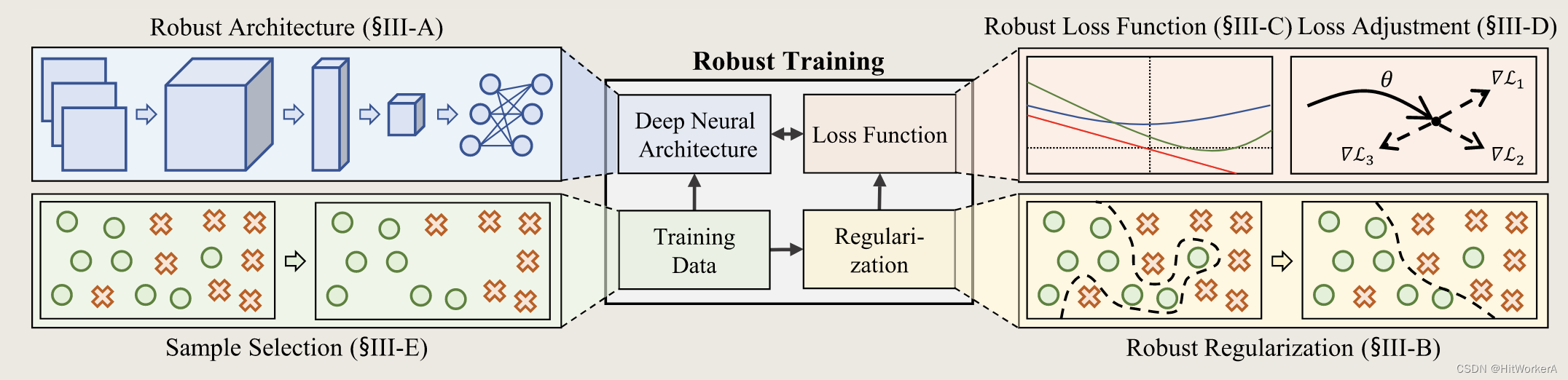
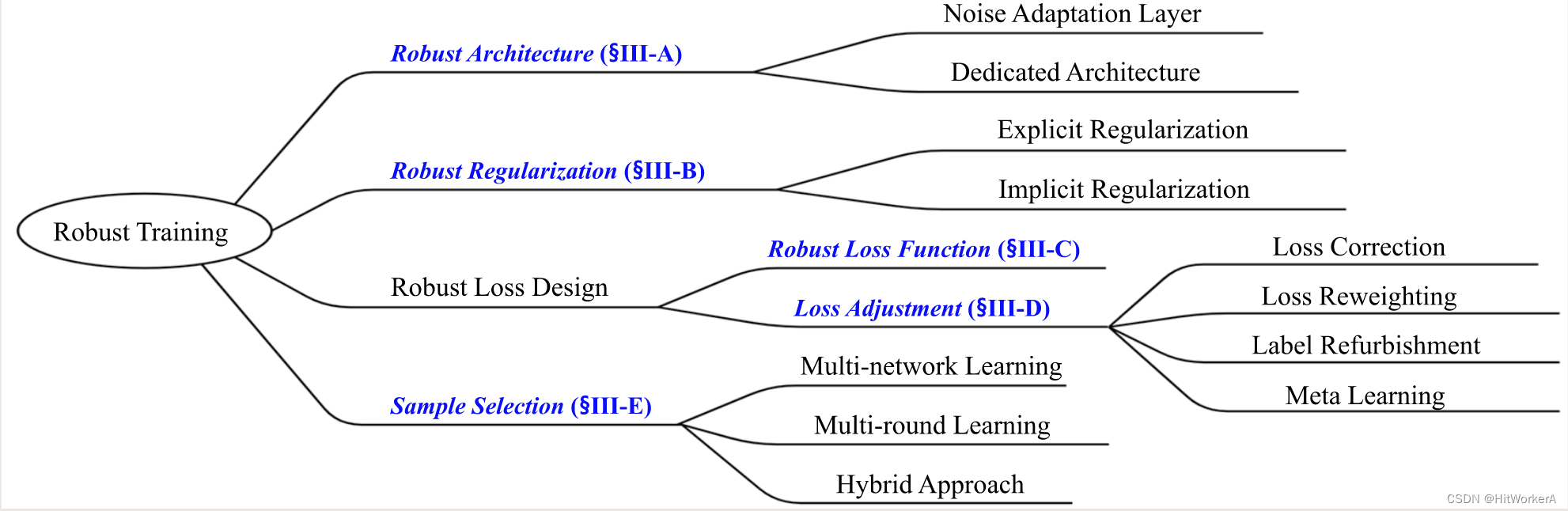
主要分为5类进行综述讨论
- Robust Architecture
- Robust Regularization
- Robust Loss Function
- Loss Adjustment
- Sample Selection
Robust Architecture
- Noise Adaptation Layer: (疑问:通常如何设计的?去除了之后,模型的输入会发生变化,如何修改的?)
- 目标:找到潜在的标签转换模式(Label Transition Pattern, i.e., the noise transition matrix T.)
- 该层通常放置在基础模型的顶端,在测试的时候,该模型通常被去除了;
- Drawbacks: 无法识别错误标注的样本, 平等的对待所有样本;
- Dedicated Architecture:
- 主要处理更加复杂的目标;
- 模型举例:
- Probabilistic noise Modeling
- Masking
- Drawbacks: 很难拓展到其他的结构
Robust Regularization
像常规的数据增强,dropout单独使用并不能提升测试的准确率,因此需要结合一些针对于Noisy Labels的正则化方法使用。
- Explicit Regularization
- Believel Learning
- Annotator confusion
- Loss-based gradient clipping(基于loss的梯度截断)
- 评价:这类方法通常引入了依赖于模型的敏感超参数,或者需要更深的模型才能弥补失去的模型表达容量(representing capacity),因此需要最优的fine-tune.
- Implicit Regularization
- 对抗训练(adversarial training)
- 标签平滑(label smoothing)
- 评价:解决了Explicit Regularizaition的问题;但是往往这类方法使得训练变得缓慢,收敛变得困难。
Robust Loss Function
Robust Loss Function从理论层面保证了模型可以学到一个最小的risk,从而保证模型是noisy-tolerate的。
一些loss function的比较:
- categorical cross entropy(CCE): 快速拟合和高泛化性
- Mean absolute Error(MAE): 比CCE有更好的泛化能力,但是当碰到复杂的样本时泛化能力急剧下降;
- Generalized Cross Entropy: CCE和MAE的结合;
- Bitempered loss: a proper unbiased generalization of the CE loss based on the Bregman divergence.
- Symmetric Cross Entropy (SCE): 受到KL散度对称性的启发,提出了集合一个noisy tolerance term,同CCE结合的loss;
- Curriculum Loss (CL): 一种surrogate loss
- Active Passive Loss: (APL) 其实是两个loss的结合active loss & passive loss. Active Loss最大化属于给定类的概率;passive loss最小化是其他类别的概率;
评价:这些损失函数在简单的场景(类别少的分类)效果会比较好,但是增加了模型收敛的时间;
Loss Adjustment
- Loss Correction: 修改每一个example的loss,通过乘以由另外一个特别的DNN预测的标签转换概率;
- 常见的方法有反向矫正(backward correction),前向矫正(forward correction) (两者也就是网络在反向传播和前向传播过程中做的矫正)
- 评价:这些方法的鲁棒性高度依赖于预测的到的转换矩阵的准确性(The precision of transition matrix estimated); 同时,为了获得这个转换矩阵,往往先需要获得先验信息。
- Loss Reweighting——将更大的权重分配给有正确标签的样本,而将更小的权重分配给错误标签的样本。
- 评价:这些方法需要额外的权重分配策略函数,增加了一些超参数,同时在实际中比较难以应用。
- Loss Refurbishment:
- 感觉整体的意思就是对某个样本沿着correct label的方向修改,从而修改了Loss的传播;
- 评价:所有的噪声标签都被clean labels显性的替代了。但是方法容易受confusion的样本的影响;如果一旦refurbish错了,那么模型很可能overfitting refurbished labels.
- Meta Learning
- 使用meta-learning, distillation learning;
- 评价:需要unbiased clean validation data来最小化辅助目标,在现实中unbiased数据很难做到;
Sample Selection
DNN在更新迭代的时候,由选择的clean example来进行梯度的更新;同时在论文中,作者引用DNN的memorization effect的时候指出:
In the empirical studies [21], [141], the memorization effect is also observed since DNNs tend to first learn simple and generalized patterns and then gradually overfit to all noisy patterns. As such, favoring small-loss training examples as the clean ones are commonly employed to design robust training methods.
但是不正确的样本选择会带来累积误差,所以很多方法就是在做如何才能更好的选择样本;
- Multinetwork Learning
- co-training methods: 可以理解为两个网络,一个在挑;另外一个在训练(co-teaching methods)
- small-loss tricks: 当loss distribution of true-labeled and false labeled examples largely overlap的时候,该方法并不是很有效。
- Multiround Learning: 顾名思义,就是在一个网络的基础上,不断挑数据,然后不断迭代优化,在这个过程中,选择的数据集合不断的在增加。
- ITLM:在每一轮训练的时候,将一部分的small loss的样本选择出来,然后用于下一轮样本的训练。
- INCV: 每一轮通过交叉验证的方法分类真实标签的样本并去除大loss的样本。
- iterative detection: 通过利用local outlier factor算法检测错误标签的样本。
- 评价:随着每一轮样本的增加,计算花销线性增长;同时,也有可能有漏选的样本。
- Hybrid Approach:
- 将样本选择方法同其他的方法结合起来,来提高noisy labels的利用率。
- 在这个方法中,最主流的方法就是将样本选择方法同半监督学习方法结合起来(combination of selection methods & semi-supervised methods)。
- 评价:明显提高了噪声的鲁棒性;但是引入的超参数使得模型更容易受到数据和噪声改变的影响,同时计算开销也有所提高。
未来研究方向
- Mutlilabel data with label noise
- 将现有的单标签的算法直接用于处理多标签数据,模型并不能很好的对noisy label进行矫正;
- Class Imbalance Data with Label Noise
- 现实世界中,data imbalance和label noise基本上是同时存在的。在很多处理label noise的算法中,在所有类别上训练样本是同时被对待处理的,这就导致了算法并不能对data imbalance问题做出响应;
- 同时,如果移除了minor class中的一些样本的话,有可能会导致更加严重的后果;
- Connection with Input Perturbation
- 像对抗训练等对网络的输出进行干扰,可以提高网络的鲁棒性;
- Efficient Learning Pipeline
- 提高网络的训练时间也是需要关注的一个方向;














 1351
1351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









