







Multi-Context Attention for human pose estimation(发表与2017年2月)
这篇论文的关键点是构建多尺度下的CNN,研究尺度的变化是此论文的创新的地方,所得到的网络是端到端的框架结构。
整体方法:
首先使用stacked Hourglass堆叠沙漏网络的的attention map 热点图。然后使用CRF(conditional random field)得到热点图中的相邻关系。然后组合holistic attention model得到全局的个体和part attetntion model得到的人体局部部件。并在此基础上设计了新Hourglass模型(hourglass residual units)HRU增加了感受野变化。
所以从这整个流程中,可以感受到一些作者在研究尺度——全局到局部的变化——所花的心力——>两个Model外加感受野的变化力度HRU,这些可以丰富Hourglass网络。所倾向重点是挖掘信息,身体部件的探测上(包括遮挡,扭曲),当然也有构建part connection的方法。
小小的历史介绍:
姿态识别需要结合大小的尺度,先前的paper是手工设计实现这种效果,如多边框/多种形式的裁剪,不灵活也不能抓到姿态的多样性,所以要用神经网络。
人体姿态识别历史:
开始使用模型,比如图形或框架[45,8,30,31],然后后来就有人引入了卷积网络[37-40,43,8-10,29,33]。开始是学习简单结果[8],后来Tompson将这些特征融合得到图片[37],用Markov random field(MRF)做后处理。再然后到了使用空间相关的卷积姿态网络[40]。目前阶段是到了Hourglass[5,29],[5]是Hourglass的变种,沙漏网络是使用重复池化和上采样来学习空间分布。
多上下文处理的历史:
这儿的上下文是目标周围的空间,对象的联系,还有对象间的相互作用。使用上下文信息的方法有糅和多尺度的特征[15,16],以及使用门方法触发多尺度交互。这篇文章要在应用上下文信息这一角度上会缕清楚。
热点图机制:
visual attention model 注意力尺度变化,一般应用在循环神经网络recurrent neural networks ,得到每一步的attention map热点图,最后将这些过程产生的attention map融合[2,3,27]。这篇文章也要这这里着重发力。文中的attention map和heatmap概念上基本一致,attention map强调不同尺度的意义。
具体细节:
还是这个研究领域的两步走策略:一是挖掘不同尺度下热点图的信息,能构建上下文关系;二是要更好的应用空间相关的方法,提出了CRF。
结构框架:
使用多层Hourglass结构,每个结构中都产生一堆热点图。多个结构堆叠,结构间输入不同,所以结构间会产生差异(尺度上的),这样热点图就是分层次的了,能代表了不同的尺度下的特征。
具体到单个Hourglass 的结构,也做了修改,所达到的效果就是可以能更快改变感受野。当然保留了Hourglass的多尺度效应以及应用残差网络的好处。
整体结构:
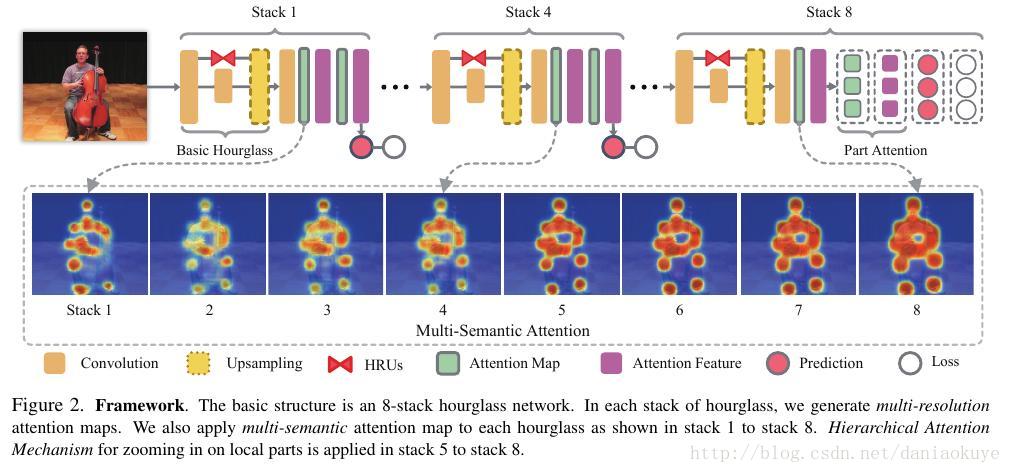
这个网络结构中,Hourglass是嵌入的,多上下文的attention model是这个网络的属性(多种分割/多种分辨率/多层次的全局热点图),最后得到的热点图再自动的给特征(身体部件)赋予权重。
基础结构:
Hourglass单元/块是基础网络结构,使用MSE(mean squared error)计算loss。在单个Hourglass 中,原有的残差单元替换成了Micro hourglass residual units(HRUs),但此分支的作用还是不变,是跨分辨率组合特征。这种新结构作者称之为nested hourglass networks——嵌入到Hourglass中的。然后这种结构又用了好几层,这样每一层就会发生注意力(要解析的尺度)尺度不完全一致,达到multi-semantic attention的效果。然后又有新的trick机巧设计,这些结构设置不同,一共用了8个这种结构,前4个得到了两个全局热点图,后4个则是去关注局部热点图。(凡是神经网络中称为trick的,都是讲不太清,但有效的。当然后来的有些文章会解析一些用的很广的,比如Relu,就不被称为trick了)
HRUs——Hourglass结构的变化:
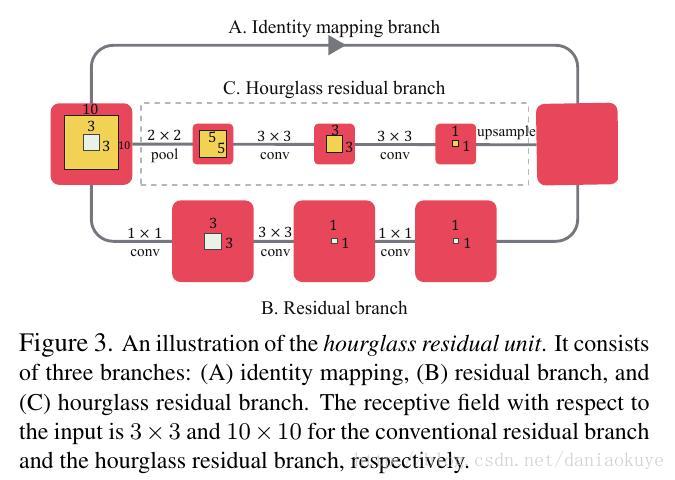
回忆下残差网络[20]: Xn+1 = h(Xn ) + F(Xn , Wfn ) where xn and xn+1 are the input and output of the n-th unit, and F is the stacked convolution, batch normalization, and ReLU nonlinearity. In [20], h(xn ) = xn is the identity mapping.

HRU使用了三个分支,三个分支的感受野大小不一样,最后加起来作为HRU的输出。关于这点,这篇论文讲的比较清楚,特别是ResNet中分辨率不一致的处理,或者更倾向于意义。
CRF——身体部件的相关:
CRF(confitional random fields) 做空间相关, we use the mean-field approximation approach to recursively learn the spatial correlation kernel [51, 25]. 身体部件间的相关是每个bottom-up网络识别姿态所必须的,这儿是根据近似和空间相关计算概率,当然已知道身体部件是什么了。这是CRF一个已有的成果。
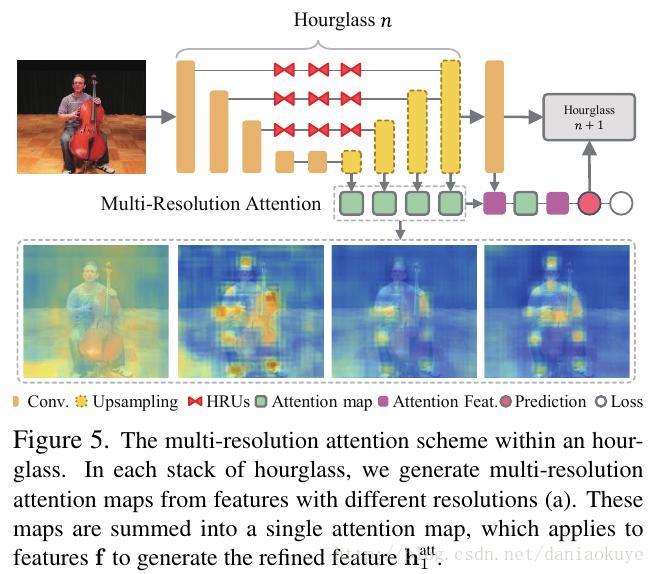
多分辨率得到的热点图:
然后根据又生成了高分辨率下的attention map,以及全局和局部的attention map,然后将这些attention map组合起来得到heatmap热点图。
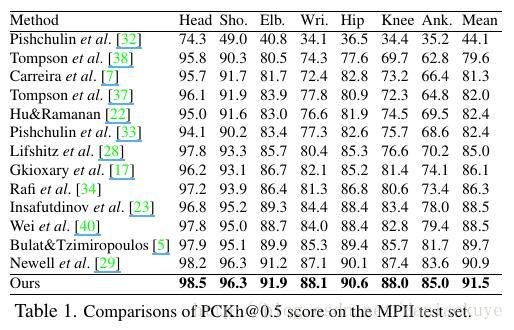
精度:
没怎么提及速度如何,网络是端到端的结构,速度应该不会太差。
对这篇论文值得期待的是如何增强Hourglass在多尺度下的表现能力。














 2381
2381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









