







Stacked Hourglass Networks for Human Pose Estimation
ECCV2016
http://www-personal.umich.edu/~alnewell/pose/
Torch code is available
本文使用CNN网络来进行人体姿态估计,使用 Stacked Hourglass Networks,这里的 Hourglass 漏斗形状,Stacked Hourglass 就是多个漏斗形状网络级联起来
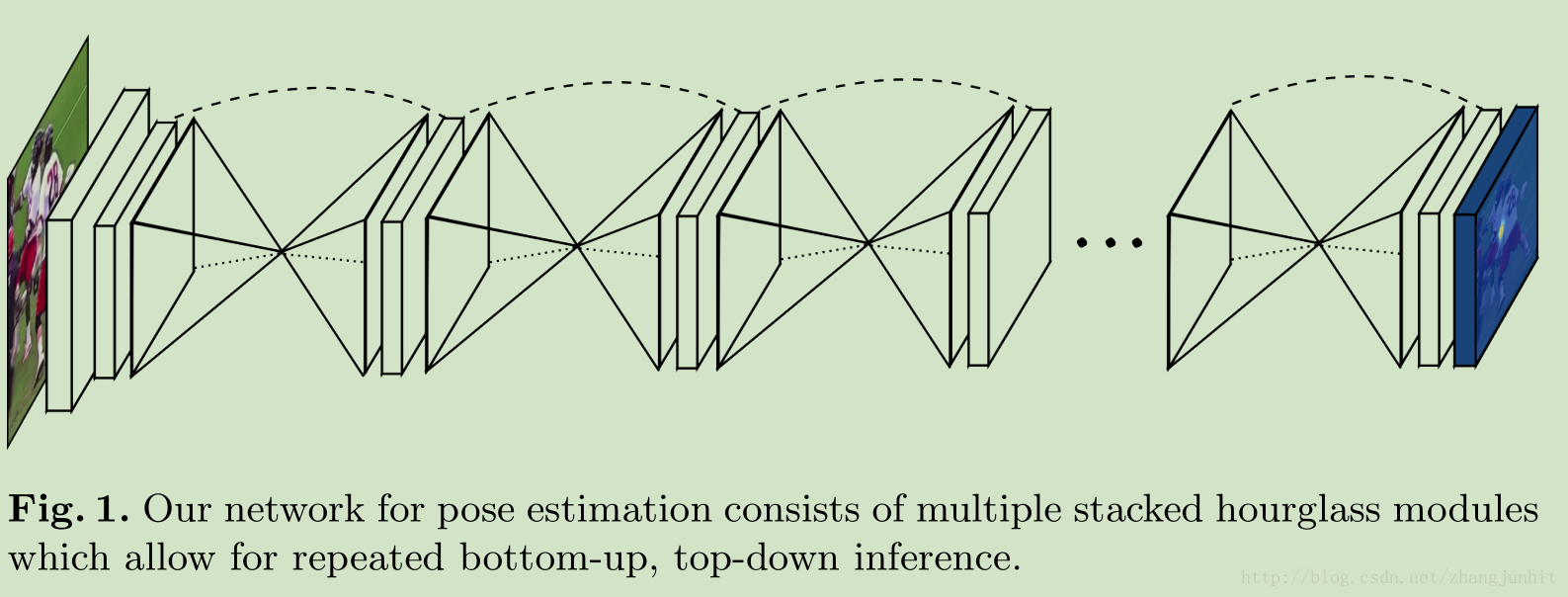
人体姿态估计使用 CNN 网络如何做了? 一般来说是先进行人体关节的检测,然后再将这些关节联系起来估计人体姿态

3 Network Architecture
3.1 Hourglass Design
漏斗网络的设计主要源于 the need to capture information at every scale 即多尺度信息的捕获
局部信息对于检测 人脸和手是至关重要的。最终的姿态估计则需要对整个人体的一致性理解 coherent understanding。 对于人的方向、肢体的排列、相邻关节的关系等信息需要从图像中不同的尺度去衡量和解析
The topology of the hourglass is symmetric
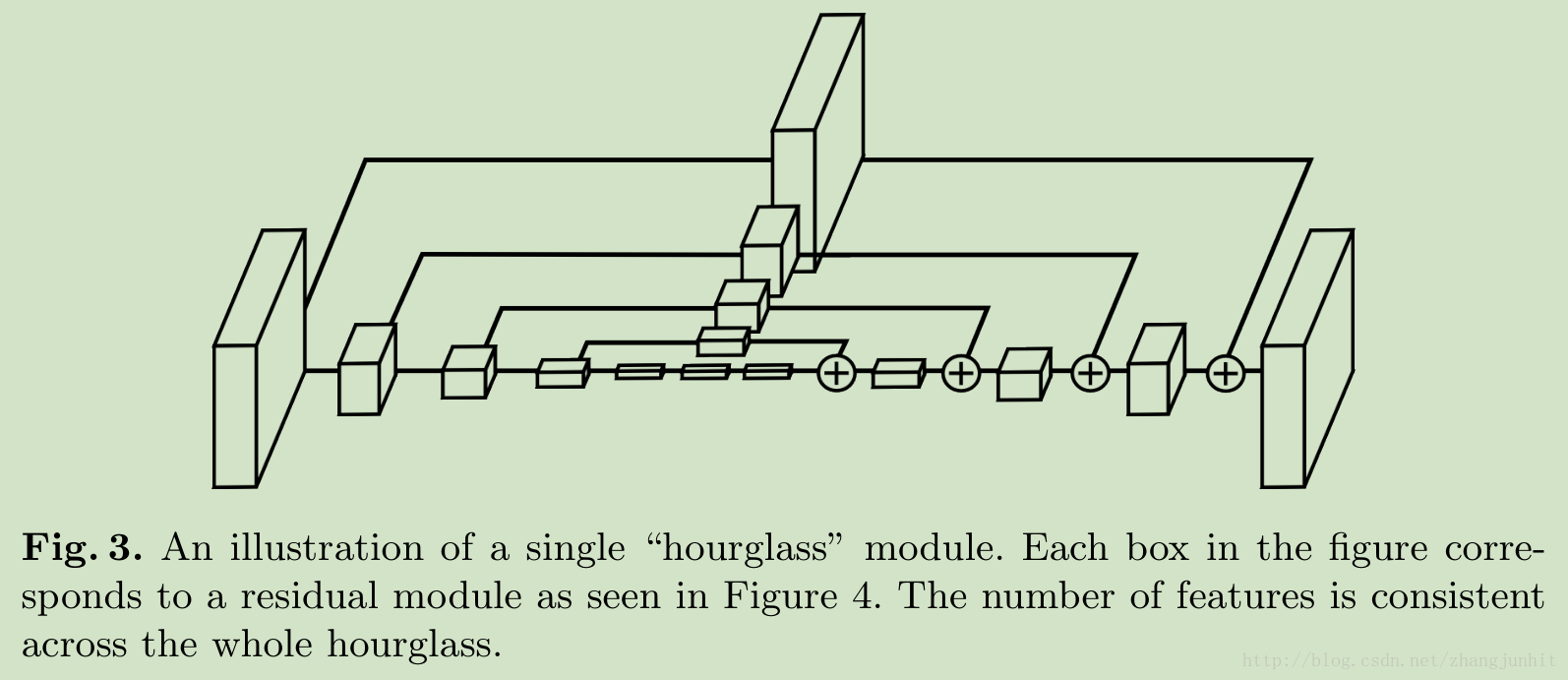
Our hourglass module differs from these designs mainly in its more symmetric distribution of capacity between bottom-up processing (from high resolutions to low resolutions) and top-down processing (from low resolutions to high resolutions).
3.2 Layer Implementation
在网络层的实现中,这里尝试了一些方法来提升性能
大量使用 residual modules
滤波器尺寸不超过 3x3
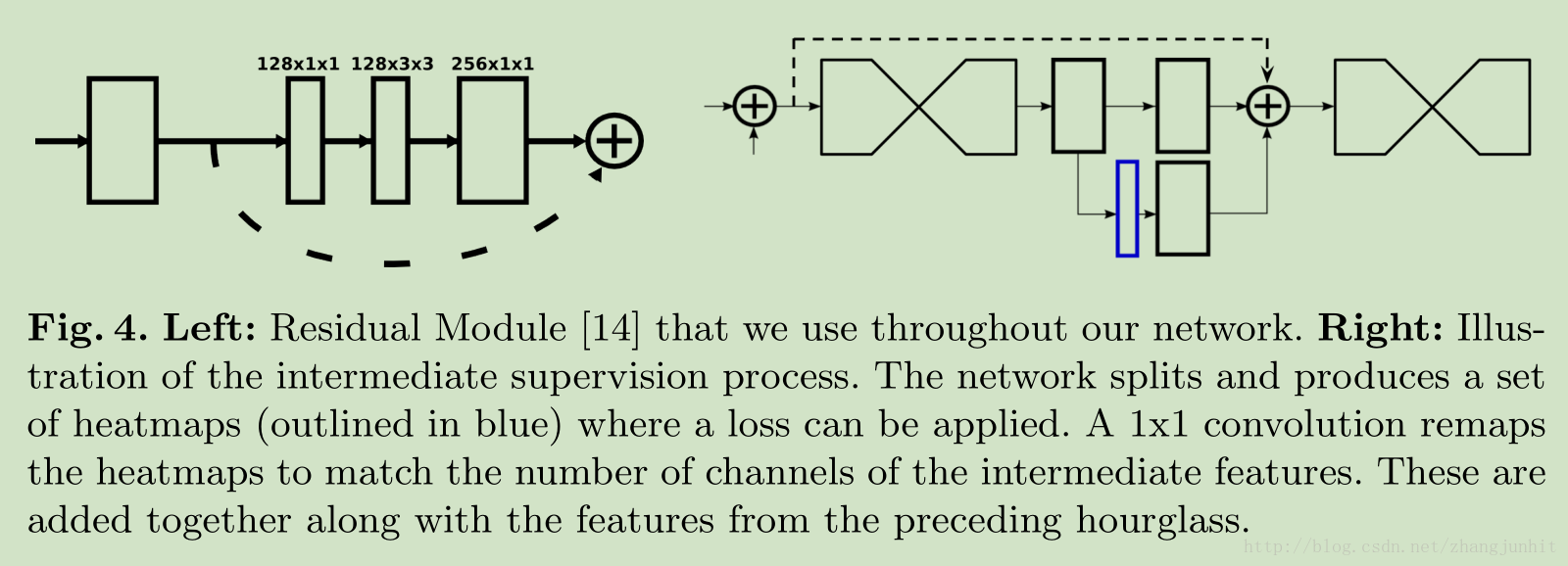
3.3 Stacked Hourglass with Intermediate Supervision
在级联漏斗网络中我们加入了中间监督,就是中间结果和真值数据比较,提升网络的性能,这个有点类似人脸识别中的 FaceID系列中采用的方法
3.4 Training Details
训练中的一些细节介绍
Example output on MPII’s test set

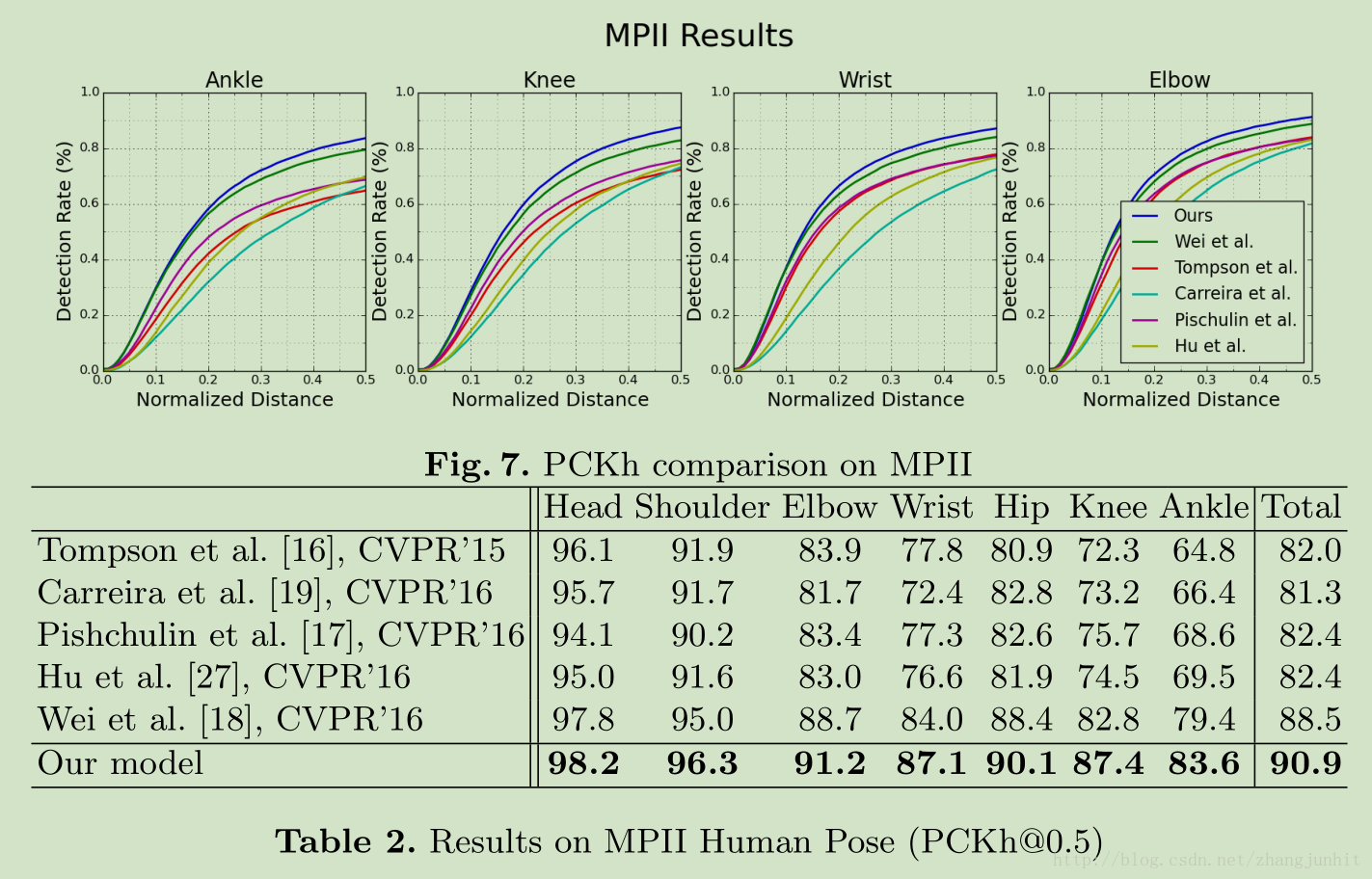
本文最大的特色就是设计一个漏洞形状网络结构,然后级联这个网络。这个漏洞网络的网络结构是对称的。这个级联有对应着图像多尺度信息的提取。
SPPE Stacked Hourglass model is rather vulnerable to bounding box errors.Even for the cases when the bounding boxes are considered as correct with IoU > 0.5, the detected human poses can still be wrong. Since SPPE produces a pose for each given bounding box, redundant detections result in redundant poses.

















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









