






论文地址:https://arxiv.org/pdf/1812.05784.pdf
代码开源:https://github.com/nutonomy/second.pytorch
摘要
点云中的目标检测是许多机器人应用中的重要方面,例如自动驾驶。在本文中,我们考虑将点云编码为适合下游检测流程的格式的问题。最近的文献提出了两种类型的编码器;固定编码器倾向于快速但牺牲准确性,而从数据中学习的编码器更准确但较慢。在这项工作中,我们提出了PointPillars,一种新型编码器,它利用PointNets来学习以垂直列(pillar)组织的点云的表示。虽然编码后的特征可以与任何标准的2D卷积检测架构一起使用,但我们进一步提出了一个精简的下游网络。广泛的实验表明,PointPillars在速度和准确性方面都比以前的编码器有着显著的优势。尽管只使用激光雷达,我们完整的检测流程在3D和俯视图的KITTI基准测试中都明显优于现有技术,甚至在融合方法中也是如此。这种检测性能是在每秒62帧的速度下实现的:运行时间提高了2到4倍。我们方法的更快版本在每秒105帧的速度下达到了现有技术的水平。这些基准测试表明,PointPillars是适用于点云中目标检测的合适编码方式。
1.引言
在城市环境中部署自动驾驶车辆(AVs)面临着一项艰巨的技术挑战。在其他任务中,AVs需要实时检测和跟踪移动物体,如车辆、行人和骑车者。为了实现这一目标,自动驾驶车辆依赖于多个传感器,其中激光雷达可能是最重要的。激光雷达使用激光扫描器测量与环境的距离,从而生成稀疏的点云表示。传统上,激光雷达的机器人技术流程通过自底向上的流程来解释这些点云,涉及背景减除,接着是时空聚类和分类。
随着深度学习在计算机视觉领域取得的巨大进步,大量的文献研究探讨了将这项技术应用于激光雷达点云目标检测的可能性。尽管这两种模态之间有许多相似之处,但存在两个关键的区别:1)点云是一种稀疏表示,而图像是密集的;2)点云是三维的,而图像是二维的。因此,从点云中进行目标检测并不简单地适用于标准的图像卷积流程。
一些早期的研究集中于使用3D卷积或将点云投影到图像中进行处理。近期的方法倾向于从俯视图(Bird’s Eye View,BEV)的角度观察激光雷达点云。这种俯视图的透视图提供了几个优势。首先,俯视图可以保留物体的尺度信息。其次,在俯视图中进行卷积可以保留局部的距离信息。如果在图像视图中进行卷积,将会模糊深度信息。
然而,俯视图往往非常稀疏,这使得直接应用卷积神经网络变得不切实际和低效。一种常见的解决方法是将地面划分为一个规则的网格,例如10 x 10 厘米,然后对每个网格单元中的点执行手工特征编码方法[2, 11, 26, 32]。然而,这种方法可能不够优化,因为硬编码的特征提取方法可能无法泛化到新的配置,除非进行大量的工程努力。为了解决这些问题,并在Qi等人开发的PointNet设计的基础上构建,VoxelNet [33]是第一个在这个领域真正进行端到端学习的方法之一。VoxelNet将空间划分为体素(voxels),对每个体素应用PointNet,然后在垂直轴上应用3D卷积中间层以合并特征,最后应用2D卷积检测架构。虽然VoxelNet的性能很强大,但推理时间为4.4 Hz,太慢无法实时部署。最近的SECOND 改进了VoxelNet的推理速度,但3D卷积仍然是瓶颈。
在本研究中,我们提出了PointPillars:一种用于3D物体检测的方法,它只使用2D卷积层进行端到端学习。PointPillars使用一种新颖的编码器,它在点云的垂直列(pillar)上学习特征,以预测物体的3D方向框。这种方法有几个优势。首先,通过学习特征而不是依赖固定编码器,PointPillars可以利用点云所表示的全部信息。此外,通过在pillar而不是体素上操作,无需手动调整垂直方向的划分。最后,pillar非常高效,因为所有关键操作都可以用2D卷积来表达,而在GPU上计算2D卷积非常高效。学习特征的另一个好处是PointPillars不需要手动调整来使用不同的点云配置,例如多个激光雷达扫描或甚至雷达点云。
我们在公开的KITTI检测挑战中评估了我们的PointPillars网络,该挑战要求在BEV或3D中检测汽车、行人和骑车人[5]。虽然我们的Point Pillars网络只使用激光雷达点云进行训练,但它在性能上超越了目前的最先进方法,包括使用激光雷达和图像的方法,从而为BEV和3D检测建立了新的性能标准(表格1和表格2)。同时,PointPillars的运行速度为每秒62帧,比以前的最先进方法快2-4倍(图1)。PointPillars还允许在速度和准确性之间进行权衡;在某种设置下,我们在每秒超过100帧的速度下达到了与最先进方法相匹配的性能(图5)。我们还发布了代码以重现我们的结果。

图1 我们提出的PointPillars(PP)方法在KITTI测试集上的俯视图性能与速度对比图中。单独使用激光雷达的方法用蓝色圆圈表示,激光雷达和视觉相结合的方法用红色方块表示。同时,我们还绘制了来自KITTI排行榜的顶尖方法:M:MV3D,A:AVOD,C:ContFuse,V:VoxelNet,F:Frustum PointNet ,S:SECOND ,P+:PIXOR++。PointPillars在速度和准确性方面大大优于所有其他单独使用激光雷达的方法。除了在行人方面稍逊一筹外,它也优于所有基于融合的方法。在3D指标上取得了类似的表现(表2)。
1.1 最近工作
1.1.1 使用CNNs的目标检测
从Girshick等人的开创性工作开始,卷积神经网络(CNN)架构已经成为图像检测领域的最先进方法。随后的一系列论文提倡了一种两阶段的解决方案。在第一阶段,区域建议网络(RPN)提出候选建议,然后将其裁剪和调整大小,然后由第二阶段的网络进行分类。两阶段的方法在重要的视觉基准数据集,如COCO 上占据主导地位,这些数据集最初是由Liu等人提出的单阶段架构。在单阶段架构中,通过一个步骤对一组预测进行密集的anchor框回归和分类,提供了快速且简单的架构。最近,Lin等人有力地证明,通过他们提出的焦点损失函数,单阶段方法在准确性和运行时间方面优于两阶段方法。在这项工作中,我们采用了单阶段方法。
1.1.2 Lidar点云中的目标检测
点云中的物体检测本质上是一个三维问题。因此,自然而然地使用3D卷积网络进行检测,这是一些早期方法的范例。虽然这些方法提供了直接的架构,但它们的速度很慢;例如,Engelcke等人对单个点云进行推断需要0.5秒的时间。最近的大多数方法通过将3D点云投影到地面平面或图像平面上来改善运行时性能。在最常见的范式中,点云被组织成体素,并且每个垂直列中的体素集被编码为固定长度的手工特征编码,以形成伪图像,可以由标准图像检测架构处理。其中一些值得注意的工作包括MV3D,AVOD,PIXOR和Complex YOLO,它们都使用相同的固定编码范例作为其架构的第一步。前两种方法还将激光雷达特征与图像特征融合,创建多模态检测器。MV3D和AVOD中使用的融合步骤迫使它们使用两阶段的检测流程,而PIXOR和Complex YOLO使用单阶段的流程。
在Qi等人的开创性工作中,他们提出了一种用于学习无序点集的简单架构——PointNet,为实现端到端学习提供了一条途径。VoxelNet是最早在激光雷达点云中应用PointNet进行物体检测的方法之一。在该方法中,PointNet被应用于体素,然后通过一系列3D卷积层、2D主干网络和检测头进行处理。这实现了端到端的学习,但与之前依赖于3D卷积的工作类似,VoxelNet速度较慢,对于单个点云需要225毫秒的推断时间(4.4 Hz)。另一种最近的方法Frustum PointNet使用PointNet对从图像中投影到3D中的检测框生成的锥体内的点云进行分割和分类。与其他融合方法相比,Frustum PointNet在基准性能方面取得了很高的表现,但其多阶段设计使得端到端学习不切实际。最近的SECOND方法对VoxelNet进行了一系列改进,实现了更强的性能和更快的速度(20 Hz),但他们无法去除昂贵的3D卷积层。
1.2 贡献
- 我们提出了一种新颖的点云编码器和网络,称为PointPillars,它在点云上进行操作,实现了端到端的3D目标检测网络训练。
- 我们展示了所有在pillar上的计算都可以表示为密集的2D卷积,这使得推理速度达到每秒62帧;比其他方法快2-4倍。
- 我们在KITTI数据集上进行了实验,并在车辆、行人和骑车者的鸟瞰图(BEV)和3D基准测试中展示了最先进的结果。
- 我们进行了多项消融实验,以研究影响强大检测性能的关键因素。
2. PointPillars 网络
PointPillars接受点云作为输入,并对汽车、行人和骑车者估计有方向的3D包围框。它由三个主要阶段组成(图2):(1) 特征编码网络,将点云转换成稀疏的伪图像;(2) 一个2D卷积主干网络,将伪图像处理成高级表示;和(3) 一个检测头,用于检测和回归3D包围框。
2.1 点云转换伪图像
为了应用2D卷积架构,我们首先将点云转换为伪图像。
我们用l表示点云中的一个点,其坐标为x、y和z。作为第一步,点云在x-y平面上被离散化为等间距的网格,创建了一组柱体P,其中|P|=B。需要注意的是,柱体是一个在z方向上具有无限空间范围的体素,因此不需要超参数来控制z维度的分箱。然后,每个柱体中的点被装饰(增强)为r、xc、yc、zc、xp、yp,其中r是反射率,下标c表示到柱体中所有点的算术平均距离,下标p表示相对于柱体x、y中心的偏移(有关设计细节,请参见第7.3节)。现在,装饰后的激光雷达点ˆl是9维的。虽然我们关注的是激光雷达点云,但可以通过改变每个点的装饰来使用其他点云,如雷达或RGB-D[27]。
由于点云的稀疏性,柱体集合大部分为空,而非空的柱体通常只包含少量点。例如,在
0.1
6
2
0.16^2
0.162 平方米的网格分辨率下,来自HDL-64E Velodyne激光雷达的点云在KITTI数据集中的 typcial range内有6,000-9,000个非空柱体,这相当于约97%的稀疏度。我们利用这种稀疏性,通过对每个样本(P)和每个柱体(N)设置限制,创建一个大小为(D, P, N)的密集张量。如果一个样本或柱体的数据量过大,无法适应这个张量,那么数据将被随机采样。相反地,如果一个样本或柱体的数据量过少,无法填充张量,将进行零填充(zero padding)。
接下来,我们使用了PointNet的简化版本,在这个版本中,对于每个点,我们应用一个线性层,然后接着使用BatchNorm [10]和ReLU [19]来生成一个大小为(C, P, N)的张量。然后对通道进行max操作,创建一个大小为(C, P)的输出张量。需要注意的是,线性层可以被表示为张量上的1x1卷积,从而实现非常高效的计算。
编码完成后,特征被散回到原始柱体位置,创建一个大小为(C, H, W)的伪图像,其中H和W表示画布的高度和宽度。需要注意的是,我们选择使用柱体而不是体素,可以避免在[33]的卷积中间层中使用昂贵的3D卷积操作。
2.2主干网络
我们使用了与Voxel类似的骨干网络,其结构如图2所示。该骨干网络包含两个子网络:一个自顶向下的网络,用于生成逐渐变小的空间分辨率特征,以及一个进行上采样和拼接顶部特征的第二个网络。自顶向下的骨干网络可以用一系列块Block(S, L, F)来描述。每个块的步幅为S(相对于原始输入伪图像进行测量)。每个块由L个输出通道数为F的3x3 2D卷积层组成,每个卷积层后面跟着BatchNorm和ReLU。层内的第一个卷积具有步幅
S
/
S
i
n
S/S_{in}
S/Sin,以确保在接收到步幅为
S
i
n
S_{in}
Sin的输入块后,该块在步幅为S上进行操作。块内的所有后续卷积的步幅为1。
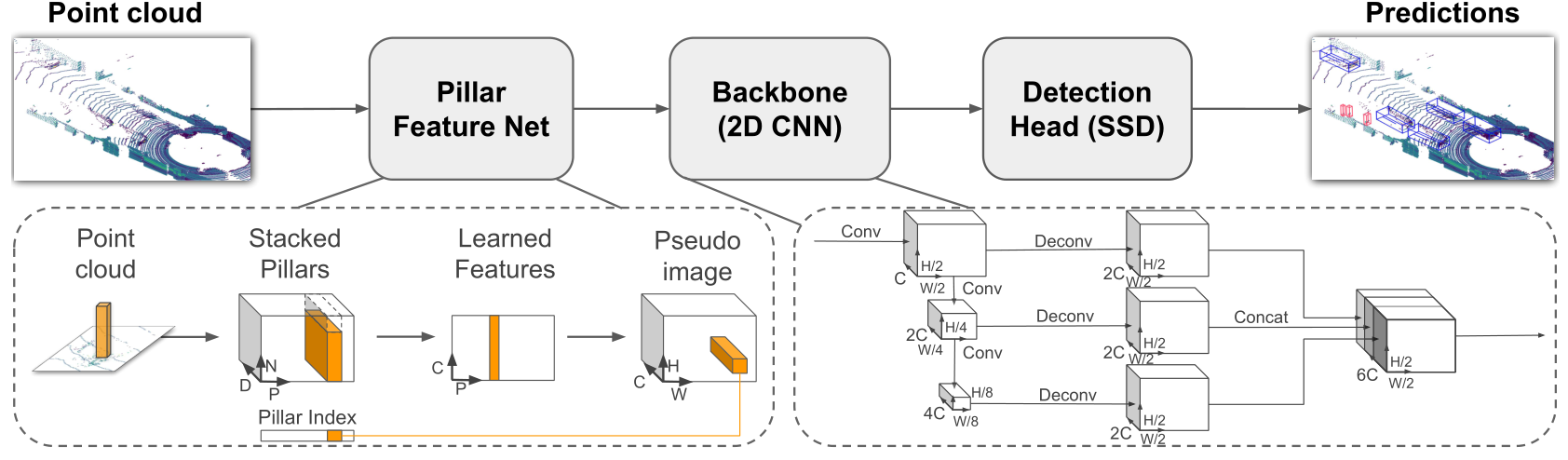
通过上采样和拼接,将来自每个自顶向下块的最终特征组合如下。首先,使用具有Ffinal个特征的转置2D卷积将特征从初始步幅Sin上采样为最终步幅Sout(两者再次相对于原始伪图像进行测量),得到上采样特征Up(Sin, Sout, F)。然后,对上采样特征应用BatchNorm和ReLU。最终的输出特征是来自不同步幅的所有特征的拼接。
2.3检测头
我们使用单次检测器(SSD)[18]的设置来执行3D物体检测。如果有兴趣进行不同的任务(例如分割),只需要将检测头替换为专门用于所需任务的头部即可。与SSD类似,我们使用2D交并比(IoU)[4]将先验框与真实值匹配。匹配时不考虑边界框的高度和高程;相反,对于2D匹配,高度和高程成为额外的回归目标。















 3128
3128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









