






前言
将开源的大语言预训练模型部署到用户设备上进行推理应用,特别是结合用户专业领域知识库构建AI应用,让AI在回答时更具有专业性,目前已经有很多成熟的应用方案。其中,支持大模型本地化部署的平台及工具很多,比较出名的有ollama、vLLM、LangChain、Ray Serve等,大大简化了模型的部署工作,并提供模型全生命周期管理。
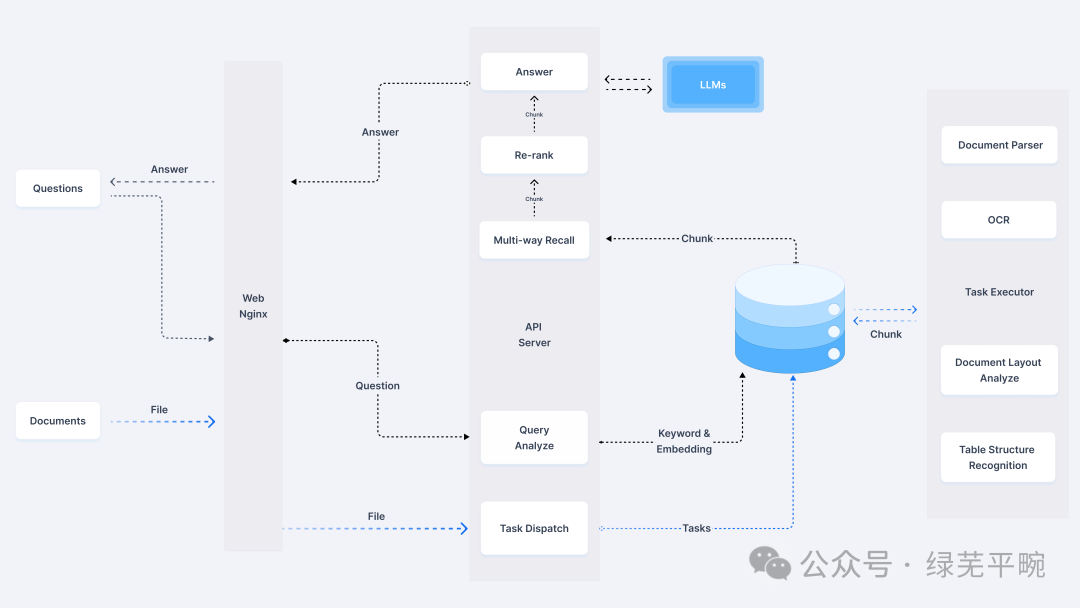
对应地,需要知识库构建的相应工具,能处理各种格式(doc/pdf/txt/xls等)的各种文档,能够直接读取文档并处理大量信息资源,包括文档上传、自动抓取在线文档,然后进行文本的自动分割、向量化处理,来实现本地检索增强生成(RAG)等功能。这类工具主要有RAGFlow、MaxKB、AnythingLLM、FastGPT、Dify 、Open WebUI 等。本文将采用ollama + RAGFlow方式进行搭建,系统架构如下:
1 安装ollama
ollama是一个开源的大型语言模型服务工具,旨在帮助用户在本地环境中部署和运行大型语言模型,其核心功能是提供一个简单、灵活的方式,将这些复杂的AI模型从云端迁移到本地机器上,简化大型语言模型在本地环境中的运行和管理。它不仅为开发者提供了一个强大的平台来部署和定制AI模型,而且也让终端用户能够更加私密和安全地与这些智能系统进行交互。
(1)执行如下命令安装
curl -fsSL https://ollama.com/install.sh | sh
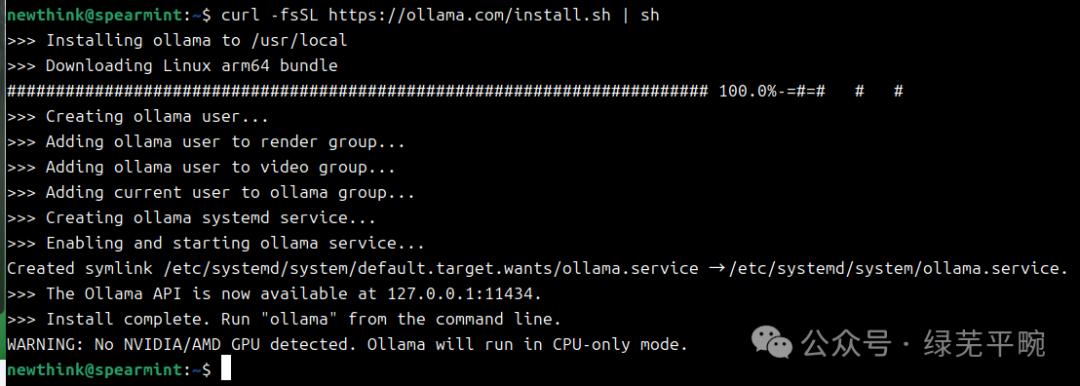
在安装过程中,ollama会识别相应的GPU加速卡,若未识别相应设备,则使用CPU模式
GPU模式“NVIDIA GPU installed”
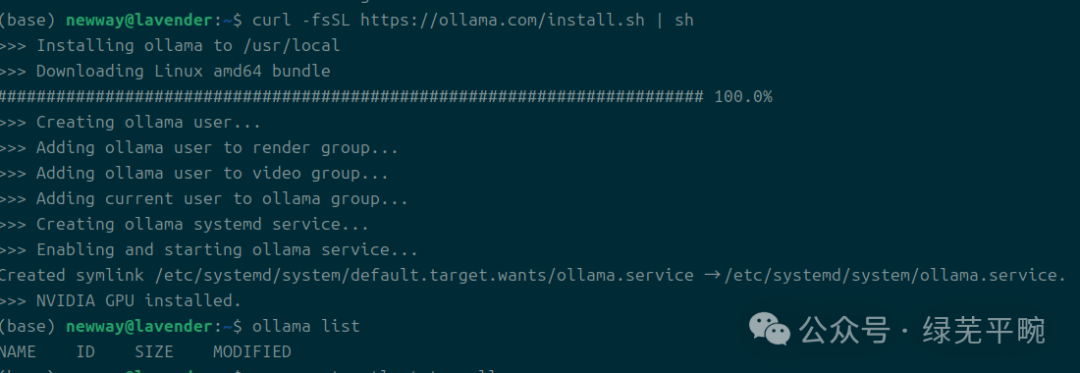
CPU模式“No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode”
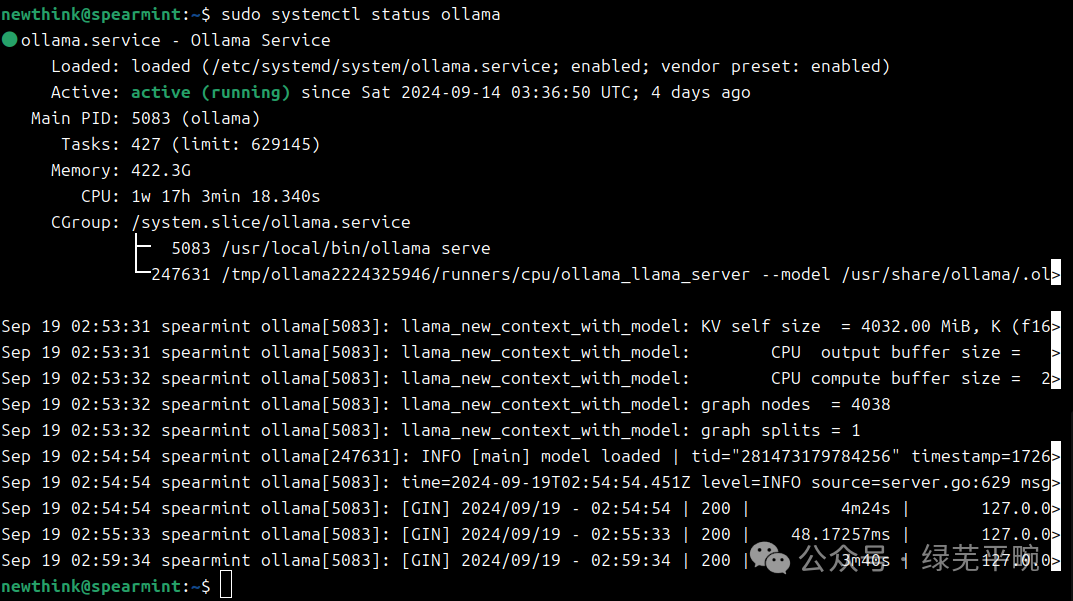
(2)安装后查看ollama状态
sudo systemctl status ollama
(3)设置ollama环境变量
sudo vi /etc/systemd/system/ollama.service
增加Environment=”OLLAMA_HOST=0.0.0.0:11434”,否则后面在RAGFlow容器环境下配置连接时,无法连接ollama.
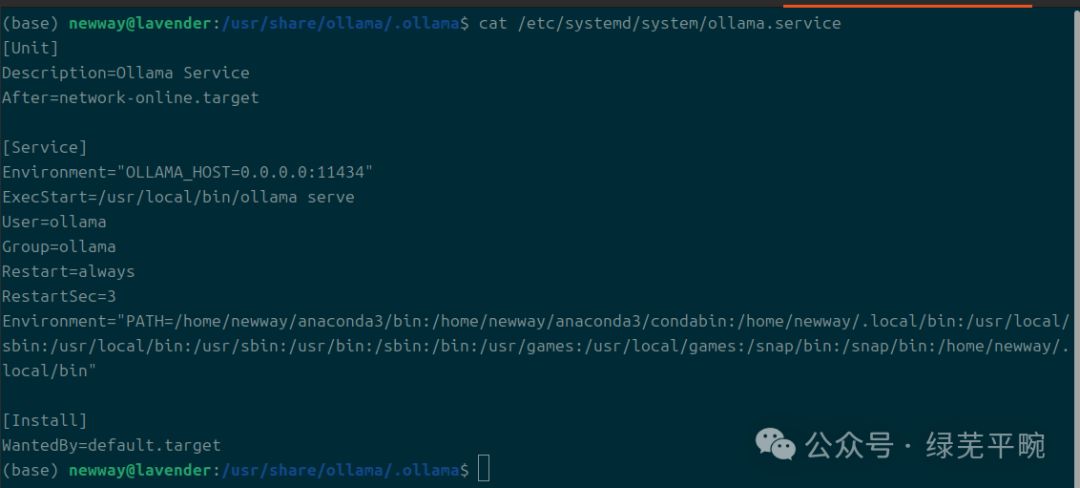
# 修改并重启服务
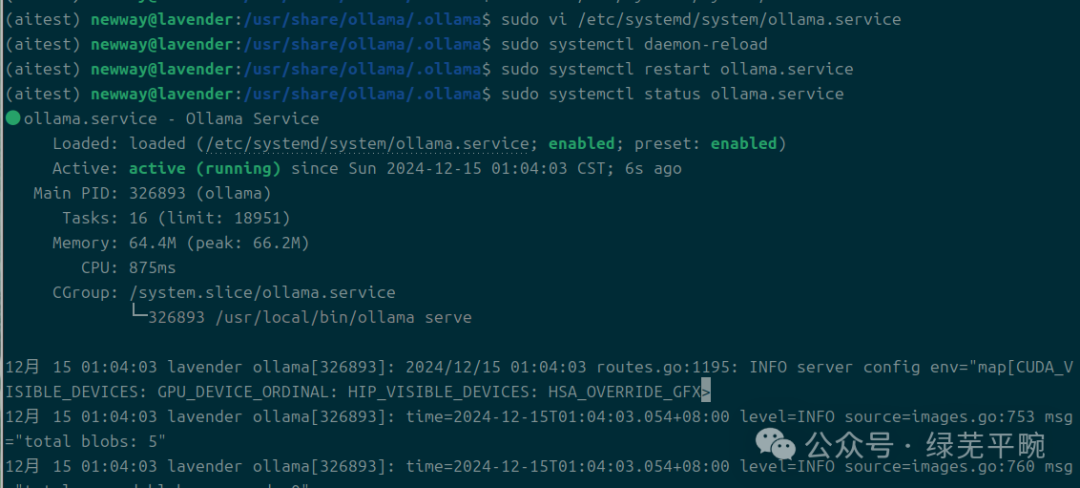
sudo systemctl daemon-reload
sudo systemctl restart ollama.service
sudo systemctl status ollama.service
2 部署千问大模型
(1) 模型下载
与docker类似,可以通过ollama pull 命令进行预训练模型下载,目前ollama已支持许多大模型,可以通过访问https://ollama.com/library获取相关信息。
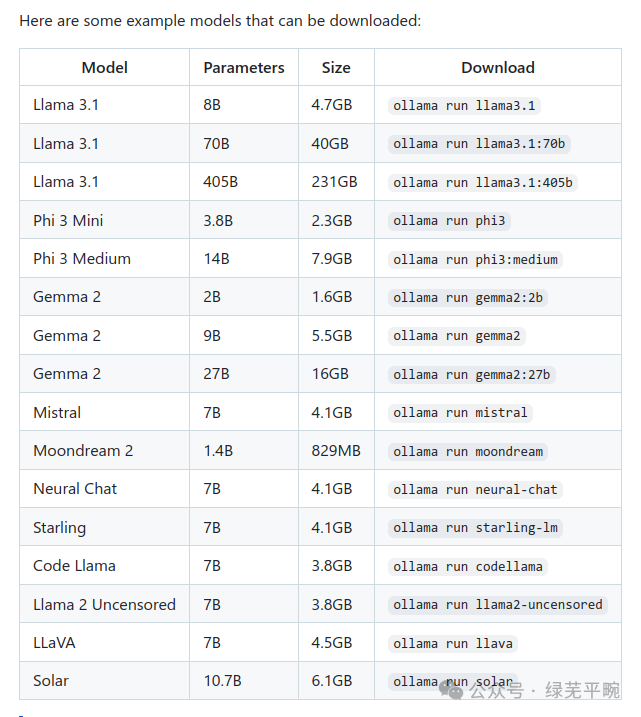
这里使用ollama run qwen2.5:7b,当本地没有qwen2.5:7b预训练模型时,ollama将先下载模型到本地,然后运行该模型。

测试运行正常,可进行问答测试。基于ollama的千问7b大模型部署完毕。
3 安装RAGFlow
RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。RAGFlow部署采用的是docker容器化部署,因组件较多使用了多个容器,需要通过docker compose进行多容器部署方式。
(1)执行如下命令克隆RAGFlow仓库
#参考官方手册https://ragflow.io/docs/dev/进行操作即可:
git clone https://github.com/infiniflow/ragflow.git
cd ragflow
git checkout -f v0.14.1
(2)修改docker子目录下的.env文件,进行初始化配置
这里特别要注意的是,在初始化环境变量里RAGFLOW_IMAGE环境变量指向的是标签为v0.14.1-slim镜像文件,该镜像未打包embedding models,我这里修改为v0.14.1。
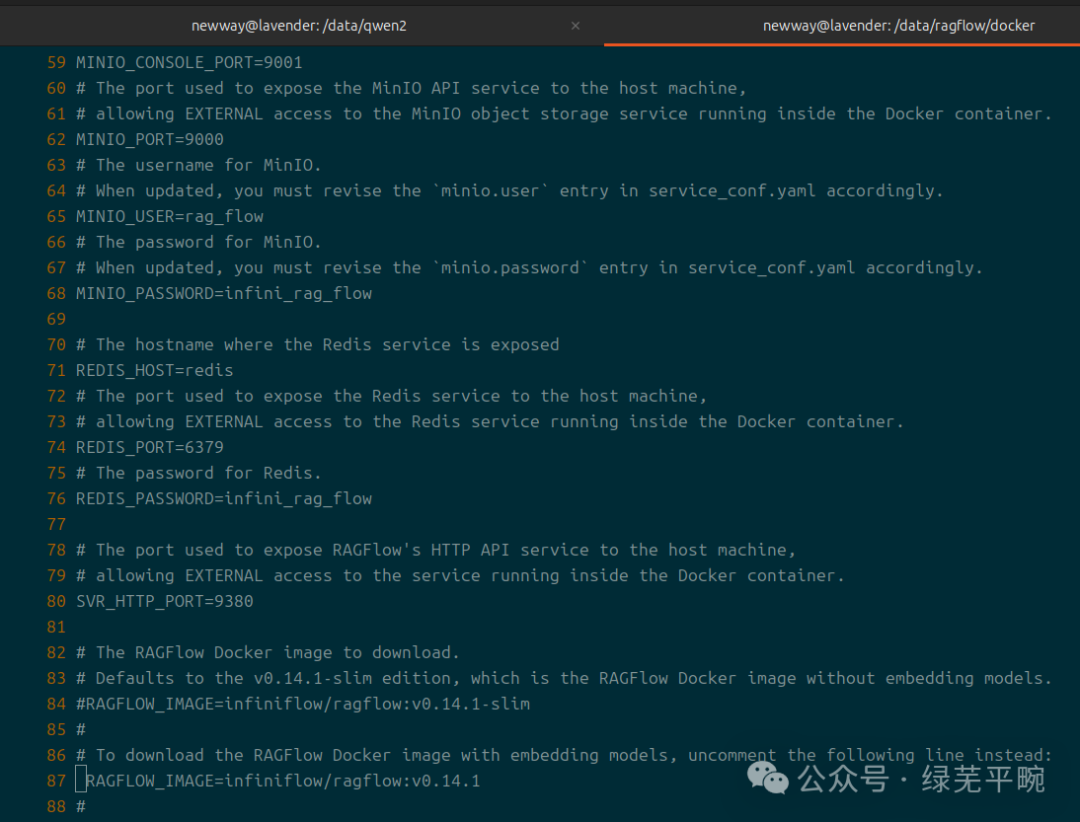
其他变量参数包括相关组件的端口,应用的用户初始化密码、镜像下载地址等,按需进行调整和设置。
vi docker/.env
注释掉84行,使用第87行。
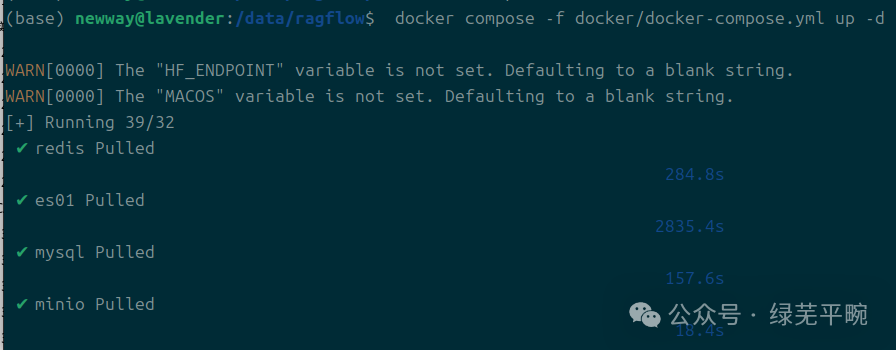
(3)进入ragflow目录,使用docker compose启动应用
进入 docker 文件夹,利用编译好的 Docker 镜像启动服务器,将开始将镜像下载到本地并完成启动:
cd ragflow
docker compose -f docker/docker-compose.yml up -d
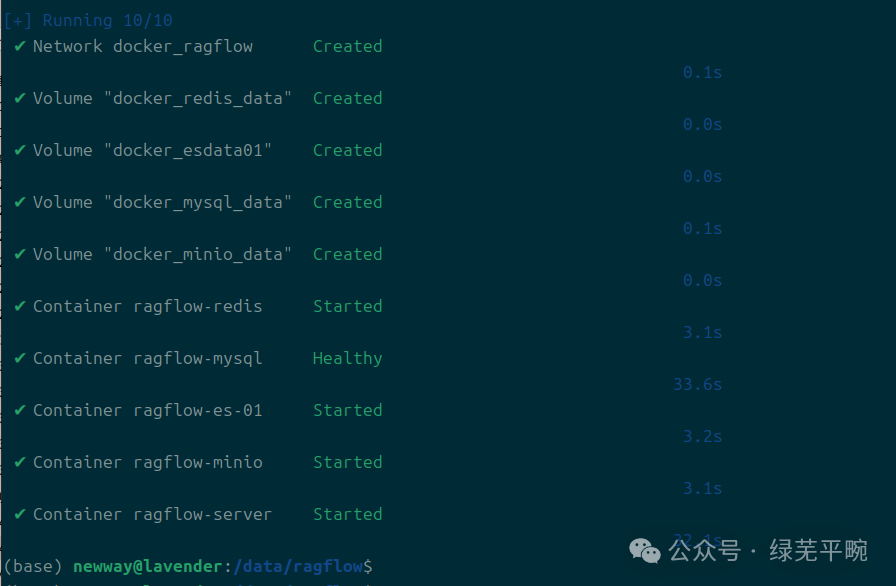
(4)查看ragflow相关组件及启动情况
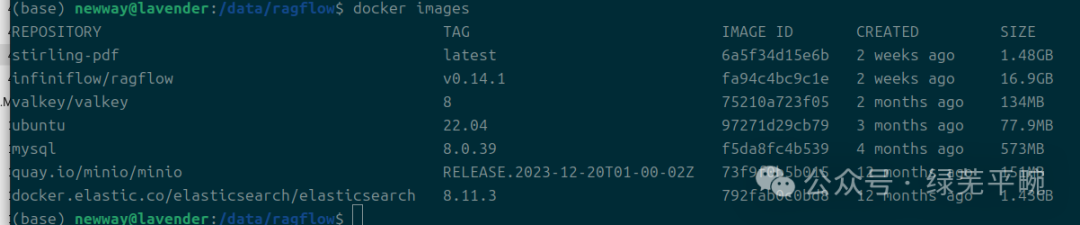
docker images
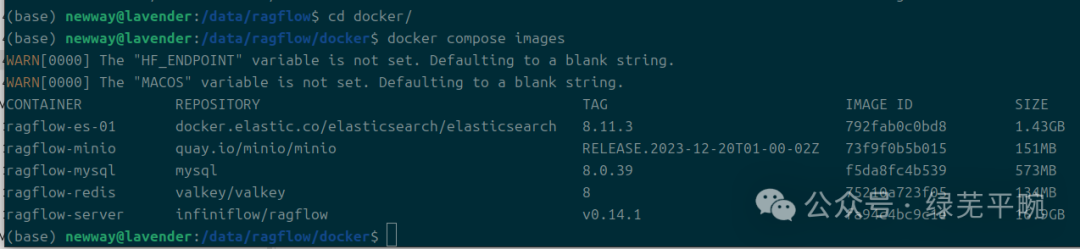
docker compose images
docker logs -f ragflow-server

4 配置RAGFlow-接入本地大模型
In your web browser, enter the IP address of your server and log in to RAGFlow.With the default settings, you only need to enter http://IP_OF_YOUR_MACHINE (sans port number) as the default HTTP serving port 80 can be omitted when using the default configurations.
在这里输入本机地址,因没更改默认端口即80,进入如下界面,第一次需要进行注册并登录。
完成注册登录后,进入如下页面,将页面调整为中文。
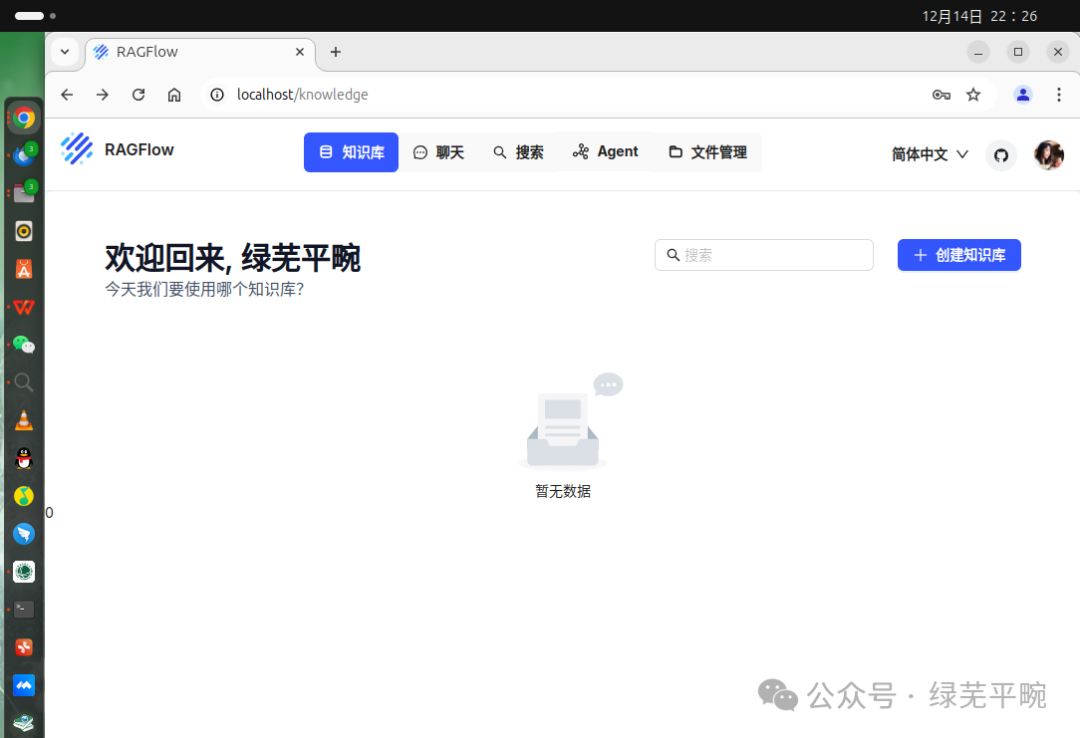
点击图像进入如下界面,配置模型提供商,这里默认为各种在线大模型供应商模型接入,但需要你去相应的模型供应商申请API key填入。
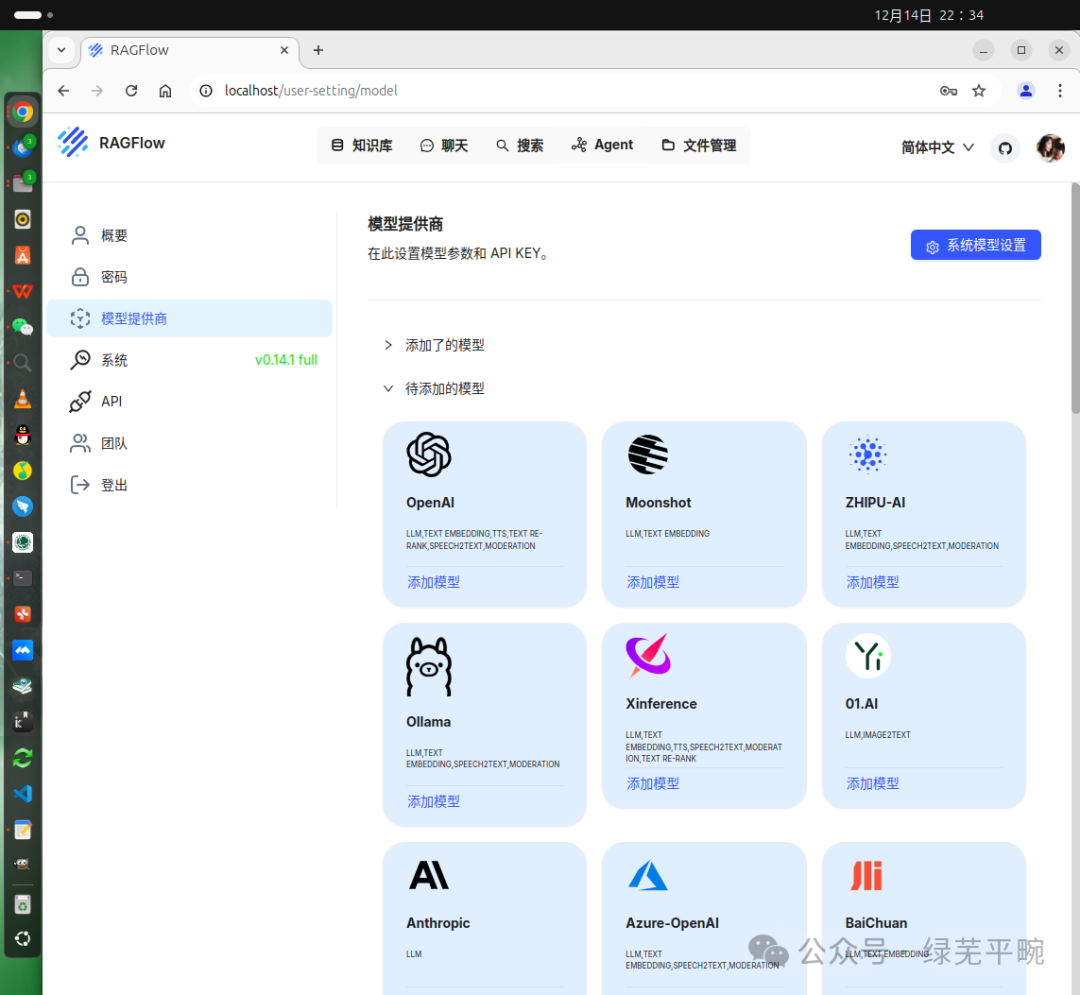
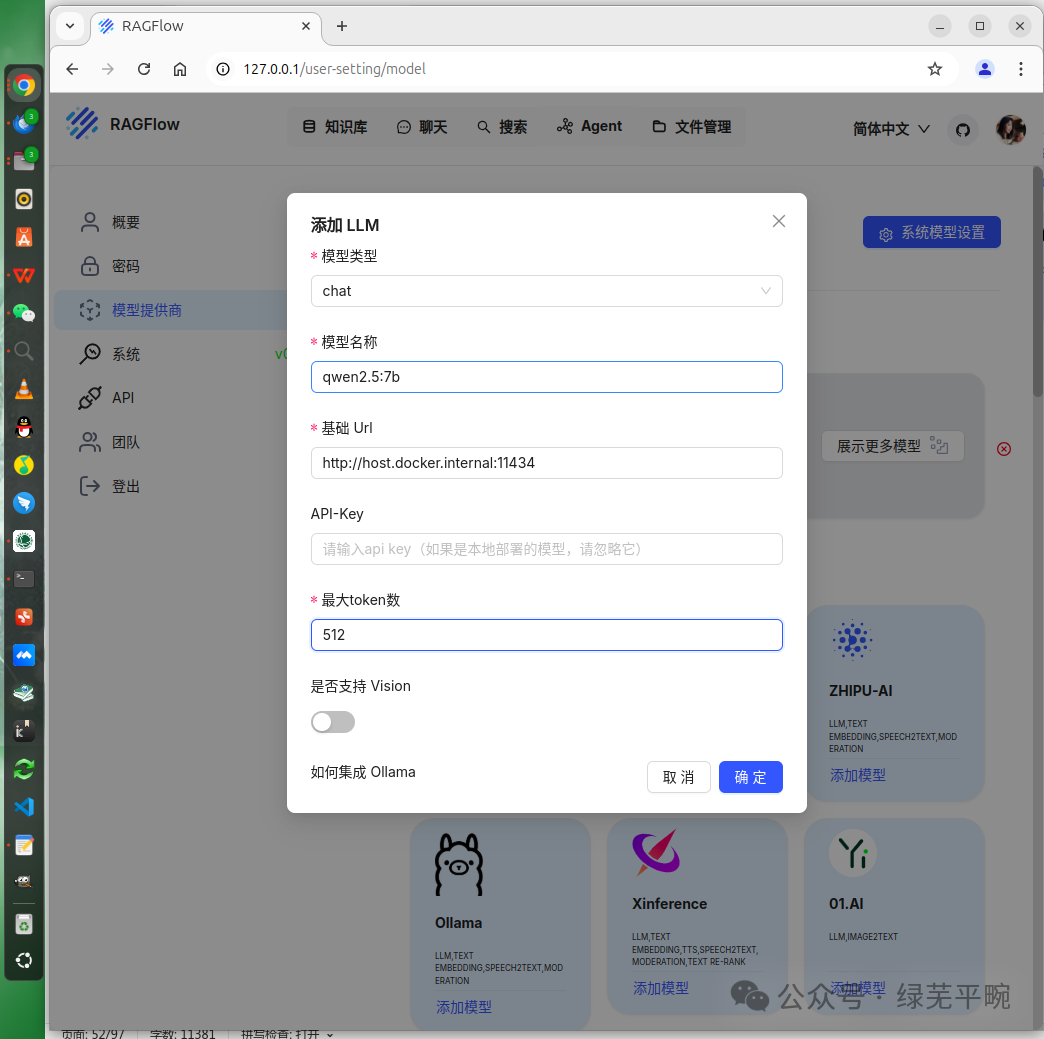
这里,我们配置接入本地部署的ollama管理的大模型
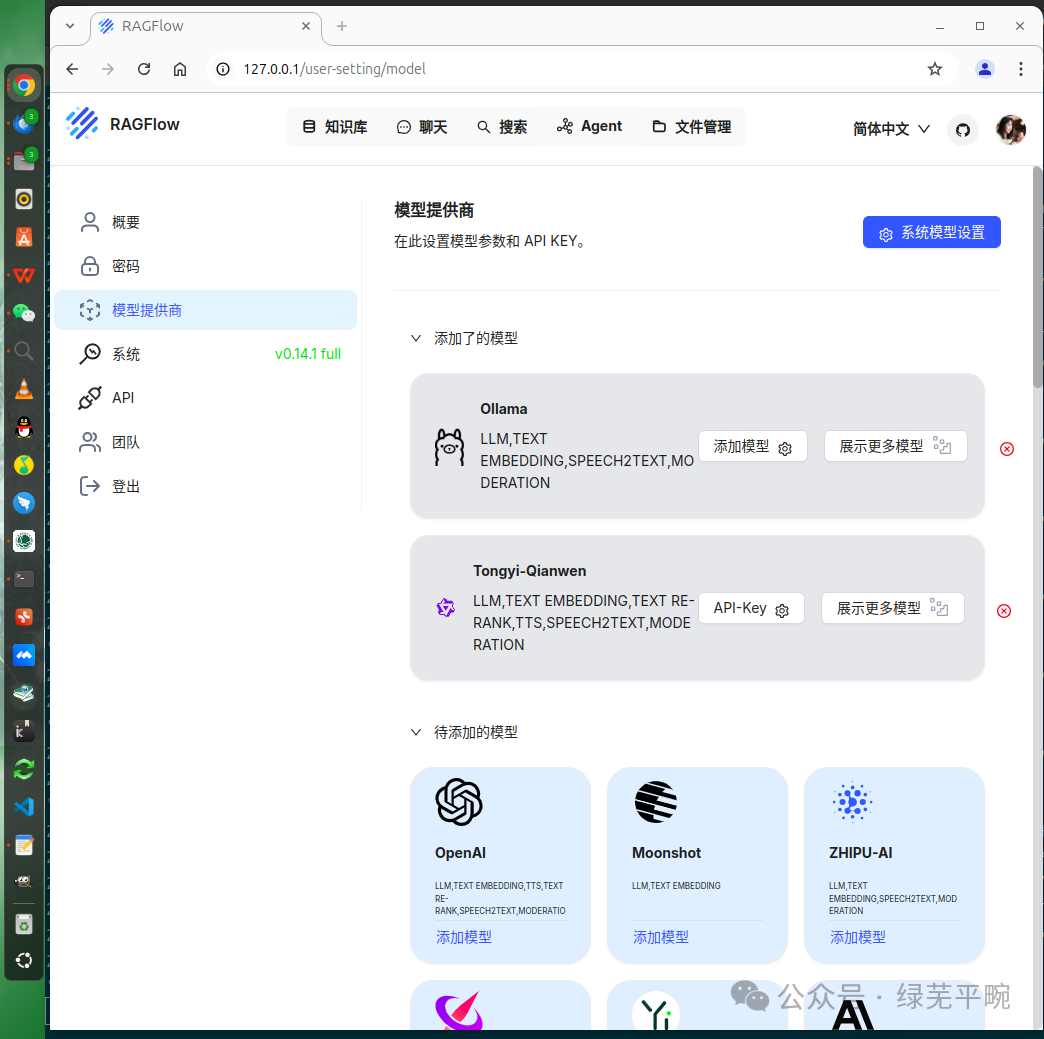
添加成功后,显示如下:
5 配置RAGFlow-创建知识库
进行初始化配置后,点击保存。
上传个人相关知识文档等,由系统进行解析处理。
点击新增文件,上传相关文档。可以当前选择,也可以拖拽文件夹
点击解析,系统将对上传文档进行文本识别(图片类文档)、分割、向量化处理。
由于个人笔记本性能问题,这里只做简单测试,不做大规模文档入库。解析完成后,进行检索测试。这里从王国维的东山杂记里,尝试检索柳如是的信息。
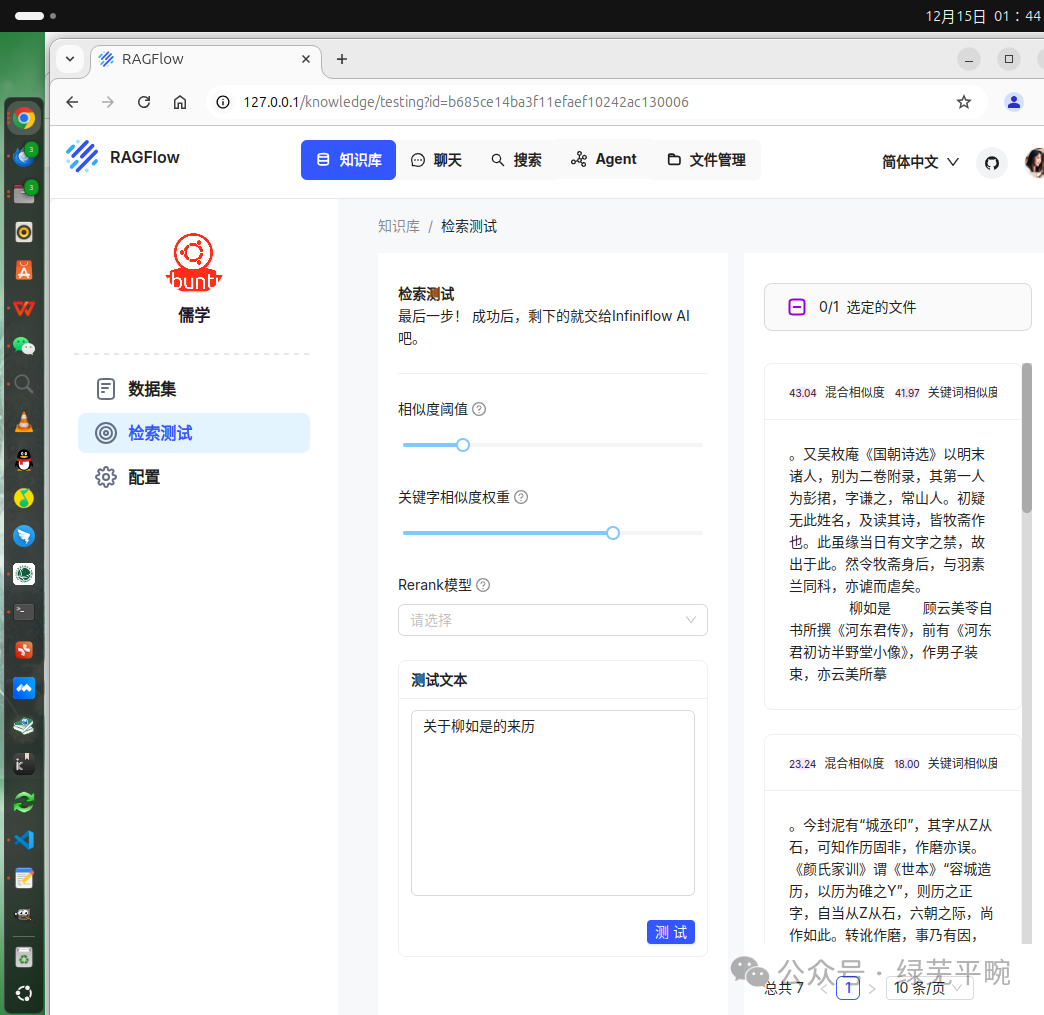
可以看到,向量化后的资料库里已经有了柳如是的信息,但切片不完整。由此可见,在进行资料入库时需要有针对性的辅助切片标注等。另外,也可能跟文言文有关系。
6 智能体应用测试
建立一个特定专业的智能体(Agent),相当于你的一个数字健身,赋于它一个角色(role),制定提示词(Prompt),设置自由度,温度等。
(1)新建助理
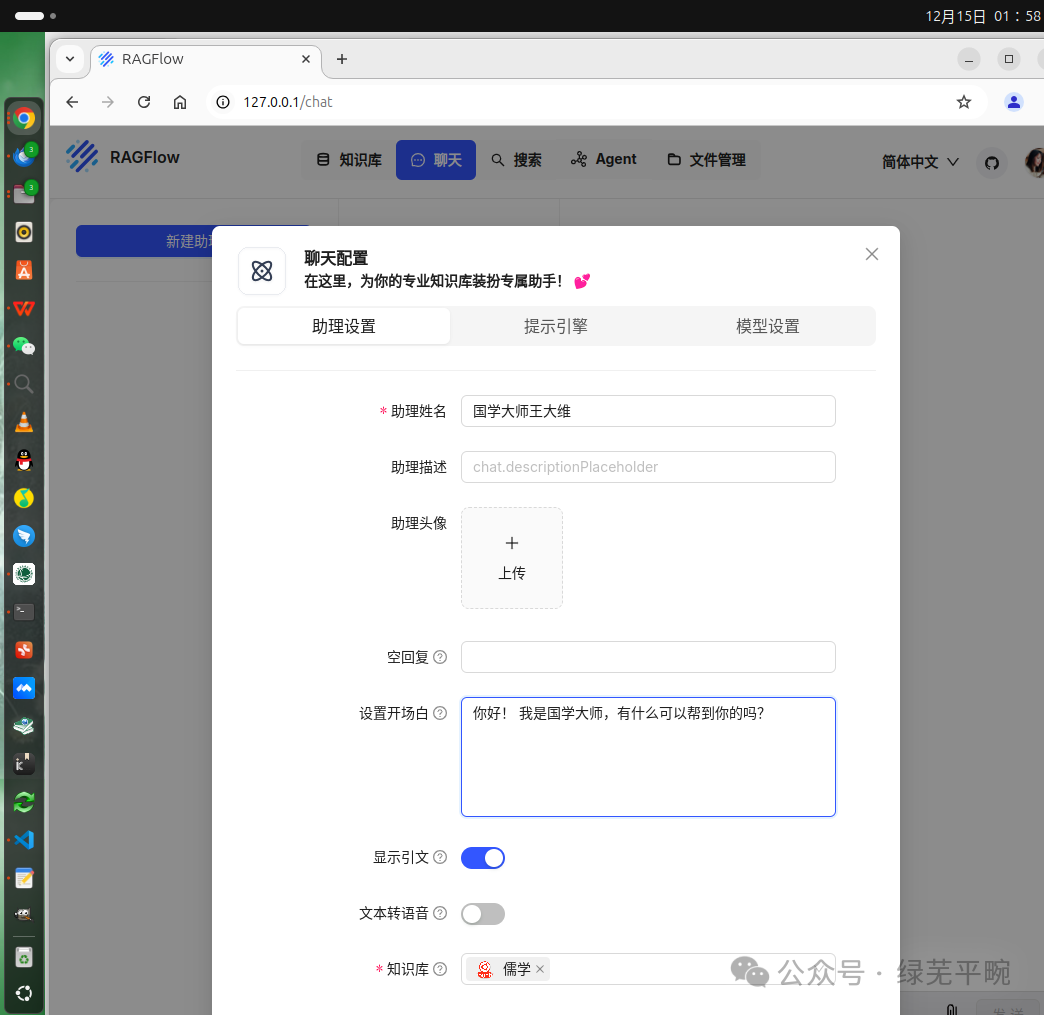
角色设定及提示词
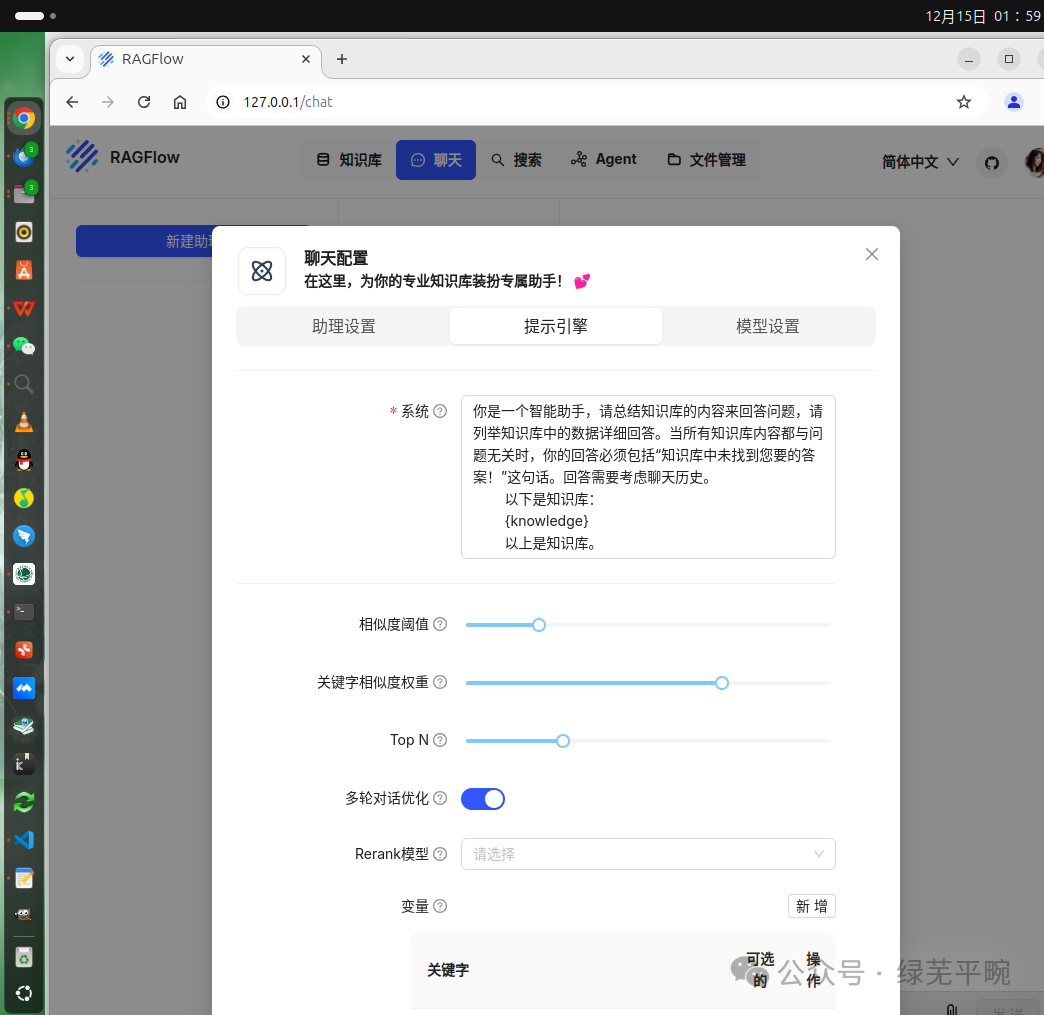
设置使用本地千问大模型并结合知识库内容进行回答,设定自由度为“精确”
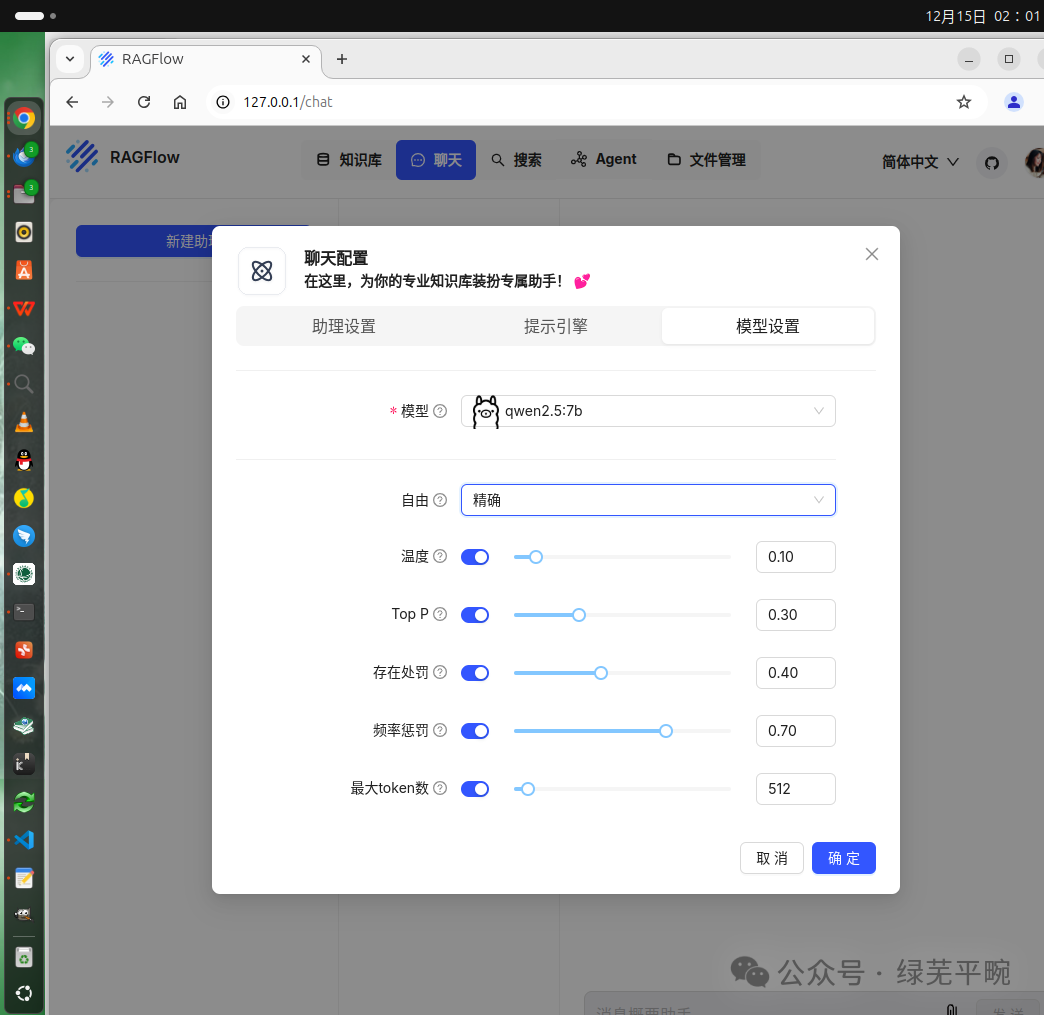
下面开始问题测试:先只用本地千问大模型进行问答测试,我问他灶神是谁,千问没有正面回答我的问题。
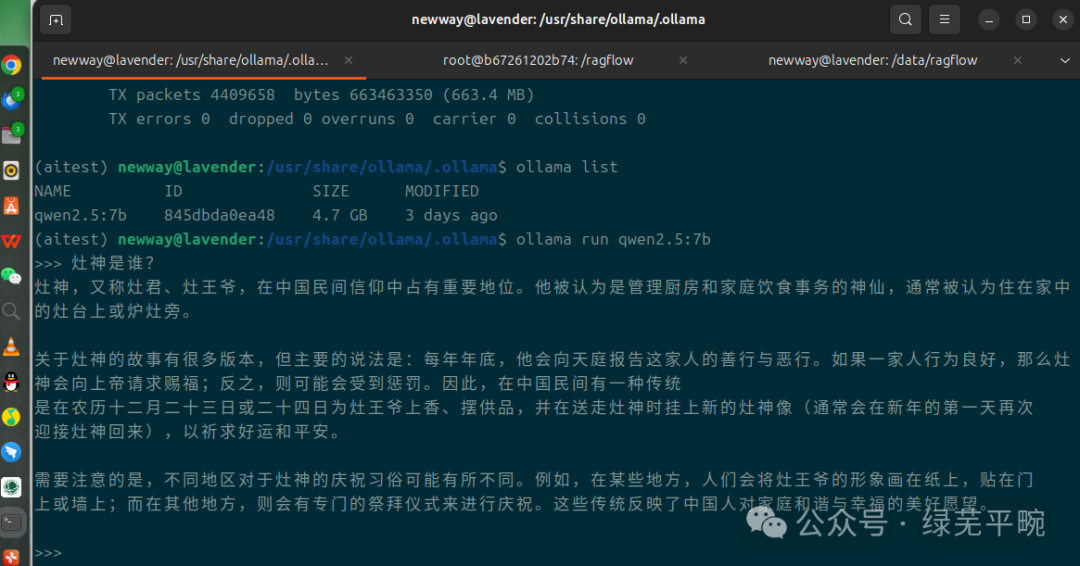
尝试追问灶神具体是谁?我让千问从王国维的《东山杂记》里找答案,AI开始胡说八道了,大模型幻觉病发作。
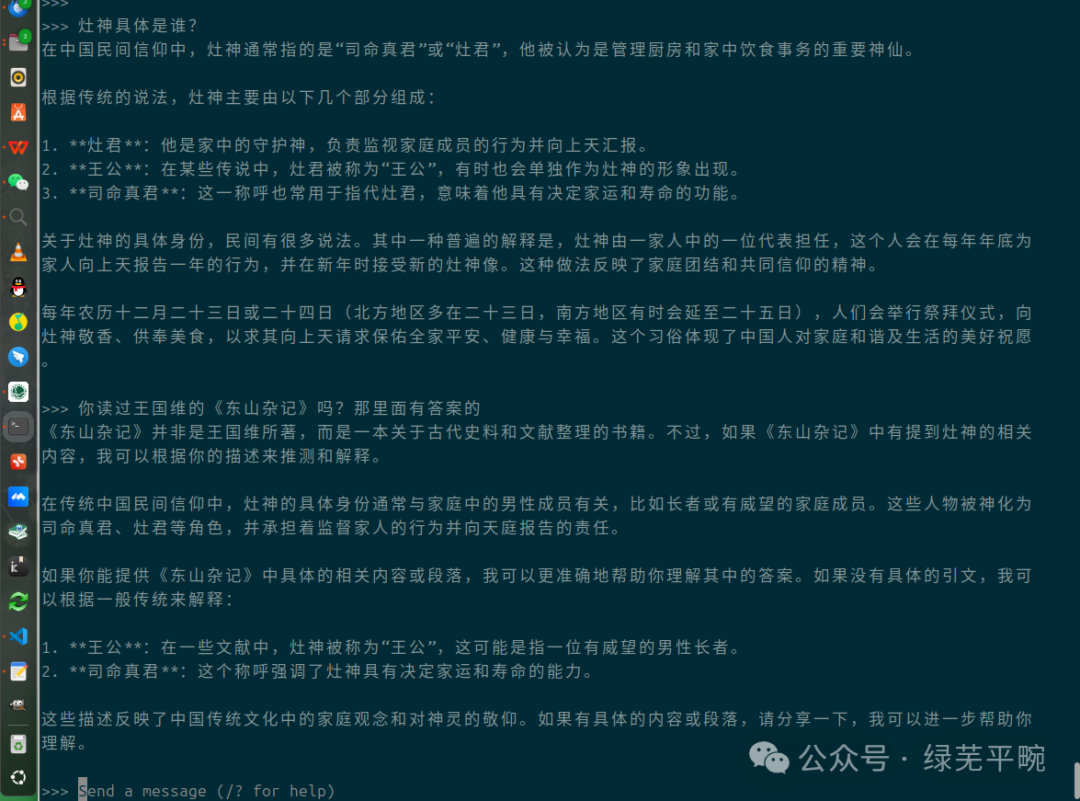
再通过本地千问大模型结合本地知识库进行问答测试,该智能助理很快从本地知识库中找到了准确的答案。
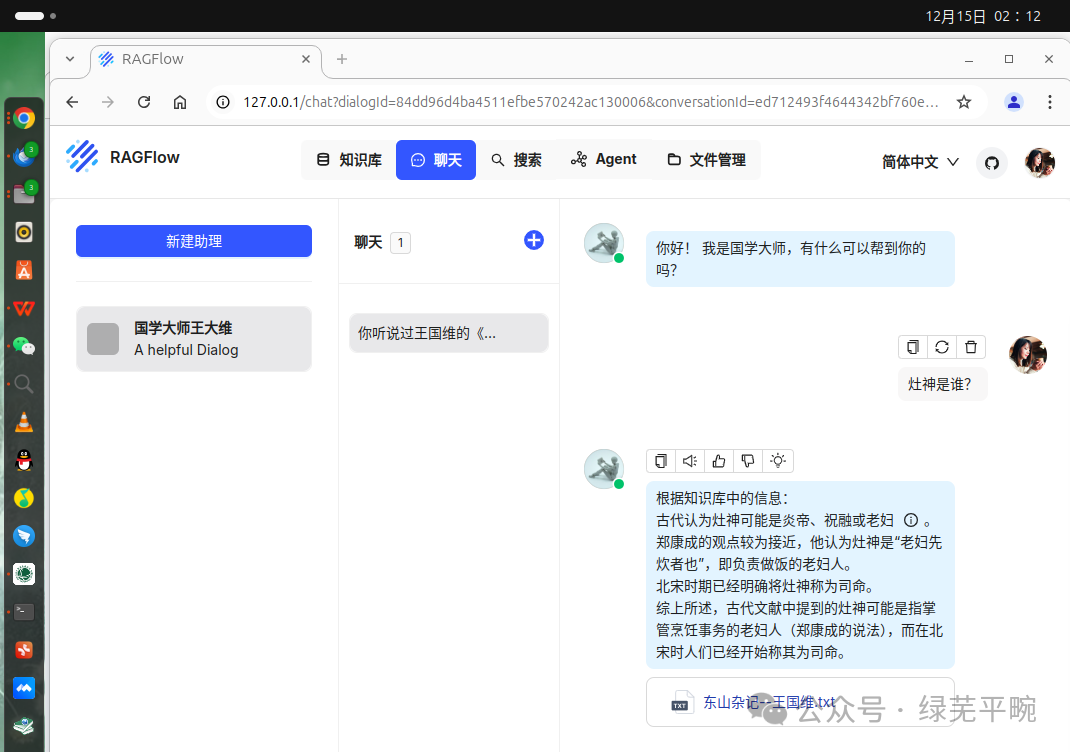
可以看到,在专业知识库下回答的问题更有特定性。但总的来看,人工智能对文言文的理解还是较白话文差一些。通过RAGFlow可以建立不同领域的个人知识库及智能体,本文演示了如何结合AI大模型和知识库进行RAG。
附:古之灶神
古之灶神,《淮南子》以为炎帝,戴圣及贾逵、许慎皆以为祝融。郑康成据《礼器》文以为灶,老妇之祭,其注《礼器》云“老妇先炊者也,以礼意求之”。郑说为近。然臧文仲燔柴于爨,郑君云“时人以为祭火神乃燔柴”。则周时已有以祀神者,至后世祀司命,盖已三变。观李少君以祠灶、偲道、却老方见武帝,则汉初方士或已为此说矣。(王国维.《东山杂记》)
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 8833
8833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









