






本文使用本地部署的llm,embedding模型,自定义prompt提取诡秘之主知识图谱,并使用neo4j可视化 实体等信息,在命令行中不管是global还是local搜索达到了不错的效果。花了一周时间研究graphrag,期间遇到的问题和相关解决办法如下。
流程:
grapharg官方上手:https://microsoft.github.io/graphrag/posts/get_started/
步骤:
- 模型部署和环境搭建
- mkdir -p ./guimi/input 下载txt格式小说到input文件夹下
- python -m graphrag.index --init --root ./guimi 初始化文件guimi文件夹,出现settings.yaml文件和prompt文件是我们后续需要修改的。
- 修改完yaml文件和自定义prompt后就可以开始index
- 开始query
- 配置neo4j的docker 容器,可视化知识图谱。
模型部署和环境搭建:
- 使用vllm在本地部署qwen2-72b-instruct模型,可以使用其他支持openai格式调用的模型。
- 在本地使用xinference部署bge-m3 embedding模型,xinfrence本身支持使用openai的api调用embedding服务。
- conda在本地创建graphrag的运行环境,用于执行graphrag相关命令和作为运行neo4j jupyternote(如下)的内核环境。
conda create -n graphrag2 python==3.11
pip install graphrag
pip install --quiet pandas neo4j-rust-ext #安装neo4j的依赖包
settings.yaml文件修改
settings.yaml文件中我修改的内容如下,其他部分我没有做出修改。
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_chat
model: qwen2-72b-instruct
model_supports_json: false # 虽然qwen2-72b可以输出json格式的内容,但是我这里还是设置了false。
#因为我发现设置true的时候,graphrag会一直尝试"repair json",后文我会详细讲解这个问题.
api_base: http://1xx.xx.xxx.xx:80/v1
parallelization:
stagger: 0.3
async_mode: threaded # or asyncio
embeddings:
async_mode: threaded # or asyncio
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_embedding # or azure_openai_embedding
model: bge-embedding #这个是我在xinference中加载本地bge-m3模型自定义的名称。
api_base: http://1xx.xx.xxx.xx:9997/v1
自定义prompt
entity_extraction.txt
-Goal-
Given a text document that is potentially relevant to this activity and a list of entity types, identify all entities of those types from the text and all relationships among the identified entities. Special attention is paid to the unique elements and styles of Chinese online novels.
-Steps-
1. Identify all entities. For each identified entity, extract the following information:
- entity_name: Name of the entity, capitalized
- entity_type: One of the following types: [章节, 角色, 场景, 地点, 时间, 物品, 组织, 事件, 能力, 概念, 职业, 社会阶层, 货币, 语言, 仪式, 神灵, 超自然现象, 情感, 动作, 对话]
- entity_description: Comprehensive description of the entity's attributes and activities
Format each entity as ("entity"{tuple_delimiter}<entity_name>{tuple_delimiter}<entity_type>{tuple_delimiter}<entity_description>)
2. From the entities identified in step 1, identify all pairs of (source_entity, target_entity) that are *clearly related* to each other.
For each pair of related entities, extract the following information:
- source_entity: name of the source entity, as identified in step 1
- target_entity: name of the target entity, as identified in step 1
- relationship_description: explanation as to why you think the source entity and the target entity are related to each other
- relationship_strength: an integer score between 1 to 10, indicating strength of the relationship between the source entity and target entity
Format each relationship as ("relationship"{tuple_delimiter}<source_entity>{tuple_delimiter}<target_entity>{tuple_delimiter}<relationship_description>{tuple_delimiter}<relationship_strength>)
3. Return output in Chinese as a single list of all the entities and relationships identified in steps 1 and 2. Use **{record_delimiter}** as the list delimiter.
4. If you have to translate into Chinese, just translate the descriptions, nothing else!
5. When finished, output {completion_delimiter}.
######################
-Examples-
######################
Example 1:
entity_types: [章节, 角色, 场景, 地点, 时间, 物品, 组织, 事件, 能力, 概念, 职业, 社会阶层, 货币, 语言, 仪式, 神灵, 超自然现象, 情感, 动作, 对话]
text:
第一部 小丑
第一章 绯红
痛!
好痛!
头好痛!
光怪陆离满是低语的梦境迅速支离破碎,熟睡中的周明瑞只觉脑袋抽痛异常,仿佛被人用棒子狠狠抡了一下,不,更像是遭尖锐的物品刺入太阳穴并伴随有搅动!
######################
output:
("entity"{tuple_delimiter}第一部 小丑{tuple_delimiter}章节{tuple_delimiter}小说的第一部分,标题为"小丑")
{record_delimiter}
("entity"{tuple_delimiter}第一章 绯红{tuple_delimiter}章节{tuple_delimiter}第一部中的第一章,标题为"绯红")
{record_delimiter}
("entity"{tuple_delimiter}周明瑞{tuple_delimiter}角色{tuple_delimiter}小说的主要角色,经历了剧烈的头痛)
{record_delimiter}
("entity"{tuple_delimiter}光怪陆离满是低语的梦境{tuple_delimiter}场景{tuple_delimiter}周明瑞所经历的梦境,充满奇异景象和低语)
{record_delimiter}
("entity"{tuple_delimiter}头痛{tuple_delimiter}情感{tuple_delimiter}周明瑞所感受到的强烈痛苦)
{record_delimiter}
("relationship"{tuple_delimiter}周明瑞{tuple_delimiter}头痛{tuple_delimiter}周明瑞遭受剧烈的头痛,这是故事开始的关键事件{tuple_delimiter}9)
{record_delimiter}
("relationship"{tuple_delimiter}第一章 绯红{tuple_delimiter}光怪陆离满是低语的梦境{tuple_delimiter}第一章的背景设定,为故事营造神秘氛围{tuple_delimiter}8)
{completion_delimiter}
######################
Example 2:
entity_types: [章节, 角色, 场景, 地点, 时间, 物品, 组织, 事件, 能力, 概念, 职业, 社会阶层, 货币, 语言, 仪式, 神灵, 超自然现象, 情感, 动作, 对话]
text:
视线先是模糊,继而蒙上了淡淡的绯红,目光所及,周明瑞看见面前是一张原木色泽的书桌,正中央放着一本摊开的笔记,纸张粗糙而泛黄,抬头用奇怪的字母文字书写着一句话语,墨迹深黑,醒目欲滴。
笔记本左侧靠桌子边缘,有一叠整整齐齐的书册,大概七八本的样子,它们右手边的墙上镶嵌着灰白色的管道和与管道连通的壁灯。
这盏灯很有西方古典风味,约成年人半个脑袋大小,内层是透明的玻璃,外面用黑色金属围出了栅格。
######################
output:
("entity"{tuple_delimiter}绯红{tuple_delimiter}概念{tuple_delimiter}笼罩周明瑞视线的颜色,可能暗示某种超自然现象)
{record_delimiter}
("entity"{tuple_delimiter}书桌{tuple_delimiter}物品{tuple_delimiter}原木色泽的书桌,放置在周明瑞面前)
{record_delimiter}
("entity"{tuple_delimiter}笔记本{tuple_delimiter}物品{tuple_delimiter}放在书桌中央的笔记本,纸张粗糙泛黄)
{record_delimiter}
("entity"{tuple_delimiter}奇怪的字母文字{tuple_delimiter}语言{tuple_delimiter}笔记本上书写的未知语言)
{record_delimiter}
("entity"{tuple_delimiter}壁灯{tuple_delimiter}物品{tuple_delimiter}西方古典风味的壁灯,与灰白色管道相连)
{record_delimiter}
("relationship"{tuple_delimiter}周明瑞{tuple_delimiter}书桌{tuple_delimiter}周明瑞看到的主要物品,可能暗示他所处的环境{tuple_delimiter}7)
{record_delimiter}
("relationship"{tuple_delimiter}笔记本{tuple_delimiter}奇怪的字母文字{tuple_delimiter}笔记本上记录的文字,可能包含重要信息{tuple_delimiter}8)
{completion_delimiter}
######################
Example 3:
entity_types: [章节, 角色, 场景, 地点, 时间, 物品, 组织, 事件, 能力, 概念, 职业, 社会阶层, 货币, 语言, 仪式, 神灵, 超自然现象, 情感, 动作, 对话]
text:
克莱恩·莫雷蒂,北大陆鲁恩王国阿霍瓦郡廷根市人,霍伊大学历史系刚毕业的学生……
父亲是皇家陆军上士,牺牲于南大陆的殖民冲突,换来的抚恤金让克莱恩有了进入私立文法学校读书的机会,奠定了他考入大学的基础……
母亲是黑夜女神信徒,在克莱恩通过霍伊大学入学考试那年过世……
还有一个哥哥,一个妹妹,共同住在公寓的两居室内……
######################
output:
("entity"{tuple_delimiter}克莱恩·莫雷蒂{tuple_delimiter}角色{tuple_delimiter}北大陆鲁恩王国阿霍瓦郡廷根市人,霍伊大学历史系毕业生)
{record_delimiter}
("entity"{tuple_delimiter}鲁恩王国{tuple_delimiter}地点{tuple_delimiter}故事背景中的一个国家,位于北大陆)
{record_delimiter}
("entity"{tuple_delimiter}廷根市{tuple_delimiter}地点{tuple_delimiter}克莱恩的家乡,位于鲁恩王国阿霍瓦郡)
{record_delimiter}
("entity"{tuple_delimiter}霍伊大学{tuple_delimiter}组织{tuple_delimiter}克莱恩就读的大学,有历史系)
{record_delimiter}
("entity"{tuple_delimiter}皇家陆军{tuple_delimiter}组织{tuple_delimiter}克莱恩父亲曾服役的军队)
{record_delimiter}
("entity"{tuple_delimiter}黑夜女神{tuple_delimiter}神灵{tuple_delimiter}克莱恩母亲信仰的神灵)
{record_delimiter}
("entity"{tuple_delimiter}私立文法学校{tuple_delimiter}组织{tuple_delimiter}克莱恩曾就读的学校,为他上大学奠定基础)
{record_delimiter}
("relationship"{tuple_delimiter}克莱恩·莫雷蒂{tuple_delimiter}霍伊大学{tuple_delimiter}克莱恩是霍伊大学历史系的毕业生{tuple_delimiter}9)
{record_delimiter}
("relationship"{tuple_delimiter}克莱恩·莫雷蒂{tuple_delimiter}黑夜女神{tuple_delimiter}克莱恩的母亲是黑夜女神的信徒,可能影响克莱恩的背景{tuple_delimiter}7)
{completion_delimiter}
######################
Example 4:
entity_types: [章节, 角色, 场景, 地点, 时间, 物品, 组织, 事件, 能力, 概念, 职业, 社会阶层, 货币, 语言, 仪式, 神灵, 超自然现象, 情感, 动作, 对话]
text:
作为历史系毕业生,克莱恩掌握了号称北大陆诸国文字源头的古弗萨克语,以及古代陵寝里经常出现,与祭祀、祈祷相关的赫密斯文……
赫密斯文?周明瑞心头一动,伸手按住抽痛的太阳穴,将视线投向了书桌上摊开的那本笔记,只觉泛黄纸张上的那行文字从奇怪变得陌生,从陌生变得熟悉,从熟悉变得可以解读。
这是用赫密斯文书写的话语!
那深黑欲滴的墨迹如是说:
"所有人都会死,包括我。"
######################
output:
("entity"{tuple_delimiter}古弗萨克语{tuple_delimiter}语言{tuple_delimiter}北大陆诸国文字的源头,克莱恩掌握的语言之一)
{record_delimiter}
("entity"{tuple_delimiter}赫密斯文{tuple_delimiter}语言{tuple_delimiter}古代陵寝中常见的文字,与祭祀和祈祷有关)
{record_delimiter}
("entity"{tuple_delimiter}所有人都会死,包括我{tuple_delimiter}对话{tuple_delimiter}笔记本上用赫密斯文写的话语)
{record_delimiter}
("entity"{tuple_delimiter}解读能力{tuple_delimiter}能力{tuple_delimiter}周明瑞/克莱恩突然获得的能够解读赫密斯文的能力)
{record_delimiter}
("relationship"{tuple_delimiter}克莱恩·莫雷蒂{tuple_delimiter}古弗萨克语{tuple_delimiter}克莱恩作为历史系毕业生掌握的重要语言{tuple_delimiter}8)
{record_delimiter}
("relationship"{tuple_delimiter}周明瑞{tuple_delimiter}解读能力{tuple_delimiter}周明瑞突然获得解读赫密斯文的能力,暗示他可能与克莱恩有某种联系{tuple_delimiter}9)
{record_delimiter}
("relationship"{tuple_delimiter}赫密斯文{tuple_delimiter}所有人都会死,包括我{tuple_delimiter}笔记本上用赫密斯文写的神秘话语,可能暗示重要剧情{tuple_delimiter}10)
{completion_delimiter}
######################
Example 5:
entity_types: [章节, 角色, 场景, 地点, 时间, 物品, 组织, 事件, 能力, 概念, 职业, 社会阶层, 货币, 语言, 仪式, 神灵, 超自然现象, 情感, 动作, 对话]
text:
克莱恩·莫雷蒂,北大陆鲁恩王国阿霍瓦郡廷根市人,霍伊大学历史系刚毕业的学生……
父亲是皇家陆军上士,牺牲于南大陆的殖民冲突,换来的抚恤金让克莱恩有了进入私立文法学校读书的机会,奠定了他考入大学的基础……
母亲是黑夜女神信徒,在克莱恩通过霍伊大学入学考试那年过世……
还有一个哥哥,一个妹妹,共同住在公寓的两居室内……
######################
output:
("entity"{tuple_delimiter}克莱恩·莫雷蒂{tuple_delimiter}角色{tuple_delimiter}北大陆鲁恩王国阿霍瓦郡廷根市人,霍伊大学历史系毕业生)
{record_delimiter}
("entity"{tuple_delimiter}鲁恩王国{tuple_delimiter}地点{tuple_delimiter}故事背景中的一个国家,位于北大陆)
{record_delimiter}
("entity"{tuple_delimiter}廷根市{tuple_delimiter}地点{tuple_delimiter}克莱恩的家乡,位于鲁恩王国阿霍瓦郡)
{record_delimiter}
("entity"{tuple_delimiter}霍伊大学{tuple_delimiter}组织{tuple_delimiter}克莱恩就读的大学,有历史系)
{record_delimiter}
("entity"{tuple_delimiter}皇家陆军{tuple_delimiter}组织{tuple_delimiter}克莱恩父亲曾服役的军队)
{record_delimiter}
("entity"{tuple_delimiter}黑夜女神{tuple_delimiter}神灵{tuple_delimiter}克莱恩母亲信仰的神灵)
{record_delimiter}
("entity"{tuple_delimiter}私立文法学校{tuple_delimiter}组织{tuple_delimiter}克莱恩曾就读的学校,为他上大学奠定基础)
{record_delimiter}
("relationship"{tuple_delimiter}克莱恩·莫雷蒂{tuple_delimiter}霍伊大学{tuple_delimiter}克莱恩是霍伊大学历史系的毕业生{tuple_delimiter}9)
{record_delimiter}
("relationship"{tuple_delimiter}克莱恩·莫雷蒂{tuple_delimiter}黑夜女神{tuple_delimiter}克莱恩的母亲是黑夜女神的信徒,可能影响克莱恩的背景{tuple_delimiter}7)
{completion_delimiter}
######################
Example 6:
entity_types: [章节, 角色, 场景, 地点, 时间, 物品, 组织, 事件, 能力, 概念, 职业, 社会阶层, 货币, 语言, 仪式, 神灵, 超自然现象, 情感, 动作, 对话]
text:
"'占卜家'有什么能力?"
"你的问题不够准确,应该是服用了'占卜家'魔药会获得什么能力?"邓恩·史密斯摇头一笑,灰眸与面孔都背对着红月,藏在了阴影里,"占星术、卡牌占卜、灵摆、灵视以及类似的很多很多东西,当然,不是说你服下魔药,就立刻了解并掌握了它们,魔药只是让你具备学习这些的资格和能力。"
"因为缺乏直接的对敌手段,呵,你应该能够想象到,仪式魔法需要太多的准备,根本不适合遭遇战,所以,相应地,在神秘学知识上,'占卜家'会比'窥秘人'更博学,更专业。"
######################
output:
("entity"{tuple_delimiter}占卜家{tuple_delimiter}职业{tuple_delimiter}一种非凡者职业,需要服用特定魔药,具备学习占星术、卡牌占卜、灵摆、灵视等能力的资格)
{record_delimiter}
("entity"{tuple_delimiter}窥秘人{tuple_delimiter}职业{tuple_delimiter}一种非凡者职业,与占卜家相比可能具有更多直接对敌手段)
{record_delimiter}
("entity"{tuple_delimiter}占星术{tuple_delimiter}能力{tuple_delimiter}占卜家可以学习的一种能力,属于占卜类技能)
{record_delimiter}
("entity"{tuple_delimiter}卡牌占卜{tuple_delimiter}能力{tuple_delimiter}占卜家可以学习的一种能力,通过卡牌进行预测)
{record_delimiter}
("entity"{tuple_delimiter}灵摆{tuple_delimiter}能力{tuple_delimiter}占卜家可以学习的一种能力,可能涉及使用摆动的物体进行占卜)
{record_delimiter}
("entity"{tuple_delimiter}灵视{tuple_delimiter}能力{tuple_delimiter}占卜家可以学习的一种能力,可能涉及看到常人无法看到的事物)
{record_delimiter}
("entity"{tuple_delimiter}仪式魔法{tuple_delimiter}能力{tuple_delimiter}一种需要大量准备的魔法形式,不适合在遭遇战中使用)
{record_delimiter}
("relationship"{tuple_delimiter}占卜家{tuple_delimiter}占星术{tuple_delimiter}占卜家通过服用魔药获得学习占星术的能力{tuple_delimiter}9)
{record_delimiter}
("relationship"{tuple_delimiter}占卜家{tuple_delimiter}神秘学知识{tuple_delimiter}占卜家在神秘学知识方面比窥秘人更博学、更专业{tuple_delimiter}8)
{completion_delimiter}
######################
-Real Data-
######################
entity_types: [章节, 角色, 场景, 地点, 时间, 物品, 组织, 事件, 能力, 概念, 职业, 社会阶层, 货币, 语言, 仪式, 神灵, 超自然现象, 情感, 动作, 对话]
text: {input_text}
######################
output:
community_report.txt
You are an AI assistant that helps a human analyst to perform general information discovery. Information discovery is the process of identifying and assessing relevant information associated with certain entities (e.g., organizations and individuals) within a network.
# Goal
Write a comprehensive report of a community, given a list of entities that belong to the community as well as their relationships and optional associated claims. The report will be used to inform decision-makers about information associated with the community and their potential impact. The content of this report includes an overview of the community's key entities, their legal compliance, technical capabilities, reputation, and noteworthy claims.
# Report Structure
The report should include the following sections:
- TITLE: community's name that represents its key entities - title should be short but specific. When possible, include representative named entities in the title.
- SUMMARY: An executive summary of the community's overall structure, how its entities are related to each other, and significant information associated with its entities.
- IMPACT SEVERITY RATING: a float score between 0-10 that represents the severity of IMPACT posed by entities within the community. IMPACT is the scored importance of a community.
- RATING EXPLANATION: Give a single sentence explanation of the IMPACT severity rating.
- DETAILED FINDINGS: A list of 5-10 key insights about the community. Each insight should have a short summary followed by multiple paragraphs of explanatory text grounded according to the grounding rules below. Be comprehensive.
Return output as a well-formed JSON-formatted string with the following format:
{{
"title": <report_title>,
"summary": <executive_summary>,
"rating": <impact_severity_rating>,
"rating_explanation": <rating_explanation>,
"findings": [
{{
"summary":<insight_1_summary>,
"explanation": <insight_1_explanation>
}},
{{
"summary":<insight_2_summary>,
"explanation": <insight_2_explanation>
}}
]
}}
# Grounding Rules
Points supported by data should list their data references as follows:
"This is an example sentence supported by multiple data references [Data: <dataset name> (record ids); <dataset name> (record ids)]."
Do not list more than 5 record ids in a single reference. Instead, list the top 5 most relevant record ids and add "+more" to indicate that there are more.
For example:
"Person X is the owner of Company Y and subject to many allegations of wrongdoing [Data: Reports (1), Entities (5, 7); Relationships (23); Claims (7, 2, 34, 64, 46, +more)]."
where 1, 5, 7, 23, 2, 34, 46, and 64 represent the id (not the index) of the relevant data record.
Do not include information where the supporting evidence for it is not provided.
# Example Input
-----------
Text:
Entities
id,entity,description
5,VERDANT OASIS PLAZA,Verdant Oasis Plaza is the location of the Unity March
6,HARMONY ASSEMBLY,Harmony Assembly is an organization that is holding a march at Verdant Oasis Plaza
Relationships
id,source,target,description
37,VERDANT OASIS PLAZA,UNITY MARCH,Verdant Oasis Plaza is the location of the Unity March
38,VERDANT OASIS PLAZA,HARMONY ASSEMBLY,Harmony Assembly is holding a march at Verdant Oasis Plaza
39,VERDANT OASIS PLAZA,UNITY MARCH,The Unity March is taking place at Verdant Oasis Plaza
40,VERDANT OASIS PLAZA,TRIBUNE SPOTLIGHT,Tribune Spotlight is reporting on the Unity march taking place at Verdant Oasis Plaza
41,VERDANT OASIS PLAZA,BAILEY ASADI,Bailey Asadi is speaking at Verdant Oasis Plaza about the march
43,HARMONY ASSEMBLY,UNITY MARCH,Harmony Assembly is organizing the Unity March
Output:
{{
"title": "Verdant Oasis Plaza and Unity March",
"summary": "The community revolves around the Verdant Oasis Plaza, which is the location of the Unity March. The plaza has relationships with the Harmony Assembly, Unity March, and Tribune Spotlight, all of which are associated with the march event.",
"rating": 5.0,
"rating_explanation": "The impact severity rating is moderate due to the potential for unrest or conflict during the Unity March.",
"findings": [
{{
"summary": "Verdant Oasis Plaza as the central location",
"explanation": "Verdant Oasis Plaza is the central entity in this community, serving as the location for the Unity March. This plaza is the common link between all other entities, suggesting its significance in the community. The plaza's association with the march could potentially lead to issues such as public disorder or conflict, depending on the nature of the march and the reactions it provokes. [Data: Entities (5), Relationships (37, 38, 39, 40, 41,+more)]"
}},
{{
"summary": "Harmony Assembly's role in the community",
"explanation": "Harmony Assembly is another key entity in this community, being the organizer of the march at Verdant Oasis Plaza. The nature of Harmony Assembly and its march could be a potential source of threat, depending on their objectives and the reactions they provoke. The relationship between Harmony Assembly and the plaza is crucial in understanding the dynamics of this community. [Data: Entities(6), Relationships (38, 43)]"
}},
{{
"summary": "Unity March as a significant event",
"explanation": "The Unity March is a significant event taking place at Verdant Oasis Plaza. This event is a key factor in the community's dynamics and could be a potential source of threat, depending on the nature of the march and the reactions it provokes. The relationship between the march and the plaza is crucial in understanding the dynamics of this community. [Data: Relationships (39)]"
}},
{{
"summary": "Role of Tribune Spotlight",
"explanation": "Tribune Spotlight is reporting on the Unity March taking place in Verdant Oasis Plaza. This suggests that the event has attracted media attention, which could amplify its impact on the community. The role of Tribune Spotlight could be significant in shaping public perception of the event and the entities involved. [Data: Relationships (40)]"
}}
]
}}
# Real Data
Use the following text for your answer. Do not make anything up in your answer.
Text:
{input_text}
The report should include the following sections:
- TITLE: community's name that represents its key entities - title should be short but specific. When possible, include representative named entities in the title.
- SUMMARY: An executive summary of the community's overall structure, how its entities are related to each other, and significant information associated with its entities.
- IMPACT SEVERITY RATING: a float score between 0-10 that represents the severity of IMPACT posed by entities within the community. IMPACT is the scored importance of a community.
- RATING EXPLANATION: Give a single sentence explanation of the IMPACT severity rating.
- DETAILED FINDINGS: A list of 5-10 key insights about the community. Each insight should have a short summary followed by multiple paragraphs of explanatory text grounded according to the grounding rules below. Be comprehensive.
Return output as a well-formed JSON-formatted string with the following format:
{{
"title": <report_title>,
"summary": <executive_summary>,
"rating": <impact_severity_rating>,
"rating_explanation": <rating_explanation>,
"findings": [
{{
"summary":<insight_1_summary>,
"explanation": <insight_1_explanation>
}},
{{
"summary":<insight_2_summary>,
"explanation": <insight_2_explanation>
}}
]
}}
# Grounding Rules
Points supported by data should list their data references as follows:
"This is an example sentence supported by multiple data references [Data: <dataset name> (record ids); <dataset name> (record ids)]."
Do not list more than 5 record ids in a single reference. Instead, list the top 5 most relevant record ids and add "+more" to indicate that there are more.
For example:
"Person X is the owner of Company Y and subject to many allegations of wrongdoing [Data: Reports (1), Entities (5, 7); Relationships (23); Claims (7, 2, 34, 64, 46, +more)]."
where 1, 5, 7, 23, 2, 34, 46, and 64 represent the id (not the index) of the relevant data record.
Do not include information where the supporting evidence for it is not provided.
Output:
summarize_description.txt
You are an expert Cultural Anthropologist with a specialization in digital media and Chinese literature. You are skilled at analyzing social networks, cultural trends, and online communities. You are adept at helping people understand the relations and structure of specific interest groups, particularly within the Chinese web novels domain, by utilizing your knowledge of cultural nuances and digital communication patterns.
Using your expertise, you're asked to generate a comprehensive summary of the data provided below.
Given one or two entities, and a list of descriptions, all related to the same entity or group of entities.
Please concatenate all of these into a single, concise description in Chinese. Make sure to include information collected from all the descriptions.
If the provided descriptions are contradictory, please resolve the contradictions and provide a single, coherent summary.
Make sure it is written in third person, and include the entity names so we have the full context.
Enrich it as much as you can with relevant information from the nearby text, this is very important.
If no answer is possible, or the description is empty, only convey information that is provided within the text.
#######
-Data-
Entities: {entity_name}
Description List: {description_list}
#######
Output:
claim_extraction.txt
这个prompt的内容我未做修改
-Target activity-
You are an intelligent assistant that helps a human analyst to analyze claims against certain entities presented in a text document.
-Goal-
Given a text document that is potentially relevant to this activity, an entity specification, and a claim description, extract all entities that match the entity specification and all claims against those entities.
-Steps-
1. Extract all named entities that match the predefined entity specification. Entity specification can either be a list of entity names or a list of entity types.
2. For each entity identified in step 1, extract all claims associated with the entity. Claims need to match the specified claim description, and the entity should be the subject of the claim.
For each claim, extract the following information:
- Subject: name of the entity that is subject of the claim, capitalized. The subject entity is one that committed the action described in the claim. Subject needs to be one of the named entities identified in step 1.
- Object: name of the entity that is object of the claim, capitalized. The object entity is one that either reports/handles or is affected by the action described in the claim. If object entity is unknown, use **NONE**.
- Claim Type: overall category of the claim, capitalized. Name it in a way that can be repeated across multiple text inputs, so that similar claims share the same claim type
- Claim Status: **TRUE**, **FALSE**, or **SUSPECTED**. TRUE means the claim is confirmed, FALSE means the claim is found to be False, SUSPECTED means the claim is not verified.
- Claim Description: Detailed description explaining the reasoning behind the claim, together with all the related evidence and references.
- Claim Date: Period (start_date, end_date) when the claim was made. Both start_date and end_date should be in ISO-8601 format. If the claim was made on a single date rather than a date range, set the same date for both start_date and end_date. If date is unknown, return **NONE**.
- Claim Source Text: List of **all** quotes from the original text that are relevant to the claim.
Format each claim as (<subject_entity>{tuple_delimiter}<object_entity>{tuple_delimiter}<claim_type>{tuple_delimiter}<claim_status>{tuple_delimiter}<claim_start_date>{tuple_delimiter}<claim_end_date>{tuple_delimiter}<claim_description>{tuple_delimiter}<claim_source>)
3. Return output in English as a single list of all the claims identified in steps 1 and 2. Use **{record_delimiter}** as the list delimiter.
4. When finished, output {completion_delimiter}
-Examples-
Example 1:
Entity specification: organization
Claim description: red flags associated with an entity
Text: According to an article on 2022/01/10, Company A was fined for bid rigging while participating in multiple public tenders published by Government Agency B. The company is owned by Person C who was suspected of engaging in corruption activities in 2015.
Output:
(COMPANY A{tuple_delimiter}GOVERNMENT AGENCY B{tuple_delimiter}ANTI-COMPETITIVE PRACTICES{tuple_delimiter}TRUE{tuple_delimiter}2022-01-10T00:00:00{tuple_delimiter}2022-01-10T00:00:00{tuple_delimiter}Company A was found to engage in anti-competitive practices because it was fined for bid rigging in multiple public tenders published by Government Agency B according to an article published on 2022/01/10{tuple_delimiter}According to an article published on 2022/01/10, Company A was fined for bid rigging while participating in multiple public tenders published by Government Agency B.)
{completion_delimiter}
Example 2:
Entity specification: Company A, Person C
Claim description: red flags associated with an entity
Text: According to an article on 2022/01/10, Company A was fined for bid rigging while participating in multiple public tenders published by Government Agency B. The company is owned by Person C who was suspected of engaging in corruption activities in 2015.
Output:
(COMPANY A{tuple_delimiter}GOVERNMENT AGENCY B{tuple_delimiter}ANTI-COMPETITIVE PRACTICES{tuple_delimiter}TRUE{tuple_delimiter}2022-01-10T00:00:00{tuple_delimiter}2022-01-10T00:00:00{tuple_delimiter}Company A was found to engage in anti-competitive practices because it was fined for bid rigging in multiple public tenders published by Government Agency B according to an article published on 2022/01/10{tuple_delimiter}According to an article published on 2022/01/10, Company A was fined for bid rigging while participating in multiple public tenders published by Government Agency B.)
{record_delimiter}
(PERSON C{tuple_delimiter}NONE{tuple_delimiter}CORRUPTION{tuple_delimiter}SUSPECTED{tuple_delimiter}2015-01-01T00:00:00{tuple_delimiter}2015-12-30T00:00:00{tuple_delimiter}Person C was suspected of engaging in corruption activities in 2015{tuple_delimiter}The company is owned by Person C who was suspected of engaging in corruption activities in 2015)
{completion_delimiter}
-Real Data-
Use the following input for your answer.
Entity specification: {entity_specs}
Claim description: {claim_description}
Text: {input_text}
Output:
开始Index
一般来说,settings.yaml文件和自定义prompt修改后,现在可以直接运行
python -m graphrag.index --root ./guimi
一切顺利的话,indexing-engine.log中不会报错,命令行也会出现"🚀All workflows completed successfully."
artifacts目录中会出现如下parquet文件:
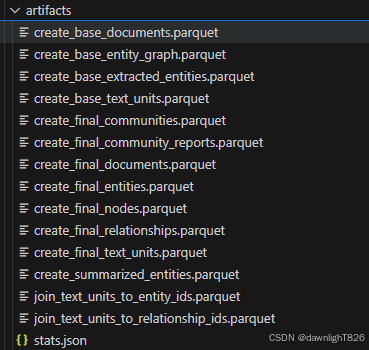
尤其注意是否有create_final_community_reports.parquet文件,可能存在的情况是:虽然"🚀All workflows completed successfully.",但是这个文件会有并不存在的情况,这会影响global和local search能否成功。
自己搞Graphrag总会出现各种小问题,这个我放在最后章节再讲吧。
开始Query
这里我使用《诡秘之主》的前20章作为input
(graphrag) PS D:\instance> python -m graphrag.query --root ./guimi3_copy --method local "主角为什么会加入组织?"
INFO: Reading settings from guimi3_copy\settings.yaml
INFO: Vector Store Args: {}
creating llm client with {'api_key': 'REDACTED,len=9', 'type': "openai_chat", 'model': 'qwen2-72b-instruct', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 1.0, 'n': 1, 'request_timeout': 180.0, 'a独自难以解决的障碍 [Data: Relationships (344, 438, 519, 555, 422, +more); Sources (65)]。加入值夜者组织,克莱恩相信可以接触到神秘世界的常识和相关渠道,积累独自难独自难以解决的障碍 [Data: Relationships (344, 438, 519, 555, 422, +more); Sources (65)]。加入值夜者组织,克莱恩相信可以接触到神秘世界的常识和相关渠道,积累足够的人脉,从而撬动“聚会”,从“正义”和“倒吊人”那里获得最大的收益,形成现实与神秘世界之间的良性循环 [Data: Relationships (344, 438, 519, 555, 422, +more); Sources (65)]。
此外,克莱恩也考虑过加入邓恩口中提到的“心理炼金会”,但意识到这将意味着失去自由,时刻处于危险之中,且他根本不知道如何找到这个组织 [Data: Relationships (344, 438, 519, 555, 422, +more); Sources (65)]。成为文职人员,克莱恩认为有缓冲和退出的机会,而值夜者身份或许能成为更好的保护色,让他在现实与神秘世界中游刃有余 [Data: Relationships (344, 438, 519, 555, 422, +more); Sources (65)]。
在权衡了所有利弊后,克莱恩决定加入值夜者组织,成为文职人员,以期获得神秘世界的知识和资源,保护自己免受超自然事件的威胁,同时也能在现实世界中保持一定的自由和安全 [Data: Relationships (344, 438, 519, 555, 422, +more); Sources (65)]。这一决定反映了克莱恩在面对未知和危险时的智慧与勇气,以及他对于个人成长和安全的深思熟虑。
neo4j可视化知识图谱
- 搭建neo4j的docker环境,可视化知识图谱的关系
docker run \
-p 7474:7474 -p 7687:7687 \
--name neo4j-apoc \
-e NEO4J_apoc_export_file_enabled=true \
-e NEO4J_apoc_import_file_enabled=true \
-e NEO4J_apoc_import_file_use__neo4j__config=true \
-e NEO4J_PLUGINS=\[\"apoc\"\] \
neo4j:5.21.2
浏览器打开http://localhost:7474/,然后输入默认用户名neo4j,默认密码neo4j即可登录,登录之后要求重设密码。
2. 将parquet文件数据加载到neo4j中
jupyternote book文件如下,使用前面创建好的conda环境作为环境内核。
import pandas as pd
# ./guimi3/output/20240829-155446/artifacts
entities = pd.read_parquet('./guimi3/output/20240829-155446/artifacts/create_final_entities.parquet')
relationships = pd.read_parquet('./guimi3/output/20240829-155446/artifacts/create_final_relationships.parquet')
text_units = pd.read_parquet('./guimi3/output/20240829-155446/artifacts/create_final_text_units.parquet')
communities = pd.read_parquet('./guimi3/output/20240829-155446/artifacts/create_final_communities.parquet')
community_reports = pd.read_parquet('./guimi3/output/20240829-155446/artifacts/create_final_community_reports.parquet')
import pandas as pd
from neo4j import GraphDatabase
import time
NEO4J_URI = "neo4j://localhost:7687"
NEO4J_USERNAME = "neo4j"
NEO4J_PASSWORD = "neo4j123" #neo4j设置的密码
NEO4J_DATABASE = "neo4j"
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USERNAME, NEO4J_PASSWORD))
def import_data(cypher, df, batch_size=1000):
for i in range(0,len(df), batch_size):
batch = df.iloc[i: min(i+batch_size, len(df))]
result = driver.execute_query("UNWIND $rows AS value " + cypher,
rows=batch.to_dict('records'),
database_=NEO4J_DATABASE)
print(result.summary.counters)
return
#导入text units
cypher_text_units = """
MERGE (c:__Chunk__ {id:value.id})
SET c += value {.text, .n_tokens}
WITH c, value
UNWIND value.document_ids AS document
MATCH (d:__Document__ {id:document})
MERGE (c)-[:PART_OF]->(d)
"""
import_data(cypher_text_units, text_units)
#加载entities
cypher_entities= """
MERGE (e:__Entity__ {id:value.id})
SET e += value {.human_readable_id, .description, name:replace(value.name,'"','')}
WITH e, value
CALL db.create.setNodeVectorProperty(e, "description_embedding", value.description_embedding)
CALL apoc.create.addLabels(e, case when coalesce(value.type,"") = "" then [] else [apoc.text.upperCamelCase(replace(value.type,'"',''))] end) yield node
UNWIND value.text_unit_ids AS text_unit
MATCH (c:__Chunk__ {id:text_unit})
MERGE (c)-[:HAS_ENTITY]->(e)
"""
import_data(cypher_entities, entities)
#导入relationships
cypher_relationships = """
MATCH (source:__Entity__ {name:replace(value.source,'"','')})
MATCH (target:__Entity__ {name:replace(value.target,'"','')})
// not necessary to merge on id as there is only one relationship per pair
MERGE (source)-[rel:RELATED {id: value.id}]->(target)
SET rel += value {.rank, .weight, .human_readable_id, .description, .text_unit_ids}
RETURN count(*) as createdRels
"""
import_data(cypher_relationships, relationships)
#导入communities
cypher_communities = """
MERGE (c:__Community__ {community:value.id})
SET c += value {.level, .title}
/*
UNWIND value.text_unit_ids as text_unit_id
MATCH (t:__Chunk__ {id:text_unit_id})
MERGE (c)-[:HAS_CHUNK]->(t)
WITH distinct c, value
*/
WITH *
UNWIND value.relationship_ids as rel_id
MATCH (start:__Entity__)-[:RELATED {id:rel_id}]->(end:__Entity__)
MERGE (start)-[:IN_COMMUNITY]->(c)
MERGE (end)-[:IN_COMMUNITY]->(c)
RETURn count(distinct c) as createdCommunities
"""
import_data(cypher_communities, communities)
#导入community_reports
cypher_community_reports = """MATCH (c:__Community__ {community: value.community})
SET c += value {.level, .title, .rank, .rank_explanation, .full_content, .summary}
WITH c, value
UNWIND range(0, size(value.findings)-1) AS finding_idx
WITH c, value, finding_idx, value.findings[finding_idx] as finding
MERGE (c)-[:HAS_FINDING]->(f:Finding {id: finding_idx})
SET f += finding"""
import_data(cypher_community_reports, community_reports)
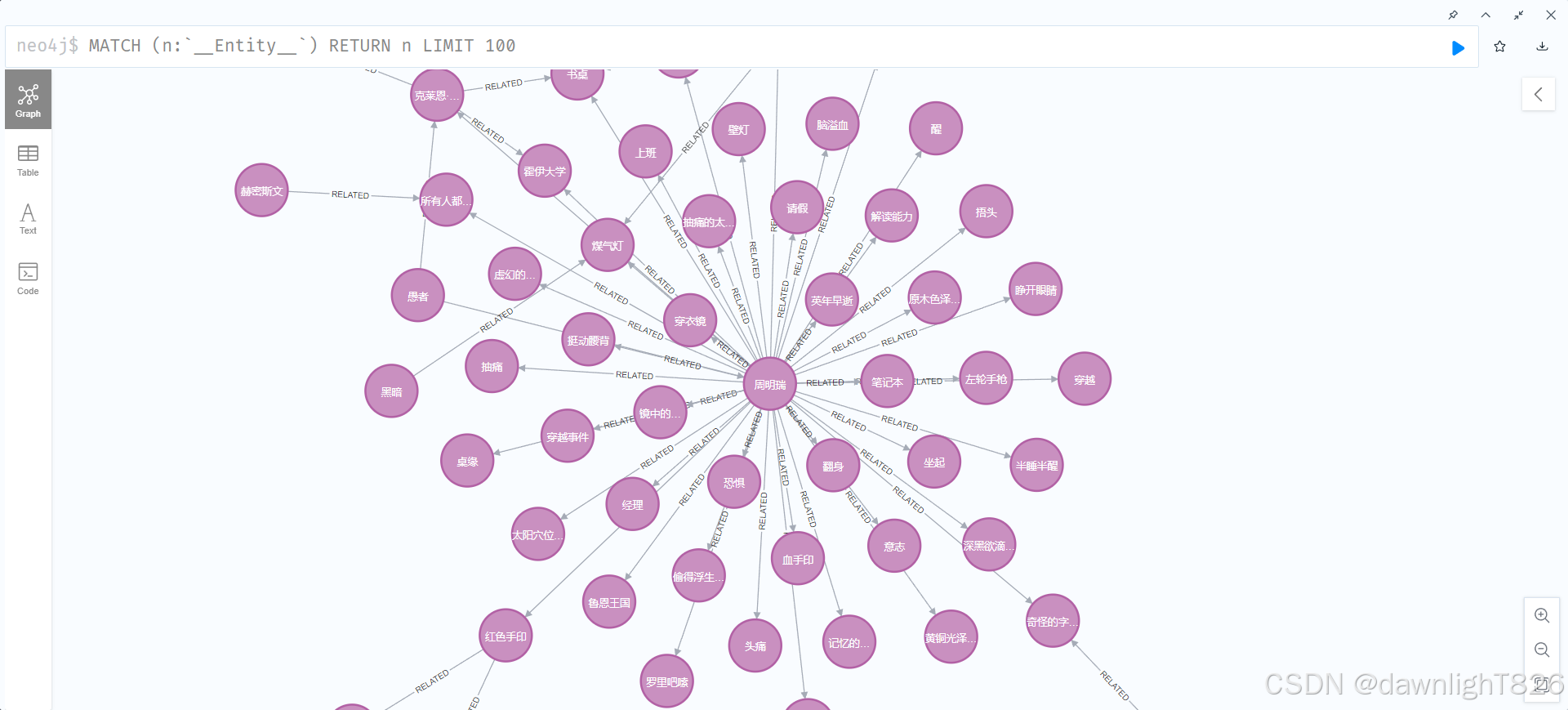
1.部分entity展示
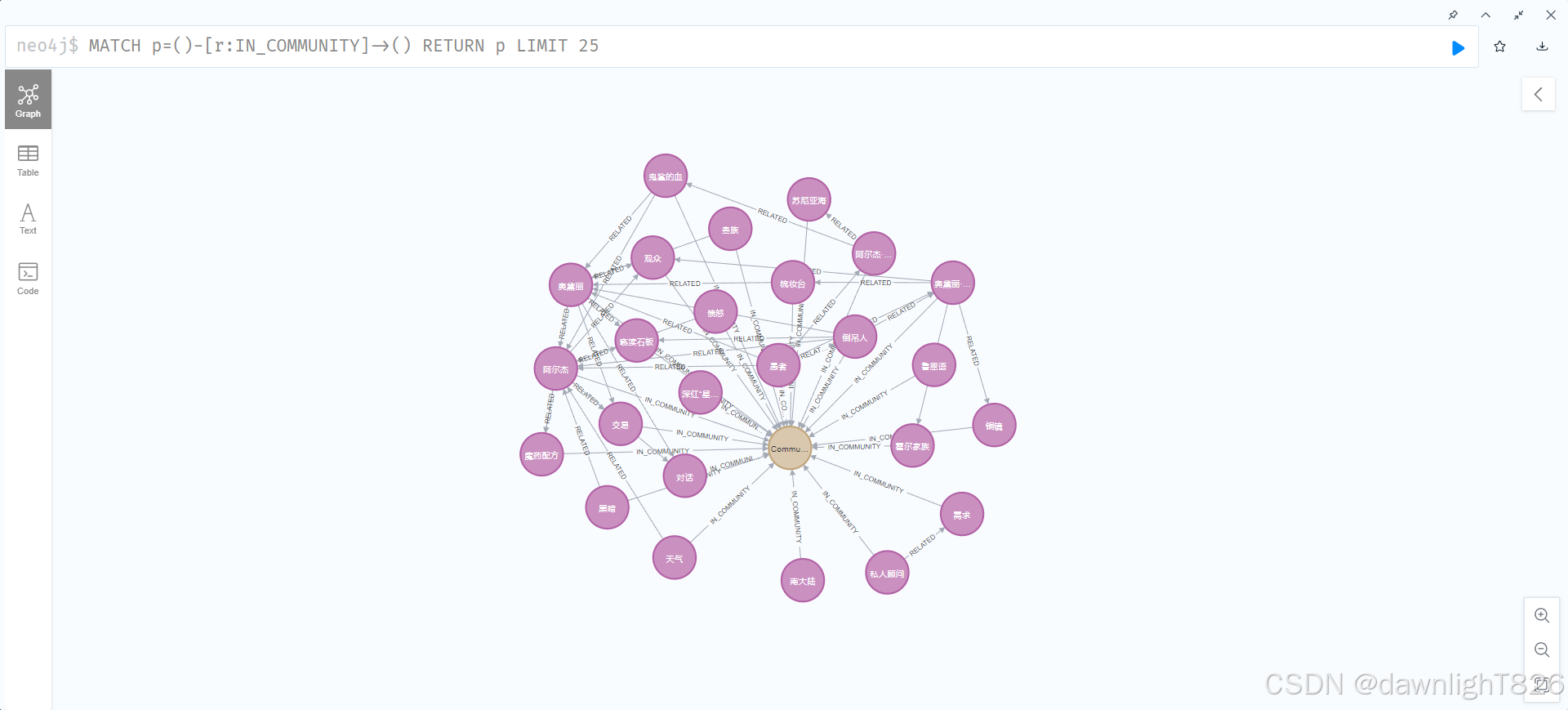
2. relationship展示
遇到的error和解决办法
- 格式解析函数不稳定
15:13:27,950 graphrag.index.graph.extractors.community_reports.community_reports_extractor ERROR error generating community report
Traceback (most recent call last):
File "D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\index\graph\extractors\community_reports\community_reports_extractor.py", line 58, in __call__
await self._llm(
File "D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\llm\openai\json_parsing_llm.py", line 34, in __call__
result = await self._delegate(input, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\llm\openai\openai_token_replacing_llm.py", line 37, in __call__
return await self._delegate(input, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\llm\openai\openai_history_tracking_llm.py", line 33, in __call__
output = await self._delegate(input, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\llm\base\caching_llm.py", line 96, in __call__
result = await self._delegate(input, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\llm\base\rate_limiting_llm.py", line 177, in __call__
result, start = await execute_with_retry()
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\llm\base\rate_limiting_llm.py", line 159, in execute_with_retry
async for attempt in retryer:
File "D:\anaconda\envs\graphrag\Lib\site-packages\tenacity\asyncio\__init__.py", line 166, in __anext__
do = await self.iter(retry_state=self._retry_state)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\site-packages\tenacity\asyncio\__init__.py", line 153, in iter
result = await action(retry_state)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\site-packages\tenacity\_utils.py", line 99, in inner
return call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\site-packages\tenacity\__init__.py", line 398, in <lambda>
self._add_action_func(lambda rs: rs.outcome.result())
^^^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\concurrent\futures\_base.py", line 449, in result
return self.__get_result()
^^^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\concurrent\futures\_base.py", line 401, in __get_result
raise self._exception
File "D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\llm\base\rate_limiting_llm.py", line 165, in execute_with_retry
return await do_attempt(), start
^^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\llm\base\rate_limiting_llm.py", line 147, in do_attempt
return await self._delegate(input, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\llm\base\base_llm.py", line 48, in __call__
return await self._invoke_json(input, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\llm\openai\openai_chat_llm.py", line 90, in _invoke_json
raise RuntimeError(error_msg)
RuntimeError: Failed to generate valid JSON output - Faulty JSON: {}
GraphRAG在生成community_reports的时候需要的是json格式的数据,默认的guimi3\prompts\community_report.txt给出的格式是由两个花括号的 {{}},这是因为python的format是这样规定的,"{}"中间的东西是可以替换的,如果中间是json,那么就会需要 {{ }} , 但是LLM在生成json数据可能会产生额外的字符比如 ```json, {{ 等。 Graphrag需要解析并修复llm的json输出,保证得到的是标准的json格式,相关的函数是llm\openai\utils.py中的try_parse_json_object函数,在GraphRAGv0.2.2已经增加清洗额外字符的功能,如果还有的问题的话,可以将 guimi3\prompts\community_report.txt中的 {{}} 都改为 {}。
click here
create_final_community_reports.parquet消失
"🚀All workflows completed successfully."跑通,但是生成的文件中没有create_final_community_reports.parquet,报错的信息如下:
15:47:43,281 datashaper.workflow.workflow INFO executing verb window
15:47:43,284 graphrag.index.emit.parquet_table_emitter INFO emitting parquet table create_final_community_reports.parquet
15:47:43,304 graphrag.index.emit.parquet_table_emitter ERROR Error while emitting parquet table
Traceback (most recent call last):
File "D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\index\emit\parquet_table_emitter.py", line 40, in emit
await self._storage.set(filename, data.to_parquet())
^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\site-packages\pandas\util\_decorators.py", line 333, in wrapper
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\site-packages\pandas\core\frame.py", line 3113, in to_parquet
return to_parquet(
^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\site-packages\pandas\io\parquet.py", line 480, in to_parquet
impl.write(
File "D:\anaconda\envs\graphrag\Lib\site-packages\pandas\io\parquet.py", line 190, in write
table = self.api.Table.from_pandas(df, **from_pandas_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "pyarrow\table.pxi", line 3874, in pyarrow.lib.Table.from_pandas
File "D:\anaconda\envs\graphrag\Lib\site-packages\pyarrow\pandas_compat.py", line 611, in dataframe_to_arrays
arrays = [convert_column(c, f)
^^^^^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\site-packages\pyarrow\pandas_compat.py", line 611, in <listcomp>
arrays = [convert_column(c, f)
^^^^^^^^^^^^^^^^^^^^
File "D:\anaconda\envs\graphrag\Lib\site-packages\pyarrow\pandas_compat.py", line 598, in convert_column
raise e
File "D:\anaconda\envs\graphrag\Lib\site-packages\pyarrow\pandas_compat.py", line 592, in convert_column
result = pa.array(col, type=type_, from_pandas=True, safe=safe)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "pyarrow\array.pxi", line 339, in pyarrow.lib.array
File "pyarrow\array.pxi", line 85, in pyarrow.lib._ndarray_to_array
File "pyarrow\error.pxi", line 91, in pyarrow.lib.check_status
pyarrow.lib.ArrowTypeError: ("Expected bytes, got a 'list' object", 'Conversion failed for column findings with type object')
15:47:43,520 graphrag.index.reporting.file_workflow_callbacks INFO Error emitting table details=None
相关函数在index\emit\parquet_table_emitter.py中的
async def emit(self, name: str, data: pd.DataFrame) -> None:
"""Emit a dataframe to storage."""
filename = f"{name}.parquet"
log.info("emitting parquet table %s", filename)
try:
# open('./buf.csv','w+',encoding='UTF-8')
# data.to_csv('./buf.csv',encoding='UTF-8')
# data=pd.read_csv('./buf.csv',encoding='UTF-8') 上面三行取消注释会在目录输出csv文件查看输出的内容是什么
# data['community']=data['community'].astype(str)
await self._storage.set(filename, data.to_parquet()) # 显示data转换为parquet格式出现问题
# shutil.rmtree('./buf.csv')
except ArrowTypeError as e:
log.exception("Error while emitting parquet table")
self._on_error(
e,
traceback.format_exc(),
None,
)
except ArrowInvalid as e:
log.exception("Error while emitting parquet table")
self._on_error(
e,
traceback.format_exc(),
None,
)
解决办法:
- 将上面函数的注释都取消,让data文件先转换为csv文件再转换为parquet文件,可以解决生成parquet文件的问题,但是在global和local的query的过程中会出现问题。
- or将settings.yaml中的
model_supports_json修改为false,这种方法可以顺利生成parquet文件,可以导入neo4j,并且可以global和local query。如歌还有错误的话,可能是prompt的格式错误。
click here
- 无法回答问题
出现"🚀All workflows completed successfully.", parquet文件生成都正常, indexing-enging.log文件中也没有error产生,但是在cli中global或者local query中都会出现如下错误:
(graphrag) PS D:\instance> python -m graphrag.query --root ./guimi3_copy --method global "主角为什么会加入组织?"
INFO: Reading settings from guimi3_copy\settings.yaml
D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\query\indexer_adapters.py:71: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
entity_df["community"] = entity_df["community"].fillna(-1)
D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\query\indexer_adapters.py:72: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
entity_df["community"] = entity_df["community"].astype(int)
creating llm client with {'api_key': 'REDACTED,len=9', 'type': "openai_chat", 'model': 'qwen2-72b-instruct', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 1.0, 'n': 1, 'request_timeout': 180.0, 'api_base': 'http://172.17.120.13:80/v1', 'api_version': None, 'organization': None, 'proxy': None, 'cognitive_services_endpoint': None, 'deployment_name': None, 'model_supports_json': False, 'tokens_per_minute': 0, 'requests_per_minute': 0, 'max_retries': 10, 'max_retry_wait': 10.0, 'sleep_on_rate_limit_recommendation': True, 'concurrent_requests': 25}
SUCCESS: Global Search Response:
(graphrag) PS D:\instance>
注意到"SUCCESS: Global Search Response:"后面有些情况会出现文字,有些情况是不会出现文字的输出结果的。
比较奇怪的是:
- input的长度较短的时候,比如取小说前6或者20章,在cli中正常输出内容。
(graphrag2) PS D:\instance> python -m graphrag.query --root ./guimi3 --method global "主角是一个什么样的人?"
INFO: Reading settings from guimi3\settings.yaml
creating llm client with {'api_key': 'REDACTED,len=9', 'type': "openai_chat", 'model': 'qwen2-72b-instruct', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 1.0, 'n': 1, 'request_timeout': 180.0, 'api_base': 'http://172.17.120.13:80/v1', 'api_version': None, 'organization': None, 'proxy': None, 'cognitive_services_endpoint': None, 'deployment_name': None, 'model_supports_json': False, 'tokens_per_minute': 0, 'requests_per_minute': 0, 'max_retries': 10, 'max_retry_wait': 10.0, 'sleep_on_rate_limit_recommendation': True, 'concurrent_requests': 25}
SUCCESS: Global Search Response: ## 主角周明瑞的多维度分析
### 身份与社会关系
周明瑞是廷根市的核心人物,与奥黛丽·霍尔、阿尔杰·威尔逊等非凡者有密切联系,同时与克莱恩·莫雷蒂的身份或记忆交织,这表明他在非凡者社群中扮演着 重要角色 [Data: Reports (15, 21, 20, 30, 31)]. 他与克莱恩的记忆碎片可能对他的身份产生了深远影响,导致了某种身份转换 [Data: Reports (25)].
### 职业与能力
周明瑞可能拥有超自然能力,如伤口迅速愈合,这与他作为非凡者的职业身份相吻合 [Data: Reports (15)]. 他同时在数字媒体和中国文学领域活跃,与左轮 手枪有紧密关联,这可能与他的个人安全有关 [Data: Reports (16, 25)].
### 兴趣与仪式
周明瑞参与了转运仪式,对塔罗牌感兴趣,这表明他对命运和神秘学有浓厚的兴趣 [Data: Reports (6, 21)]. 他与塔罗占卜有关联,可能与地球上的塔罗牌有联系,这暗示了他对塔罗占卜有一定的了解或兴趣 [Data: Reports (28)].
### 家庭与经济
周明瑞与班森有着紧密的家庭关系,班森为家庭成员创造了良好的学习条件,支持妹妹的教育 [Data: Reports (18)]. 他购买黑麦面包和羔羊肉,关注面包价 格变化,反映了他与经济环境的互动 [Data: Reports (15)].
### 社会经济背景
周明瑞居住在廷根市,与低收入阶层居住的地方和下水道设施相关,这反映了社区的社会经济背景 [Data: Reports (15)].
### 结论
综上所述,周明瑞是一个身份复杂、能力非凡、兴趣广泛的人物,他在社会关系、职业能力、兴趣爱好、家庭经济以及社会经济背景等多个方面都有着独特的表现。他的故事交织着非凡者社群的神秘、个人成长的挑战以及对命运的探索 [Data: Reports (15, 21, 20, 30, 31, 16, 25, 6, 21, 28, 18, 15, 15)].
(graphrag2) PS D:\instance>
- input的长度中长的时候,比如取小说的前60章, 小说第一部(100多章), 能够query出内容,但是跟前面返回的一些内容中的’INFO’又些许不同。
(graphrag2) PS D:\instance> python -m graphrag.query --root ./guimi3_copy2 --method global "主角是一个什么样的人?"
INFO: Reading settings from guimi3_copy2\settings.yaml
D:\anaconda\envs\graphrag2\Lib\site-packages\graphrag\query\indexer_adapters.py:71: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
entity_df["community"] = entity_df["community"].fillna(-1)
D:\anaconda\envs\graphrag2\Lib\site-packages\graphrag\query\indexer_adapters.py:72: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
entity_df["community"] = entity_df["community"].astype(int)
creating llm client with {'api_key': 'REDACTED,len=9', 'type': "openai_chat", 'model': 'qwen2-72b-instruct', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 1.0, 'n': 1, 'request_timeout': 180.0, 'api_base': 'http://172.17.120.13:80/v1', 'api_version': None, 'organization': None, 'proxy': None, 'cognitive_services_endpoint': None, 'deployment_name': None, 'model_supports_json': False, 'tokens_per_minute': 0, 'requests_per_minute': 0, 'max_retries': 10, 'max_retry_wait': 10.0, 'sleep_on_rate_limit_recommendation': True, 'concurrent_requests': 25}
SUCCESS: Global Search Response: ## 克莱恩:一个复杂而多维的非凡者
克莱恩是一位居住在鲁恩王国的非凡者,他不仅拥有梦境占卜、灵摆占卜、开启灵视和感知灵感的能力,还展现出接近神灵的力量,是塔罗会中的一员,同时也是愚者的另一个身份,这彰显了他在非凡者社会中的重要地位和神秘色彩 [Data: Reports (380, 422, 418)].
### 职业与能力
克莱恩的职业身份多样,包括但不限于占卜家、小丑和学徒。他与多个实体如梅高欧丝、邓恩·史密斯、佛尔思·沃尔等有着紧密联系,这些关系影响着故事的发展 [Data: Reports (651, 610, 543, 560, 351, +more)]. 他拥有灵视能力,能够观察到常人无法看到的现象,如气场、情绪颜色和灵魂的存在 [Data: Reports (368, 580, 102, 536, 367)].
### 神秘学与仪式
克莱恩对神秘学充满热情,是一位仪式魔法的专家,他不仅尝试描绘曾经进入地下室的“客人”,还通过仪式魔法清除不洁,甚至画出画像,以此证明他已具备使用该魔法的能力 [Data: Reports (685, 568)]. 他深入研究仪式与存在的关联,通过梦境、记忆碎片等途径探索未知 [Data: Reports (434)].
### 社区与关系
克莱恩是本社区的关键人物,与多个社区紧密相连,包括班森、克莱恩与梅丽莎的家庭社区,通灵者与克莱恩的超自然社区,以及克莱恩与笔记社区等 [Data: Reports (175, 676, 375)]. 他与奥黛丽、邓恩·史密斯、梅丽莎、周明瑞、阿尔杰、伦纳德等关键人物有着复杂的关系,这些关系涉及神秘学、政治、家庭和 职业等多个层面,构成了一个紧密的社区 [Data: Reports (380)].
### 探索与战斗
克莱恩在故事中扮演着核心角色,他的行动和决策对社区内的其他人物和事件产生深远影响 [Data: Reports (429, 659, 117, 603, 498, 686)]. 他不仅是一 位战斗者,还是一位探索者,经常卷入超自然事件和神秘组织的纠葛中。他与封印物、序列魔药和生命学派等神秘元素有直接关联 [Data: Reports (651, 610, 351, 634)].
### 职业晋升与能力提升
克莱恩期望通过晋升来进一步获得和提升这些非凡能力,他深入研究扮演法,以控制消化魔药过程中的精神能量,提升自身能力 [Data: Reports (403)]. 他掌握冥想技巧,用于精神集中和放松,进入精神宁静状态,这是他在仪式魔法开始前的准备活动,用于积蓄精神,帮助他快速入睡进行梦境占卜 [Data: Reports (120)].
### 知识与智慧
克莱恩是一位对非凡能力深感兴趣的人物,他似乎已经具备了某种独特的能力,这使他能够鉴别谎言和处理超自然现象。他深入研究神秘学知识,与超自然现象紧密相关 [Data: Reports (683, 491, 409, 114, 101)].
### 家庭与情感
克莱恩展现出深厚的家庭纽带,特别是与妹妹梅丽莎的兄妹关系,他关心家人,经常为梅丽莎准备食物,体现了兄妹间的亲情 [Data: Reports (506)].
### 总结
克莱恩是一位复杂且多维的角色,他不仅是占卜家,还与家人、非凡者社区和神秘力量有着紧密的联系 [Data: Reports (506, 678, 381)]. 他是一位非凡者,拥有多种职业身份,包括但不限于占卜家、小丑和学徒,与多个实体有紧密联系,如梅高欧丝、邓恩·史密斯、佛尔思·沃尔等,这些关系影响着故事的发展 [Data: Reports (651, 610, 543, 560, 351, +more)]. 他是一位占卜者,能够通过冥想进入灵界,使用星灵体进行占卜 [Data: Reports (367)].
- input为整部诡秘之主(6部)的小说的时候,只会显示如下的"INFO",但是没有文字内容显示出来。
(graphrag) PS D:\instance> python -m graphrag.query --root ./guimi3_copy --method local "小说结尾发生了什么事情?"
INFO: Reading settings from guimi3_copy\settings.yaml
INFO: Vector Store Args: {}
D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\query\indexer_adapters.py:71: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
entity_df["community"] = entity_df["community"].fillna(-1)
D:\anaconda\envs\graphrag\Lib\site-packages\graphrag\query\indexer_adapters.py:72: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
entity_df["community"] = entity_df["community"].astype(int)
creating llm client with {'api_key': 'REDACTED,len=9', 'type': "openai_chat", 'model': 'qwen2-72b-instruct', 'max_tokens': 4000, 'temperature': 0.0, 'top_p': 1.0, 'n': 1, 'request_timeout': 180.0, 'api_base': 'http://172.17.120.13:80/v1', 'api_version': None, 'organization': None, 'proxy': None, 'cognitive_services_endpoint': None, 'deployment_name': None, 'model_supports_json': False, 'tokens_per_minute': 0, 'requests_per_minute': 0, 'max_retries': 10, 'max_retry_wait': 10.0, 'sleep_on_rate_limit_recommendation': True, 'concurrent_requests': 25}
creating embedding llm client with {'api_key': 'REDACTED,len=9', 'type': "openai_embedding", 'model': 'bge-embedding', 'max_tokens': 4000, 'temperature': 0, 'top_p': 1, 'n': 1, 'request_timeout': 180.0, 'api_base': 'http://172.17.120.14:9997/v1', 'api_version': None, 'organization': None, 'proxy': None, 'cognitive_services_endpoint': None, 'deployment_name': None, 'model_supports_json': None, 'tokens_per_minute': 0, 'requests_per_minute': 0, 'max_retries': 10, 'max_retry_wait': 10.0, 'sleep_on_rate_limit_recommendation': True, 'concurrent_requests': 25}
Warning: No community records added when building community context.
SUCCESS: Local Search Response:
根据inpu的长度不同出现上面的3个不同的情况。
相关问题的描述:failed to answer,
I think the error occurs when LLM results is not json format in the map seach step. You can change another model or use a really simple test text file, and test agin.
Clean the string and extract only the JSON part,
Errors in local search,
短文本正常,长文本出错

















 1042
1042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









