






AI 推理平台在模型部署与应用落地进程中扮演着关键角色。开发者或企业如何挑选适配自身需求的推理平台?
今天,咱们就重点介绍两个主流的推理平台 Xinference 和Ollama。文章最后附上Xinference+Qwen的实战步骤,以及介绍一个如何计算模型显存使用量的小工具。
1. 什么是推理平台?
为了让大家更好理解,我们这里把推理平台和推理引擎结合进行介绍:
推理引擎(Inference Engine):专注于底层模型的运行性能,比如 vLLM、llama.cpp、TensorRT-LLM、SGlang 等。这类工具通常提供高性能的推理能力,但需要开发者自行处理模型加载、接口调用等细节。
推理平台(Inference Platform):封装了模型加载、接口调用、后端调度、硬件加速等功能,面向开发者和系统集成者,简化推理部署过程。
最常见的是Ollama和Xinference,本文为大家做一个介绍和对比分析
推理引擎和推理平台经常会结合起来使用,在下面会具体介绍。
2. Xinference 介绍
Xinference 是一个功能全面的 分布式 AI 推理框架,支持包括 大语言模型(LLM)、语音识别模型、多模态模型 在内的多种主流模型类型。
它的目标是让开发者能够像部署微服务一样,一键部署并运行开源或自定义模型,快速构建自己的 AI 服务平台。
Xinference 支持多种推理引擎,Xinference需要单独安装支持的推理引擎,当满足模型格式为pytorch、gptq或者awq等条件时,Xinference 会自动选择 vLLM 作为引擎来达到更高的吞吐量。
此外,Xinference 也支持 SGLang 后端,可根据具体的模型和应用需求,灵活选择使用 SGLang 进行推理,以充分发挥其在集群部署、大规模模型推理等方面的优势。
Xinference 的特性:

Xinference的官网地址:
https://inference.readthedocs.io/en/latest/
Github地址 Star 达到了7.5K,更多用于企业级部署:

Xinference的内部结构:
Xinference 利用Xinference 设计的 actor 编程框架 Xoscar作为其核心组件,用于管理机器、设备和模型推理进程。每个 Actor 作为模型推理的基本单元,可以将各种推理后端集成到 Actor 中,从而支持多个推理引擎和硬件。这些 Actor 被托管并在 ActorPool中调度,ActorPool设计为异步非阻塞的,充当资源池的功能。
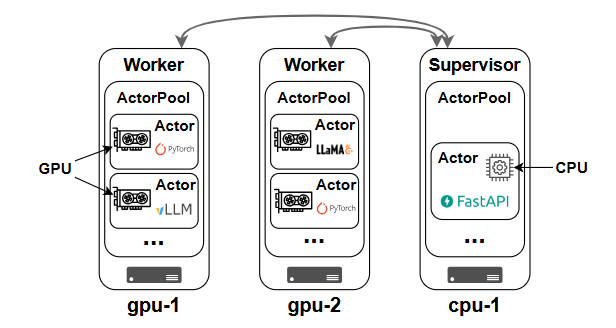
supervisor 和 worker 都是 Actor 实例。需要在每台服务器上创建一个 ActorPool,作为资源池;每个 Actor 可以使用一个 CPU 内核或一块 GPU 设备。每台服务器都有自己的地址(IP 地址或主机名),因此不同计算节点上的 Actor 可以通过这些地址相互通信。
目前Xinference 有企业版和开源版本,功能对比见下图。

3.** Ollama****介绍**
Ollama是一个旨在简化在本地运行大型语言模型(LLM) 的轻量级推理工具,强调隐私保护、高性能和本地控制权。它为开发者提供了一个极为简洁的方式,在本地系统中管理、运行和调用各种主流 LLM,无需依赖任何云服务。Ollama 自带内置推理引擎,一般情况下不需再另外安装推理引擎,可以在本地简单快速地运行 LLM。
Ollama 的特性:

Ollama的官网地址:
https://ollama.com/
主要由于个人用户的大量下载使用,Github地址 Star 达到了137K:

4. Ollama和Xinference对比分析**
**
功能维度:

性能维度:

易用性与集成:

5. 总结:如何选择合适的框架
选择:Ollama
- 本地轻量部署场景如果你希望在笔记本或边缘设备上运行 LLM,且关注数据本地化处理、或离线使用。适用于智能助手、笔记类工具、本地搜索引擎等场景。
- 开发与集成灵活性
若你追求快速集成 LLM 到现有应用中,并且运行环境多样、希望最大限度地控制部署细节,Ollama 提供了更轻量的开发体验。

选择:Xinference
- 企业级或高并发场景如果你的应用需要在大规模集群上部署、支持高并发访问,或需同时服务多个模型与任务类型(如语言、图像、语音等),推荐使用 Xinference。适用于大型问答系统、多模态平台、AI 服务平台等。
- 硬件加速与性能极限需求对模型推理速度和资源利用率有严格要求的用户,尤其是在有 GPU/TPU 等加速硬件的场景中,Xinference 提供了更专业的优化能力。

附:实战Xinference
Xinference+Qwen,实战操作步骤:
https://docs.alayanew.com/docs/documents/bestPractice/bigModel/QwQOnXinference
附:模型显存使用量计算小工具
大家可以在模型训练和推理之前,通过以下小工具计算需要多少GPU 内存以及token:
https ://rahulschand.github.io/gpu_poor/



















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









