








这篇文章的背景是说在深度学习下的隐私保护中,差分隐私在组合和采样等方面存在隐私退化问题,从而对训练神经网络进行隐私分析变得十分复杂。所以文章提出一种新的定义叫做f-DP,用于对训练神经网络进行细化的隐私分析。并且利用f-DP的组合和采样属性推导出SGD和Adam优化算法的隐私保证的表达式。
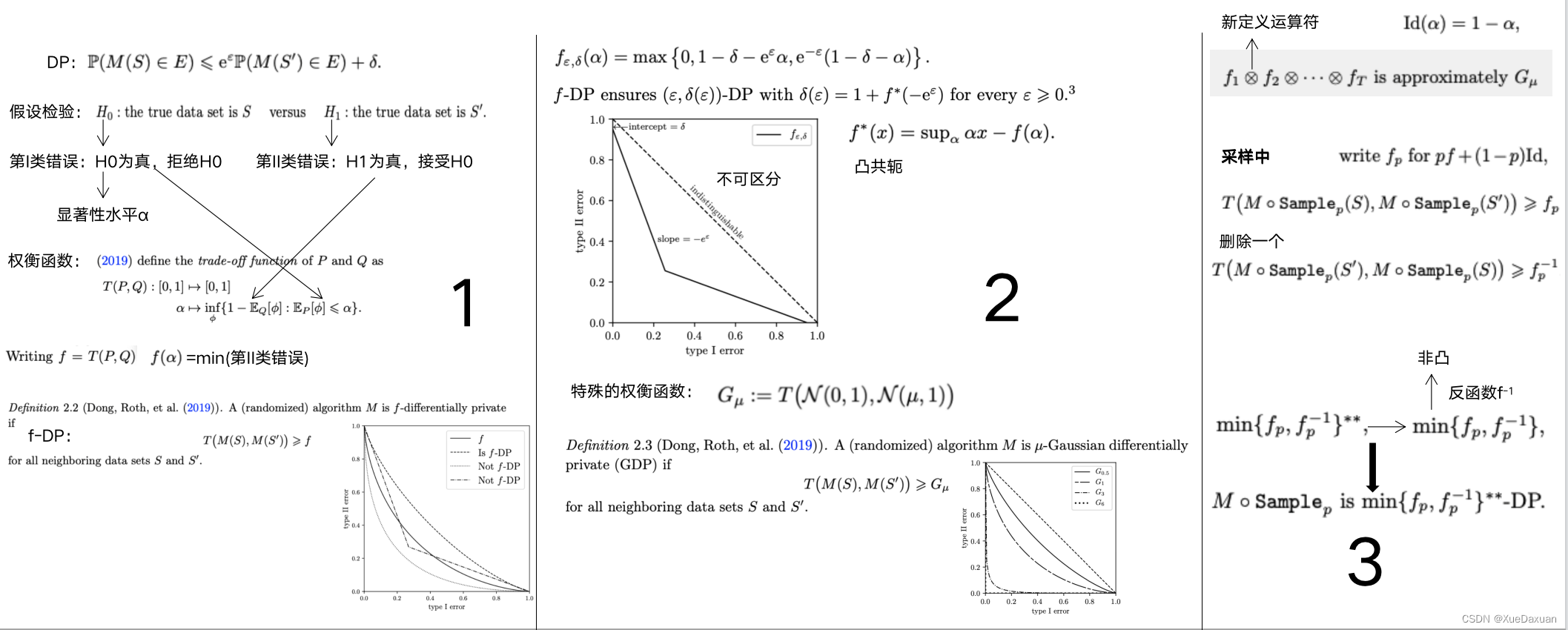
在DP中,我们用概率分布来确定样本是否在两个数据集中,如果背景知识强大的攻击者不能够区分样本来自哪个数据集,那么证明这个随机算法是好的。
那么从统计学假设检验的角度来看的话,我们可以把问题等价成,原假设H0和备择假设H1。将H0为真,但是拒绝H0这种事件叫做第一类错误,将H1为真,接受H0这种事件叫做第二类错误。其中第一类错误是小于等于显著性水平α ,表示的是H0为真但是拒绝H0的概率。(置信度中的α)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9454
9454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









