







算法介绍
线性回归:
1,监督算法
2,y是连续的,属于回归算法(KNN是离散的y,属于分类算法)
一元线性回归&多元线性回归
元:未知数个数
次:这个多项式的最高次数
一元线性回归:y=kx+b y=2x+1
多元线性回归:y=k1x1+k2x2+… +b
两直线 平行:k相等
两直线 垂直:k乘积等于-1
两直线交于y轴:b1=b2
最佳拟合线满足的条件
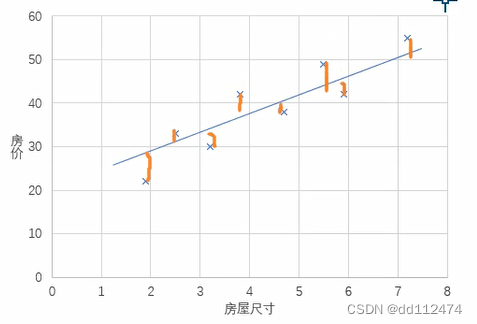

构建模型
w 权重weight -----直线斜率
b 偏差bias -----直线 截距
本来是求所有点到直线的绝对值之和最小,为了方便直接求平方和最小
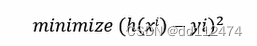
更进一步,对m个样本的平均最小误差:
(误差平方和函数)

之所以是1/2m 而不是 1/m,是为了便于求偏导,求偏导是1/2直接抵消掉了

线性回归要点总结(重要)

最小二乘法
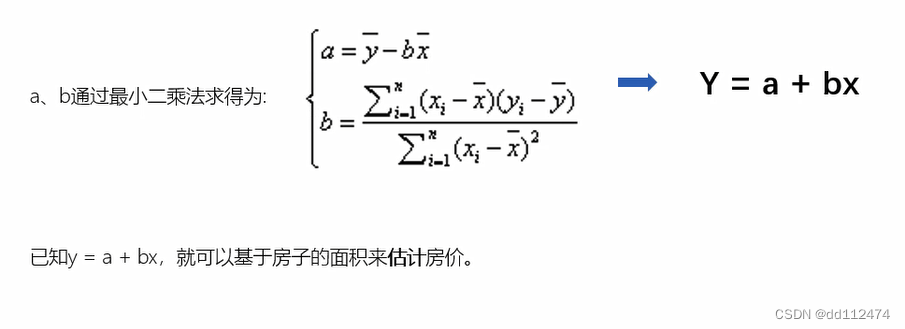
梯度下降法(线性系数计算)
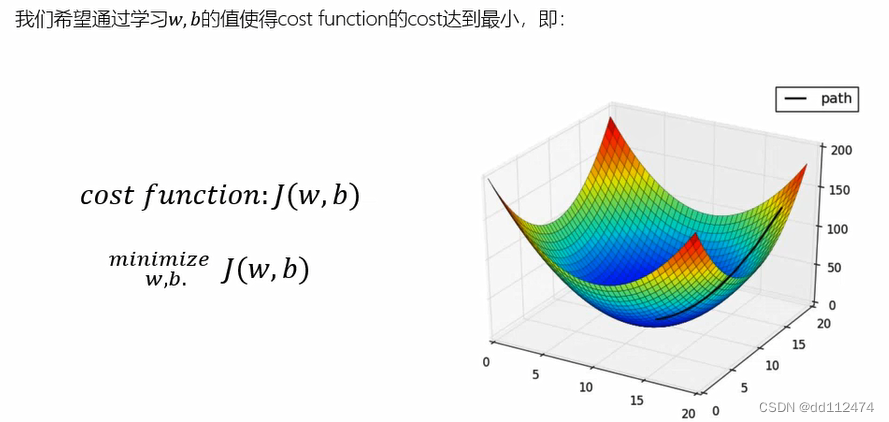
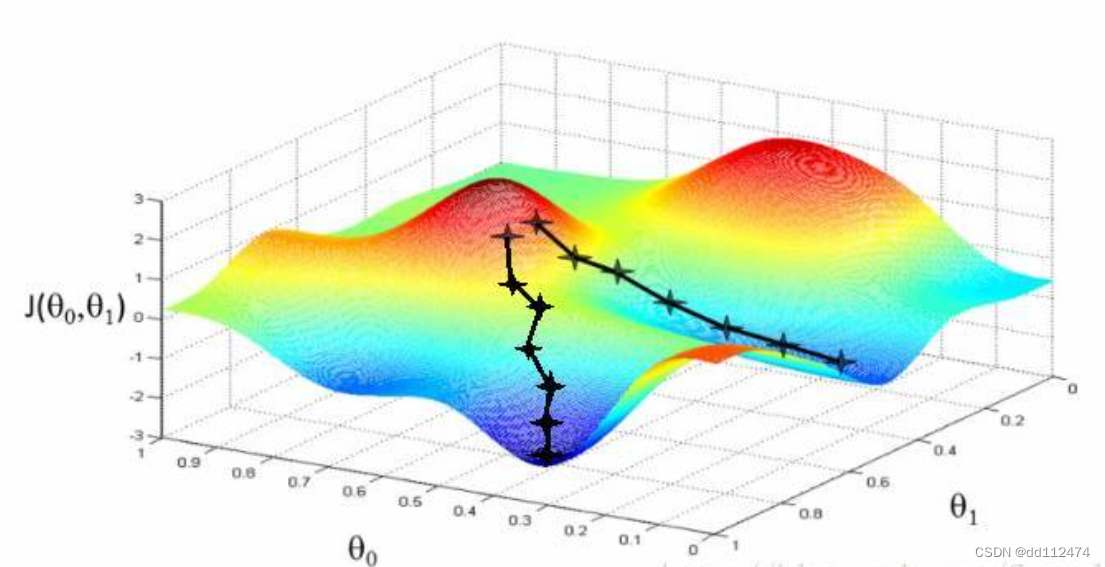
我的理解:一个人,站在山顶(红色部分),他想走到山脚(蓝色半部分),他迈出的每一步的步幅(学习率α)是相同的。那么,他往越陡的方向走,就越快到达山脚,这里“越陡”就是沿着斜率方向,而斜率就是求偏导,这也就是为啥线性回归那里误差函数前面有个1/2方便在这里抵消偏导的*2


梯度下降和最小二乘法都可以求得 y=ax+b 里面的a和b
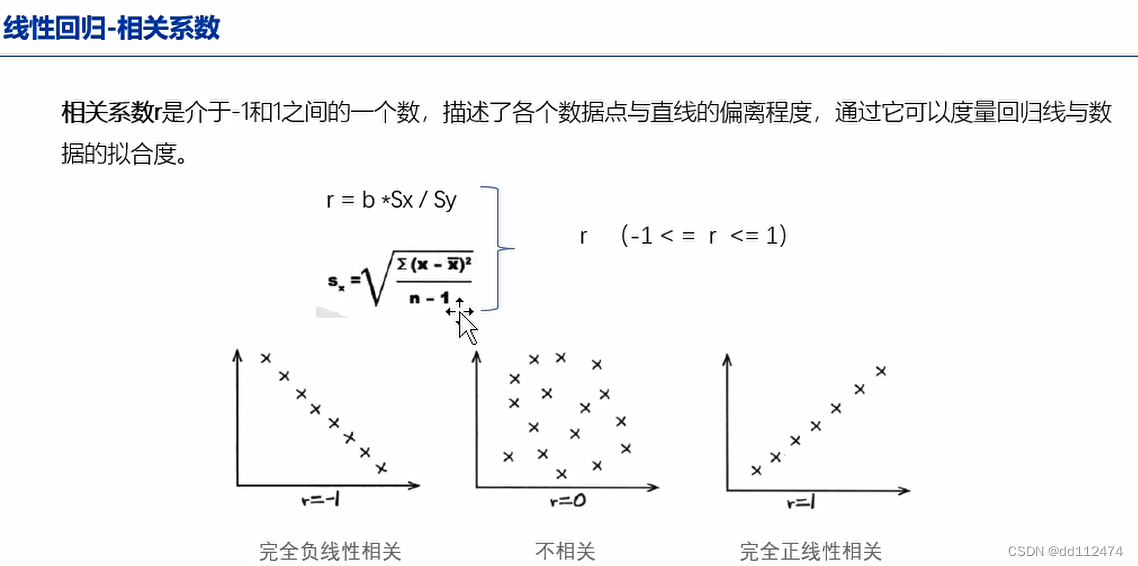
相关性
pandas中相关系数r可以用 DataFrame.corr()来求
数学模型:
相关性代码 .corr()
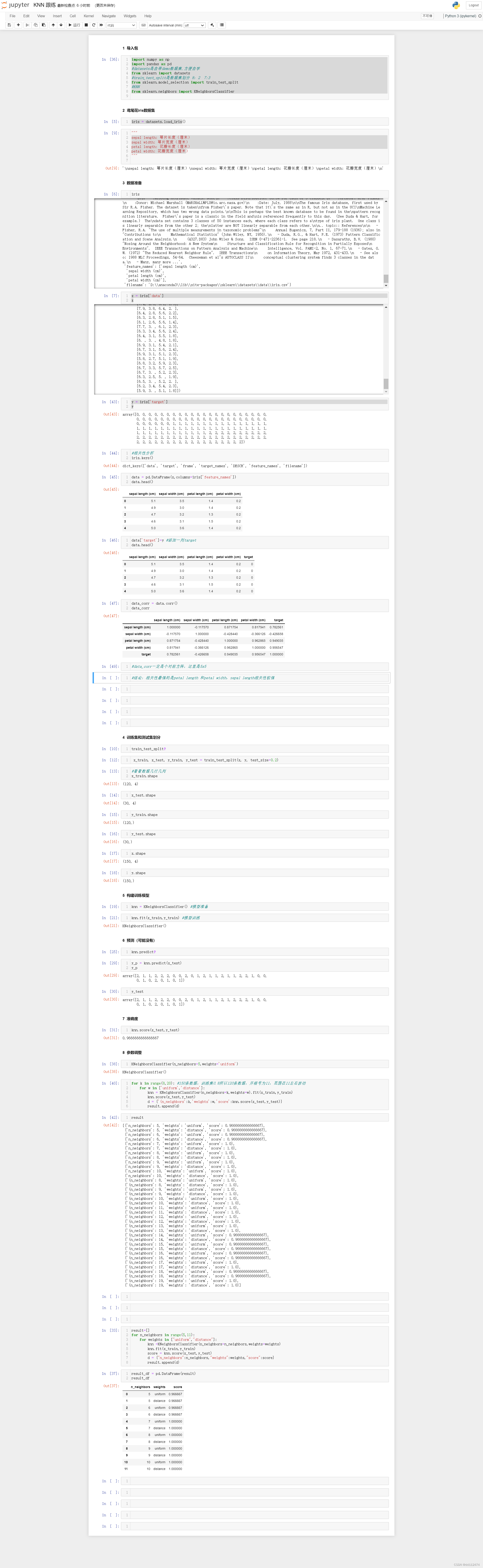
这里直接用上次KNN的那个数据集
导入包
import numpy as np
import pandas as pd
#datasets是自带demo数据集,方便自学
from sklearn import datasets
#train_test_split是数据集划分 8:2 7:3
from sklearn.model_selection import train_test_split
#KNN
from sklearn.neighbors import KNeighborsClassifier
导入数据集,生成x,y
sepal length: 萼片长度(厘米)
sepal width: 萼片宽度(厘米)
petal length: 花瓣长度(厘米)
petal width: 花瓣宽度(厘米)
iris = datasets.load_iris()
x = iris['data']
x
y = iris['target']
y
将数据放进DataFrame
在iris数据里可以看到feature_name
因为做相关性分析必须要表里同时有x和y,所以要加一列y (第46行)
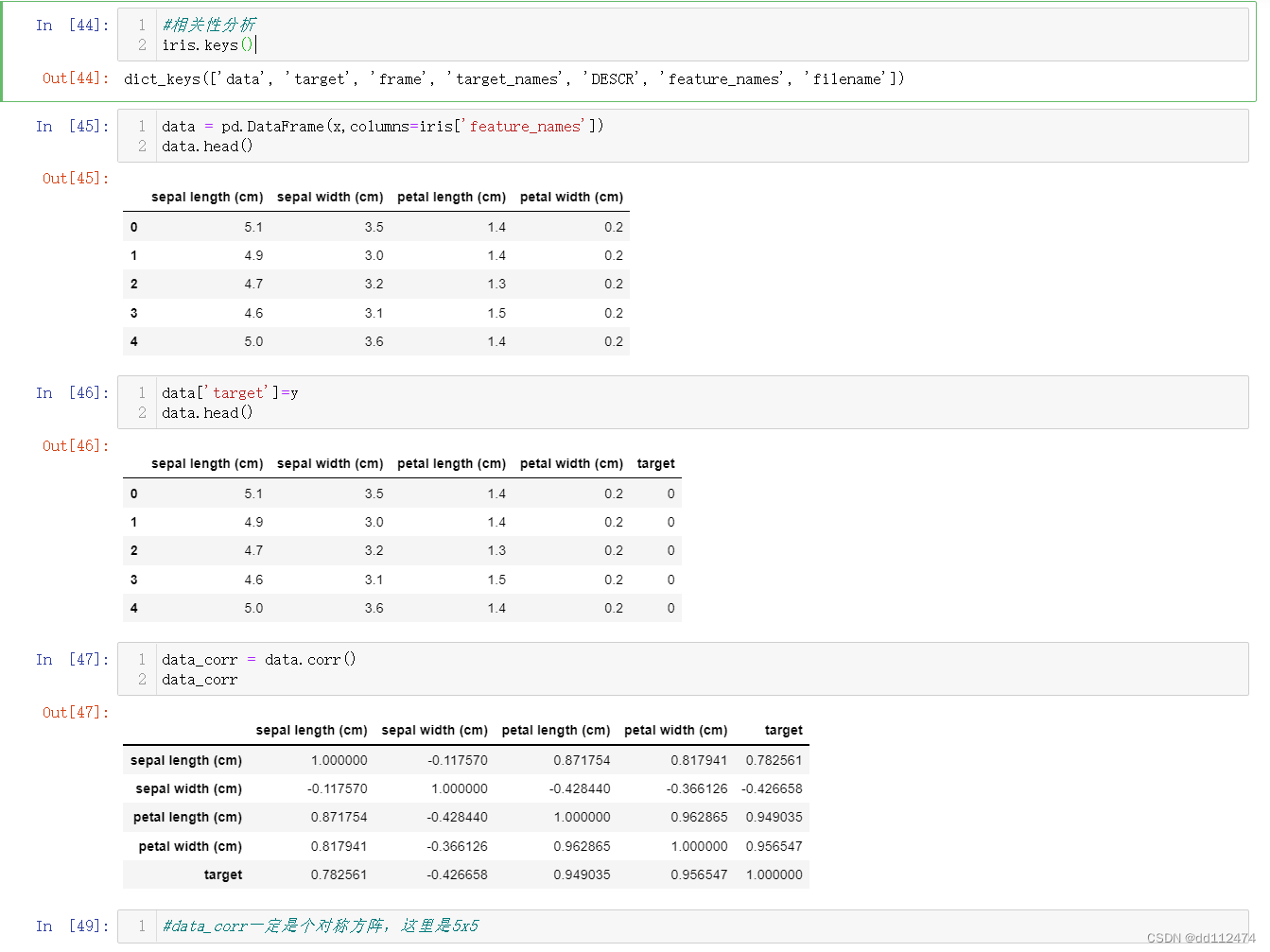
比如:这个数据的含义是:petal length(花瓣长度)与sepal length(萼片长度)呈正相关,相关性为0.871754

最终只关心x和y的关系,这里y就是target那一列,所以只用看最后一列:
相关性最强的是petal length 和petal width,sepal length相关性较强

单独用Series或者DataFrame拎出来看,更直观。
DataFrame就是多了一个[]

全文代码参考















 1029
1029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









