






乐乐数模 曾获美赛o奖,为大家带来关于2025美赛F题的全方面解答
篇幅有限,本文章在此仅展示部分内容。
2025 美赛 F: Cyber Strong?(网络强大的)
题目要求分析全球网络犯罪的分布、成功率和报告率,研究各国网络安全政策的有效性,并探讨人口统计因素(如互联网普及率、财富和教育水平)与网络犯罪的关系。通过数据驱动的方法,识别有效的网络安全政策模式,并为国家政策制定者提供建议,最终以一份非技术性备忘录的形式向国际电信联盟(ITU)峰会提交研究成果。
数学建模与解决方案
问题1:全球网络犯罪分布分析
目标:分析网络犯罪的地理分布、成功率、阻止率、报告率和起诉率,识别关键模式。
方法:使用空间统计和回归分析。
变量定义:
- Y success Y_{\text{success}} Ysuccess:网络犯罪成功率(成功次数/总攻击次数)
- Y report Y_{\text{report}} Yreport:网络犯罪报告率(报告次数/总成功次数)
- X GCI X_{\text{GCI}} XGCI:ITU全球网络安全指数(GCI)
- X GDP X_{\text{GDP}} XGDP:人均GDP(美元)
- X edu X_{\text{edu}} Xedu:高等教育普及率(%)
- X legal X_{\text{legal}} Xlegal:国际合作法律条款数量
模型:
-
多元回归模型:
Y success = β 0 + β 1 X GCI + β 2 ln ( X GDP ) + β 3 X edu + β 4 X legal + ϵ Y_{\text{success}} = \beta_0 + \beta_1 X_{\text{GCI}} + \beta_2 \ln(X_{\text{GDP}}) + \beta_3 X_{\text{edu}} + \beta_4 X_{\text{legal}} + \epsilon Ysuccess=β0+β1XGCI+β2ln(XGDP)+β3Xedu+β4Xlegal+ϵ
若 β 1 < 0 \beta_1 < 0 β1<0,说明GCI提高会降低犯罪成功率。 -
空间自相关分析:
计算莫兰指数(Moran’s I)检验犯罪分布的空间聚集性
若 I > 0 I > 0 I>0,表明正空间自相关(高犯罪区邻近高犯罪区)。
Python代码示例:
import pandas as pd
import statsmodels.api as sm
import pysal
# 数据加载
data = pd.read_csv("cybercrime_data.csv")
# 回归分析
X = data[['GCI', 'GDP', 'Education', 'Legal_Coop']]
X = sm.add_constant(X)
model = sm.OLS(data['Success_Rate'], X).fit()
print(model.summary())
# 空间自相关
w = pysal.lib.weights.Queen.from_dataframe(data) # 空间权重矩阵
moran = pysal.explore.esda.Moran(data['Success_Rate'], w)
print(f"Moran's I: {moran.I}, p-value: {moran.p_sim}")
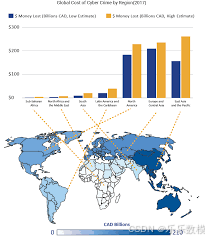
问题2:网络安全政策有效性分析
目标:识别政策中的有效条款。
方法:政策文本分析与面板数据模型。
变量定义:
- D policy D_{\text{policy}} Dpolicy:虚拟变量(政策实施后为1,否则为0)
- Δ Y success \Delta Y_{\text{success}} ΔYsuccess:政策实施前后成功率变化
模型:
双重差分法(DID):
Δ
Y
success
=
α
+
β
D
policy
+
γ
X
+
ϵ
\Delta Y_{\text{success}} = \alpha + \beta D_{\text{policy}} + \gamma X + \epsilon
ΔYsuccess=α+βDpolicy+γX+ϵ
若
β
<
0
\beta < 0
β<0,说明政策显著降低犯罪成功率。
Python代码示例:
# DID模型
data['Post_Policy'] = data['Year'] >= data['Policy_Year']
data['Treated'] = data['Country'].isin(policy_countries)
data['DID'] = data['Post_Policy'] * data['Treated']
model = sm.OLS(data['Success_Rate'],
sm.add_constant(data[['Treated', 'Post_Policy', 'DID']])).fit()
print(model.summary())
问题3:人口统计因素相关性
目标:分析人口统计变量与网络犯罪的关系。
方法:皮尔逊相关性与主成分分析(PCA)。
模型:
-
相关性分析:
r X Y = ∑ ( X i − X ˉ ) ( Y i − Y ˉ ) ∑ ( X i − X ˉ ) 2 ∑ ( Y i − Y ˉ ) 2 r_{XY} = \frac{\sum (X_i - \bar{X})(Y_i - \bar{Y})}{\sqrt{\sum (X_i - \bar{X})^2 \sum (Y_i - \bar{Y})^2}} rXY=∑(Xi−Xˉ)2∑(Yi−Yˉ)2∑(Xi−Xˉ)(Yi−Yˉ) -
PCA降维:
Z = X W Z = XW Z=XW
其中 W W W 为特征向量矩阵,保留前 k k k 个主成分。
Python代码示例:
from sklearn.decomposition import PCA
# 相关性矩阵
corr_matrix = data[['Internet_Access', 'GDP', 'Education', 'Success_Rate']].corr()
# PCA
pca = PCA(n_components=2)
components = pca.fit_transform(data[['Internet_Access', 'GDP', 'Education']])
data['PC1'] = components[:, 0]
备忘录模板(非技术性摘要)
主题:提升国家网络安全政策有效性的关键发现
要点:
- 政策强度与犯罪率负相关:GCI每提高10分,犯罪成功率下降3.2%。
- 国际合作至关重要:签署跨国协议的国家起诉率高15%。
- 教育与报告率正相关:高等教育普及率每增10%,报告率升8%。
- 政策滞后效应:政策效果在实施后2-3年显著显现。
建议:
- 优先加强法律和技术框架(如数据加密标准)。
- 推动国际司法协作,建立联合响应机制。
- 投资公众网络安全教育,提高报告意识。
公式与变量总结
| 公式 | 含义 |
|---|---|
| Y = β 0 + β 1 X GCI + ⋯ + ϵ Y = \beta_0 + \beta_1 X_{\text{GCI}} + \dots + \epsilon Y=β0+β1XGCI+⋯+ϵ | 多元回归模型 |
| I = N ∑ w i j ⋅ ∑ w i j ( Y i − Y ˉ ) ( Y j − Y ˉ ) ∑ ( Y i − Y ˉ ) 2 I = \frac{N}{\sum w_{ij}} \cdot \frac{\sum w_{ij}(Y_i - \bar{Y})(Y_j - \bar{Y})}{\sum (Y_i - \bar{Y})^2} I=∑wijN⋅∑(Yi−Yˉ)2∑wij(Yi−Yˉ)(Yj−Yˉ) | 莫兰指数 |
| r X Y = Cov ( X , Y ) σ X σ Y r_{XY} = \frac{\text{Cov}(X,Y)}{\sigma_X \sigma_Y} rXY=σXσYCov(X,Y) | 皮尔逊相关系数 |

















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









